Learn more about Search Results A - Page 799

- You may be interested
- 「OpenAIと共にAI製品を開発する CoRiseか...
- モダンなCPU上でのBERTライクモデルの推論...
- 新しいデータサイエンスの問題に取り組む...
- Google Cloud上のサーバーレストランスフ...
- 「Zoomのプライバシーの微調整が、通話内...
- 「先進的なマルチモーダル生成AIの探求」
- Amazon BedrockとAmazon Transcribeを使用...
- 「500のゲームとアプリが現在RTXによって...
- データサイエンティストの役割の典型
- このAI論文では、Complexity-Impacted Rea...
- 「AIが候補者のマッチングを通じて採用の...
- 「AIはどれくらい環境に優しいのか?人間...
- 新たな研究が、AIの隠れた脆弱性を明らか...
- 「共感を人工的に作り出す」
- Hugging Face Hubへようこそ、Stable-base...

世界最大のオープンマルチリンガル言語モデル「BLOOM」をご紹介します
大規模言語モデル(LLM)は、AI研究に大きな影響を与えています。これらの強力な汎用モデルは、ユーザーの指示に基づいてさまざまな言語タスクを遂行することができます。しかし、学術界、非営利団体、および中小企業の研究所は、それらを作成、研究、または使用することが困難であり、必要なリソースと独占的な権利を持つわずかな産業研究所だけが完全にアクセスできます。今日、私たちは初めて完全な透明性で訓練された最初の多言語LLMであるBLOOMを公開し、この現状を変えます。これは、AI研究者が単一の研究プロジェクトに関与した最大の共同研究の成果です。 BLOOMは1760億のパラメータを持ち、46の自然言語と13のプログラミング言語でテキストを生成することができます。スペイン語、フランス語、アラビア語などのほとんどすべての言語において、BLOOMはこれまでに作成された1000億以上のパラメータを持つ最初の言語モデルとなります。これは、70以上の国と250以上の機関から1000人以上の研究者が関与した1年の作業の集大成であり、フランスのパリ南部にあるJean ZayスーパーコンピュータでのBLOOMモデルのトレーニングは、フランスの研究機関CNRSとGENCIからの推定300万ユーロ相当の計算助成金によって可能になりました。 研究者は今やBLOOMをダウンロードして実行し、最新の大規模言語モデルの性能と動作を、最も深い内部操作まで調査することができます。また、ビッグサイエンスプロジェクト自体で開発されたモデルの責任あるAIライセンスの条件に同意する個人や機関は、ローカルマシンやクラウドプロバイダ上でモデルを使用し、拡張することができます。この協力と継続的な改善の精神のもと、トレーニングの中間チェックポイントと最適化器の状態も初めて公開します。8つのA100を使って遊ぶ余裕がありませんか?現在はGoogleのTPUクラウドにバックアップされた推論APIとモデルのFLAXバージョンも提供されており、迅速なテスト、プロトタイピング、および小規模な使用が可能です。Hugging Face Hubで既に試すことができます。 これはまだ始まりに過ぎません。BLOOMの機能は、ワークショップがモデルを実験し、調整し続けることでさらに向上していきます。私たちは、以前の努力であるT0++と同様にBLOOMを指示可能にするための作業を開始し、さらに言語を追加し、モデルをより使いやすいバージョンに圧縮し、より複雑なアーキテクチャの出発点として使用する予定です… 1000億以上のパラメータモデルの力を持つ実験のすべてが、現在は可能です。BLOOMは、成長するモデルの種であり、一度きりのモデルではありません。私たちは、それを拡大するためのコミュニティの取り組みをサポートする準備ができています。

文のトランスフォーマーを使用してプレイリスト生成器を構築する
