Learn more about Search Results A - Page 797

- You may be interested
- 「あなたがその仕事を手に入れることを保...
- スラヴァ・マデルスカ、ヘルステック起業...
- 「Googleのジェミニを使い始める方法はこ...
- 文の補完のための言語モデル
- 「30/10から5/11までの週の、トップで重要...
- アップルの研究者がDeepPCRを公開:通常は...
- 「データベース間でSQLの実行順序が異なる...
- 大規模言語モデルとは何ですか?
- 「Google.orgの新しい助成金は、永久凍土...
- 「競合するアジェンダがオンラインコンテ...
- NVIDIAの創設者兼CEO、ジェンセン・ファン...
- 新しい人工知能(AI)の研究アプローチは...
- ドローンが風力タービンを氷から保護する
- 「RAGとLLM:動的言語モデリングの新たな...
- 複雑なAIモデルの解読:パデュー大学の研...

機械学習でパワーアップした顧客サービス
このブログ投稿では、実際の顧客サービスのユースケースをシミュレートし、Hugging Faceエコシステムの機械学習ツールを使用してそれに対処します。 強くお勧めするのは、このノートブックをテンプレート/例として使用して、あなた自身の実世界のユースケースを解決することです。 タスク、データセット、モデルの定義 実際のコーディングに取り掛かる前に、自動化または一部自動化したいユースケースの明確な定義を持つことが重要です。ユースケースの明確な定義は、最適なタスク、使用するデータセット、および適用するモデルを特定するのに役立ちます。 NLPタスクの定義 では、自然言語処理モデルを使用して解決したい仮想的な問題について考えてみましょう。私たちは製品を販売しており、顧客サポートチームはフィードバック、クレーム、質問を含む数千のメッセージを受け取っています。理想的には、これらのメッセージにすべて返答する必要があります。 すぐに明らかになるのは、顧客サポートがすべてのメッセージに返信することは不可能であるということです。したがって、私たちは最も不満な顧客にのみ返信し、これらのメッセージに100%回答することを決定します。それらは中立的なメッセージや肯定的なメッセージと比べて最も緊急性があると考えられるためです。 非常に不満な顧客のメッセージが全メッセージの一部であると仮定し、不満なメッセージを自動的にフィルタリングできるとすると、顧客サポートはこの目標を達成できるはずです。 不満なメッセージを自動的にフィルタリングするために、自然言語処理技術を適用する予定です。 最初のステップは、私たちのユースケース(不満なメッセージのフィルタリング)を機械学習タスクにマッピングすることです。 Hugging Face Hubのタスクページは、与えられたシナリオに最も適したタスクを確認するための素晴らしい場所です。各タスクには詳細な説明と潜在的な使用例があります。 最も不満な顧客のメッセージを見つけるタスクは、テキスト分類のタスクとしてモデル化できます。メッセージを次の5つのカテゴリのいずれかに分類します:非常に不満、不満、中立、満足、または非常に満足。 適切なデータセットの見つけ方 タスクを決定したら、次にモデルをトレーニングするためのデータを見つける必要があります。これはユースケースのパフォーマンスにとって通常はモデルアーキテクチャを選ぶよりも重要です。モデルはトレーニングされたデータの質によってのみ優れた性能を発揮します。したがって、データセットの選択と作成には非常に注意が必要です。 不満なメッセージのフィルタリングという仮想的なユースケースを考えると、使用可能なデータセットを見てみましょう。 実際のユースケースでは、おそらくNLPシステムが処理する実際のデータを最もよく表す内部データがあるでしょう。したがって、そのような内部データをNLPシステムのトレーニングに使用するべきです。