Learn more about Search Results A - Page 796

- You may be interested
- 「ユネスコ、AIチップの埋め込みに関する...
- 効果的な小規模言語モデル:マイクロソフ...
- 「CMUの研究者がBUTD-DETRを導入:言語発...
- 「Pythonにおけるコードゴルフ:簡潔なプ...
- 「LeNetのマスタリング:アーキテクチャの...
- Plotlyを使用してマッププロットを作成す...
- 「NVIDIAのAIが地球を気候変動から救う」
- バイデン大統領がAI実行命令を発布し、安...
- 「React開発者にとってのAI言語モデルの力...
- 視覚のない人のための音声ビジョン
- 清華大学の研究者たちは、メタラーニング...
- 3つの質問:大規模言語モデルについて、Ja...
- 「トランスフォーマーの簡素化:理解でき...
- 「AIと著作権に関する公開意見募集中の米...
- GPT-4のプロンプト効果の比較:Dash、Pane...
データ測定ツールのご紹介:データセットを見るためのインタラクティブツール
要約:データセットを構築し、測定し、比較するためのオンラインツールを作成しました。 🤗データ計測ツールにアクセスするには、ここをクリックしてください。 機械学習データセットの急成長する統一リポジトリの開発者として(Lhoest et al. 2021)、🤗Hugging Faceチームはデータセットのドキュメント化のための良い実践をサポートするために取り組んできました(McMillan-Major et al. 2021)。静的(進化する可能性のある)ドキュメントはこの方向性への必要な第一歩を表しますが、データセットの実際の内容を理解するには、動機付けのある計測とそれに対する対話的な可視化能力が必要です。 そのため、私たちはオープンソースのPythonライブラリとノーコードインターフェースである🤗データ計測ツールを紹介します。これは、私たちのデータセットとSpaces Hubsを使用して、優れたStreamlitツールと組み合わせて、データセットの理解、構築、キュレーション、比較を支援するために使用することができます。 🤗データ計測ツールとは何ですか? データ計測ツール(DMT)は、データセットの作成者やユーザーが責任あるデータ開発のために有意義で役立つメトリクスを自動的に計算できるインタラクティブなインターフェースおよびオープンソースライブラリです。 なぜこのツールを作成したのですか? 機械学習データセットの綿密なキュレーションと分析は、AIの開発においてしばしば見落とされています。AIにおける「ビッグデータ」の現在の標準(Luccioni et al. 2021, Dodge et al. 2021)は、さまざまなウェブサイトから収集されたデータを使用しており、異なるデータソースが具体的に何を表しているか、それらがモデルの学習にどのように影響するかについてはほとんど注意が払われていません。データセットの注釈手法は、開発者の目標に合ったデータセットのキュレーションに役立つことがありますが、これらのデータセットのさまざまな側面を「測定する」ための手法はかなり限られています(Sambasivan et…

🤗 Hubでのスーパーチャージド検索
