Learn more about Search Results エージェント - Page 7

- You may be interested
- MLflowを使用した機械学習実験のトラッキング
- BERTopicとHugging Face Hubの統合をご紹...
- 詳細な説明でPythonでテキストから特徴を...
- 『MakeBlobs + フィクショナルな合成デー...
- ナノタトゥーは、電池やワイヤーが必要あ...
- GPT-エンジニア:あなたの新しいAIコーデ...
- NVIDIAとUTオースティンの研究者がMimicGe...
- 「メタのLlama 2の力を明らかにする:創発...
- 3Dインスタンスセグメンテーションにおけ...
- 「ODSC Westでの対面トレーニングがチーム...
- AIのインフレーション:常に多い方がいい...
- あなたは優れたEDAフレームワークを持って...
- 「データセットに欠損値がありますか?何...
- 「ODSC West Bootcamp Roadmapのご紹介 &#...
- 「SelFeeに会いましょう:自己フィードバ...

「LangChainエージェントを使用してLLMをスーパーチャージする方法」
「LangChainエージェントを使用すると、アプリケーション内でLarge Language Modelを拡張し、外部の情報源にアクセスしたり、自身でアクションを実行することができます」
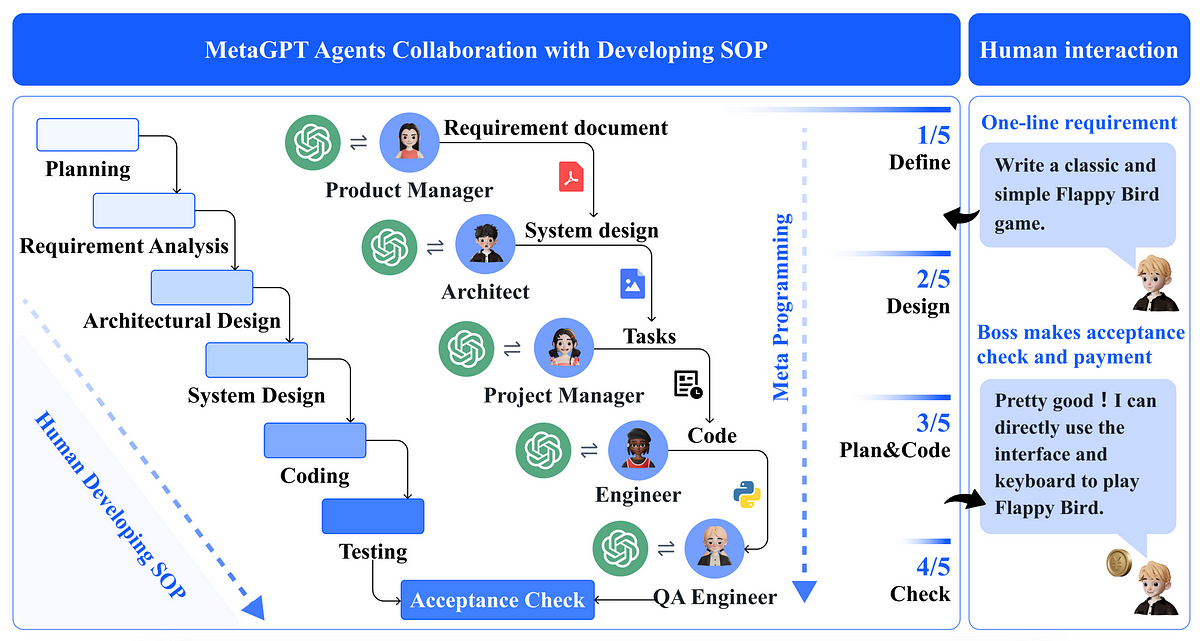
メタGPTとは何ですか?LLMエージェントが複雑なタスクを解決するために協力することです
GPTと最近の大規模な言語モデルのおかげで、新しいタイプのAIベースのシステム、エージェントの普及が見られましたエージェントとは、ChatGPTのようなAIモデルで、アクセスして対話を行うことができるものです

AIエージェント:月のジェネレーティブAIトレンド
わずか30分で、実世界の知識を持つLLMを使用して、ノーコードAIエージェントアプリケーションを構築する方法を学びます

この中国のAI論文では、「物理的なシーンの制約を持つ具体的な計画におけるタスクプランニングエージェント(TaPA)」が提案されています
日常生活でどのように意思決定を行うのでしょうか?私たちはしばしば私たちの常識に基づいて偏見を持ちます。ではロボットはどうでしょうか?彼らは常識に基づいて意思決定をすることができるのでしょうか?人間の指示を成功裏に完了するには、共通の感覚を持つ具現化エージェントが必要です。現在のLLMsは現実の世界のより詳細な情報が必要なため、実行不可能なアクションの連続を生じます。 自動化学科と北京国家情報科学技術研究センターの研究者たちは、物理的なシーンの制約を持つ具現化されたタスクでのTAsk Planning Agent(TaPA)を提案しました。これらのエージェントは、視覚認識モデルとLLMsを整列させることにより、シーン内の既存のオブジェクトに応じた実行可能なプランを生成します。 研究者は、TaPAがタスクの種類やターゲットオブジェクトを制約せずに具体的な計画を生成できると主張しています。まず、各サンプルが視覚的なシーン、指示、および対応するプランの三つ組である多モーダルデータセットを作成しました。生成されたデータセットから、シーンのオブジェクトリストに基づいてアクションステップを予測することで、事前学習済みのLLaMAネットワークを微調整し、さらにタスクプランナーとして割り当てます。 具現化エージェントは、立ち止まるポイントを効果的に訪れ、RGB画像を収集し、多視点の情報を提供することで、オープンボキャブラリディテクタを多視点画像に汎化するための十分な情報を提供します。