ただし、モデルの汎用性を向上させるために公開されているデータも含めることは役立ちます。 Hugging Face Hubの利用可能なデータセットをすべて見てみましょう。左側にはタスクカテゴリやより具体的なタスクに基づいてデータセットをフィルタリングできます。私たちのユースケースはテキスト分類 -> 感情分析に対応しているので、これらのフィルタを選択しましょう。このノートブックの執筆時点では、約80のデータセットが残ります。データセットを選ぶ際には、次の2つの側面を評価する必要があります:…

機械学習洞察のディレクター
機械学習のテーブルの席は、技術的なスキル、問題解決能力、ビジネスの洞察力など、ディレクターのような役職にしかないものです。 機械学習および/またはデータサイエンスのディレクターは、しばしばMLシステムの設計、数学の深い知識、MLフレームワークの熟知、リッチなデータアーキテクチャの理解、実世界のアプリケーションへのMLの適用経験、優れたコミュニケーションスキルを持つことが求められます。また、業界の最新動向に常に精通していることも期待されています。これは大変な注文です! これらの理由から、私たちはこのユニークなMLディレクターのグループにアクセスし、ヘルスケアからファイナンス、eコマース、SaaS、研究、メディアなど、さまざまな産業における彼らの現在のMLの洞察と業界のトレンドについての記事シリーズを作成しました。たとえば、あるディレクターは、MLを使用して空の空転トラック運転(約20%の時間が発生)をわずか19%に減らすことで、約10万人のアメリカ人の炭素排出量を削減できると指摘しています。注意:これは元ロケット科学者によって行われた即興の計算ですが、私たちはそれを受け入れます。 この最初のインストールでは、地中に埋まった地雷を検出するために地中レーダーを使用している研究者、元ロケット科学者、ツォンカ語に堪能なアマチュアゲーマー(クズ=こんにちは!)、バン生活を送っていた科学者、まだ実践的な高性能データサイエンスチームのコーチ、関係性、家族、犬、ピザを大切にするデータ実践者など、豊富なフィールドの洞察を持つ機械学習ディレクターの意見を紹介します。 🚀 さまざまな産業における機械学習ディレクターのトップと出会い、彼らの見解を聞いてみましょう: アーキ・ミトラ – Buzzfeedの機械学習ディレクター 背景:ビジネスにおけるMLの約束にバランスをもたらす。プロセスよりも人。希望よりも戦略。AIの利益よりもAIの倫理。ブラウン・ニューヨーカー。 興味深い事実:ツォンカ語を話すことができます(Googleで検索してください!)そしてYouth for Sevaを支援しています。 Buzzfeed:デジタルメディアに焦点を当てたアメリカのインターネットメディア、ニュース、エンターテイメント会社。 1. MLがメディアにポジティブな影響を与えたのはどのような点ですか? 顧客のためのプライバシー重視のパーソナライゼーション:すべてのユーザーは個別であり、長期的な関心事は安定していますが、短期的な関心事は確率的です。彼らはメディアとの関係がこれを反映することを期待しています。ハードウェアアクセラレーションの進歩と推奨のためのディープラーニングの組み合わせにより、この微妙なニュアンスを解読し、ユーザーに適切なコンテンツを適切なタイミングで適切なタッチポイントで提供する能力が解き放たれました。 メディア製作者のための支援ツール:メディアにおける制作者は限られた資産ですが、MLによる人間-ループアシストツールにより、彼らの創造的な能力を保護し、協力的なマシン-人間のフライホイールを解き放つことができました。適切なタイトル、画像、ビデオ、および/またはコンテンツに合わせて自動的に提案するだけの簡単なことでも、協力的なマシン-人間のフライホイールを解き放つことができます。 テストの締め付け:資本集約型のメディアベンチャーでは、ユーザーの共感を得る情報を収集する時間を短縮し、即座に行動する必要があります。