huggingface_hubライブラリは、ホスティングエンドポイント(モデル、データセット、スペース)を探索するためのプログラム的なアプローチを提供する軽量なインタフェースです。 これまでは、このインタフェースを介してハブでの検索は難しく、ユーザーは「知っているだけ」で慣れなければならない多くの側面がありました。 この記事では、huggingface_hubに追加されたいくつかの新機能を紹介し、ユーザーにJupyterやPythonインタフェースを離れずに使用したいモデルやデータセットを検索するためのフレンドリーなAPIを提供します。 始める前に、システムに最新バージョンのhuggingface_hubライブラリがない場合は、次のセルを実行してください: !pip install huggingface_hub -U 問題の位置づけ: まず、自分がどのようなシナリオにいるか想像してみましょう。テキスト分類のためにハブでホストされているすべてのモデルを見つけたいとします。これらのモデルはGLUEデータセットでトレーニングされ、PyTorchと互換性があります。 https://huggingface.co/models を単に開いてそこにあるウィジェットを使用することもできます。しかし、これによりIDEを離れて結果をスキャンする必要がありますし、必要な情報を得るためにはいくつかのボタンクリックが必要です。 もしもIDEを離れずにこれを解決する方法があったらどうでしょうか?プログラム的なインタフェースであれば、ハブを探索するためのワークフローにも簡単に組み込めるかもしれません。 ここでhuggingface_hubが登場します。 このライブラリに慣れている方は、すでにこの種のモデルを検索できることを知っているかもしれません。しかし、クエリを正しく取得することは試行錯誤の痛ましいプロセスです。 それを簡略化することはできるでしょうか?さあ、見てみましょう! 必要なものを見つける まず、HfApiをインポートします。これはHugging Faceのバックエンドホスティングと対話するのに役立つクラスです。モデル、データセットなどを通じて対話することができます。さらに、いくつかのヘルパークラスもインポートします:ModelFilterとModelSearchArguments from huggingface_hub import HfApi, ModelFilter,…

Pythonを使用した感情分析の始め方
感情分析は、データを感情に基づいてタグ付けする自動化されたプロセスです。感情分析により、企業はデータをスケールで分析し、洞察を検出し、プロセスを自動化することができます。 過去には、感情分析は研究者、機械学習エンジニア、または自然言語処理の経験を持つデータサイエンティストに限定されていました。しかし、AIコミュニティは最近、機械学習へのアクセスを民主化するための素晴らしいツールを開発しました。今では、わずか数行のコードを使って感情分析を行い、機械学習の経験が全くなくても利用することができます!🤯 このガイドでは、Pythonを使用した感情分析の始め方についてすべてを学びます。具体的には以下の内容です: 感情分析とは何か? Pythonで事前学習済みの感情分析モデルを使用する方法 独自の感情分析モデルを構築する方法 感情分析でツイートを分析する方法 さあ、始めましょう!🚀 1. 感情分析とは何ですか? 感情分析は、与えられたテキストの極性を特定する自然言語処理の技術です。感情分析にはさまざまなバリエーションがありますが、最も広く使用されている技術の1つは、データを「ポジティブ」、「ネガティブ」、または「ニュートラル」のいずれかにラベル付けするものです。たとえば、次のようなツイートを見てみましょう。@VerizonSupportをメンションしているものです: “dear @verizonsupport your service is straight 💩 in dallas.. been with y’all over…

BERT 101 – 最新のNLPモデルの解説
