Learn more about Search Results [6] - Page 7

- You may be interested
- 「人工的な汎用知能(Artificial General ...
- 「夢の彫刻:DreamTimeは、テキストから3D...
- 「ExcelでのPython:これがデータサイエン...
- 「2023年の機械学習のアンラーニング:現...
- 「リリに会ってください:マッキンゼーの...
- 機械学習洞察のディレクター【パート4】
- 「ロボットが外科医よりも正確に眼球の裏...
- 「粒子群最適化:探索手順、ビジュアライズ」
- 「データ分析のためのトップ10のSQLプロジ...
- 「OpenAIがDall E-3を発売!次世代AIイメ...
- 『チェッカーフラッグの先に:F1統計の探求』
- スクラッチからCodeParrot 🦜をトレーニン...
- Mistral AIは、Mistral 7Bをオープンソー...
- スタンフォードの研究者がRoboFuMeを導入...
- アレクサ・ゴルディッチとともにAIキャリ...
「先天性とは何か、そしてそれは人工知能にとって重要なのか?(パート1)」
「生物学と人工知能における先天性の問題は、人間のようなAIの将来にとって重要ですこの概念とその応用についての二部構成の詳細な解説は、状況を明確にするのに役立つかもしれません...」
イネイテンスとは何か?人工知能にとって重要なのか?(パート2)
「生物学と人工知能における先天性の問題は、人間のようなAIの将来にとって重要ですこの2部構成の深い探求は、この概念とその応用についての議論を解消するかもしれません...」

「普及型生成AIの環境への影響」
この記事は、次の問いについて考えます ChatGPTのような生成型AIが大規模に採用された場合の環境への影響はどうなるでしょうか?つまり、何十億人が利用する場合の環境への影響はどうなるかということです…

LLaMA 皆のためのLLM!
何年もの間、深層学習コミュニティは公開性と透明性を受け入れ、HuggingFaceのような大規模なオープンソースプロジェクトを生み出してきました深層学習における最も重要なアイデアの多くは、このようなプロジェクトで生まれました(例えば...

