Learn more about Search Results A - Page 794

- You may be interested
- 「AIは政治をより簡単、安価かつ危険にする」
- 「コマンドバーの創設者兼CEO、ジェームズ...
- このAI論文は、MITが化学研究のために深層...
- Amazon SageMaker Studioで生産性を向上さ...
- オフラインでのアクティブなポリシー選択
- ビジネスにおけるオープンソースと専有モ...
- マルコフとビネメ・シェビシェフの不等式
- AWSにおけるマルチモデルエンドポイントの...
- ビジネス戦略において機械学習を使用する...
- 宇宙における私たちの位置を理解する
- アデプトAIはFuyu-8Bをオープンソース化し...
- 「機械学習をマスターするための5つの無料...
- 偽の預言者:自家製時系列回帰のための特...
- パレート、パワーロー、そしてファットテール
- メタ:メタバースの悪夢からAIの成功へ

「ODSC Europe 2023の写真とハイライト」
ODSC Europe 2023から数週間が経ちましたが、最高のノートで去ることができました週はデータサイエンスのトップトピック、AIのイノベーションに関する魅力的なセッションで満ち、しばらく会っていなかった笑顔の顔もありました以下はODSCのハイライトです...
テキストの生成方法:トランスフォーマーを使用した言語生成のための異なるデコーディング方法の使用方法
はじめに 近年、大規模なトランスフォーマーベースの言語モデル(例えば、OpenAIの有名なGPT2モデル)が数百万のウェブページを学習することで、オープンエンドの言語生成に対する関心が高まっています。条件付きのオープンエンドの言語生成の結果は印象的です。例えば、ユニコーンに関するGPT2、XLNet、CTRLでの制御言語生成などです。改良されたトランスフォーマーアーキテクチャや大量の非教示学習データに加えて、より良いデコーディング手法も重要な役割を果たしています。 このブログ記事では、異なるデコーディング戦略の概要と、さらに重要なことに、人気のあるtransformersライブラリを使ってそれらを簡単に実装する方法を紹介します! 以下のすべての機能は、自己回帰言語生成に使用することができます(ここでは復習です)。要するに、自己回帰言語生成は、単語のシーケンスの確率分布を条件付き次の単語の分布の積として分解できるという仮定に基づいています: P(w1:T∣W0)=∏t=1TP(wt∣w1:t−1,W0) ,with w1:0=∅, P(w_{1:T} | W_0 ) = \prod_{t=1}^T P(w_{t} | w_{1: t-1}, W_0) \text{ ,with } w_{1: 0} = \emptyset, P(w1:T∣W0)=t=1∏TP(wt∣w1:t−1,W0) ,with w1:0=∅,…

「The Reformer – 言語モデリングの限界を押し上げる」
Reformerが半ミリオントークンのシーケンスを訓練するために8GB未満のRAMを使用する方法 Reformerモデルは、Kitaev、Kaiserらによって2020年に紹介されたもので、現在のところ最もメモリ効率の良いトランスフォーマーモデルの1つです。 最近、長いシーケンスモデリングは大きな関心を集めており、今年だけでも多くの論文が提出されています(Beltagyら(2020年)、Royら(2020年)、Tayら、Wangらなど)。長いシーケンスモデリングの背後にある動機は、要約、質問応答などの多くのNLPタスクが、BERTなどのモデルよりも長い入力シーケンスを処理する必要があるということです。