Learn more about Search Results A - Page 795

- You may be interested
- 宇宙探索と最先端技術
- People Analyticsは新しい大きなトレンド...
- データストレージの最適化:SQLにおけるデ...
- 物理情報を持つDeepONetによる逆問題の解...
- UCバークレーの研究者たちは、LLMCompiler...
- モデルインサイトの視覚化:ディープラー...
- 「Llama 2をローカルでダウンロードしてア...
- 「FraudGPTと出会ってください:ChatGPTの...
- このAI論文では、エッジコンピュータ上で...
- LLM(Language Model)をアプリケーション...
- Hugging FaceとGradioを使用して、5分でAI...
- Google AIは、埋め込みモデルのスケーラビ...
- 「ゲームからAIへ:NvidiaのAI革命におけ...
- 「全体的な実験の影響を推定する」
- 光ベースのコンピューティング革命:強化...

インターネット上でのディープラーニング:言語モデルの共同トレーニング
Quentin LhoestさんとSylvain Lesageさんの追加の助けを得ています。 現代の言語モデルは、事前学習に多くの計算リソースを必要とするため、数十から数百のGPUやTPUへのアクセスなしでは入手することが不可能です。理論的には、複数の個人のリソースを組み合わせることが可能かもしれませんが、実際には、インターネット上の接続速度は高性能GPUスーパーコンピュータよりも遅いため、このような分散トレーニング手法は以前は限定的な成功しか収めていませんでした。 このブログ記事では、参加者のネットワークとハードウェアの制約に適応することができる新しい協力的な分散トレーニング方法であるDeDLOCについて説明します。私たちは、40人のボランティアを使ってベンガル語の言語モデルであるsahajBERTの事前学習を行うことで、実世界のシナリオでの成功を示します。ベンガル語の下流タスクでは、このモデルは数百の高級アクセラレータを使用したより大きなモデルとほぼ同等のクオリティを実現しています。 オープンコラボレーションにおける分散深層学習 なぜやるべきなのか? 現在、多くの高品質なNLPシステムは大規模な事前学習済みトランスフォーマーに基づいています。一般的に、その品質はサイズとともに向上します。パラメータ数をスケールアップし、未ラベルのテキストデータの豊富さを活用することで、自然言語理解や生成において類を見ない結果を実現することができます。 残念ながら、これらの事前学習済みモデルを使用するのは、便利なだけではありません。大規模なデータセットでのトランスフォーマーのトレーニングに必要なハードウェアリソースは、一般の個人やほとんどの商業または研究機関には手の届かないものです。例えば、BERTのトレーニングには約7000ドルかかると推定され、GPT-3のような最大のモデルでは、この数は1200万ドルにもなります!このリソースの制約は明らかで避けられないもののように思えますが、広範な機械学習コミュニティにおいて事前学習済みモデル以外の代替手段は本当に存在しないのでしょうか? ただし、この状況を打破する方法があるかもしれません。解決策を見つけるために、周りを見渡すだけで十分かもしれません。求めている計算リソースは既に存在している可能性があるかもしれません。たとえば、多くの人々は自宅にゲームやワークステーションのGPUを搭載したパワフルなコンピュータを持っています。おそらく、私たちがFolding@home、Rosetta@home、Leela Chess Zero、または異なるBOINCプロジェクトのように、ボランティアコンピューティングを活用することで、彼らのパワーを結集しようとしていることはお分かりいただけるかもしれませんが、このアプローチはさらに一般的です。