Learn more about Search Results MPT - Page 78

- You may be interested
- 最適なパイプラインとトランスフォーマー...
- 新しいAIリスクの早期警告システム
- 新たなAIツールは、より高度な天体生物学...
- 「レーザーマッピングによって忘れられた...
- 「データオデッセイの航海:2023年のトッ...
- 4/9から10/9までの週のためのトップ重要な...
- 電車利用者のためのリアルタイム混雑予測
- このAI研究は、単一の画像を探索可能な3D...
- MySQLのJSON_ARRAYAGG関数をハッキングし...
- AIバイアス:課題と解決策
- 「TR0Nに会ってください:事前学習済み生...
- 「アルゴリズムを使用して数千件の患者請...
- クラスタリングアルゴリズムへの導入
- 「AIによる生成写真を用いた文学作品にお...
- 特定のデータ処理タスクを効率的に解決す...

3B、4B、9B のスケールで 5 つの新しいマルチモーダルモデルを備えた OpenFlamingo チームが、前モデルを上回る OpenFlamingo v2 をリリースしました
ワシントン大学、スタンフォード大学、AI2、UCSB、Googleの研究者グループは、最近OpenFlamingoプロジェクトを開発しました。このプロジェクトはDeepMindのFlamingoチームと同様のモデルを構築することを目指しています。OpenFlamingoモデルは、任意の混合テキストと画像のシーケンスを処理し、テキストを出力することができます。キャプショニング、ビジュアルクエスチョンアンサリング、画像分類などが、このモデルの能力とコンテキストでのサンプリングを活用することができる活動の一部です。 現在、チームはv2のリリースを発表しました。このリリースには、3B、4B、9Bのレベルでトレーニングされた5つのOpenFlamingoモデルが含まれています。これらのモデルは、LLaMAよりも制約の緩いオープンソースモデルから派生しており、MosaicのMPT-1Bと7B、Together.XYZのRedPajama-3Bなどが含まれています。 研究者たちは、すでにプリトレーニングされた静的言語モデルのレイヤーに視覚的な特徴を追加することで、Flamingoモデリングパラダイムを使用しました。ビジョンエンコーダーと言語モデルは静的なままですが、接続モジュールはFlamingoと同様にWebスクレイピングされた画像テキストのシーケンスを使用してトレーニングされます。 チームは、キャプショニング、VQA、および分類モデルをビジョン言語データセットでテストしました。その結果、チームはv1リリースとOpenFlamingo-9B v2モデルの間で大きな進歩を遂げたことがわかりました。 彼らは7つのデータセットと5つの異なるコンテキストからの結果を組み合わせて、モデルの有効性を評価しました。コンテキストのないショット、4つのショット、8つのショット、16のショット、32のショットの評価を行いました。OpenFlamingo (OF)のOF-3BおよびOF-4BレベルのモデルをFlamingo-3BおよびFlamingo-9Bレベルのモデルと比較し、平均してOpenFlamingo (OF)はFlamingoの性能の80%以上を達成していることがわかりました。研究者たちはまた、自身の結果をPapersWithCodeで公開された最適化されたSoTAと比較しました。オンラインデータのみで事前トレーニングされたOpenFlamingo-3BおよびOpenFlamingo-9Bモデルは、32のコンテキストインスタンスで微調整された性能の55%以上を達成しています。OpenFlamingoのモデルは、0ショットではDeepMindの平均10%、32ショットでは15%遅れています。 チームは引き続きトレーニングと最先端のマルチモーダルモデルの提供に取り組んでいます。次に、事前トレーニングに使用するデータの品質を向上させることを目指しています。

Pythonを使用してTenacityを使用してリトライを制御する:エンドツーエンドのチュートリアル
Python Tenacityライブラリを発見し、Pythonアプリケーションで効果的な再試行ロジックとエラーハンドリングを実装する方法を学びましょうネットワークやAPIの障害、タイムアウト、およびさまざまな他の課題に対処するための実践的な例と業界で証明されたベストプラクティスを提供します

大規模な言語モデルにおけるコンテキストに基づく学習アプローチ
言語モデリング(LM)は、単語のシーケンスの生成的な尤度をモデル化することを目指し、将来の(または欠損している)トークンの確率を予測します言語モデルは自然言語処理の世界を革新しました...
既存のLLMプロジェクトをLangChainを使用するように適応する
おめでとうございます!素晴らしいLLMの概念証明が完成しましたね自信を持って世界に披露できます!もしかしたら、OpenAIライブラリを直接利用したかもしれませんし、他のライブラリを使用しているかもしれませんが、どのようにしても、この素晴らしい成果を誇示できます!
科学ソフトウェアの開発
この記事では、このシリーズの最初の記事で示されたように、科学ソフトウェアの開発においてTDDの原則に従って、Sobelフィルタとして知られるエッジ検出フィルタを開発します
もし、口頭および書面によるコミュニケーションが人間の知能を発展させたのであれば… 言語モデルは一体どうなっているのでしょうか?
人間の知能は、その非凡な認知能力によって、他の種に比べて比類のない存在ですこの知的優位性の原動力は、言語の出現に遡ることができます...