BERTとは何ですか? BERT(Bidirectional Encoder Representations from Transformers)は、自然言語処理のための機械学習(ML)モデルです。Google AI Languageの研究者によって2018年に開発され、感情分析や固有表現認識など、最も一般的な言語タスクの11以上に対するスイスアーミーナイフのような解決策として機能します。 言語は、コンピュータが「理解する」のが難しいものでした。もちろん、コンピュータはテキスト入力を収集、保存、読み取ることができますが、基本的な言語コンテキストが欠けています。 そこで、自然言語処理(NLP)が登場しました。これは、テキストや話された言葉からテキストを読み取り、分析し、解釈し、意味を導き出すための人工知能の分野です。この実践では、言語学、統計学、機械学習を組み合わせて、コンピュータが人間の言語を「理解する」のを支援します。 従来、個々のNLPタスクは、各具体的なタスクごとに作成された個別のモデルによって解決されてきました。それは、それまでの話。BERTの登場により、NLPの領域は革命を起こしました。BERTは、最も一般的なNLPタスクの11以上を解決することで、これまでのモデルよりも優れていることから、NLPのジャック・オブ・オール・トレードとなりました。 このガイドでは、BERTとは何か、なぜ異なるのか、BERTを使用し始める方法について学びます: BERTは何に使用されるのか? BERTはどのように動作するのか? BERTのモデルサイズとアーキテクチャ BERTの一般的な言語タスクでの性能 ディープラーニングの環境への影響 BERTのオープンソースの力 BERTを使用し始める方法 BERTのよくある質問 結論 さあ、始めましょう! 🚀 1.…
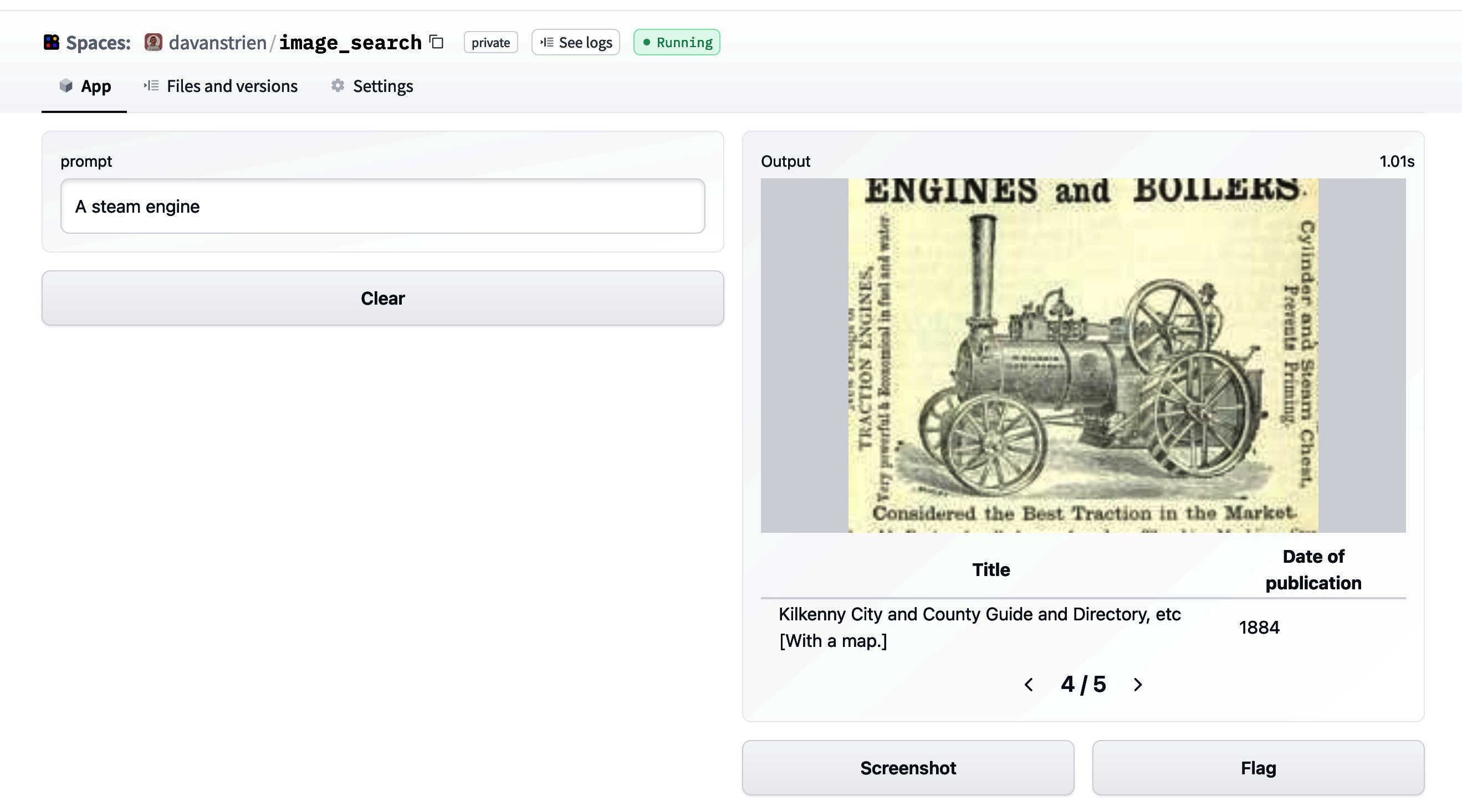
🤗データセットを使った画像検索
🤗 datasetsは、データセットに簡単にアクセスして共有することができるライブラリです。また、メモリに収まらないデータを効率的に処理することも容易にします。 datasetsが最初にリリースされた当初は、主にテキストデータと関連していました。しかし、最近では、datasetsは音声や画像に対するサポートを増やしています。特に、画像のためのdatasetsの機能タイプが追加されました。以前のブログ投稿では、datasetsと🤗 transformersを組み合わせて画像分類モデルのトレーニング方法を紹介しました。このブログ投稿では、datasetsと他のいくつかのライブラリを組み合わせて画像検索アプリケーションを作成する方法を見ていきます。 まず、datasetsをインストールします。画像を扱うために、pillowもインストールします。さらに、sentence_transformersとfaissも必要です。これらについては後ほど詳しく説明します。また、richもインストールします。ここでは簡単に使用するだけですが、非常に便利なパッケージなので、ぜひ詳しく探索してみてください! !pip install datasets pillow rich faiss-gpu sentence_transformers まずは、画像の特徴を見てみましょう。素晴らしいライブラリであるrichを使用して、Pythonオブジェクト(関数、クラスなど)を調べることができます。 from rich import inspect import datasets inspect(datasets.Image, help=True) ╭───────────────────────── <class 'datasets.features.image.Image'>…

カスタムデータセットでセマンティックセグメンテーションモデルを微調整する