数時間前に、Sentence TransformersとGradioを使用して構築したプレイリスト生成器を公開しました。それに続いて、プロジェクトを効果的な学習体験として活用する方法について考察しました。しかし、実際にプレイリスト生成器をどのように構築したのでしょうか?この投稿では、そのプロジェクトを解説し、埋め込みの生成方法と多段階のGradioデモの構築方法について説明します。 以前のHugging Faceブログの記事でも探求したように、Sentence Transformers(ST)は文の埋め込みを生成するためのツールを提供するライブラリです。使用できる歌詞のデータセットにアクセスできたため、STの意味的検索機能を活用して与えられたテキストプロンプトからプレイリストを生成することにしました。具体的には、プロンプトから埋め込みを作成し、その埋め込みを事前生成された歌詞の埋め込みセット全体で意味的検索に使用し、関連するソングのセットを生成することでした。これはすべて、Hugging Face Spacesでホストされた新しいBlocks APIを使用したGradioアプリに包括されます。 Gradioのやや高度な使用方法について説明しますので、ライブラリに初めて取り組む方は、この投稿のGradio固有の部分に取り組む前に、Blocksの紹介を読むことをお勧めします。また、歌詞のデータセットは公開しませんが、Hugging Face Hubで歌詞の埋め込みを試すことができます。それでは、始めましょう! 🪂 Sentence Transformers:埋め込みと意味的検索 埋め込みはSentence Transformersの鍵です!以前の記事で埋め込みが何であり、どのように生成するかについて学びましたので、この投稿を続ける前にそれをチェックすることをお勧めします。 Sentence Transformersには、事前学習された埋め込みモデルの大規模なコレクションがあります!独自のトレーニングデータを使用してこれらのモデルを微調整するチュートリアルも用意されていますが、多くのユースケース(歌詞のコーパスを対象とした意味的検索など)では、事前学習されたモデルが問題なく機能します。ただし、利用可能な埋め込みモデルが非常に多いため、どれを使用するかをどのように知ることができるのでしょうか? STのドキュメントでは、多くの選択肢が強調されており、評価メトリックといくつかの使用ケースの説明も示されています。MS MARCOモデルはBing検索エンジンのクエリでトレーニングされていますが、他のドメインでも優れたパフォーマンスを発揮するため、このプロジェクトではこれらのいずれかを選択することができると判断しました。プレイリスト生成器に必要なのは、いくつかの意味的な類似性を持つ曲を見つけることであり、特定のパフォーマンス指標に達成することにはあまり興味がないため、sentence-transformers/msmarco-MiniLM-L-6-v3を任意に選びました。 STの各モデルには、設定可能な入力シーケンス長があります(最大値まで)。その後、入力は切り捨てられます。私が選んだモデルは最大シーケンス長が512ワードピースであり、これは歌を埋め込むのに十分ではないことがわかりました。幸いなことに、歌詞をモデルが解析できるように小さなチャンクに分割する簡単な方法があります。それは、詩です!歌を詩に分割し、各詩を埋め込んだ後、検索がはるかに優れた結果を示すことになります。 歌は詩に分割され、それぞれの詩は埋め込まれます。 実際に埋め込みを生成するには、Sentence Transformersモデルの.encode()メソッドを呼び出し、文字列のリストを渡すだけです。その後、埋め込みを好きな方法で保存できます。この場合は、pickle形式で保存することにしました。…

BLOOMトレーニングの技術背後