「ChatGPTコードインタプリタを使用して、人道支援データの非構造化Excelテーブルを分析する」
新しい実験的な機能「コードインタプリター」は、ChatGPTの使用の一環としてPythonコードの生成と実行をネイティブにサポートしますデータエンジニアリングを行うためには大きな潜在能力を示しています
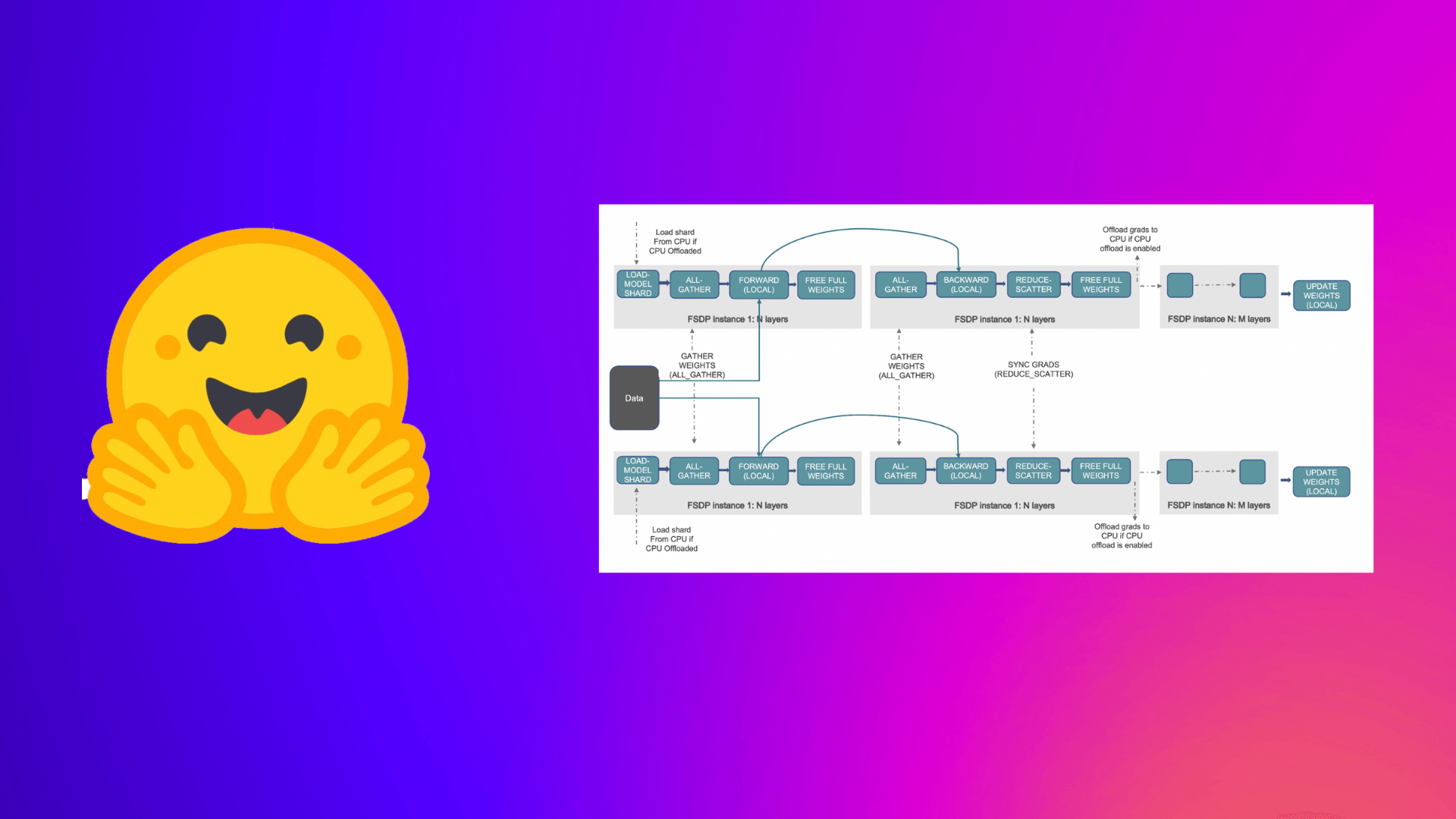
PyTorch完全にシャーディングされたデータパラレルを使用して、大規模モデルのトレーニングを加速する
この投稿では、Accelerate ライブラリを活用して大規模なモデルのトレーニングを行う方法について説明します。これにより、ユーザーは PyTorch FullyShardedDataParallel (FSDP) の最新機能を活用することができます。 機械学習 (ML) モデルのスケール、サイズ、およびパラメータがますます増加するにつれ、ML プラクティショナーは自身のハードウェア上でそのような大規模なモデルをトレーニングしたり、ロードしたりすることが困難になっています。 一方で、大規模なモデルは小さなモデルと比較して学習が速く(データと計算効率が高く)、パフォーマンスも著しく向上することがわかっています [1]。しかし、そのようなモデルをほとんどの利用可能なハードウェア上でトレーニングすることは困難です。 大規模なMLモデルをトレーニングするためには、分散トレーニングが重要です。 分散トレーニング の分野では、最近重要な進展がありました。最も注目すべき進展のいくつかは以下のとおりです: ZeROを用いたデータ並列化 – Zero Redundancy Optimizer [2] ステージ1:データ並列ワーカー/ GPU間でオプティマイザーの状態を分割 ステージ2:データ並列ワーカー/…