ベイジアンテクニックのさまざまな手法と強化学習の進歩により、時間だけでなくそれに関連するコストも大幅に削減することができました。 2. メディア内の最大のMLの課題は何ですか? プライバシー、編集の声、公平な報道:メディアは今以上に民主主義の重要な柱です。MLはそれを尊重し、他のドメインや業界では明確に考慮されない制約の中で操作する必要があります。編集によるカリキュレーションされたコンテンツとプログラミングとMLによる推奨のバランスを見つけることは、依然として課題です。BuzzFeedにとってももう1つのユニークな課題は、インターネットは自由であるべきだと信じているため、他の企業とは異なり、ユーザーを追跡していないことです。 3. メディアへのMLの統合を試みる際に、よく見かける間違いは何ですか?…
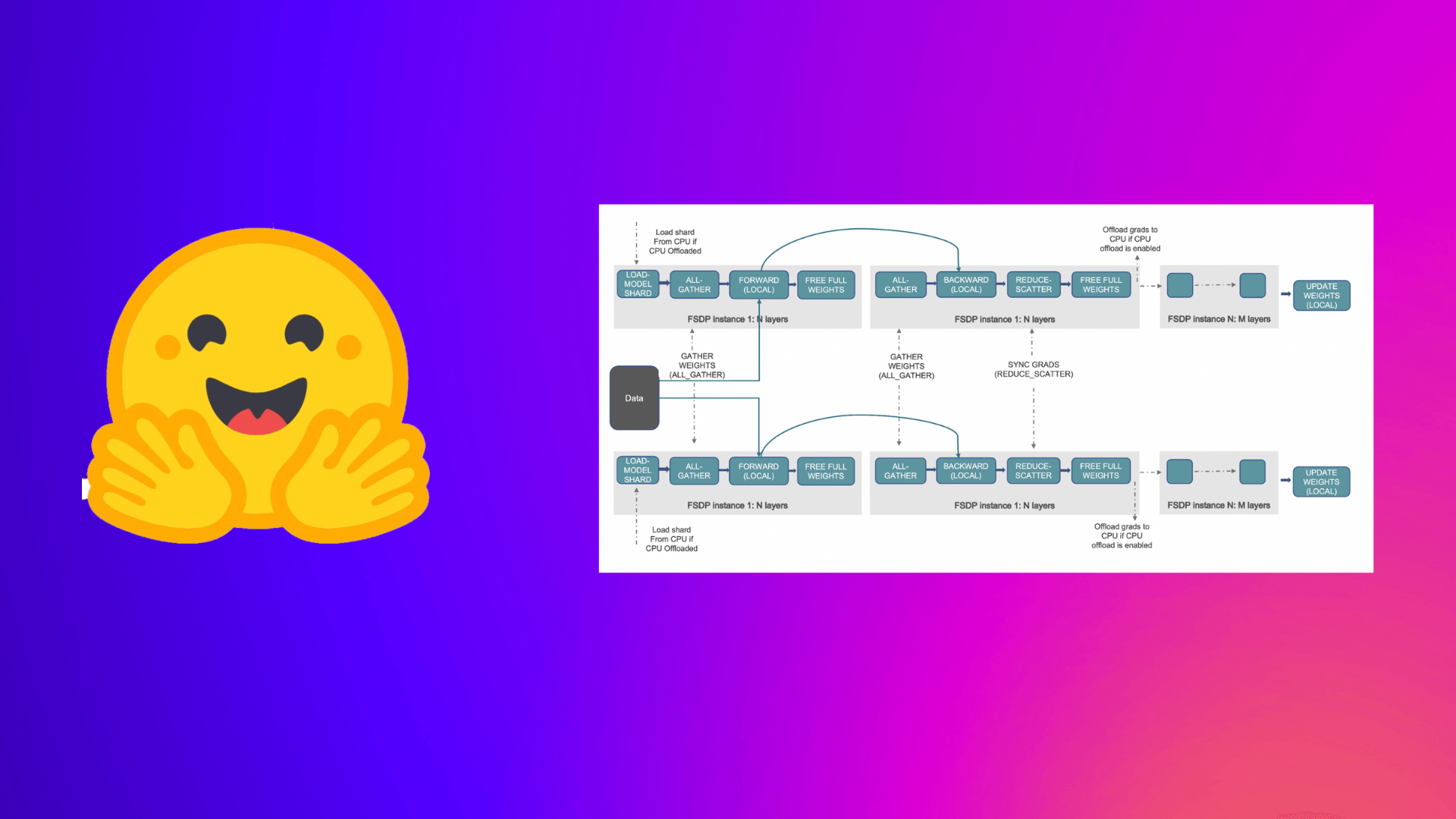
PyTorch完全にシャーディングされたデータパラレルを使用して、大規模モデルのトレーニングを加速する
この投稿では、Accelerate ライブラリを活用して大規模なモデルのトレーニングを行う方法について説明します。これにより、ユーザーは PyTorch FullyShardedDataParallel (FSDP) の最新機能を活用することができます。 機械学習 (ML) モデルのスケール、サイズ、およびパラメータがますます増加するにつれ、ML プラクティショナーは自身のハードウェア上でそのような大規模なモデルをトレーニングしたり、ロードしたりすることが困難になっています。 一方で、大規模なモデルは小さなモデルと比較して学習が速く(データと計算効率が高く)、パフォーマンスも著しく向上することがわかっています [1]。しかし、そのようなモデルをほとんどの利用可能なハードウェア上でトレーニングすることは困難です。 大規模なMLモデルをトレーニングするためには、分散トレーニングが重要です。 分散トレーニング の分野では、最近重要な進展がありました。最も注目すべき進展のいくつかは以下のとおりです: ZeROを用いたデータ並列化 – Zero Redundancy Optimizer [2] ステージ1:データ並列ワーカー/ GPU間でオプティマイザーの状態を分割 ステージ2:データ並列ワーカー/…

深層強化学習の概要
Hugging FaceとのDeep Reinforcement Learningクラスの第1章 ⚠️ この記事の新しい更新版はこちらでご覧いただけます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learningクラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ⚠️ この記事の新しい更新版はこちらでご覧いただけます 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learningクラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 人工知能の最も魅力的なトピックへようこそ: Deep Reinforcement Learning(深層強化学習) Deep RLは、エージェントが行動を実行し、結果を観察することで、環境内でどのように振る舞うかを学習する機械学習の一種です。…

私たちは、オープンかつ協力的な機械学習のために1億ドルを調達しました 🚀