この全体のプロセスにより、TaPAはシーン情報と人間の指示を考慮して、ステップバイステップで実行可能なアクションを生成することができます。 彼らはどのように多モーダルデータセットを生成したのでしょうか?ビジョン言語モデルや大規模多モーダルモデルを活用する方法の一つです。しかし、計画エージェントを訓練するための大規模な多モーダルデータセットが不足しているため、現実の屋内シーンに基づく具現化されたタスクプランニングを作成し達成することは困難です。彼らはGPT-3.5を使用し、提示されたシーン表現と設計プロンプトを使用して、計画エージェントの調整のための大規模な多モーダルデータセットを生成することでこれを解決しました。 研究者は、事前学習済みのLLMsからタスクプランナーをトレーニングし、80の屋内シーン、15Kの指示とアクションプランを含む多モーダルデータセットを構築しました。彼らは位置選択基準や回転カメラなどの周囲の3Dシーンを探索するための画像収集戦略をいくつか設計しました。クラスタリング手法に触発されて、彼らは全体のシーンをいくつかのサブリージョンに分割し、知覚のパフォーマンスを向上させました。 研究者たちは、TaPAエージェントがLLMaやGPT-3.5などの最先端のLLMsやLLaVAなどの大規模多モーダルモデルよりも生成されたアクションプランの成功率が高いと主張しています。LLaVAとGPT-3.5と比較して、それぞれ26.7%と5%の幻覚ケースの割合が減少していることで、入力オブジェクトのリストをより良く理解できるとしています。 研究者たちは、収集した多モーダルデータセットの統計データが、従来の命令従順タスクのベンチマークよりもはるかに複雑で、実装ステップが長く、最適化のためにさらなる新しい手法が必要であることを示していると主張しています。

SalesforceのAI研究者が、LLMを活用した自律エージェントの進化と革新的なBOLAA戦略を紹介します
最近の大規模言語モデル(LLM)の成果により、LLMを使用してさまざまな複雑なタスクを処理するための新しい研究が奨励されており、特にLLMを拡張した自律エージェント(LAA)には最も大きな注目が集まっています。 LAAは、LLMの知能を連続的なアクション実行に拡張することにより、設定と難解な問題の処理においてデータを収集することで優位性を示します。 BabyAGI1は、OpenAI LLM2を使用してタスクを生成し、優先順位付けし、実行するAIパワードのタスク管理システムを提案しています。 LLM APIの呼び出しを許可する人気のあるオープンソースのLAAフレームワークはAutoGPT3です。 ReActは、後続のアクションを生成する前に周囲と対話する最近提案されたLAA技術です。 LAAを作成するための現在のオープンソースのフレームワークはLangchain4と呼ばれます。オリジナルの調査のため、LAAは十分に調査されていません。最初に開始するために最適なエージェントアーキテクチャはまだ特定されていません。 LLMが次のアクションを生成するためにインコンテキスト学習を行うためには、ReActはすでに定義済みの例でエージェントを刺激します。さらに、ReActは、アクションを実行する前に中間思考に従事する必要があると主張します。 ReWOOは、LAAに追加の計画プロセスを導入します。 Langchainは、ゼロショットのツール使用能力を持つReActエージェントを一般化します。最適なエージェント設計は、タスクと対応するLLMバックボーンとの整合性を考慮していない先行研究であまり十分に考慮されていません。第二に、LAAにおける現在のLLMの効果の知識はまだ完了していません。初期の論文では、わずかなLLMバックボーンのパフォーマンスが比較されています。 ReActは、主要なLLMとしてPaLMを使用します。 