Learn more about Search Results リポジトリ - Page 78

- You may be interested
- 現実世界における数学:テスト、シミュレ...
- 「LLMガイド、パート1:BERT」 LLMガイド...
- 「トップデータプライバシーツール2023」
- オープンLLMリーダーボード:DROPディープ...
- CommonCanvasをご紹介します:クリエイテ...
- 「2024年に必ず試してみるべきトップ15の...
- 次世代のコンピューティング:NVIDIAとAMD...
- 「自分自身でタスクを行う方法を知ってい...
- 「フィンタスティック:3DアーティストがA...
- 大規模な言語モデル:DeBERTa — デコーデ...
- オープンソースのAmazon SageMaker Distri...
- AGIの現実世界の課題
- シンガポール国立大学の研究者たちは、ピ...
- 『LangChainを使用してテキストから辞書を...
- AIとオープンソースソフトウェア:誕生時...

🤗 Optimum IntelとOpenVINOでモデルを高速化しましょう
昨年7月、インテルとHugging Faceは、Transformerモデルのための最新かつシンプルなハードウェアアクセラレーションツールの開発で協力することを発表しました。本日、私たちはOptimum IntelにIntel OpenVINOを追加したことをお知らせできて非常に嬉しく思います。これにより、Hugging FaceハブまたはローカルにホストされるTransformerモデルを使用して、様々なIntelプロセッサ上でOpenVINOランタイムによる推論を簡単に実行できます(サポートされているデバイスの完全なリストを参照)。OpenVINOニューラルネットワーク圧縮フレームワーク(NNCF)を使用してモデルを量子化し、サイズと予測レイテンシをわずか数分で削減することもできます。 この最初のリリースはOpenVINO 2022.2をベースにしており、私たちのOVModelsを使用して、多くのPyTorchモデルに対する推論を実現しています。事後トレーニング静的量子化と量子化感知トレーニングは、多くのエンコーダモデル(BERT、DistilBERTなど)に適用することができます。今後のOpenVINOリリースでさらに多くのエンコーダモデルがサポートされる予定です。現在、エンコーダデコーダモデルの量子化は有効化されていませんが、次のOpenVINOリリースの統合により、この制限は解除されるはずです。 では、数分で始める方法をご紹介します! Optimum IntelとOpenVINOを使用してVision Transformerを量子化する この例では、食品101データセットでイメージ分類のためにファインチューニングされたVision Transformer(ViT)モデルに対して事後トレーニング静的量子化を実行します。 量子化は、モデルパラメータのビット幅を減らすことによってメモリと計算要件を低下させるプロセスです。ビット数を減らすことで、推論時に必要なメモリが少なくなり、行列乗算などの演算が整数演算によって高速に実行できるようになります。 まず、仮想環境を作成し、すべての依存関係をインストールしましょう。 virtualenv openvino source openvino/bin/activate pip install pip --upgrade pip…