たとえば、いくつかの研究所は、自身の小規模なクラスタを結集して利用することができますし、低コストのクラウドインスタンスを使用して実験に参加したい研究者もいるかもしれません。 疑い深い考え方をすると、ここで重要な要素が欠けているのではないかと思うかもしれません。分散深層学習においてデータ転送はしばしばボトルネックとなります。複数のワーカーから勾配を集約する必要があるためです。実際、インターネット上での分散トレーニングへの単純なアプローチは必ず失敗します。ほとんどの参加者はギガビットの接続を持っておらず、いつでもネットワークから切断される可能性があるためです。では、家庭用のデータプランで何かをトレーニングする方法はどうすればいいのでしょうか? 🙂 この問題の解決策として、私たちは新しいトレーニングアルゴリズム、Distributed Deep Learning in Open Collaborations(またはDeDLOC)を提案しています。このアルゴリズムの詳細については、最近公開されたプレプリントで詳しく説明しています。では、このアルゴリズムの中核となるアイデアについて見てみましょう! ボランティアと一緒にトレーニングする 最も頻繁に使用される形態の分散トレーニングにおいては、複数のGPUを使用したトレーニングは非常に簡単です。ディープラーニングを行う場合、通常はトレーニングデータのバッチ内の多くの例について損失関数の勾配を平均化します。データ並列の分散DLの場合、データを複数のワーカーに分割し、個別に勾配を計算し、ローカルのバッチが処理された後にそれらを平均化します。すべてのワーカーで平均勾配が計算されたら、モデルの重みをオプティマイザで調整し、モデルのトレーニングを続けます。以下に、実行されるさまざまなタスクのイラストを示します。 多くの場合、同期の量を減らし、学習プロセスを安定化させるために、ローカルのバッチを平均化する前にNバッチの勾配を蓄積することができます。これは実際のバッチサイズをN倍にすることと同等です。このアプローチは、最先端の言語モデルのほとんどが大規模なバッチを使用しているという観察と組み合わせることで、次のようなシンプルなアイデアに至りました。各オプティマイザステップの前に、すべてのボランティアのデバイスをまたいで非常に大規模なバッチを蓄積しましょう!この方法は、通常の分散トレーニングと完全に等価であり、簡単にスケーラビリティを実現するだけでなく、組み込みの耐障害性も持っています。以下に、それを説明する例を示します。 共同の実験中に遭遇する可能性のあるいくつかの故障ケースを考えてみましょう。今のところ、最も頻繁なシナリオは、1人または複数の参加者がトレーニング手続きから切断されることです。彼らは不安定な接続を持っているか、単に自分のGPUを他の用途に使用したいだけかもしれません。この場合、トレーニングにはわずかな遅れが生じますが、これらの参加者の貢献は現在蓄積されているバッチサイズから差し引かれます。しかし、他の参加者が彼らの勾配でそれを補ってくれるでしょう。また、さらに多くの参加者が加わる場合、目標のバッチサイズは単純により速く達成され、トレーニング手続きは自然にスピードアップします。これを以下のビデオでデモンストレーションしています。…

スケールにおけるトランスフォーマーの最適化ツールキット、Optimumをご紹介します