今日は、素晴らしいニュースをお伝えします!Hugging Faceは、Lux CapitalをリードとするシリーズCの資金調達で1億ドルを調達しました🔥🔥🔥。Sequoia、Coatue、そして既存の投資家であるAddition、a_capital、SV Angel、Betaworks、AIX Ventures、Kevin Durant、Thirty Five VenturesのRich Kleiman、Datadogの共同設立者兼CEOであるOlivier Pomelなどが主要な出資者となっています。 2018年にPyTorch BERTをオープンソース化して以来、私たちは長い道のりを歩んできましたが、まだ始まったばかりです!🙌 機械学習は、技術を構築するためのデフォルトの方法になりつつあります。1日の平均を考えてみると、機械学習はあらゆるところにあります:Zoomの背景、Googleでの検索、Uberの利用、オートコンプリート機能を使用したメールの作成など、すべてが機械学習です。 Hugging Faceは、現在最も急成長しているコミュニティであり、機械学習のための最も使用されているプラットフォームです!自然言語処理、コンピュータビジョン、音声、時系列、生物学、強化学習、化学などのための100,000以上の事前学習モデルと10,000以上のデータセットをホストしており、Hugging Face Hubは、最先端のモデルを作成、共同作業、展開するための機械学習のホームとなっています。 10,000以上の企業がHugging Faceを使用して機械学習による技術を構築しています。彼らの機械学習科学者、データサイエンティスト、機械学習エンジニアは、私たちの製品とサービスの助けを借りて、数え切れないほどの時間を節約し、機械学習のロードマップを加速させています。 私たちはAI分野にポジティブな影響を与えたいと考えています。より責任あるAIの進展は、モデル、データセット、トレーニング手順、評価指標をオープンに共有し、問題を解決するために協力することを通じて実現されると考えています。オープンソースとオープンサイエンスは、信頼性、堅牢性、再現性、継続的なイノベーションをもたらします。これを念頭に、私たちはBigScienceをリードしています。これは、1,000人以上の研究者が集まり、非常に大きな言語モデルの研究と作成を行う協力的なワークショップです。そして、私たちは現在、世界最大のオープンソースの多言語言語モデルのトレーニングを行っています🌸 ⚠️ しかし、まだ大量の作業が残されています。 Hugging Faceでは、機械学習にはバイアス、プライバシー、エネルギー消費などの重要な制約と課題があることを認識しています。オープンさ、透明性、協力を通じて、これらの課題を緩和するための責任ある包括的な進歩、理解、および説明責任を促進することができます。…

最適なパイプラインとトランスフォーマーパイプラインによる高速推論
推論は、Hugging Face TransformersパイプラインをサポートしてOptimumに追加されました。これには、ONNX Runtimeを使用したテキスト生成も含まれます。 BERTとTransformersの採用はますます拡大しています。Transformerベースのモデルは、自然言語処理だけでなく、コンピュータビジョン、音声、時間系列でも最先端の性能を発揮しています。💬 🖼 🎤 ⏳ 企業は、Transformerモデルを大規模なワークロードに使用するため、実験および研究フェーズから本番フェーズに移行しています。ただし、デフォルトでは、BERTおよびその関連製品は、従来の機械学習アルゴリズムと比較して、比較的遅くて大きくて複雑なモデルです。 この課題を解決するために、私たちはOptimumを作成しました。これは、BERTなどのTransformerモデルのトレーニングと推論を高速化するためのHugging Face Transformersの拡張機能です。 このブログ投稿では、次のことを学びます: 1. Optimumとは何ですか?ELI5 2. 新しいOptimum推論とパイプラインの機能 3. RoBERTaの質問応答を加速するためのエンドツーエンドチュートリアル、量子化、最適化を含む 4. 現在の制限事項 5. Optimum推論FAQ 6.…

学生アンバサダープログラムの応募受付が開始されました!