大きな入力シーケンスを処理する必要があるタスクでは、長いシーケンスモデルはメモリオーバーフローを避けるために入力シーケンスを切り詰める必要がなく、従って標準の「BERT」のようなモデルを上回る性能を示すことが示されています(Beltagyら(2020年)による)。 Reformerは、このデモに示されているように、一度に最大で半ミリオンのトークンを処理する能力により、長いシーケンスモデリングの限界を em em ます。比較のために、従来の bert-base-uncased モデルでは、入力の長さを512トークンに制限しています。Reformerでは、標準のトランスフォーマーアーキテクチャの各部分が最小限のメモリ要件を最適化するために再設計されており、性能の大幅な低下を伴わずにメモリの改善がなされています。 メモリの改善は、Reformerの作者がトランスフォーマーワールドに導入した4つの特徴に帰属できます: Reformer Self-Attention Layer – ローカルコンテキストに制限されることなく自己注意を効率的に実装する方法は? Chunked Feed Forward Layers – 大規模なフォワードレイヤーの時間とメモリのトレードオフを改善する方法は? Reversible Residual Layers…

‘Perceiver IO どんなモダリティにも対応するスケーラブルな完全注意モデル’
TLDR 私たちはPerceiver IOをTransformersに追加しました。これは、テキスト、画像、音声、ビデオ、ポイントクラウドなど、あらゆる種類のモダリティ(それらの組み合わせも含む)に対応した最初のTransformerベースのニューラルネットワークです。以下のスペースをご覧いただくと、いくつかの例をご覧いただけます。 画像間のオプティカルフローの予測 画像の分類。 また、いくつかのノートブックも提供しています。 以下に、モデルの技術的な説明をご覧いただけます。 はじめに Transformerは、元々Vaswaniらによって2017年に紹介され、機械翻訳の最先端(SOTA)の結果を改善するというAIコミュニティでの革命を引き起こしました。2018年には、BERTがリリースされ、トランスフォーマーエンコーダ専用のモデルで、自然言語処理(NLP)のベンチマーク(特にGLUEベンチマーク)を圧倒的に上回りました。 その後まもなくして、AI研究者たちはBERTのアイデアを他の領域にも適用し始めました。以下にいくつかの例を挙げます。 Facebook AIのWav2Vec2は、このアーキテクチャをオーディオに拡張できることを示しました。 Google AIのVision Transformer(ViT)は、このアーキテクチャがビジョンに非常に適していることを示しました。 最近では、Google AIのVideo Vision Transformer(ViViT)もこのアーキテクチャをビデオに適用しました。 これらのすべての領域で、大規模な事前トレーニングとこの強力なアーキテクチャの組み合わせにより、最先端の結果が劇的に改善されました。 ただし、Transformerのアーキテクチャには重要な制約があります。自己注意機構により、計算およびメモリの両方でスケーリングが非常に悪くなります。各レイヤーでは、すべての入力をクエリとキーの生成に使用し、ペアごとのドット積を計算します。したがって、高次元データに自己注意を適用するには、ある形式の前処理が必要です。たとえば、Wav2Vec2では、生の波形を時間ベースの特徴のシーケンスに変換するために、特徴エンコーダを使用してこの問題を解決しています。Vision Transformer(ViT)は、画像を重ならないパッチのシーケンスに分割し、「トークン」として使用します。Video Vision Transformer(ViViT)は、ビデオから重ならない時空間の「チューブ」を抽出し、「トークン」として使用します。Transformerを特定のモダリティで動作させるためには、通常はトークンのシーケンスに離散化する必要があります。…