ReWOOは、エージェントの計画と命令の調整にOpenAI text-DaVinci-003モデルを使用します。一般的なウェブエージェントのために、MIND2WebではFlan-T5とOpenAI GPT3.5/4を比較します。 ただし、最近の研究では、異なる事前学習済みLLMを使用したLAAの効果の比較を徹底的に行っているわずかな論文しかありません。比較的最近の記事では、LLMをエージェントとして評価するためのベースラインを発表しています。ただし、エージェントアーキテクチャとそれらのLLMバックボーンを同時に考慮する必要があります。 LAAの研究は、効果と効率の観点から最適なLLMを選択することによって進化しています。第三に、活動がより複雑になるにつれて、多くのエージェントが調整を必要とする場合があります。最近、ReWOOは、推論を観察から分離することでLAAの効果を高めることを発見しました。 この研究では、Salesforce Researchの研究者は、特にオープンドメインの状況において、タスクの複雑さが上がると複数のエージェントを調整して単一のジョブを実行することが好ましいと主張しています。たとえば、オンラインのナビゲーションの仕事では、クリックエージェントを使用してクリック可能なボタンと対話し、他のリソースを見つけるために検索エージェントに依頼するかもしれません。ただし、オーケストレーションの効果を検証し、多くの個人を調整する方法を探索する論文はほとんどありません。この報告書では、これらの研究のギャップを埋めるために、LAAのパフォーマンス比較を包括的に分析することを提案しています。彼らは、LLMバックボーンとLAAエージェントアーキテクチャにさらに深く踏み込みます。 彼らは、既存の設定からエージェントのベンチマークを作成し、さまざまなLLMバックボーンに基づいたさまざまなエージェントアーキテクチャの機能を評価します。彼らのエージェントベンチマークのタスクは、複数のタスクの複雑さレベルに関連しているため、タスクの複雑さに応じたエージェントのパフォーマンスを評価することが可能です。これらのエージェントアーキテクチャは、現在の設計の決定を徹底的に検証するために作成されています。複数の労働LAAの選択とコミュニケーションを可能にするために、彼らはBOLAA5というユニークなLAAアーキテクチャを提示しています。これには、数多くの協力エージェントの上にコントローラーモジュールが備わっています。 この論文の貢献は以下の通りです: • 6つの異なるLAAエージェントアーキテクチャが開発されました。プロンプト、自己思考、および計画から派生したLAAの設計の直感をサポートするために、これらをいくつかのバックボーンLLMと統合しました。また、アクションとの関与能力を向上させるために、多数の孤立したエージェントの能力を向上させるためのマルチエージェント戦略オーケストレーションのためのBOLAAを作成しました。 •…

AgentBenchをご紹介します:さまざまな状況で大規模な言語モデルをエージェントとして評価するために開発された多次元ベンチマークです
大規模言語モデル(LLM)は登場し、進化し、人工知能の分野に複雑さの新たなレベルを加えました。徹底的なトレーニング方法により、これらのモデルは驚くべき自然言語処理、自然言語理解、自然言語生成のタスクをマスターしました。質問に答える、自然言語の推論を理解する、要約するなどのタスクです。また、NLPに一般的に関連付けられていない、人間の意図を把握し、指示を実行するなどの活動も達成しています。 LLMを使用して自律的な目標を達成するAutoGPT、BabyAGI、AgentGPTなどのアプリケーションは、すべてのNLPの進歩のおかげで可能になりました。これらのアプローチは一般の人々から多くの関心を集めていますが、LLMを評価するための標準化されたベースラインの欠如は依然として重要な障害となっています。