この投稿は、Hugging Faceが最先端の機械学習プロダクションパフォーマンスを民主化するための旅の第一歩です。目指すところに到達するために、私たちはハードウェアパートナーと手を組んで取り組む予定です。以下のIntelと協力しています。この旅に参加して、新しいオープンソースライブラリであるOptimumをフォローしてください! なぜ 🤗 Optimum なのか? 🤯 Transformersのスケーリングは難しい Tesla、Google、Microsoft、Facebook、これらの企業に共通するものは何でしょうか?もちろんいくつかありますが、その1つは毎日数十億のTransformerモデルの予測を実行していることです。TeslaのAutoPilotのためのTransformer、Gmailの文章補完のためのTransformer、Facebookの投稿のリアルタイム翻訳のためのTransformer、Bingの自然言語クエリに対する回答のためのTransformerなど、さまざまな用途で使用されています。 Transformerは機械学習モデルの精度を飛躍的に向上させ、NLPを征服し、SpeechやVisionなどの他のモダリティにも広がっています。しかし、これらの巨大なモデルを本番環境に持ち込み、スケールで高速に実行することは、どの機械学習エンジニアリングチームにとっても大きな課題です。 上記の企業のように、数百人の高度に熟練した機械学習エンジニアを雇っていない場合はどうでしょうか?私たちの新しいオープンソースライブラリであるOptimumを通じて、Transformerのプロダクションパフォーマンスのための究極のツールキットを構築し、特定のハードウェア上でモデルをトレーニングおよび実行するための最大の効率性を実現することを目指しています。 🏭 OptimumがTransformerを活用します 最適なパフォーマンスでモデルをトレーニングおよび提供するためには、モデルのアクセラレーション技術は対象のハードウェアと互換性が必要です。各ハードウェアプラットフォームは、パフォーマンスに大きな影響を与える特定のソフトウェアツール、機能、ノブを提供しています。同様に、スパース化や量子化などの高度なモデルアクセラレーション技術を活用するためには、最適化されたカーネルがシリコン上の演算子と互換性があり、モデルアーキテクチャから派生したニューラルネットワークグラフに特化している必要があります。この3次元の互換性行列やモデルアクセラレーションライブラリの使用方法について詳しく調査するのは、ほとんどの機械学習エンジニアにとって困難な作業です。 Optimumはこの作業を簡単にすることを目指し、効率的なAIハードウェアを対象としたパフォーマンス最適化ツールを提供し、ハードウェアパートナーとの共同開発で機械学習エンジニアをML最適化の魔術師に変えます。 Transformerライブラリでは、最先端のモデルを研究者やエンジニアが簡単に使用できるようにし、フレームワーク、アーキテクチャ、パイプラインの複雑さを抽象化しました。 Optimumライブラリでは、エンジニアが利用可能なすべてのハードウェア機能を活用し、ハードウェアプラットフォーム上でのモデルアクセラレーションの複雑さを抽象化することで、エンジニアに簡単になります。 🤗 Optimumの実践:Intel Xeon CPU向けのモデルの量子化方法 🤔 量子化の重要性と正しい方法 BERTなどの事前学習済み言語モデルは、さまざまな自然言語処理タスクで最先端の結果を達成しており、ViTやSpeech2Textなどの他のTransformerベースのモデルも、コンピュータビジョンや音声タスクで最先端の結果を達成しています。Transformerは機械学習の世界で広く使われており、今後も使われ続けます。…

ハグフェイスでの夏
夏は公式に終わり、この数か月はHugging Faceでかなり忙しかったです。Hubの新機能や研究、オープンソースの開発など、私たちのチームはオープンで協力的な技術を通じてコミュニティを支援するために一生懸命取り組んできました。 このブログ投稿では、6月、7月、8月のHugging Faceで起こったすべてのことをお伝えします! この投稿では、私たちのチームが取り組んでいるさまざまな分野について取り上げていますので、最も興味のある部分にスキップすることを躊躇しないでください 🤗 新機能 コミュニティ オープンソース ソリューション 研究 新機能 ここ数か月で、Hubは10,000以上のパブリックモデルリポジトリから16,000以上のモデルに増えました!