オープンソースの企業であり、機械学習の民主化を目指すHugging Faceは、世界中のさまざまなバックグラウンドを持つ人々にオープンソースの機械学習を教えることが不可欠だと考えています。 2023年までに500万人に機械学習を教えることを目指しています。 あなたは機械学習を勉強していますか、または既にコミュニティで機械学習を普及させていますか? Hugging Faceと一緒に機械学習の民主化の取り組みに参加し、キャンパスコミュニティにHugging Faceを使用したMLモデルの構築方法を紹介したいですか? もしもそうであれば、私たちはあなたの取り組みをサポートするために、初の学生アンバサダープログラムを立ち上げます 🤗 🥳 以下のことをしたい場合は、学生アンバサダープログラムは素晴らしい機会です。 仲間をサポートして彼らの機械学習の道を手助けする 無料でオープンソースの技術を学び使う 繁栄するエコシステムに貢献する コミュニティの価値観を共有しながらコミュニティを育てることに熱心である 学生アンバサダープログラムはあなたにとって絶好の機会です。応募期限は2022年6月13日までです! プログラムへの参加のメリットは何ですか? 🤩 選ばれたアンバサダーは以下のリソースとサポートを受けることができます: 🎎 コラボレーションできる仲間のネットワーク。 🧑🏻💻 Hugging Faceチームからのワークショップとサポート!…

ハギングフェイスフェローシッププログラムの発表
フェローシップは、さまざまなバックグラウンドを持つ優れた人々のネットワークであり、機械学習のオープンソースエコシステムに貢献しています🚀。このプログラムの目標は、主要な貢献者に力を与え、彼らの影響力をスケールさせると同時に、他の人々にも貢献を促すことです。 フェローシップの仕組み 🙌🏻 これはHugging Faceが貢献者の素晴らしい仕事をサポートしています!フェローであることは、すべての人にとって異なる方法で機能します。重要な質問は次のとおりです: ❓ 貢献者がより大きな影響を持つためには何が必要ですか? Hugging Faceは彼らが常にやりたかったプロジェクトを実現できるようにどのようにサポートできますか? あらゆるバックグラウンドのフェローを歓迎します!機械学習の進歩は草の根の貢献に依存しています。それぞれの人には、さまざまな方法でこの分野を民主化するために使用できる独自のスキルと知識があります。それぞれのフェローは異なる方法で影響を与え、それは完璧です🌈。 Hugging Faceは彼らが最も必要とする方法で創造し、共有し続けることをサポートします。 フェローシップに参加することの利点は何ですか? 🤩 利点は個々の興味に基づきます。Hugging Faceがフェローをサポートする例をいくつか紹介します: 💾 コンピューティングとリソース 🎁 マーチャンダイズと資産。 ✨ Hugging Faceからの公式な認知。 フェローになるには…

Q-学習入門 第1部への紹介
ハギングフェイスと一緒に行うディープ強化学習クラスのユニット2、パート1 🤗 ⚠️ この記事の新しいバージョンがこちらで利用可能です 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 ⚠️ この記事の新しいバージョンがこちらで利用可能です 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はディープ強化学習クラスの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご覧ください。 このクラスの第1章では、強化学習(RL)、RLプロセス、およびRL問題を解決するための異なる手法について学びました。また、最初のランダーエージェントをトレーニングして、月面に正しく着陸させ、Hugging Face Hubにアップロードしました。 今日は、強化学習のメソッドの一つである価値ベースの手法について詳しく掘り下げて、最初のRLアルゴリズムであるQ-Learningを学びます。 また、スクラッチから最初のRLエージェントを実装し、2つの環境でトレーニングします: Frozen-Lake-v1(滑りにくいバージョン):エージェントは凍ったタイル(F)の上を歩き、穴(H)を避けて、開始状態(S)からゴール状態(G)へ移動する必要があります。 自動タクシーは、都市をナビゲートすることを学び、乗客をポイントAからポイントBまで輸送する必要があります。 このユニットは2つのパートに分かれています: 第1部では、価値ベースの手法とモンテカルロ法と時間差学習の違いについて学びます。 そして、第2部では、最初のRLアルゴリズムであるQ-Learningを学び、最初のRLエージェントを実装します。 このユニットは、Deep Q-Learning(ユニット3)で作業できるようになるためには基礎となるものです。これは最初のDeep…