ChatGPTから独自のプライベートなフランス語チューターを作成する方法
議論された外国語チューターのコードは、私のGitHubページの同梱リポジトリで見つけることができます非商業利用に限り、自由に使用することができます長い間延期していたので、私は...
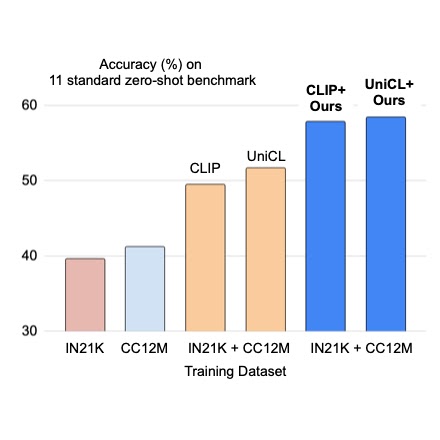
プレフィックス条件付きの画像キャプションと画像分類のデータセットの統合
クラウドAIチームの学生研究者である斎藤邦明と知識チームの研究科学者であるソン・キヒョクによる投稿 ウェブスケールの画像キャプションデータセットでの視覚言語(VL)モデルの事前トレーニングは、画像分類データによる従来の事前トレーニングに対する強力な代替手段として最近注目されています。画像キャプションデータセットはより「オープンドメイン」であると考えられており、広範なシーンタイプや語彙の単語を含んでいるため、少数およびゼロショットの認識タスクで強力な性能を持つモデルが得られます。しかし、細粒度のクラスの説明を持つ画像は稀であり、画像キャプションデータセットは手動のキュレーションを経ていないため、クラスの分布が不均衡になる可能性があります。これに対して、ImageNetなどの大規模な分類データセットは通常キュレーションされており、バランスの取れたラベル分布を持つ細粒度のカテゴリを提供することができます。一見有望に聞こえるかもしれませんが、キャプションと分類データセットを直接組み合わせて事前トレーニングすることは、さまざまな下流タスクに対してうまく汎化しないバイアスのある表現を生み出す可能性があるため、通常は成功しないことがあります。 CVPR 2023で発表された「Prefix Conditioning Unifies Language and Label Supervision」では、分類とキャプションデータセットの両方を使用して補完的な利点を提供する事前トレーニング戦略を示しています。まず、データセットを単純に統合すると、モデルはデータセットのバイアスに影響を受け、下流のゼロショット認識タスクでの最適な性能を発揮しない結果となります。各データセットにおける画像ドメインと語彙のカバレッジは異なるためです。この問題に対処するために、我々はプレフィックス条件付けという新しい簡単で効果的な手法を使用して、トレーニング中にデータセットのバイアスと視覚的な概念を分離します。このアプローチにより、言語エンコーダは両方のデータセットから学習すると同時に、各データセットに対して特徴抽出を調整することができます。プレフィックス条件付けは、Contrastive Language-Image Pre-training(CLIP)やUnified Contrastive Learning(UniCL)などの既存のVL事前トレーニング目標に簡単に統合できる汎用の手法です。 高レベルのアイデア 分類データセットは少なくとも2つの方法でバイアスがかかる傾向があります:(1)画像には制限されたドメインの単一のオブジェクトがほとんど含まれており、(2)語彙が限定されており、ゼロショット学習に必要な言語の柔軟性を欠いています。たとえば、「犬の写真」というクラスの埋め込みは、通常、ImageNet向けに最適化されたものでは、ImageNetデータセットから引っ張られた画像の中央に1匹の犬の写真が表示されるものであり、他のデータセットに含まれる複数の位置にいる犬の画像や他の被写体との組み合わせにはうまく汎化しません。 それに対して、キャプションデータセットにはさまざまなシーンタイプと語彙が含まれています。以下に示すように、モデルが単純に2つのデータセットから学習する場合、言語の埋め込みは画像分類とキャプションデータセットのバイアスを絡め取る可能性があり、ゼロショット分類の汎化性能が低下することがあります。2つのデータセットのバイアスを分離できれば、キャプションデータセットに適した言語の埋め込みを使用して汎化性能を向上させることができます。 上:画像分類とキャプションデータセットのバイアスを絡め取る言語の埋め込み。下:2つのデータセットのバイアスを分離した言語の埋め込み。 プレフィックス条件付け プレフィックス条件付けは、プロンプトチューニングに部分的に触発された手法であり、学習可能なトークンを入力トークンシーケンスの前に追加することで、事前トレーニング済みのモデルバックボーンにタスク固有の知識を学習させ、それを使用して下流タスクを解決するための方法を指示します。プレフィックス条件付けアプローチは、プロンプトチューニングとは異なる2つの点で異なります:(1)データセットのバイアスを分離するために画像キャプションと分類データセットを統合するように設計されており、(2)VL事前トレーニングに適用される一方、標準のプロンプトチューニングはモデルの微調整に使用されます。プレフィックス条件付けは、ユーザーが提供するデータセットの種類に基づいてモデルバックボーンの振る舞いを明示的に制御する方法です。特に、さまざまなタイプのデータセットの数が事前にわかっている場合に役立ちます。 トレーニング中、接頭辞条件付けは、各データセットタイプごとにテキストトークン(接頭辞トークン)を学習し、データセットのバイアスを吸収し、残りのテキストトークンが視覚的な概念を学習することに集中できるようにします。具体的には、入力トークンの先頭に各データセットタイプごとの接頭辞トークンを追加し、入力データのタイプ(分類対キャプションなど)に関する言語エンコーダと視覚エンコーダに情報を提供します。接頭辞トークンはデータセットタイプ固有のバイアスを学習するため、言語表現のバイアスを分離し、入力キャプションなしでもテスト時に画像キャプションデータセットで学習された埋め込みを利用することができます。 CLIPでは、言語エンコーダと視覚エンコーダを使用して接頭辞条件付けを利用します。テスト時には、画像キャプションデータセットで使用された接頭辞を使用します。このデータセットはより広範なシーンタイプと語彙をカバーするため、ゼロショット認識の性能が向上します。 接頭辞条件付けのイラスト。 実験結果…
GPTと人間の心理学
GPTと人間の心理学との類推を行うことで、私たちは生成型AIの出力を促進する方法を理解することができます