このガイドでは、最先端のセマンティックセグメンテーションモデルであるSegformerのファインチューニング方法を紹介します。私たちの目標は、ピザ配達ロボットのためのモデルを構築することで、それによってロボットがどこに進むべきかを見ることができ、障害物を認識できるようにすることです 🍕🤖。最初に、Segments.aiで一連の歩道の画像にラベルを付けます。次に、🤗 transformersというオープンソースのライブラリを使用して、事前学習済みのSegFormerモデルをファインチューニングします。このライブラリは、最先端のモデルの簡単な実装を提供しています。このプロセスで、最大のオープンソースのモデルとデータセットのカタログであるHugging Face Hubの使用方法も学びます。 セマンティックセグメンテーションは、画像内の各ピクセルを分類するタスクです。これはより正確な画像の分類方法と見なすことができます。医療画像や自動運転など、さまざまな分野で幅広い用途があります。例えば、ピザ配達ロボットの場合、画像内の歩道がどこにあるか正確に知ることが重要です。 セマンティックセグメンテーションは分類の一種であるため、画像分類とセマンティックセグメンテーションに使用されるネットワークアーキテクチャは非常に似ています。2014年、Longらによる画像セグメンテーションのための異彩を放つ論文では、畳み込みニューラルネットワークが使用されています。最近では、画像分類にTransformers(例:ViT)が使用されており、最新のセマンティックセグメンテーションにも使用されており、最先端の技術をさらに押し上げています。 SegFormerは、2021年にXieらによって提案されたセマンティックセグメンテーションのモデルです。ポジションエンコーディングを使用しない階層的なトランスフォーマーエンコーダと、単純な多層パーセプトロンデコーダを持っています。SegFormerは、複数の一般的なデータセットで最先端の性能を実現しています。さあ、ピザ配達ロボットが歩道の画像でどのようにパフォーマンスを発揮するか見てみましょう。 必要な依存関係をインストールして始めましょう。データセットとモデルをHugging Face Hubにプッシュするために、Git LFSをインストールし、Hugging Faceにログインする必要があります。 git-lfsのインストール方法は、お使いのシステムによって異なる場合があります。Google ColabにはGit LFSが事前にインストールされていることに注意してください。 pip install -q transformers datasets evaluate segments-ai apt-get…

機械学習の専門家 – マーガレット・ミッチェル
みなさん、こんにちは!Machine Learning Expertsへようこそ。私は司会のBritney Mullerです。今日のゲストは、マーガレット・ミッチェル(通称メグ)です。メグはGoogleのEthical AIグループの創設者兼共同リーダーであり、機械学習の分野でのパイオニアであり、50以上の論文を発表しているだけでなく、Ethical AIの分野でのリーディングリサーチャーでもあります。 メグがエシカルAIの重要性に気づいた瞬間(素晴らしいストーリー!)、MLチームが有害なデータバイアスにより意識的になる方法、およびMLにおける包括性と多様性の力(およびパフォーマンスの利点)について話すことができます。 このパワフルなエピソードをご紹介できることをとても楽しみにしています!こちらがメグ・ミッチェルとの対談です: 転写: 注:転写はわかりやすい読みやすさを提供するためにわずかに修正/再フォーマットされています。 あなたの経歴とHugging Faceへの経緯について少し共有していただけますか? Dr. マーガレット・ミッチェルの経歴: Reed Collegeで言語学の学士号を取得 – NLPに取り組んだ 学士号取得後、補助および補完技術に取り組み、修士課程中も同様に研究 ワシントン大学で計算言語学の修士号を取得 コンピュータサイエンスの博士号を取得 メグ:私はJohns Hopkinsでポスドクとして統計的な研究を行い、その後、Microsoft Researchに移り、ビジョンから言語生成に取り組み、盲目の人々が世界をより簡単に移動できるようにするSeeing…