コミュニティの皆さんが世界と共有するために素晴らしいモデルをたくさん共有してくれたおかげです。そして、数字の背後には、あなたと共有するためのたくさんのクールな新機能があります! Spaces Beta ( hf.co/spaces ) Spacesは、ユーザープロファイルまたは組織hf.coプロファイルに直接機械学習デモアプリケーションをホストするためのシンプルで無料のソリューションです。GradioとStreamlitの2つの素晴らしいSDKをサポートしており、Pythonで簡単にクールなアプリを構築することができます。数分でアプリをデプロイしてコミュニティと共有することができます! 🚀 Spacesでは、シークレットの設定、カスタム要件の許可、さらにはGitHubリポジトリから直接管理することもできます。ベータ版にはhf.co/spacesでサインアップできます。以下はいくつかのお気に入りです! Chef Transformerの助けを借りてレシピを作成 HuBERTを使用して音声をテキストに変換…
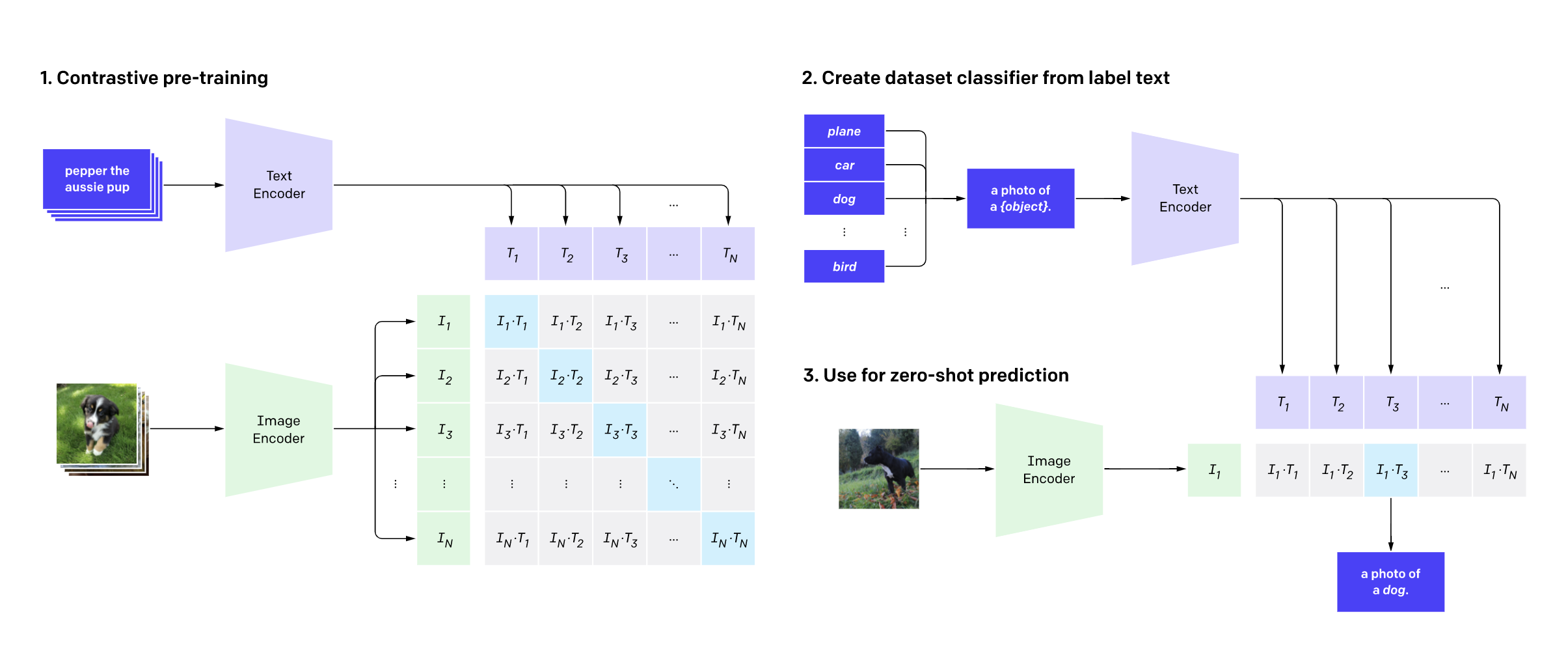
リモートセンシング(衛星)画像とキャプションを使用してCLIPの微調整
リモートセンシング(衛星)画像とキャプションを使用したCLIPの微調整 今年の7月、Hugging FaceはFlax/JAXコミュニティウィークを開催し、自然言語処理(NLP)とコンピュータビジョン(CV)の分野でHugging Faceトランスフォーマーモデルを訓練するプロジェクトの提出をコミュニティに呼びかけました。 参加者はFlaxとJAXを使用したTensor Processing Units(TPUs)を使用しました。JAXは線形代数ライブラリ(numpyのような)で、自動微分(Autograd)を行い、XLAにコンパイルできます。また、FlaxはJAX用のニューラルネットワークライブラリであり、エコシステムです。TPUの計算時間は、共同スポンサーであるGoogle Cloudが無料で提供しました。 その後の2週間で、チームはHugging FaceとGoogleの講義に参加し、JAX/Flaxを使用して1つ以上のモデルを訓練し、それらをコミュニティと共有し、モデルの機能を示すHugging Face Spacesデモを提供しました。約100チームが参加し、170のモデルと36のデモが生まれました。 私たちのチームは、おそらく他の多くのチームと同様に、12のタイムゾーンにまたがる分散型のチームです。私たちの共通点は、TWIML Slackチャンネルに所属していることであり、そこでは人工知能(AI)と機械学習(ML)のトピックに関心を持つメンバーが集まっています。 私たちは、OpenAIのCLIPネットワークをRSICDデータセットの衛星画像とキャプションで微調整しました。CLIPネットワークは、インターネット上で見つかる画像とキャプションのペアを使用して、自己教師ありの方法で視覚的な概念を学習します。推論中、モデルはテキストの説明に基づいて最も関連性の高い画像を予測するか、画像に基づいて最も関連性の高いテキストの説明を予測することができます。CLIPは、普段の画像に対してゼロショットで使用するには十分なパワフルです。しかし、衛星画像は普段の画像とは異なるため、CLIPを微調整することが有益であると考えました。私たちの直感は正しかったようで、評価結果(後述)が示すようになりました。この記事では、私たちのトレーニングと評価プロセスの詳細、およびこのプロジェクトへの今後の取り組みについて説明します。 私たちのプロジェクトの目標は、有用なサービスを提供し、CLIPを実用的なユースケースに使用する方法を示すことでした。私たちのモデルは、テキストクエリを使用して大規模な衛星画像のコレクションを検索するためにアプリケーションによって使用することができます。