DeepSpeedを使用して大規模モデルトレーニングを高速化する
この投稿では、Accelerate ライブラリを活用して、ユーザーが DeeSpeed の ZeRO 機能を利用して大規模なモデルをトレーニングする方法について説明します。 大規模なモデルをトレーニングしようとする際にメモリ不足 (OOM) エラーに悩まされていますか?私たちがサポートします。大規模なモデルは非常に高性能ですが、利用可能なハードウェアでトレーニングするのは困難です。大規模なモデルのトレーニングに利用可能なハードウェアの最大限の性能を引き出すために、ZeRO – Zero Redundancy Optimizer [2] を使用したデータ並列処理を活用することができます。 以下は、このブログ記事からの図を使用した ZeRO を使用したデータ並列処理の短い説明です。 (出典: リンク) a. ステージ 1 :…
トランスフォーマーにおける対比的探索を用いた人間レベルのテキスト生成 🤗
1. 紹介: 自然言語生成(テキスト生成)は自然言語処理(NLP)の中核的なタスクの一つです。このブログでは、現在の最先端のデコーディング手法であるコントラスティブサーチを神経テキスト生成のために紹介します。コントラスティブサーチは、元々「A Contrastive Framework for Neural Text Generation」[1]([論文] [公式実装])でNeurIPS 2022で提案されました。さらに、この続編の「Contrastive Search Is What You Need For Neural Text Generation」[2]([論文] [公式実装])では、コントラスティブサーチがオフザシェルフの言語モデルを使用して16の言語で人間レベルのテキストを生成できることが示されています。 [備考] テキスト生成に馴染みのないユーザーは、このブログ記事を詳しくご覧ください。 2.…

より小さいほうが良いです:Xeon上で効率的な生成AI体験、Q8-Chat
大規模言語モデル(LLM)は、機械学習の世界を席巻しています。Transformerアーキテクチャのおかげで、LLMはテキスト、画像、ビデオ、オーディオなどの大量の非構造化データから学習する驚異的な能力を持っています。テキスト分類のような抽出型のタスクや、テキスト要約、テキストから画像生成などの生成型のタスクでも非常に優れたパフォーマンスを発揮します。 その名前からもわかるように、LLMは一般的に100億パラメータを超える大規模なモデルです。BLOOMモデルのように1000億パラメータ以上のものもあります。LLMは、検索や対話型アプリケーションなどの低遅延のユースケースで十分に高速な予測を行うために、高性能なGPUに典型的に見られる大量の計算能力を必要とします。残念ながら、多くの組織にとっては関連するコストが高く、最先端のLLMをアプリケーションに使用することが困難になります。 この記事では、Intel CPU上で効率的に実行するために、LLMのサイズと推論レイテンシを減らす最適化技術について説明します。 量子化の基礎 通常、LLMは16ビットの浮動小数点パラメータ(FP16/BF16)でトレーニングされます。したがって、単一の重みまたはアクティベーション値の値を保存するためには2バイトのメモリが必要です。さらに、浮動小数点の演算は整数の演算よりも複雑で遅く、追加の計算能力が必要です。 量子化は、モデルパラメータが取ることができるユニークな値の範囲を縮小することで、両方の問題を解決するモデルの圧縮技術です。たとえば、モデルを8ビット整数(INT8)のような低精度に量子化して、モデルを縮小し、複雑な浮動小数点演算をより単純で高速な整数演算に置き換えることができます。 要するに、量子化はモデルパラメータをより小さな値範囲に再スケーリングします。成功すると、モデルのサイズが少なくとも2倍に縮小され、モデルの精度には影響しません。 量子化は、通常、トレーニング中に適用することができます。これを量子化対応トレーニング(QAT)と呼びますが、一般的に最良の結果が得られます。既存のモデルを量子化する場合は、非常に少ない計算能力を必要とする高速なテクニックであるポストトレーニング量子化(PTQ)を適用することもできます。 さまざまな量子化ツールが利用可能です。たとえば、PyTorchには量子化の組み込みサポートがあります。また、QATおよびPTQのための開発者向けのAPIを備えたHugging Face Optimum Intelライブラリを使用することもできます。 LLMの量子化 最近の研究[1][2]によると、現在の量子化技術はLLMとはうまく機能しません。特に、LLMはすべてのレイヤーとトークンで特定のアクティベーションチャネルに大きな値の外れ値を示します。以下はOPT-13Bモデルの例です。すべてのトークンで、アクティベーションの1つのチャネルが他のすべてのチャネルよりもはるかに大きな値を持っていることがわかります。この現象はモデルのすべてのTransformerレイヤーで見られます。 *出典: SmoothQuant* 現在の最良の量子化技術は、トークン単位でアクティベーションを量子化し、切り捨てられた外れ値または低いマグニチュードのアクティベーションを引き起こします。いずれの解決策もモデルの品質に大きな影響を与えます。さらに、量子化対応トレーニングには追加のモデルトレーニングが必要であり、計算リソースとデータの不足のため、ほとんどの場合には実用的ではありません。 SmoothQuant[3][4]は、この問題を解決する新しい量子化技術です。それは重みとアクティベーションに共同の数学的変換を適用し、アクティベーションの外れ値と非外れ値の比率を減らすことで、Transformerのレイヤーを「量子化に適した」状態にします。これにより、モデルの品質に影響を与えずに8ビットの量子化が可能となります。その結果、SmoothQuantはIntel CPUプラットフォーム上で優れたパフォーマンスを発揮する、より小さく、高速なモデルを生成します。 *出典: SmoothQuant* それでは、SmoothQuantを人気のあるLLMに適用した場合の動作を見てみましょう。 SmoothQuantを使用したLLMの量子化…