近年、ますます大規模な言語モデルの訓練が一般的になってきました。これらのモデルがさらなる研究のために公開されていない問題は頻繁に議論されますが、そのようなモデルを訓練するための技術やエンジニアリングについての隠された知識は滅多に注目されません。本記事では、1760億パラメータの言語モデルBLOOMを例に、そのようなモデルの訓練の裏側にあるハードウェアとソフトウェアの技術とエンジニアリングについて、いくつかの光を当てることを目指しています。 しかし、まず、この素晴らしい1760億パラメータモデルの訓練を可能にするために貢献してくれた企業や主要な人物やグループに感謝したいと思います。 その後、ハードウェアのセットアップと主要な技術的な構成要素について説明します。 以下はプロジェクトの要約です: 人々 このプロジェクトは、Hugging Faceの共同創設者でありCSOのThomas Wolf氏が考案しました。彼は巨大な企業と競争し、単なる夢だったものを実現し、最終的な結果をすべての人にアクセス可能にすることで、最も多くの人々にとっては夢であったものを実現しました。 この記事では、モデルの訓練のエンジニアリング側に特化しています。BLOOMの背後にある技術の最も重要な部分は、私たちにコーディングと訓練の助けを提供してくれた専門家の人々と企業です。 感謝すべき6つの主要なグループがあります: HuggingFaceのBigScienceチームは、数人の専任の従業員を捧げ、訓練を始めから終わりまで行うための方法を見つけるために、Jean Zayの計算機を超えるすべてのインフラストラクチャを提供しました。 MicrosoftのDeepSpeedチームは、DeepSpeedを開発し、後にMegatron-LMと統合しました。彼らの開発者たちはプロジェクトのニーズに多くの時間を費やし、訓練前後に素晴らしい実践的なアドバイスを提供しました。 NVIDIAのMegatron-LMチームは、Megatron-LMを開発し、私たちの多くの質問に親切に答えてくれ、一流の実践的なアドバイスを提供しました。 ジャン・ゼイのスーパーコンピュータを管理しているIDRIS / GENCIチームは、計算リソースをプロジェクトに寄付し、優れたシステム管理のサポートを提供しました。 PyTorchチームは、このプロジェクトのために基礎となる非常に強力なフレームワークを作成し、訓練の準備中に私たちをサポートし、複数のバグを修正し、PyTorchコンポーネントの使いやすさを向上させました。 BigScience Engineeringワーキンググループのボランティア プロジェクトのエンジニアリング側に貢献してくれたすべての素晴らしい人々を全て挙げることは非常に困難なので、Hugging Face以外のいくつかの主要な人物を挙げます。彼らはこのプロジェクトのエンジニアリングの基盤となりました。 Olatunji Ruwase、Deepak…

敵対的なデータを使用してモデルを動的にトレーニングする方法
ここで学ぶこと 💡ダイナミックな敵対的データ収集の基本的なアイデアとその重要性。 ⚒敵対的データを動的に収集し、モデルをそれらでトレーニングする方法 – MNIST手書き数字認識タスクを例に説明します。 ダイナミックな敵対的データ収集(DADC) 静的ベンチマークは、モデルの性能を評価するための広く使用されている方法ですが、多くの問題があります:飽和していたり、バイアスがあったり、抜け穴があったりし、研究者が指標の増加を追い求める代わりに、信頼性のあるモデルを構築することができません1。 ダイナミックな敵対的データ収集(DADC)は、静的ベンチマークのいくつかの問題を緩和する手法として大いに期待されています。DADCでは、人間が最先端のモデルを騙すための例を作成します。このプロセスには次の2つの利点があります: ユーザーは、自分のモデルがどれだけ堅牢かを評価できます。 より強力なモデルをさらにトレーニングするために使用できるデータを提供します。 このように騙し、敵対的に収集されたデータでモデルをトレーニングするプロセスは、複数のラウンドにわたって繰り返され、人間と合わせてより堅牢なモデルが得られるようになります1。 敵対的データを使用してモデルを動的にトレーニングする ここでは、ユーザーから敵対的なデータを動的に収集し、それらを使用してモデルをトレーニングする方法を説明します – MNIST手書き数字認識タスクを使用します。 MNIST手書き数字認識タスクでは、28×28のグレースケール画像の入力から数字を予測するようにモデルをトレーニングします(以下の図の例を参照)。数字の範囲は0から9までです。 画像の出典:mnist | Tensorflow Datasets このタスクは、コンピュータビジョンの入門として広く認識されており、標準(静的)ベンチマークテストセットで高い精度を達成するモデルを簡単にトレーニングすることができます。しかし、これらの最先端のモデルでも、人間がそれらを書いてモデルに入力したときに正しい数字を予測するのは難しいとされています:研究者は、これは静的テストセットが人間が書く非常に多様な方法を適切に表現していないためだと考えています。したがって、人間が敵対的なサンプルを提供し、モデルがより一般化するのを助ける必要があります。 この手順は以下のセクションに分けられます: モデルの設定 モデルの操作…