そのようなクエリは、画像全体を記述することができます(例:ビーチ、山、空港、野球場など)、またはこれらの画像内の特定の地理的または人工的な特徴を検索または言及することができます。CLIPは、他のドメインでも同様に微調整することができます。これは、医療画像のメディカルチームによって示されています。 テキストクエリを使用して大規模な画像コレクションを検索する能力は、非常に強力な機能であり、社会的な善だけでなく、悪意のある目的にも使用することができます。国家防衛や反テロ活動、気候変動の影響を管理可能な状態になる前に発見し対処する能力など、様々な応用が考えられます。ただし、この力は、権威主義的な国家による軍事や警察の監視などの目的で誤用される可能性もあるため、倫理的な問題も提起されます。 プロジェクトについては、プロジェクトページで詳細を読むことができます。また、独自のデータで推論に使用するために、トレーニング済みモデルをダウンロードすることもできます。デモでも実際の動作を確認することができます。 トレーニング データセット 私たちは、主にRSICDデータセットを使用してCLIPモデルを微調整しました。このデータセットは、Google Earth、Baidu Map、MapABC、Tiandituから収集された約10,000枚の画像から構成されています。このデータセットは、Exploring Models…
機械学習の時代がコードとして到来しました
2021年版のState of AIレポートが先週発表されました。そして、Kaggle State of Machine Learning and Data Science Surveyも同様です。これらのレポートには学びや議論の余地がたくさんありますが、いくつかのポイントが私の注意を引きました。 「AIはますます国家の電力網やパンデミック中の自動スーパーマーケットの倉庫計算など、ミッションクリティカルなインフラに適用されています。しかし、成熟度が急速に成長する展開の巨大さに追いついているかどうかについては疑問があります。」 機械学習を活用したアプリケーションがITのあらゆる分野に広がっていることは否定できません。しかし、それは企業や組織にとってどういう意味を持つのでしょうか?どのように堅牢な機械学習ワークフローを構築すれば良いのでしょうか?私たちは皆、100人のデータサイエンティストを採用すべきなのでしょうか?それとも100人のDevOpsエンジニアを採用すべきなのでしょうか? 「トランスフォーマーは、自然言語処理だけでなく、音声、コンピュータビジョン、さらにはタンパク質の構造予測など、機械学習の一般的なアーキテクチャとして登場しています。」 古参の人々は、ITには銀の弾丸はないということを痛感してきました。それでも、トランスフォーマーのアーキテクチャは、さまざまな機械学習タスクにおいて非常に効率的です。しかし、機械学習の革新の猛烈なペースにどうやってついていけば良いのでしょうか?これらの最先端モデルを活用するためには、本当に専門的なスキルが必要なのでしょうか?それとももっと短い道でビジネス価値を創出する方法があるのでしょうか? さて、私の考えはこうです。 マス向け機械学習! 機械学習はどこにでもあります、少なくともそうしようとしています。数年前、Forbesは「ソフトウェアが世界を食べた、今度はAIがソフトウェアを食べる」と書きましたが、これは実際にはどういう意味なのでしょうか?もし、それが機械学習モデルが何千行もの化石化した旧式のコードを置き換えるべきだという意味なら、私は全面賛成です。邪悪なビジネスルールよ、死ね! では、機械学習が実際にソフトウェアエンジニアリングを置き換えるということでしょうか?現在、AIが生成したコードについて幻想が広がっており、バグやパフォーマンスの問題を見つけるなど、いくつかの技術は確かに興味深いものです。