より小さく、より速い言語モデルのためのブロック疎行列
空間と時間を節約する、ゼロを一つずつ 以前のブログ投稿では、疎行列とそのニューラルネットワークへの改善効果について紹介しました。 基本的な仮定は、完全な密行列層はしばしば過剰であり、精度の大幅な低下なしに剪定することができるということです。一部の場合では、疎な線形層は精度と/または一般化を向上させることさえあります。 現在利用可能な疎行列計算をサポートするコードは効率に乏しいため、主な問題です。また、公式のPyTorchサポートもまだ待たれています。 それが私たちが忍耐を尽き、この「空白」に取り組むためにこの夏に時間をかけた理由です。今日、私たちは拡張機能pytorch_block_sparseをリリースすることをうれしく思っています。 このライブラリは、それ自体だけでなく、蒸留や量子化などの他のメソッドと組み合わせて使用することにより、ネットワークをより小さく、より高速にすることができます。これはHugging Faceにとって、誰でも低コストでニューラルネットワークを本番で使用し、エンドユーザーの体験を向上させることが重要です。 使用法 提供されるBlockSparseLinearモジュールはtorch.nn.Linearの簡単な置き換えであり、モデルで簡単に使用できます: # from torch.nn import Linear from pytorch_block_sparse import BlockSparseLinear ... # self.fc = nn.Linear(1024, 256)…

エンコーダー・デコーダーモデルのための事前学習済み言語モデルチェックポイントの活用
Transformerベースのエンコーダーデコーダーモデルは、Vaswani et al.(2017)で提案され、最近ではLewis et al.(2019)、Raffel et al.(2019)、Zhang et al.(2020)、Zaheer et al.(2020)、Yan et al.(2020)などにおいて大きな関心を集めています。 BERTやGPT2と同様に、大規模な事前学習済みエンコーダーデコーダーモデルは、Lewis et al.(2019)、Raffel et al.(2019)などのさまざまなシーケンス対シーケンスのタスクにおいて性能を大幅に向上させることが示されています。しかし、エンコーダーデコーダーモデルの事前学習には膨大な計算コストがかかるため、そのようなモデルの開発は主に大企業や研究所に限定されています。 Sascha Rothe、Shashi Narayan、Aliaksei Severynによる「シーケンス生成タスクのための事前学習済みチェックポイントの活用」(2020)では、事前学習済みのエンコーダーやデコーダーのみのチェックポイント(例:BERT、GPT2)でエンコーダーデコーダーモデルを初期化して、コストのかかる事前学習をスキップする方法が紹介されています。著者らは、このようなウォームスタートされたエンコーダーデコーダーモデルが、T5やPegasusなどの大規模な事前学習済みエンコーダーデコーダーモデルと比較して、複数のシーケンス対シーケンスのタスクで競争力のある結果をもたらすことを示しています。 このノートブックでは、エンコーダーデコーダーモデルをウォームスタートする方法の詳細を説明し、Rothe et…