Nyström形式:ニュストローム法による線形時間とメモリでのセルフアテンションの近似
はじめに トランスフォーマーは、さまざまな自然言語処理やコンピュータビジョンのタスクで優れた性能を発揮しています。その成功は、自己注意メカニズムによるものであり、入力のすべてのトークン間のペアワイズな相互作用を捉えることができます。しかし、標準の自己注意メカニズムは、入力シーケンスの長さ n n n (ここで n n n は入力シーケンスの長さ)に対して O ( n 2 ) O(n^2) O ( n 2 ) の時間とメモリの複雑さを持ち、長い入力シーケンスでのトレーニングには高コストです。 Nyströmformer は、標準の自己注意を…

プライベートハブのご紹介:機械学習を活用した新しいビルド方法
機械学習は、企業が技術を構築する方法を変えつつあります。革新的な新製品のパワーを供給し、私たちが使い慣れて愛している既知のアプリケーションにスマートな機能を提供することから、MLは開発プロセスの中心にあります。 しかし、すべての技術の変化には新たな課題が伴います。 機械学習モデルの約90%が本番環境に到達しないとされています。馴染みのないツールや非標準的なワークフローがMLの開発を遅くしています。モデルやデータセットが内部で共有されないため、同じような成果物がチーム間で常にゼロから作成されます。データサイエンティストは、ビジネスステークホルダーに技術的な作業を示すのが難しく、正確でタイムリーなフィードバックを共有するのに苦労しています。そして、機械学習チームはDocker/Kubernetesや本番環境向けのモデル最適化に時間を浪費しています。 これらを考慮して、私たちはPrivate Hub(PH)を立ち上げました。機械学習の構築方法を革新する新しい方法です。研究から本番環境まで、セキュアかつコンプライアンスを確保しながら、機械学習ライフサイクルの各ステップを加速するための統合されたツールセットを提供します。PHはさまざまなMLツールを一つにまとめることで、機械学習の協力をよりシンプルで楽しく、生産的にします。 このブログ投稿では、Private Hubとは何か、なぜ役立つのか、そしてどのようにお客様がそれを使用してMLのロードマップを加速しているのかについて詳しく説明します。 一緒に読んでいただくか、興味を引くセクションにジャンプしてください 🌟: ハグフェースハブとは何ですか? プライベートハブとは何ですか? 企業はプライベートハブをどのように使用してMLのロードマップを加速しているのでしょうか? さあ、始めましょう! 🚀 1. ハグフェースハブとは何ですか? プライベートハブについて詳しく説明する前に、まずハグフェースハブについて見てみましょう。これはPHの中心的な要素です。 ハグフェースハブは、オープンソースで公開されているオンラインプラットフォームで、人々が簡単に協力してMLを構築できる場所です。ハブは、機械学習と一緒に技術を探求し、実験し、協力し、構築するための中心的な場所として機能します。 ハグフェースハブでは、次のようなMLアセットを作成または発見することができます: モデル:NLP、コンピュータビジョン、音声、時系列、生物学、強化学習、化学などの最新の最先端モデルをホスティング。 データセット:さまざまなドメイン、モダリティ、言語に対応したデータの幅広いバリエーション。 スペース:ブラウザ内で直接MLモデルをショーケースするインタラクティブなアプリ。 ハブにアップロードされた各モデル、データセット、またはスペースは、Gitベースのリポジトリです。これはすべてのファイルを含むバージョン管理された場所で、従来のgitコマンドを使用してファイルをプル、プッシュ、クローン、操作することができます。モデル、データセット、およびスペースのコミット履歴を表示し、誰がいつ何を行ったかを確認することができます。 モデルのコミット履歴…