大規模なネアデデュープリケーション:BigCodeの背後に
対象読者 大規模な文書レベルの近似除去に興味があり、ハッシュ、グラフ、テキスト処理のいくつかの理解を持つ人々。 動機 モデルにデータを供給する前にデータをきちんと扱うことは重要です。古い格言にあるように、ゴミを入れればゴミが出てきます。データ品質があまり重要ではないという幻想を作り出す見出しをつかんでいるモデル(またはAPIと言うべきか)が増えるにつれて、それがますます難しくなっています。 BigScienceとBigCodeの両方で直面する問題の1つは、ベンチマークの汚染を含む重複です。多くの重複がある場合、モデルはトレーニングデータをそのまま出力する傾向があることが示されています[1](ただし、他のドメインではそれほど明確ではありません[2])。また、重複はモデルをプライバシー攻撃に対しても脆弱にする要因となります[1]。さらに、重複除去の典型的な利点には以下があります: 効率的なトレーニング:トレーニングステップを少なくして、同じかそれ以上のパフォーマンスを達成できます[3][4]。 データ漏洩とベンチマークの汚染を防ぐ:ゼロでない重複は評価を信用できなくし、改善という主張が偽りになる可能性があります。 アクセシビリティ:私たちのほとんどは、何千ギガバイトものテキストを繰り返しダウンロードまたは転送する余裕がありません。固定サイズのデータセットに対して、重複除去は研究、転送、共同作業を容易にします。 BigScienceからBigCodeへ 近似除去のクエストに参加した経緯、結果の進展、そして途中で得た教訓について最初に共有させてください。 すべてはBigScienceがすでに数ヶ月前に始まっていたLinkedIn上の会話から始まりました。Huu Nguyenは、私のGitHubの個人プロジェクトに気付き、BigScienceのための重複除去に取り組むことに興味があるかどうか私に声をかけました。もちろん、私の答えは「はい」となりましたが、データの膨大さから単独でどれだけの努力が必要になるかは全く無知でした。 それは楽しくも挑戦的な経験でした。その大規模なデータの研究経験はほとんどなく、みんながまだ信じていたにもかかわらず、何千ドルものクラウドコンピュート予算を任せられるという意味で挑戦的でした。はい、数回マシンをオフにしたかどうかを確認するために寝床から起きなければならなかったのです。その結果、試行錯誤を通じて仕事を学びましたが、それによってBigScienceがなければ絶対に得られなかった新しい視点が開かれました。 さらに、1年後、私は学んだことをBigCodeに戻して、さらに大きなデータセットで作業をしています。英語向けにトレーニングされたLLMに加えて、重複除去がコードモデルの改善につながることも確認しました[4]。さらに、はるかに小さなデータセットを使用しています。そして今、私は学んだことを、親愛なる読者の皆さんと共有し、重複除去の視点を通じてBigCodeの裏側で何が起こっているかを感じていただければと思います。 興味がある場合、BigScienceで始めた重複除去の比較の最新バージョンをここで紹介します: これはBigCodeのために作成したコードデータセット用のものです。データセット名が利用できない場合はモデル名が使用されます。 MinHash + LSHパラメータ( P , T , K…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.