しかし、開発者を廃止することは考えるべきではありませんし、むしろ多くの開発者を力強くサポートするために取り組むべきです。そうすれば、機械学習はただの別の退屈なITのワークロードになるでしょう(退屈なテクノロジーは素晴らしいです)。言い換えれば、私たちが本当に必要としているのは、ソフトウェアが機械学習を食べることなのです! 今回も変わらない 私は長年にわたり、ソフトウェアエンジニアリングの10年以上前のベストプラクティスがデータサイエンスや機械学習にも適用されると主張してきました。バージョン管理、再利用性、テスト可能性、自動化、デプロイメント、モニタリング、パフォーマンス、最適化などです。しばらくは孤独だったのですが、予想外にGoogleの連携がありました: 「機械学習は、あなたが偉大な機械学習の専門家ではなく、偉大なエンジニアとして機械学習を行うべきです。」- 『機械学習のルール』、Google また、車輪を再発明する必要はありません。DevOpsの運動はこれらの問題を10年以上前に解決しました。今や、データサイエンスと機械学習コミュニティは、これらの実証済みのツールとプロセスを遅延なく採用し、適応させるべきです。これが唯一の方法であり、本番環境で堅牢でスケーラブルかつ繰り返し可能な機械学習システムを構築することができます。もしMLOpsと呼ぶことが助けになるのなら、それも構いません:別のバズワードについて議論するつもりはありません。…
1Bのトレーニングペアで文埋め込みモデルをトレーニングする
文の埋め込みは、文を実数のベクトルにマッピングする手法です。理想的には、これらのベクトルは文の意味を捉え、高度に汎用的であるべきです。そのような表現は、クラスタリング、テキストマイニング、質問応答など、多くの下流アプリケーションで使用することができます。 私たちは、「1Bのトレーニングペアで最高の文埋め込みモデルをトレーニングするプロジェクト」として、最先端の文埋め込みモデルを開発しました。このプロジェクトは、Hugging Faceによって主催されたCommunity week using JAX/Flax for NLP & CVの一環として行われました。このプロジェクトでは、GoogleのFlax、JAX、およびCloudチームのメンバーから、効率的なディープラーニングフレームワークに関するガイダンスを受けました! トレーニング手法 モデル 単語とは異なり、有限の文の集合を定義することはできません。したがって、文の埋め込み手法では、内部の単語を組み合わせて最終的な表現を計算します。たとえば、SentenceBertモデル(Reimers and Gurevych, 2019)では、多くのNLPアプリケーションの基盤であるTransformerを使用し、コンテキスト化された単語ベクトルに対してプーリング操作を行います(以下の図を参照)。 マルチプルネガティブランキングロス 構成モジュールのパラメータは通常、自己教師ありの目的関数を使用して学習されます。このプロジェクトでは、以下の図で説明されているコントラスティブトレーニング方法を使用しました。文のペア(a_i, p_i)が意味的に近いペアであるデータセットを構成します。たとえば、(クエリ、回答パッセージ)、(質問、重複質問)、(論文タイトル、引用論文タイトル)などのペアを考慮します。その後、モデルは、ペア(a_i, p_i)を埋め込み空間で近いベクトルにマッピングするようにトレーニングされます。一方、非一致のペア(a_i, p_j)、i ≠ jは、埋め込み空間で遠いベクトルにマッピングされます。このトレーニング方法は、インバッチネガティブ、InfoNCE、またはNTXentLossとも呼ばれます。 形式的には、トレーニングサンプルのバッチが与えられた場合、モデルは以下の損失関数を最適化します:…
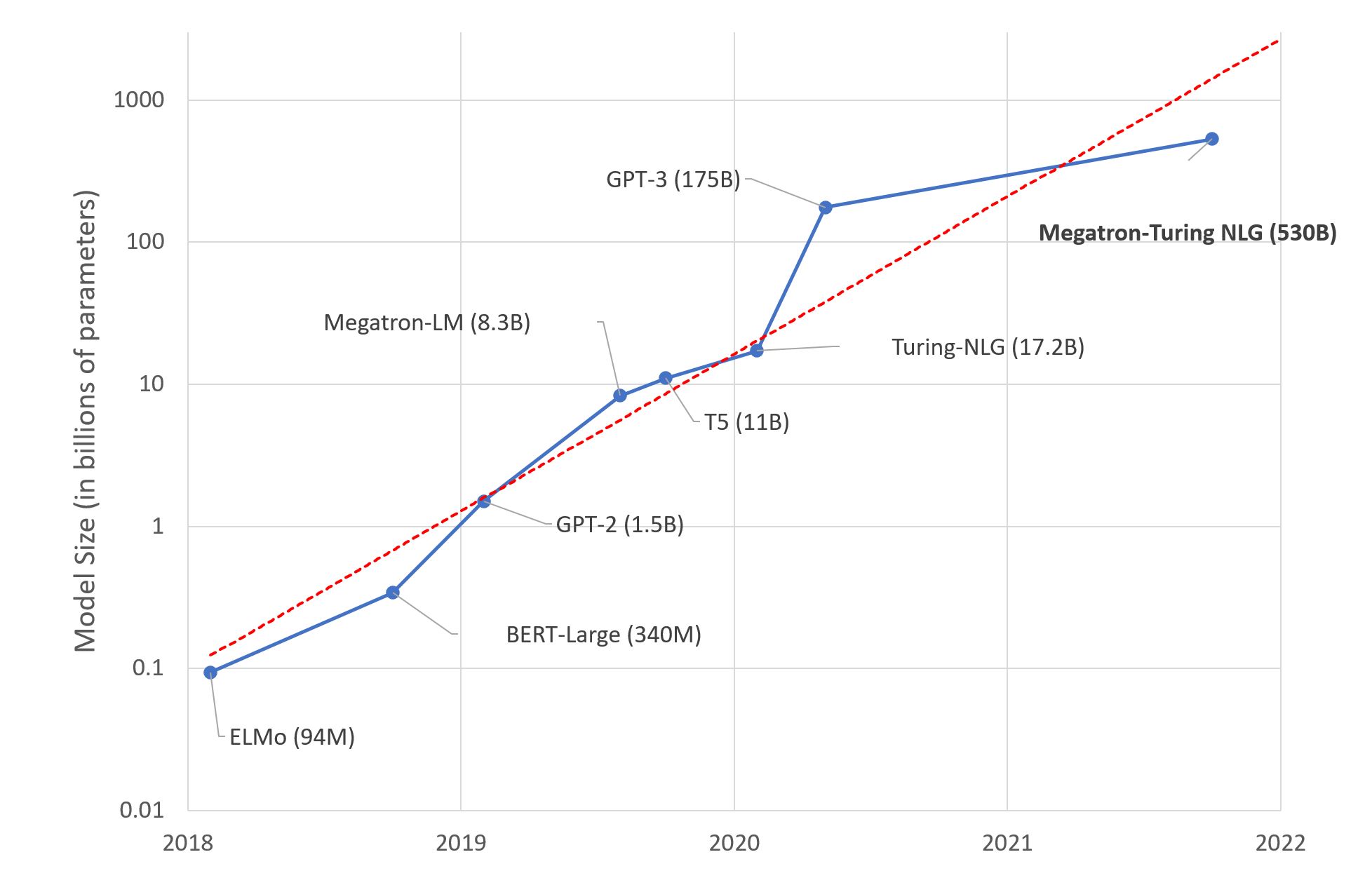
大規模言語モデル:新たなモーアの法則?