過去にはテキストベースのゲーム環境が言語エージェントを評価するために使用されてきましたが、それらは制約された離散的な行動空間を持つため、しばしば欠点があります。また、それらは主にモデルの常識的な根拠の能力を評価します。 エージェントのための既存のベンチマークのほとんどは特定の環境に焦点を当てているため、さまざまなアプリケーションコンテキストでLLMを徹底的に評価する能力が制限されています。これらの問題に対処するために、清華大学、オハイオ州立大学、UCバークレーの研究者チームがエージェントベンチを導入しました。エージェントベンチは、さまざまな設定でLLMをエージェントとして評価するために作成された多次元ベンチマークです。 エージェントベンチには8つの異なる設定が含まれており、そのうち5つは新しいものです。横思考パズル(LTP)、知識グラフ(KG)、デジタルカードゲーム(DCG)、オペレーティングシステム(OS)、データベース(DB)、知識グラフです。最後の3つの環境(家事(Alfworld)、オンラインショッピング(WebShop)、ウェブブラウジング(Mind2Web))は既存のデータセットから適応されています。これらの環境はすべて、テキストベースのLLMが自律的なエージェントとして行動できる対話的な状況を表現するよう慎重に設計されています。これらは、コーディング、知識獲得、論理的な推論、指示の従順さなど、主要なLLMのスキルを徹底的に評価するための厳密なテストベッドとして機能し、エージェントとLLMの両方を評価するためのものです。 研究者はAgentBenchを使用して、APIベースのモデルやオープンソースのモデルを含む25の異なるLLMを徹底的に分析し、評価しました。調査結果は、GPT-4などのトップモデルが幅広い実世界のタスクをうまくこなすことを示しており、高度に能力が高く、常に適応するエージェントの作成の可能性を示唆しています。ただし、これらのトップAPIベースのモデルは、オープンソースの同等モデルよりも明らかに性能が劣っています。オープンソースのLLMは他のベンチマークでは優れたパフォーマンスを発揮しますが、AgentBenchの困難なタスクが提示されると、大きな困難に直面します。これは、オープンソースのLLMの学習能力を向上させるための追加の取り組みが必要であることを強調しています。 貢献は以下のようにまとめられます: AgentBenchは、標準化された評価手順を定義し、LLMをエージェントとして評価する革新的なコンセプトを導入する徹底的なベンチマークです。それは8つの本物の環境を統合し、実世界の状況をシミュレートすることで、LLMのさまざまな能力を評価するための有用なプラットフォームを提供します。 この研究では、AgentBenchを使用して25の異なるLLMを徹底的に評価し、主要な商用APIベースのLLMとオープンソースの代替品との間に大きなパフォーマンスの差があることを明らかにしました。この評価は、LLM-as-Agentの現状を強調し、改善の余地がある領域を特定しています。 この研究では、AgentBench評価手順のカスタマイズを容易にする「API&Docker」相互作用パラダイムに基づいた統合ツールセットも提供されています。このツールセットの提供は、関連するデータセットと環境とともに、LLMの研究開発における共同研究と開発を促進します。

Dynalang エージェント学習における言語理解と将来予測の統合
急速に進化する人工知能の分野において、人間と効果的に対話し、現実世界の複雑さを乗り越えることができるエージェントは非常に求められていますこれらのエージェントは、人間の言語の微妙なニュアンスを理解するだけでなく、それを視覚的な環境と結びつける必要があります現在のエージェントモデルはしばしば...