シンプルな人々が派手なニューラルネットワークを構築するための簡単な考慮事項
写真提供:Henry & Co. (Unsplash) 機械学習が産業のあらゆる分野に浸透するにつれて、ニューラルネットワークの注目度はこれまでにないほど高まっています。たとえば、GPT-3などのモデルは過去数週間でソーシャルメディア上で話題となり、テックニュース以外のメディアでも恐怖心を煽る見出しを掲載されています。 一方で、ディープラーニングのフレームワーク、ツール、特化したライブラリにより、最先端の研究を利用した研究がこれまで以上に簡単に行えるようになり、機械学習の研究が民主化されつつあります。ほとんど魔法のようなプラグアンドプレイのコード5行で(ほぼ)最先端の結果を約束することがよくあります。私自身もHugging Face 🤗で働いているため、その点については一部罪を感じています。 😅 これにより、経験の浅いユーザーはニューラルネットワークがすでに成熟した技術であるかのような誤解を受けることがありますが、実際にはこの分野は常に発展途上にあるのです。 実際には、ニューラルネットワークの構築とトレーニングは非常にイライラする経験になることがしばしばあります : 自分のモデル/コードのバグによるパフォーマンスの問題なのか、モデルの表現力による制約なのかを理解するのが難しいことがあります。 プロセスの各ステップで微小なミスを何度も犯しても最初は気づかず、モデルは依然としてトレーニングされ、まあまあのパフォーマンスを示します。 この記事では、ニューラルネットワークの構築とデバッグ時に考えるべき手順のいくつかを紹介します。「デバッグ」とは、自分が構築したものと自分が考えているものが一致していることを確認することを意味します。また、次のステップが何であるかわからない場合に考慮すべき事項も指摘します。これらは、自然言語処理の研究を通じた経験に基づく考え方の多くですが、ほとんどの原則は他の機械学習の分野にも適用できます。 1. 🙈 機械学習を置いておいて始める 直感に反するかもしれませんが、ニューラルネットワークを構築する最初のステップは、機械学習を一旦置いて、単にデータに焦点を当てることです。例を見て、ラベルを見て、テキストを扱っている場合は語彙の多様性や長さの分布などにも注目してデータに深く入り込んでみてください。モデルが捉えられる可能性のある一般的なパターンを抽出するために、データに没頭することが重要です。数百の例を見ることで、高レベルのパターンを特定することができるでしょう。以下は、自分自身に対して考えるべきいくつかの典型的な質問です: ラベルはバランスしていますか? 自分が同意しないゴールドラベルはありますか? データはどのように取得されましたか?このプロセスでのノイズの可能性のあるソースは何ですか? トークン化、URLやハッシュタグの削除など、自然な前処理ステップはありますか? 例はどれだけ多様ですか? この問題に対してまあまあのパフォーマンスを示すルールベースのアルゴリズムは何ですか?…

Google Cloud上のサーバーレストランスフォーマーパイプラインへの私の旅