数日前、MicrosoftとNVIDIAは「世界最大かつ最もパワフルな生成言語モデル」と称される、Megatron-Turing NLG 530BというTransformerベースのモデルを発表しました。 これは、間違いなく機械学習エンジニアリングの印象的なデモンストレーションです。しかし、このメガモデルのトレンドに興奮すべきでしょうか?私自身はそう思いません。以下にその理由を説明します。 これがディープラーニングの脳です 研究者は、人間の脳が平均して860億個のニューロンと100兆個のシナプスを持つと推定しています。言語に特化しているわけではないことは明らかです。興味深いことに、GPT-4は約100兆個のパラメータを持つ予定です…この例えがどれほど不正確かもしれませんが、人間の脳と同じくらいの大きさの言語モデルを構築することが最善の長期的なアプローチなのか疑問に思わないでしょうか? もちろん、私たちの脳は進化の結果として何百万年もの間に生まれた驚異的なデバイスですが、ディープラーニングモデルは数十年しか存在していません。それでも、私たちの直感が何かが計算できないと感じるはずです。 ディープラーニング、深いポケット? 予想通り、巨大なテキストデータセットで5300億のパラメータを持つモデルをトレーニングするためには、相当なインフラストラクチャが必要です。実際に、MicrosoftとNVIDIAは数百台のDGX A100マルチGPUサーバーを使用しました。1台あたり199,000ドルで、ネットワーク機器やホスティングコストなども考慮すると、この実験を複製しようとする場合、1億ドル近く費やさなければなりません。それにつけてもフライドポテトはいかがでしょうか? 真剣に考えてみてください。どのようなビジネスケースを持つ組織が、ディープラーニングのインフラストラクチャに1億ドル、さらには1,000万ドルも費やす価値があるのでしょうか?ほとんどありません。では、これらのモデルは実際に誰のために存在するのでしょうか? その暖かい感覚はGPUクラスターです エンジニアリングの素晴らしさにもかかわらず、GPU上でのディープラーニングモデルのトレーニングは力技です。仕様書によると、各DGXサーバーは最大で6.5キロワット消費します。もちろん、データセンター(またはサーバールーム)には少なくとも同じくらいの冷却能力が必要です。あなたがスターク家であり、ウィンターフェルを冬の寒さから守る必要がある場合を除いて、これは別の問題です。 さらに、公衆の意識が気候変動や社会的責任の問題について高まるにつれ、組織は自らの炭素排出量を考慮する必要があります。2019年のマサチューセッツ大学の研究によれば、「GPU上でBERTをトレーニングすることは、アメリカ横断飛行とほぼ同等である」とされています。 BERT-Largeは3億4000万個のパラメータを持っています。Megatron-Turingの環境影響は計り知れません…私を知っている人たちは私を環境保護主義者とは呼ばないでしょうが、いくつかの数字は無視できません。 では? Megatron-Turing NLG 530Bや次に登場するどんなビーストに興奮していますか?いいえ。追加のコスト、複雑さ、環境への影響を考えると、(比較的小さい)ベンチマークの改善がその価値に見合っているとは思いません。これらの巨大モデルの構築と宣伝が組織の機械学習の理解と採用に役立っていると思いますか?いいえ。 私は何のためにこれらを行っているのか疑問に思っています。科学のための科学?昔ながらのマーケティング?技術的な優位性?おそらくそれぞれの要素が少しずつ関与しているでしょう。それらに任せておきましょう。 代わりに、高品質な機械学習ソリューションを構築するために皆さんが利用できる実用的で実行可能な技術に焦点を当てましょう。 事前学習済みモデルを使用する ほとんどの場合、カスタムのモデルアーキテクチャは必要ありません。カスタムのモデル(別のものですが)が必要な場合もありますが、それは専門家向けです。 始める良いポイントは、解決しようとしているタスクに対して事前学習されたモデルを探すことです(例えば、英語のテキストを要約するためのモデルなど)。…

コース開始コミュニティイベント
嬉しいお知らせです。Hugging Faceチームの多くの作業の結果、Hugging Faceコースのパート2が11月15日にリリースされます!パート1では、事前学習済みモデルの使用方法、テキスト分類タスクでの微調整、そして結果のモデルハブへのアップロードを教えることに焦点を当てました。パート2では、他の一般的なNLPタスクに焦点を当てます:トークン分類、言語モデリング(因果関係とマスク)、翻訳、要約、質問応答。また、Hugging Faceエコシステム全体について詳しく説明し、特に🤗データセットと🤗トークナイザーについても詳しく説明します。 このリリースに合わせて、コミュニティイベントを開催しますので、ぜひご参加ください!プログラムには2日間の講演が含まれ、その後、いかなるNLPタスクでもモデルの微調整に焦点を当てたチームプロジェクトが行われ、最後にこのようなライブデモが行われます。もし機械学習の新しい仕事を探している場合は、これらのデモはあなたのポートフォリオにうまく収まります。また、参加者全員には、それらの中から1つを構築することに成功した場合に修了証が送られます。 AWSはこのイベントをスポンサーしており、Amazon SageMakerを介して参加者に無料のコンピューティングを提供しています。 登録するには、このフォームに記入してください。以下に、2日間の講演の詳細をご紹介します。 1日目(11月15日):Transformerの概要とトレーニング方法の高レベルビュー 講演の初日は、Transformerモデルの高レベルなプレゼンテーションと、トレーニングや微調整に使用できるツールに焦点を当てます。 2日目(11月16日):使用するツール 2日目は、Hugging Face、Gradio、AWSチームによる講演に焦点を当て、使用するツールを紹介します。