プロキシマルポリシーオプティマイゼーション(PPO)
Deep Reinforcement Learning ClassのUnit 8、Hugging Faceと共に 🤗 ⚠️ この記事の新しい更新版はこちらで利用可能です 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learning Classの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ⚠️ この記事の新しい更新版はこちらで利用可能です 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learning Classの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 前のユニットでは、Advantage…
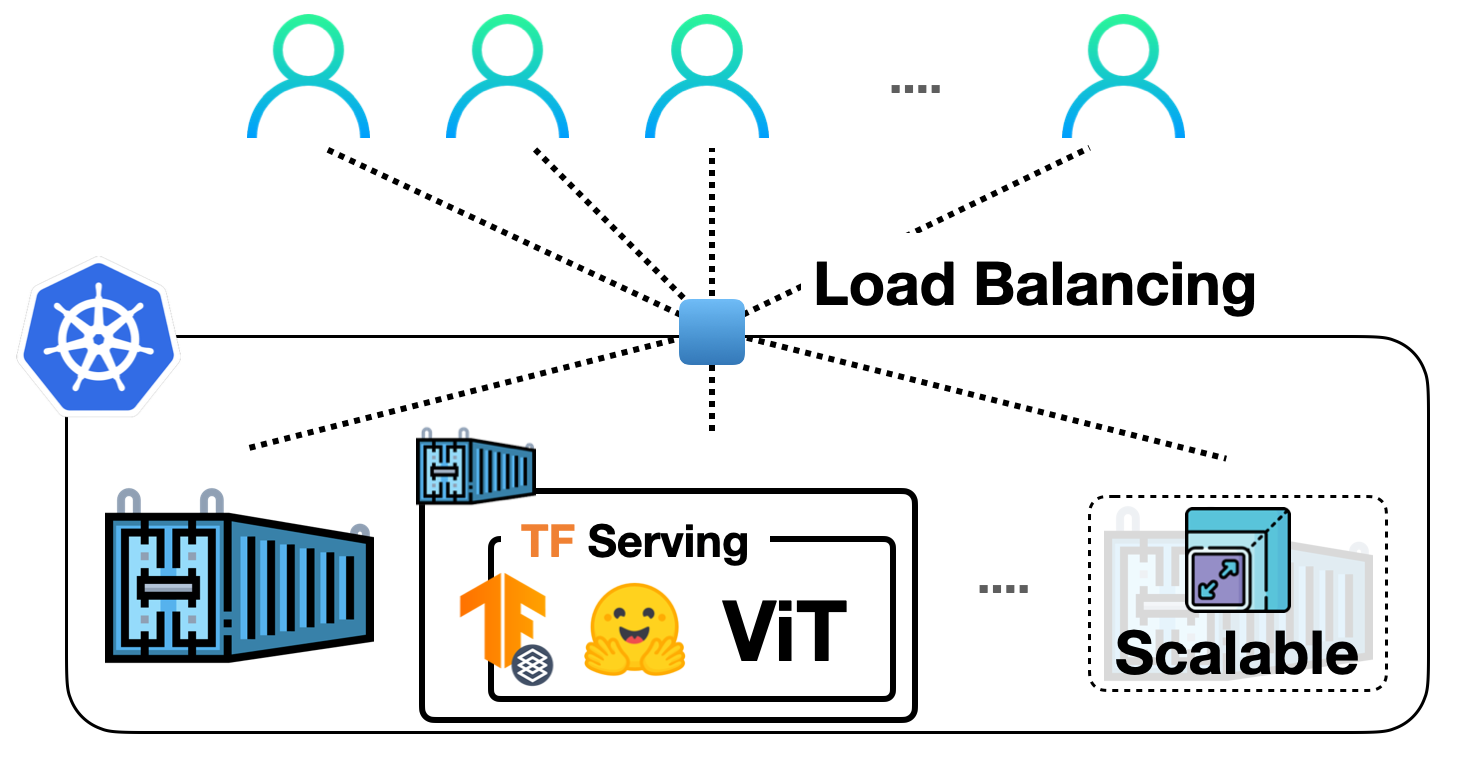
TF Servingを使用してKubernetes上に🤗 ViTをデプロイする
前の投稿では、TensorFlow Servingを使用して🤗 TransformersからVision Transformer(ViT)モデルをローカルに展開する方法を示しました。ビジョントランスフォーマーモデル内での埋め込み前処理および後処理操作、gRPCリクエストの処理など、さまざまなトピックをカバーしました! ローカル展開は、有用なものを構築するための優れたスタート地点ですが、実際のプロジェクトで多くのユーザーに対応できる展開を実行する必要があります。この投稿では、前の投稿のローカル展開をDockerとKubernetesでスケーリングする方法を学びます。したがって、DockerとKubernetesに関する基本的な知識が必要です。 この投稿は前の投稿に基づいていますので、まずそれをお読みいただくことを強くお勧めします。この投稿で説明されているコードは、このリポジトリで確認することができます。 私たちの展開をスケールアップする基本的なワークフローは、次のステップを含みます: アプリケーションロジックのコンテナ化:アプリケーションロジックには、リクエストを処理して予測を返すサービスモデルが含まれます。コンテナ化するために、Dockerが業界標準です。 Dockerコンテナの展開:ここにはさまざまなオプションがあります。最も一般的に使用されるオプションは、DockerコンテナをKubernetesクラスターに展開することです。Kubernetesは、展開に便利な機能(例:自動スケーリングとセキュリティ)を提供します。ローカルでKubernetesクラスターを管理するためのMinikubeのようなソリューションや、Elastic Kubernetes Service(EKS)のようなサーバーレスソリューションを使用することもできます。 SagemakerやVertex AIのような、MLデプロイメント固有の機能をすぐに利用できる時代に、なぜこのような明示的なセットアップを使用するのか疑問に思うかもしれません。それは考えるのは当然です。 上記のワークフローは、業界で広く採用され、多くの組織がその恩恵を受けています。長年にわたってすでに実戦投入されています。また、複雑な部分を抽象化しながら、展開に対してより細かな制御を持つことができます。 この投稿では、Google Kubernetes Engine(GKE)を使用してKubernetesクラスターをプロビジョニングおよび管理することを前提としています。GKEを使用する場合、請求を有効にしたGCPプロジェクトが既にあることを想定しています。また、GKEで展開を行うためにgcloudユーティリティを構成する必要があります。ただし、Minikubeを使用する場合でも、この投稿で説明されているコンセプトは同様に適用されます。 注意:この投稿で表示されるコードスニペットは、gcloudユーティリティとDocker、kubectlが構成されている限り、Unixターミナルで実行できます。詳しい手順は、付属のリポジトリで入手できます。 