マルチリンガルASRのためのWhisperの調整を行います with 🤗 Transformers
このブログでは、ハギングフェイス🤗トランスフォーマーを使用して、Whisperを任意の多言語ASRデータセットに対して細かく調整する手順を段階的に説明します。このブログでは、Whisperモデル、Common Voiceデータセット、および細かな調整の背後にある理論について詳しく説明し、データの準備と細かい調整の手順を実行するためのコードセルと共に提供しています。説明は少ないですが、すべてのコードがあるより簡略化されたバージョンのノートブックは、関連するGoogle Colabを参照してください。 目次 はじめに Google ColabでのWhisperの細かい調整 環境の準備 データセットの読み込み 特徴抽出器、トークナイザー、およびデータの準備 トレーニングと評価 デモの作成 締めくくり はじめに Whisperは、OpenAIのAlec Radfordらによって2022年9月に発表された自動音声認識(ASR)のための事前学習モデルです。Whisperは、Wav2Vec 2.0などの先行研究とは異なり、ラベル付きの音声トランスクリプションデータで事前学習されています。具体的には、680,000時間のデータが使用されています。これは、Wav2Vec 2.0の訓練に使用されるラベルなしの音声データ(60,000時間)よりも桁違いに多いデータです。さらに、この事前学習データのうち117,000時間が多言語ASRデータです。これにより、96以上の言語に適用できるチェックポイントが生成され、その多くは低リソース言語とされています。 このような大量のラベル付きデータにより、Whisperは事前学習データから音声認識の教師ありタスクを直接学習し、音声トランスクリプションデータからテキストへのマッピングを学習します。そのため、Whisperはパフォーマンスの高いASRモデルを得るためにほとんど追加の細かい調整を必要としません。これに対して、Wav2Vec 2.0は非教師付きタスクのマスク予測で事前学習されており、音声から隠れた状態への中間的なマッピングを学習します。非教師付きの事前学習は音声の高品質な表現を生み出しますが、音声からテキストへのマッピングは学習されません。このマッピングは細かい調整中にのみ学習されるため、競争力のあるパフォーマンスを得るにはより多くの細かい調整が必要です。 680,000時間のラベル付き事前学習データにスケールされると、Whisperモデルは多くのデータセットとドメインに対して高い汎化能力を示します。事前学習されたチェックポイントは、LibriSpeech ASRのtest-cleanサブセットで約3%の単語エラーレート(WER)を達成し、TED-LIUMでは4.7%のWERで新たな最先端の結果を実現します(Whisper論文の表8を参照)。Whisperが事前学習中に獲得した多言語ASRの知識は、他の低リソース言語に活用することができます。細かい調整により、事前学習済みのチェックポイントを特定のデータセットと言語に適応させることで、これらの結果をさらに改善することができます。 Whisperは、Transformerベースのエンコーダーデコーダーモデルであり、シーケンスからシーケンスへのモデルとも呼ばれています。Whisperは、オーディオのスペクトログラム特徴のシーケンスをテキストトークンのシーケンスにマッピングします。まず、生のオーディオ入力は特徴抽出器によってログメルスペクトログラムに変換されます。次に、Transformerエンコーダーはスペクトログラムをエンコードしてエンコーダーの隠れ状態のシーケンスを形成します。最後に、デコーダーはエンコーダーの隠れ状態と以前に予測されたトークンの両方に依存して、テキストトークンを自己回帰的に予測します。図1はWhisperモデルを要約しています。 <img…

機械学習洞察のディレクター【パート4】
MLソリューションをより速く構築したい場合は、今すぐ hf.co/support をご覧ください! 👋 ML Insightsシリーズのディレクターへお帰りなさい!以前のエディションを見逃した場合は、こちらで見つけることができます: ディレクター・オブ・マシン・ラーニング・インサイト[パート1] ディレクター・オブ・マシン・ラーニング・インサイト[パート2:SaaSエディション] ディレクター・オブ・マシン・ラーニング・インサイト[パート3:金融エディション] 🚀 この第4弾では、次のトップマシン・ラーニング・ディレクターがそれぞれの業界へのマシン・ラーニングの影響について語ります:ハビエル・マンシージャ、ショーン・ギットンズ、サミュエル・フランクリン、エヴァン・キャッスル。全員が現在、豊富なフィールドの洞察を持つマシン・ラーニングのディレクターです。 免責事項:すべての意見は個人の意見であり、過去または現在の雇用者の意見ではありません。 ハビエル・マンシージャ – マーケティングサイエンス部門のマシン・ラーニングディレクター、メルカドリブレ 経歴:経験豊富な起業家でありリーダーであるハビエルは、2010年以来マシン・ラーニングを構築する高級企業であるMachinalisの共同設立者兼CTOでした(そう、ニューラルネットの突破前の時代です)。 MachinalisがMercado Libreに買収されたとき、その小さなチームは10,000人以上の開発者を持つテックジャイアントにマシン・ラーニングを可能にする能力として進化し、ほぼ1億人の直接ユーザーの生活に影響を与えました。ハビエルは、彼らのマシン・ラーニングプラットフォーム(NASDAQ MELI)の技術と製品のロードマップだけでなく、ユーザーのトラッキングシステム、ABテストフレームワーク、オープンソースオフィスもリードしています。ハビエルはPython-Argentinaの非営利団体PyArの積極的なメンバーおよび貢献者であり、家族や友人、Python、サイクリング、サッカー、大工仕事、そしてゆっくりとした自然の休暇が大好きです! おもしろい事実:私はSF小説を読むのが大好きで、引退後は短編小説を書くという10代の夢を再開する予定です。📚 メルカドリブレ:ラテンアメリカ最大の企業であり、コンチネンタルのeコマース&フィンテックの普遍的なソリューションです 1. eコマースにおいてMLがポジティブな影響を与えたのはどのような場合ですか? 詐欺防止や最適化されたプロセスやフローなど、特定のケースにおいてMLは不可能を可能にしたと言えます。他のほとんどの分野では想像もできなかった方法で、MLがUXの次のレベルを実現しました。…