モダンなCPU上でのBERTライクモデルの推論のスケーリングアップ – パート2
イントロダクション:CPU上でのAI効率を最適化するためのIntelソフトウェアの使用 前のブログ記事で詳細に説明したように、Intel Xeon CPUは、AVX512やVNNI(Vector Neural Network Instructions)などのAIワークロードに特に設計された機能を提供しており、整数量子化されたニューラルネットワークを使用した効率的な推論をサポートするための追加のシステムツールも提供しています。このブログ記事では、ソフトウェアの最適化に焦点を当て、Intelの新しいIce Lake世代のXeon CPUのパフォーマンスについて紹介します。私たちの目標は、Intelのハードウェアを最大限に活用するためにソフトウェア側で利用可能なものをすべて紹介することです。前のブログ記事と同様に、ベンチマークの結果とグラフとともに、これらのツールと機能を簡単に使用できるようにします。 4月にIntelは最新のIntel Xeonプロセッサ、コードネームIce Lakeを発売しました。これはより効率的で高性能なAIワークロードをターゲットにしています。具体的には、Ice Lake Xeon CPUは、以前のCascade Lake Xeonプロセッサと比較して、さまざまなNLPタスクで最大75%高速な推論が可能です。これは、新しいSunny Coveアーキテクチャ上での新しい命令やPCIe 4.0のようなハードウェアおよびソフトウェアの改善の組み合わせによって実現されています。最後になりますが、Intelは、IntelのExtension for Scikit Learn、Intel TensorFlow、Intel PyTorch…

Intelのテクノロジーを使用して、PyTorchの分散ファインチューニングを高速化する
驚異的なパフォーマンスを持つ最先端のディープラーニングモデルでも、トレーニングには長い時間がかかることがよくあります。トレーニングジョブを高速化するために、エンジニアリングチームは分散トレーニングに頼っています。これは、クラスタ化されたサーバーがそれぞれモデルのコピーを保持し、トレーニングセットのサブセットでトレーニングを行い、結果を交換して最終的なモデルに収束するという分割統治技術です。 グラフィックプロセッシングユニット(GPU)は、ディープラーニングモデルのトレーニングにおいて長い間デファクトの選択肢でした。しかし、転移学習の台頭により、状況が変化しています。モデルは今や巨大なデータセットからゼロからトレーニングされることはほとんどありません。代わりに、特定の(より小さい)データセットで頻繁に微調整され、特定のタスクに対してベースモデルよりも精度の高い専用モデルが構築されます。これらのトレーニングジョブは短いため、CPUベースのクラスタを使用することは、トレーニング時間とコストの両方を管理するための興味深いオプションとなります。 この投稿の内容 この投稿では、インテル Xeon Scalable CPUサーバのクラスタ上でPyTorchのトレーニングジョブを分散して高速化する方法について説明します。Ice Lakeアーキテクチャを搭載し、パフォーマンス最適化されたソフトウェアライブラリを実行する仮想マシンを使用して、クラスタをゼロから構築します。クラウドまたはオンプレミスの環境で、簡単にデモを自身のインフラストラクチャに複製することができるはずです。 テキスト分類ジョブを実行し、MRPCデータセット(GLUEベンチマークに含まれるタスクの1つ)でBERTモデルを微調整します。MRPCデータセットには、ニュースソースから抽出された5,800の文のペアが含まれており、各ペアの2つの文が意味的に同等であるかどうかを示すラベルが付いています。このデータセットはトレーニング時間が合理的であり、他のGLUEタスクを試すのはパラメーターさえ変更すれば可能です。 クラスタが準備できたら、まずは単一のサーバーでベースラインのジョブを実行します。その後、2つのサーバーや4つのサーバーにスケールアップして、スピードアップを計測します。 途中で以下のトピックについて説明します: 必要なインフラストラクチャとソフトウェアのビルディングブロックのリストアップ クラスタのセットアップ 依存関係のインストール 単一ノードのジョブの実行 分散ジョブの実行 さあ、作業を始めましょう! インテルサーバの使用 最高のパフォーマンスを得るために、Ice Lakeアーキテクチャに基づいたインテルサーバを使用します。これには、Intel AVX-512やIntel Vector Neural Network…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.