「Retroformer」をご紹介します:プラグインの回顧モデルを学習することで、大規模な言語エージェントの反復的な改善を実現する優れたAIフレームワーク
大規模な言語モデル(LLM)を強化して、単にユーザーの質問に応答するのではなく、目標のために独立して活動できる自律的な言語エージェントにするという、力強い新しいトレンドが浮上しています。React、Toolformer、HuggingGPT、生成エージェント、WebGPT、AutoGPT、BabyAGI、Langchainなどは、LLMを利用して自律的な意思決定エージェントを開発する実用性を効果的に実証したよく知られた研究です。これらの手法は、LLMを使用してテキストベースの出力とアクションを生成し、それを使用して特定の文脈でAPIにアクセスし、活動を実行します。 ただし、現在の言語エージェントの大部分は、パラメータ数の多いLLMの範囲が非常に広いため、環境の報酬関数に最適化された行動を持っていません。ReflexionやSelf-Refine、Generative Agentなど、同様のアプローチを取る他の多くの作品とは異なり、比較的新しい言語エージェントアーキテクチャである反省アーキテクチャは、過去の失敗から学ぶために、口頭フィードバック、具体的には自己反省を利用してエージェントを支援します。これらの反射エージェントは、環境のバイナリまたはスカラーの報酬を音声入力としてテキストの要約に変換し、言語エージェントのプロンプトにさらなる文脈を提供します。 自己反省フィードバックは、エージェントに特定の改善領域を指示することで、エージェントにとって意味的な信号となります。これにより、エージェントは過去の失敗から学び、同じ間違いを繰り返さずに次回の試行でより良い結果を出すことができます。ただし、自己反省操作によって反復的な改善が可能になるものの、事前に訓練された凍結LLMから有用な反省フィードバックを生成することは困難です(図1参照)。これは、LLMが特定の環境でエージェントの誤りを特定し、改善の提案を含む要約を生成する能力が必要だからです。 図1は、凍結LLMの情報のない自己反省のイラストです。エージェントは「Teen Titans」という回答ではなく、「Teen Titans Go」と回答するべきであり、これが前回の試行が失敗した主な理由です。一連の思考、行動、詳細な観察を通じて、エージェントは目標を見失いました。しかし、凍結LLMからの音声フィードバックは、以前のアクションシーケンスを新たな計画として提案するだけであり、次の試行でも同じ間違った行動につながります。 特定の状況でのタスクの信用割り当ての問題を専門にするために、凍結言語モデルを十分に調整する必要があります。また、現在の言語エージェントは、異なる可能な報酬に基づいて勾配ベースの学習からの思考や計画に一貫した方法で取り組んでいません。Salesforce Researchの研究者は、Retroformerというモラルフレームワークを紹介し、制約を解決するためのプラグインの後向きモデルを学習して言語エージェントを強化する方法を提案しています。Retroformerは、方策最適化を通じて環境からの入力に基づいて言語エージェントのプロンプトを自動的に改善します。 具体的には、提案されたエージェントアーキテクチャは、失敗した試行を反省し、将来の報酬に対してエージェントが実行したアクションにクレジットを割り当てることで、事前に訓練された言語モデルを反復的に改善します。これは、複数の環境とタスク全体にわたる任意の報酬情報から学習することによって行われます。HotPotQAなどのオープンソースのシミュレーションおよび実世界の設定(WikipediaのAPIに繰り返し問い合わせる必要があるWebエージェントのツール使用スキルを評価する)で実験を行います。HotPotQAは、検索ベースの質問応答タスクで構成されています。反省に対して、勾配を使用しない思考や計画を行わないRetroformerエージェントは、より速く学習し、より良い意思決定を行います。具体的には、Retroformerエージェントは、検索ベースの質問応答タスクのHotPotQAの成功率をわずか4回の試行で18%向上させ、多くの状態アクション空間を持つ環境でのツール使用における勾配ベースの計画と推論の価値を証明しています。 結論として、彼らが貢献した内容は次の通りです: • この研究では、大規模言語エージェントへのコンテキスト入力に基づいて提示されるプロンプトを反復的に洗練することで、学習速度とタスク完了を向上させるRetroformerを開発しました。提案された手法は、Actor LLMのパラメータにアクセスせず、勾配を伝播する必要もないため、言語エージェントアーキテクチャ内のレトロスペクティブモデルの強化に焦点を当てています。 • 提案された手法により、さまざまなタスクと環境のためのさまざまな報酬信号からの学習が可能となります。Retroformerは、その汎用性のため、GPTやBardなどのクラウドベースのLLMに適応可能なプラグインモジュールです。