~自分自身を~ 繰り返さない
🤗 Transformersのデザイン哲学 「Don’t repeat yourself(同じことを繰り返さない)」、またはDRY(Don’t Repeat Yourself)は、ソフトウェア開発のよく知られた原則です。この原則は、「The pragmatic programmer」というコードデザインに関する最も読まれた本の1つから生まれました。この原則のシンプルなメッセージは明らかな意味を持っています。既に他の場所で存在するロジックを再書きする必要はありません。これにより、コードは同期され、メンテナンスが容易になり、より堅牢になります。この論理パターンへの変更は、依存関係のすべてに一様に影響を与えます。 Hugging FaceのTransformersライブラリの設計は、DRY原則とはまったく逆のものに見えるかもしれません。注意機構のコードは、異なるモデルファイルに50回以上もコピーされています。時にはBERTモデル全体のコードが他のモデルファイルにコピーされています。既存のモデルとほぼ同じ新しいモデルの貢献を強制的に行うことがよくありますが、それにはわずかな論理的な調整以外にも、すべての既存のコードをコピーする必要があります。なぜこれをやるのでしょうか?私たちは単に怠惰であるか、あるいは中心化された場所にすべての論理的な要素を集めることに圧倒されているのでしょうか? いいえ、私たちは怠惰ではありません。TransformersライブラリにDRYデザイン原則を適用しないというのは、非常に意識的な決定です。その代わりに、私たちは「シングルモデルファイル」ポリシーと呼ぶ別のデザイン原則を採用することにしました。シングルモデルファイルポリシーは、モデルの順方向パスに必要なすべてのコードが1つのファイル、つまりモデルファイルに含まれているというものです。推論でBERTがどのように機能するかを理解するためには、BERTのmodeling_bert.pyファイルを見ればよいだけです。異なるモデルの同一のサブコンポーネントを新しい中央集権化された場所に抽象化しようとする試みを通常は拒否します。すべての可能な注意メカニズムが含まれたattention_layer.pyを持つことはしたくありません。再び、なぜこれをやるのでしょうか? 短く言えば、その理由は次のとおりです: 1. Transformersはオープンソースコミュニティによって作られました。 2. 私たちの製品はモデルであり、顧客はモデルコードを読んだり調整したりするユーザーです。 3. 機械学習の世界は非常に速く進化しています。 4. 機械学習モデルは静的です。 1. オープンソースコミュニティによって作られました Transformersは、外部の貢献を積極的に促進するために作られています。貢献は通常、バグ修正または新しいモデルの貢献です。モデルファイルの1つでバグが見つかった場合、見つけた人が修正するのができるだけ簡単にすることを望んでいます。他のモデルの100のエラーを引き起こすことを見るのは、非常にやる気を削ぐことです。…

機械学習の専門家 – ルイス・タンストール