研究ライフサイクルの中心に倫理的な原則を置く
倫理規定 – マルチモーダルプロジェクト 倫理規定の目的 機械学習の研究や応用は「データプライバシーの問題、アルゴリズムのバイアス、自動化のリスク、悪意のある利用」(NeurIPS 2021倫理ガイドライン)を引き起こす可能性があることがよく文献化されています。この短い文書の目的は、私たち(Hugging Faceのマルチモーダル学習グループ)が追求しているプロジェクトに対して採用する倫理原則を明確化することです。プロジェクトの初めにこれらの倫理原則を定義することで、それらを機械学習のライフサイクルの中核に位置づけます。 プロジェクトで行っている意思決定、システムのどの側面に取り組んでいるか、チームへの連絡方法について透明性を持ち、プロセスの早い段階でフィードバックを受けることで、意味のある変更を行い、目標とする目標と取り込むべき価値観を意識した選択についての議論を行いたいと考えています。 この文書は、Hugging Faceのマルチモーダル学習グループ(機械学習研究者とエンジニアで構成される)による議論の結果であり、倫理の実施、データガバナンス、個人のプライバシーに関する複数の専門家の貢献を受けています。 この倫理規定の制約 この文書は進行中の作業であり、2022年5月の反省の状態を反映しています。現時点では「倫理的なAI」についての合意や公式の定義は存在せず、私たちの考えも時間とともに変わる可能性が非常に高いです。更新がある場合は、GitHubを通じて変更を直接反映し、変更の理由と更新履歴を提供します。この文書は倫理的なAIのベストプラクティスについての真実の情報源とすることを意図していません。私たちは、不完全ではあるが、研究の影響、予見される潜在的な害、およびこれらの害を緩和するために取ることができる戦略について考えることが、機械学習コミュニティにとって正しい方向に進むと信じています。プロジェクト全体を通じて、この文書で説明されている価値観をどのように実施しているか、およびプロジェクトの文脈で観察される利点と制約を文書化します。 コンテンツポリシー 最先端のマルチモーダルシステムを研究することで、私たちはこのプロジェクトの一環として目指す技術の悪用をいくつか予測しています。以下は、最終的に防止したい使用例に関するガイドラインを提供しています: 暴力、嫌がらせ、いじめ、害、憎悪、差別など、人に害を及ぼす性質のコンテンツや活動の宣伝。性別、人種、年齢、能力の状態、LGBTQA+の指向、宗教、教育、社会経済的地位、その他の敏感なカテゴリ(性差別/女性嫌悪、カースト制度、人種差別、障害差別、トランスフォビア、同性愛嫌悪)に基づく特定のアイデンティティのサブポピュレーションに対する偏見。 規制、プライバシー、著作権、人権、文化的権利、基本的権利、法律、およびその他の文書の侵害。 個人を特定できる情報の生成。 責任を持たずに虚偽の情報を生成し、他の人を傷つける目的で行うこと。 医療、法律、金融、移民などの高リスク領域でのモデルの無謀な使用 – これらは基本的に人々の生活を損なう可能性があります。 プロジェクトの価値観 透明性を持つ:私たちは意図、データの情報源、ツール、および意思決定について透明性を持ちます。透明性を持つことで、私たちはコミュニティに自分たちの作業の弱点を公開し、責任を持ち、説明責任を果たすことができます。 オープンで再現可能な作業を共有する:オープン性にはプロセスと結果の2つの側面があります。データ、ツール、実験条件の正確な説明を共有することは、良い研究の実践だと考えています。ツールやモデルのチェックポイントを含む研究資源は、すべての人に差別なく(宗教、民族、性的指向、性別、政治的指向、年齢、能力など)、対象範囲内で使用できるようにアクセスできるようにする必要があります。私たちは、研究が機械学習研究コミュニティ以外の観客にも簡単に説明できるようにすることをアクセシビリティと定義しています。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.