UCバークレーの研究者は、Dynalangを紹介しますこれは、未来のテキストおよび画像表現を予測するためにマルチモーダルなワールドモデルを学習するAIエージェントであり、想像されたモデルのロールアウトからの行動を学習します
自然言語を使用して現実世界で人々と自然にコミュニケーションできるボットを作成することは、人工知能の目標の一つです。現在の具現化エージェントは、「青いブロックを取って」「エレベーターを過ぎて右に曲がって」といった単純で低レベルのコマンドを実行できます。しかし、対話エージェントは「ここと今」の範囲外で人々が言語を使う方法の全て、知識の伝達(例:「左上のボタンでテレビの電源を切る」)、状況情報(例:「牛乳が切れています」)、調整(例:「リビングルームの掃除機はもうした」)を理解できるようにする必要があります。 子供たちが読むテキストや他の人から聞く情報のほとんどは、世界の機能や現在の状況についての情報を伝えています。エージェントが他の言語で話すことを可能にするにはどうすればよいでしょうか?強化学習(RL)は、言語依存のエージェントに問題を解決するための技術です。しかし、現在使用されているほとんどの言語依存のRL技術は、タスク固有の指示からアクションを生成するように訓練されています。たとえば、「青いブロックを取って」という目標の説明を入力とし、一連のモーターコマンドを生成することで訓練されます。自然言語が現実の世界で果たす役割の多様性を考慮すると、言語を最適な行動に直接マッピングすることは難しい学習の課題となります。 作業が片付けである場合、エージェントは次の片付けの手順に移るように答えるべきですが、夕食を提供する場合はボウルを集めるべきです。例えば「私はボウルを片付けました」という場合を考えてみましょう。仕事について話さない場合、言語はエージェントにとって最適な行動と弱い相関関係しか持ちません。その結果、言語を活用して活動を完了するためにさまざまな言語入力を使用するための学習信号として、タスク報酬のみの言語から活動へのマッピングがより良い学習信号となる可能性があります。代わりに、彼らは言語の統一的な機能は将来の予測を支援することだと提案しています。「私はボウルを片付けました」というフレーズによって、エージェントは将来の観測をより正確に予測することができます(つまり、キャビネットを開ければ中にボウルがあることがわかる)。 この意味で、子供たちが出会う言語の大部分は視覚的な経験に根ざしているかもしれません。エージェントは「レンチはナットを締めるために使用できる」というような事前の情報を使用して環境の変化を予測することができます。エージェントは「パッケージは外にある」というような発言によって観測を予測するかもしれません。このパラダイムは、指示がエージェントが報酬を予想するのに役立つという予測的な用語の下で一般的な指示の従い方を組み合わせています。彼らは、将来の表現を予測することがエージェントに言語を理解し、その言語が外部世界とどのように相互作用するかを理解するのに豊かな学習信号を提供すると主張しています。次のトークンの予測が言語モデルが世界の知識の内部表現を構築するのに役立つように、これらの貢献は示しています。 UCバークレーの研究者は、Dynalangというエージェントを紹介しています。Dynalangはオンラインの経験を通じて世界の言語と視覚モデルを獲得し、そのモデルを理解して行動する方法を利用します。Dynalangは、そのモデルを使用して行動を学習する(タスク報酬を持つ強化学習)と、言語で世界のモデルを学習する(予測ターゲットを持つ教師あり学習)を分離します。世界モデルは、視覚的およびテキストの入力を観測モダリティとして受け取り、それらは潜在空間に圧縮されます。エージェントが周囲と対話する中で収集したデータを使用して、世界モデルを将来の潜在的な表現を予測するように訓練します。世界モデルの潜在的な表現を入力として使用し、タスク報酬を最大化するための意思決定を行うポリシーを訓練します。 世界モデリングは行動とは異なるため、Dynalangは作業やタスク報酬のない単一のモダリティ(テキストのみまたはビデオのみのデータ)で事前に訓練することができます。また、言語生成のためのフレームワークも統一される可能性があります。エージェントの知覚は言語モデルに影響を与えることができます(つまり、将来のトークンに関する予測を行い、行動空間で言語を生成することにより、環境についてコミュニケーションすることができます)。彼らはDynalangをさまざまな言語的文脈を持つさまざまなドメインでテストしています。Dynalangは、ビジョン言語ナビゲーションにおいて、視覚的および言語的に複雑な領域での指示を理解するために、将来の観測、環境ダイナミクス、修正に関する言語的手がかりを利用して、マルチタスクの家庭清掃設定でタスクをより迅速に実行することを学習します。