コミュニティメンバーのマクサンス・ドミニシによるゲストブログ投稿 この記事では、Google Cloudにtransformers感情分析パイプラインを展開するまでの道のりについて説明します。まず、transformersの簡単な紹介から始め、実装の技術的な部分に移ります。最後に、この実装をまとめ、私たちが達成したことについてレビューします。 目標 Discordに残された顧客のレビューがポジティブかネガティブかを自動的に検出するマイクロサービスを作成したかったです。これにより、コメントを適切に処理し、顧客の体験を向上させることができます。たとえば、レビューがネガティブな場合、顧客に連絡し、サービスの品質の低さを謝罪し、サポートチームができるだけ早く連絡し、問題を修正するためにサポートすることができる機能を作成できます。1か月あたり2,000件以上のリクエストは予定していないため、時間と拡張性に関してはパフォーマンスの制約を課しませんでした。 Transformersライブラリ 最初に.h5ファイルをダウンロードしたとき、少し混乱しました。このファイルはtensorflow.keras.models.load_modelと互換性があると思っていましたが、実際にはそうではありませんでした。数分の調査の後、ファイルがケラスモデルではなく重みのチェックポイントであることがわかりました。その後、Hugging Faceが提供するAPIを試して、彼らが提供するパイプライン機能についてもう少し調べました。APIおよびパイプラインの結果が素晴らしかったため、自分自身のサーバーでモデルをパイプラインを通じて提供することができると判断しました。 以下は、TransformersのGitHubページの公式の例です。 from transformers import pipeline # 感情分析のためのパイプラインを割り当てる classifier = pipeline('sentiment-analysis') classifier('We are very happy to include…
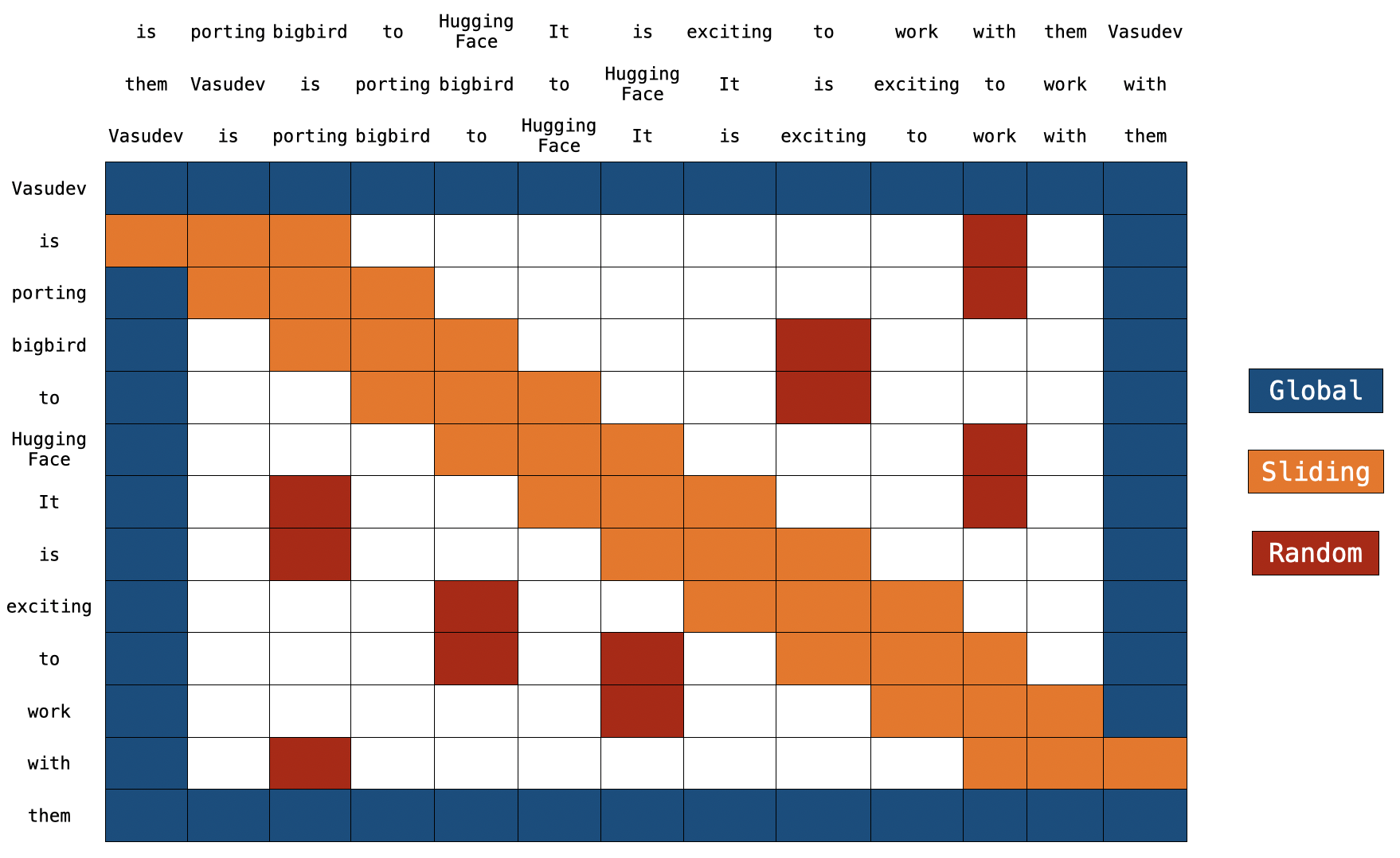
BigBirdのブロック疎な注意機構の理解
イントロダクション トランスフォーマーベースのモデルは、多くの自然言語処理タスクにおいて非常に有用であることが示されています。ただし、トランスフォーマーベースのモデルの主な制限は、O(n^2) の時間とメモリの複雑さ(ここで n はシーケンスの長さです)です。したがって、長いシーケンス n > 512 に対してトランスフォーマーベースのモデルを適用するのは計算上非常に高コストです。最近のいくつかの論文では、Longformer、Performer、Reformer、Clustered attention などが、完全な注意行列を近似することでこの問題を解決しようとしています。これらのモデルについて詳しく知りたい場合は、🤗の最近のブログ記事をチェックしてください。 BigBird(論文で紹介)は、この問題に対処するための最近のモデルの1つです。 BigBird は通常の注意(つまり、BERTの注意)ではなく、ブロックスパースな注意を使用し、BERTよりも低い計算コストで長さ 4096 のシーケンスを処理することができます。 BigBird は、長いドキュメントの要約、長いコンテキストを持つ質問応答など、非常に長いシーケンスを含むさまざまなタスクでSOTAを達成しています。 BigBird RoBERTa-like モデルは現在、🤗Transformersで利用できます。この記事の目的は、読者に 詳細な BigBird の実装の理解を提供し、🤗Transformers…
CPU上でBERT推論をスケーリングアップする(パート1)
.centered { display: block; margin: 0 auto; } figure { text-align: center; display: table; max-width: 85%; /* デモです; 必要に応じていくつかの量 (px や %) を設定してください */…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.