ウェブ3.0とブロックチェーンの進化による洞察力の向上
イントロダクション ウェブ3.0とブロックチェーンに関する洞察を提供するコミュニティThird Blockを構築した熱心な人物であるアビシェク・カテリヤ氏との対話の中で、彼の前職でのJPモルガンでのデータアナリストとしての経験、コミュニティの力、そしてこの分野で成功するためのキャリア構築の視点について共有していただく予定です。 インタビューを始めましょう AV: 自己紹介とバックグラウンドについて教えてください。 アビシェク氏 : 私はアビシェク・カテリヤと申します。フルスタックソフトウェアエンジニアで、JPモルガン&チェースで3年間働いた後、カリフォルニア拠点のAIトレードファイナンススタートアップのTradeSunに参画しました。その間、非営利セクターでの経験も豊富にあります。私はRoti Bank Foundationの創設メンバーであり、ムンバイ周辺の飢えた人々に食事を提供するための食品回収モデルの構築に取り組んできました。設立から3年間で100万食に達するために、ハイデラバード、アラ、パトナ、ナグプル、プネなどの都市にも支部を展開しました。また、ムンバイの工学大学との協力プロジェクトとして、腐った食べ物の警告装置やムンバイのハンガーマップの開発も行いました。 また、Coding4all.inというイニシアチブの一環として、高校生に無料で基本的なプログラミングを教える活動にも参加しました。5ヶ月間で200人のコホートに到達しました。学生たちがラップトップやコンピュータを持たずにオンラインで学ぶことを可能にし、世界中のテック業界のエキスパートたちが講師として参加しています。これら以外にも、Web3とブロックチェーン技術に興味を持ち始め、JPモルガンのデジタル通貨であるJPMコインプロジェクトに取り組みました。仕事の傍ら、旅行やトレッキングが好きで、インスタグラム(@abhikuchbhi_blog)にストーリーを投稿したり、MBAの進学記録を(@mbabhikuchbhi)に投稿しています。 AV: テクノロジーとビジネスマネジメントのMBAを追求していますが、MBAの取得を促した要因は何ですか? アビシェク氏: COVIDの間にMBAの計画を諦めましたが、MBAを取得するためにウォートンに行きたいと思っていました。しかし、すべての選択肢を比較する中で、インドは今後の時代において本当に適切な場所であり、Masters’ Unionは私がインドのスタートアップエコシステムに関与するための有望なオプションとして浮かび上がりました。私はあまり考えずにMUに応募し、ヒマラヤでトレッキングに行きました。戻ってきた時にはインタビューの呼び出しがあり、1ヶ月後には入学が決まりました。私はここに来てスタートアップエコシステムをより深く理解し、私のネットワークに価値ある人材を追加するためです。これは本当に素晴らしい旅であり、賢明な決断でした。 AV: キャリアに影響を与えた人物をいくつか挙げていただけますか?どのように影響を受けましたか? アビシェク氏: 小さい頃、私はいつも「バットマン」と答えていました。アイドルやメンターを持つことの意味を理解することはありませんでしたが、私は常にグリットと努力に感銘を受けたバットマンを尊敬していました。だから、常に前進し、もっとやることを私にはバットマンがインスピレーションを与えています。その他に、私の父でありシリアルアントレプレナーでもあるプラフルクマールさん。彼のベンチャーは成功しなかったものの、彼の忍耐力とグリットは今でも私に「失敗したから何だ」と言い続けてくれます。Masters’ Unionの創設者、プラサム・ミッタルさん。彼は若く、エネルギッシュであり、何でも持っていると言っても過言ではありません。しかし、彼が仕事に注ぐ熱意、エネルギー、努力は本当に素晴らしく、私にとっては確かにインスピレーションです。 起業のインスピレーション AV:…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.