Messengerベンチマークでは、Dynalangはゲームの最も困難なステージに合わせるためにゲームマニュアルを読み込み、タスク固有のアーキテクチャを上回る成績を収めます。これらの貢献は、Dynalangがさまざまなタスクを達成するためにさまざまな形式の言語を理解することを学習し、最先端の強化学習アルゴリズムやタスク固有のアーキテクチャに頻繁に勝ることを示しています。 彼らが行った貢献は以下の通りです: • 彼らは、将来の予測を利用して言語と視覚体験を結びつけるエージェントであるDynalangを提案しています。 • Dynalangは、さまざまな種類の言語を理解し、様々なタスクに取り組むために学習することにより、最新のRLアルゴリズムやタスク固有の設計を凌駕していることを示しています。 • Dynalangの形式は、アクションやタスクのインセンティブなしで、テキストの事前学習と言語生成を組み合わせる能力を含む新たな可能性を開くことを示しています。

「スタンフォード研究者は、直接の監督なしでメタ強化学習エージェントにおける単純な言語スキルの出現を探求する:カスタマイズされたマルチタスク環境におけるブレイクスルーを解明する」
スタンフォード大学の研究チームは、Reinforcement Learning(RL)エージェントが明示的な言語教育なしで間接的に言語スキルを学ぶことができるかどうかを調査することにより、自然言語処理(NLP)の分野で画期的な進展を遂げました。この研究の主な焦点は、非言語目標を達成するために環境との相互作用によって学習する能力で知られるRLエージェントが同様に言語スキルを発展させることができるかどうかを探究することでした。そのため、チームはオフィスナビゲーション環境を設計し、エージェントに可能な限り迅速に目標のオフィスを見つけるように挑戦しました。 研究者たちは、自らの探求を以下の4つの重要な質問に基づいて行いました: 1. エージェントは明示的な言語教育なしに言語を学ぶことができるのか? 2. エージェントは、言語以外のモード、例えば絵の地図など、他のモダリティを解釈することができるのか? 3. 言語スキルの出現に影響を与える要因は何か? 4. これらの結果は、高次元のピクセル観測を持つより複雑な3D環境にも適用できるのか? 言語の出現を調査するために、チームはDREAM(Deep REinforcement learning Agents with Meta-learning)エージェントを2Dオフィス環境で訓練し、トレーニングデータとして言語のフロアプランを使用しました。驚くべきことに、DREAMは探索ポリシーを学習し、フロアプランをナビゲートして読むことができるようになりました。この情報を活用し、エージェントは目標のオフィスルームに到達し、最適なパフォーマンスを達成しました。エージェントの未知の相対ステップ数や新しいレイアウトに対する汎化能力、フロアプランの学習表現を探求する能力は、その言語スキルをさらに実証しました。 初期の調査結果に満足せず、チームはさらに一歩踏み込み、DREAMを2Dバージョンのオフィスで訓練し、今度は絵のフロアプランをトレーニングデータとして使用しました。その結果も同様に印象的であり、DREAMは伝統的な言語以外のモダリティを読む能力を証明し、目標のオフィスまで歩行することができました。 この研究では、RLエージェントの言語スキルの出現に影響を与える要因を理解することも試みられました。研究者たちは、学習アルゴリズム、メタトレーニングデータの量、モデルのサイズがエージェントの言語能力を形成する上で重要な役割を果たすことを発見しました。 最後に、研究者たちはその調査結果の拡張性を検証するために、オフィス環境をより複雑な3Dドメインに拡大しました。驚くべきことに、DREAMはフロアプランを読み続け、直接の言語教育なしでタスクを解決し続けました。これにより、DREAMの言語習得能力の堅牢性がさらに確認されました。 この先駆的な研究の結果は、言語が非言語的なタスクを解決する過程で副産物として出現する可能性があることを示す説得力のある証拠を提供しています。間接的に言語を学ぶことで、これらの具体化されたRLエージェントは、関連のない目標を達成しようとする過程で人間が言語スキルを獲得する方法と驚くほど似ています。 この研究の示唆は広範囲にわたり、明示的な言語教育を必要とせずに多くのタスクに自然に適応できるより洗練された言語学習モデルの開発に向けた魅力的な可能性を切り拓きます。これらの調査結果は、NLPの進歩に貢献し、言語を理解し使用する能力がますます洗練されたAIシステムの進展に大きく貢献することが期待されています。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.