サービングモデルは、生のイメージ入力をバイトとして処理し、前処理および後処理を行うことができます。 このセクションでは、ベースのTensorFlow Servingイメージを使用してそのモデルをコンテナ化する方法を示します。TensorFlow Servingは、モデルをSavedModel形式で消費します。前の投稿でSavedModelを取得した方法を思い出してください。ここでは、SavedModelがtar.gz形式で圧縮されていることを前提としています。万が一必要な場合は、ここから入手できます。その後、SavedModelは<MODEL_NAME>/<VERSION>/<SavedModel>という特別なディレクトリ構造に配置する必要があります。これにより、TensorFlow Servingは異なるバージョンのモデルの複数の展開を同時に管理できます。 Dockerイメージの準備…

Skopsの紹介
Skopsの紹介 Hugging Faceでは、オープンソースの機械学習に関するさまざまな問題に取り組んでおり、モデルの安全なホスティングや公開、再現性、説明可能性、コラボレーションなどを可能にしています。私たちは、新しいライブラリ「Skops」をご紹介できることを大変嬉しく思っています!Skopsを使用すると、scikit-learnモデルをHugging Face Hubにホストしたり、モデルのドキュメント用のモデルカードを作成したり、他の人と共同作業したりすることができます。 まず、モデルをトレーニングしてから、Skopsを使用してステップバイステップでsklearnを本番環境で活用する方法を見ていきましょう。 # ライブラリをインポートしましょう import sklearn from sklearn.datasets import load_breast_cancer from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split # データをロードして分割します…

🧨ディフューザーを使用した安定した拡散
…🧨 ディフューザーを使用して Stable Diffusionは、CompVis、Stability AI、およびLAIONの研究者とエンジニアによって作成されたテキストから画像への潜在的な拡散モデルです。これは、LAION-5Bデータベースのサブセットから512×512の画像でトレーニングされています。LAION-5Bは現在存在する最大の、自由にアクセス可能な多様性のあるデータセットです。 この記事では、Stable Diffusionと🧨 ディフューザーのライブラリを使用する方法、モデルの動作の説明、およびディフューザーを使用して画像生成パイプラインをカスタマイズする方法について説明します。 注意:ディフュージョンモデルの動作原理を基本的に理解することを強くお勧めします。ディフュージョンモデルが完全に新しいものである場合、次のブログ記事のいずれかを読むことをお勧めします: 注釈付きディフュージョンモデル 🧨 ディフューザーの始め方 それでは、いくつかの画像を生成しましょう 🎨。 Stable Diffusionの実行 ライセンス モデルを使用する前に、モデルのライセンスを受け入れて重みをダウンロードして使用する必要があります。 注意:ライセンスはもはやUIを介して明示的に受け入れる必要はありません。 このライセンスは、このような強力な機械学習システムの潜在的な有害な影響を緩和するために設計されています。ユーザーには、ライセンスを完全かつ注意深く読むことをお願いします。以下に要約を提供します: モデルを意図的に違法または有害な出力やコンテンツの生成や共有に使用することはできません。 生成した出力に対する権利は主張しません。使用は自由であり、使用に関してはライセンスで設定された規定に違反してはならず、その使用については責任があります。 重みを再配布し、モデルを商業的および/またはサービスとして使用することができます。ただし、その場合、ライセンスで設定された使用制限とCreativeML OpenRAIL-Mのコピーをすべてのユーザーに提供する必要があります。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.