🤗 マシンラーニングエキスパートへようこそ – ルイス・タンストール こんにちは、みなさん!マシンラーニングエキスパートへようこそ。私は司会のブリトニー・ミュラーです。今日のゲストはルイス・タンストールさんです。ルイスさんはHugging Faceのマシンラーニングエンジニアで、トランスフォーマーを使ってビジネスプロセスを自動化し、MLOpsの課題を解決するための取り組みを行っています。 ルイスさんは、NLP、トポロジカルデータ解析、時系列の領域でスタートアップや企業向けに機械学習アプリケーションを開発してきました。 ルイスさんは、彼の新しい本、トランスフォーマー、大規模モデルの評価、MLエンジニアがより高速なレイテンシとスループットを目指すための最適化方法などについて話します。 以前は理論物理学者であり、仕事以外ではギターを弾いたり、トレイルランニングをしたり、オープンソースプロジェクトに貢献したりすることが好きです。 この楽しくて素晴らしいエピソードを紹介するのをとても楽しみにしています!ここで私がルイス・タンストールさんとの会話をお届けします。 注:転写はわかりやすい読みやすい体験を提供するために、わずかに修正/再フォーマットされています。 ようこそ、ルイスさん!お忙しい中、私との素晴らしいお仕事についてお話しいただき、本当にありがとうございます! ルイス: ありがとうございます、ブリトニーさん。こちらこそ、ここにいさせていただけて光栄です。 簡単な自己紹介と、Hugging Faceへの経緯について教えていただけますか? ルイス: 私をHugging Faceに導いたものはトランスフォーマーです。2018年、私はスイスのスタートアップでトランスフォーマーを使って仕事をしていました。最初のプロジェクトは、テキストを入力してそのテキスト内の質問に答えを見つけるためのモデルを訓練する質問応答のタスクでした。 当時のライブラリは「pytorch-pretrained-bert」という名前で、いくつかのスクリプトを持つ非常に特化したコードベースでした。私はトランスフォーマーについて何が起こっているのか全くわからず、オリジナルの「Attention Is All You Need」という論文を読んでも理解できませんでした。そこで他の学習リソースを探し始めました。…

CO2排出量と🤗ハブ:リーディング・ザ・チャージ
CO2排出量とは何であり、なぜ重要なのか? 気候変動は私たちが直面している最大の課題の一つであり、二酸化炭素(CO2)などの温室効果ガスの排出削減はこの問題に取り組む上で重要な役割を果たします。 機械学習モデルのトレーニングとデプロイメントには、コンピューティングインフラストラクチャのエネルギー使用によりCO2が排出されます。GPUからストレージまで、すべてが機能するためにエネルギーを必要とし、その過程でCO2を排出します。 写真:最近のTransformerモデルとそのCO2排出量 CO2の排出量は、実行時間、使用されるハードウェア、エネルギー源の炭素密度など、さまざまな要素に依存します。 以下に説明するツールを使用することで、自身の排出量を追跡および報告することができます(これは私たちのフィールド全体の透明性を向上させるために重要です!)また、モデルを選択する際にはそのCO2排出量に基づいて選択することができます。 Transformersを使用して自動的に自分のCO2排出量を計算する方法 始める前に、システムに最新バージョンのhuggingface_hubライブラリがインストールされていない場合は、以下を実行してください: pip install huggingface_hub -U Hugging Face Hubを使用して低炭素排出モデルを見つける方法 モデルがハブにアップロードされたことを考慮して、エコ意識を持ってハブ上のモデルを検索する方法はありますか?それには、huggingface_hubライブラリに新しい特別なパラメータemissions_thresholdがあります。最小または最大のグラム数を指定するだけで、その範囲内に含まれるすべてのモデルが検索されます。 たとえば、最大100グラムで作成されたすべてのモデルを検索できます: from huggingface_hub import HfApi api = HfApi()…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.