Learn more about Search Results link - Page 79

- You may be interested
- デジタルアーティストのスティーブン・タ...
- カートゥーンキャラクターの中間プロンプト
- 「クロスファンクションの機械学習プロジ...
- 「LangchainとOllamaを使用したPDFチャッ...
- ニューヨーク大学とMetaの研究者が、「Dob...
- Skopsの紹介
- 再帰型ニューラルネットワークの基礎から...
- 「チャットボットとAIアシスタントの構築」
- 「テキスト生成推論によるコンピュータか...
- 「AIと著作権に関する公開意見募集中の米...
- 効果的にLLMをトレーニングする方法:小規...
- 「NVIDIA Studio内のコンテンツ作成が、新...
- 新しいAI研究がAttrPromptを紹介します:...
- AI医療診断はどのように動作しますか?
- 「ChatGPT Visionをデータ分析に活用する5...

50以上の機械学習面接(インタビュアーとして)から学んだこと
技術面接に臨むのが難しいと思ったなら、面接を実施してみてくださいここで言っているのは、あなたを見下すような嫌な印象を与える不器用な面接官たちではありませんが、
JAXの始め方
JAXは、Googleが開発したPythonライブラリであり、あらゆるタイプのデバイス(CPU、GPU、TPUなど)で高性能な数値計算を行うためのものですJAXの主な応用の一つは、機械学習です

Amazon SageMaker Ground Truthのはじめ方
イントロダクション ジェネレーティブAIの時代において、データ生成はピークに達しています。正確な機械学習およびAIモデルの構築には、高品質なデータセットが必要です。データセットの品質保証は最も重要なタスクであり、不正確な分析や特定できない予測は、どのビジネスの全体的なレポに影響を与え、数十億または数兆の損失をもたらす可能性があります。 出典:Forbes データラベリングは、AIモデルが理解できるようにするためのデータ品質保証の第一歩です。人間にデータラベルを付けることはできないため、日々生成される無制限のデータに人間がラベルを付けることはできません。そのため、ここでは正確にラベル付けされたデータセットを作成するための素晴らしいテクニックであるAmazon SageMaker Ground Truthについて学びます。 この記事は、データサイエンスブログマラソンの一部として公開されました。 Amazon SageMaker Ground Truthとは何ですか? Amazon SageMaker Ground Truthは、データラベリングタスクを実行して効率的で高精度なデータセットを作成するためのセルフサービスオファリングです。Ground Truthでは、サードパーティのベンダーやAmazon Mechanical Turk、または私たち自身のワークフォースを介して人間の注釈者を使用することもできます。また、エンドツーエンドのラベリングジョブを設定するための管理された体験も提供しています。 出典:Edlitera.com SageMaker Ground Truthは、データ収集やラベリングの手間をかけずに数百万の自動ラベル付け合成データを生成することができます。Ground Truthは、画像、テキスト、ビデオなどさまざまなデータタイプのデータラベリング機能を提供します。これにより、テキスト分類、セグメンテーションセグメンテーション、オブジェクト検出、画像分類のタスクを機械学習モデルが容易に行えるようになります。…

人材分析のための R ツールキット:ヘッドカウントのストーリーを伝える
人事分析の仕事では、会社の従業員数や会社が今日のように進化する過程を伝えることが求められることがよくあります私はしばしばこれをウォーターフォールチャートとして提示されるのを見ますが、それは...

NumpyとPandasを超えて:知られざるPythonライブラリの潜在能力の解放
Pythonでのデータ操作と計算について話すとき、一般的にはPandasとNumpyを思い浮かべます他にも3つの強力なライブラリを見つけましょう

ロッテン・トマト映画の評価予測のデータサイエンスプロジェクト:2つ目のアプローチ
レビューの感情に基づいて映画の状態を予測する

トップ7の列操作でより効果的にPandasデータフレームを使用する
データ分析に関しては、データを操作して準備するために最もよく使用されるPythonライブラリはPandasですでは、列に対するトップ7の操作を見てみましょう
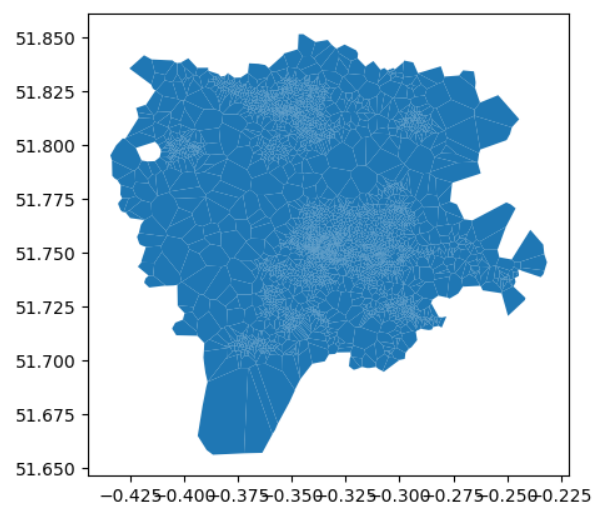
郵便番号レベルでの地理空間データの操作
一部の国では、郵便番号は地域ではなく、ポイントやルートで表されます例えば、カナダの郵便番号の最後の3桁は、地域配送ユニットに対応していて、それは一つの家に対応するかもしれません...
公正を実現する:生成モデルにおけるバイアスの認識と解消
2021年、プリンストン大学の情報技術政策センターは、機械学習アルゴリズムが人間と同様の偏見を抱くことがあるという報告書を公表しました

ACIDトランザクションとは何ですか?
トランザクションデータベースシステムにおけるACID(Atomicity, Consistency, Isolation, Durability)プロパティの理解SQLでトランザクションを書く方法に関するガイド
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.