🤗変換器を使用した確率的な時系列予測
はじめに 時系列予測は重要な科学的およびビジネス上の問題であり、従来の手法に加えて、深層学習ベースのモデルの使用により、最近では多くのイノベーションが見られています。ARIMAなどの従来の手法と新しい深層学習手法の重要な違いは、次のとおりです。 確率予測 通常、従来の手法はデータセット内の各時系列に個別に適合させられます。これらはしばしば「単一」または「ローカル」な手法と呼ばれます。しかし、一部のアプリケーションでは大量の時系列を扱う際に、「グローバル」モデルをすべての利用可能な時系列に対してトレーニングすることは有益であり、これによりモデルは多くの異なるソースからの潜在表現を学習できます。 一部の従来の手法は点値(つまり、各時刻に単一の値を出力するだけ)であり、モデルは真のデータに対するL2またはL1タイプの損失を最小化することによってトレーニングされます。しかし、予測はしばしば実世界の意思決定パイプラインで使用されるため、人間が介在していても、予測の不確実性を提供することははるかに有益です。これは「確率予測」と呼ばれ、単一の予測とは対照的です。これには、確率分布をモデル化し、そこからサンプリングすることが含まれます。 つまり、ローカルな点予測モデルをトレーニングする代わりに、グローバルな確率モデルをトレーニングすることを望んでいます。深層学習はこれに非常に適しており、ニューラルネットワークは複数の関連する時系列から表現を学習することができ、データの不確実性もモデル化できます。 確率的設定では、コーシャンまたはスチューデントTなどの選択したパラメトリック分布の将来のパラメータを学習するか、条件付き分位関数を学習するか、または時系列設定に適応させたコンフォーマル予測のフレームワークを使用することが一般的です。選択した方法はモデリングの側面に影響を与えないため、通常は別のハイパーパラメータと考えることができます。確率モデルを経験的平均値や中央値による点予測モデルに変換することも常に可能です。 時系列トランスフォーマ 時系列データをモデリングする際に、その性質上、研究者はリカレントニューラルネットワーク(RNN)(LSTMやGRUなど)、畳み込みネットワーク(CNN)などを使用したモデル、および最近では時系列予測の設定に自然に適合するトランスフォーマベースの手法を開発しています。 このブログ記事では、バニラトランスフォーマ(Vaswani et al., 2017)を使用して、単変量の確率予測タスク(つまり、各時系列の1次元分布を個別に予測)を活用します。エンコーダーデコーダートランスフォーマは予測に適しているため、いくつかの帰納バイアスをうまくカプセル化しています。 まず、エンコーダーデコーダーアーキテクチャの使用は、通常、一部の記録されたデータに対して将来の予測ステップを予測したい場合に推論時に役立ちます。これは、与えられた文脈に基づいて次のトークンをサンプリングし、デコーダーに戻す(「自己回帰生成」とも呼ばれる)テキスト生成タスクに類似して考えることができます。同様に、ここでも、ある分布タイプが与えられた場合、それからサンプリングして、望ましい予測ホライズンまでの予測を提供することができます。これは、NLPの設定についてのこちらの素晴らしいブログ記事に関しても言えます。 第二に、トランスフォーマは、数千の時系列データでトレーニングする際に役立ちます。注意機構の時間とメモリの制約のため、時系列のすべての履歴を一度にモデルに入力することは実現可能ではないかもしれません。したがって、適切なコンテキストウィンドウを考慮し、このウィンドウと次の予測長サイズのウィンドウをトレーニングデータからサンプリングして、確率的勾配降下法(SGD)のためのバッチを構築する際に使用することができます。コンテキストサイズのウィンドウはエンコーダーに渡され、予測ウィンドウは因果マスク付きデコーダーに渡されます。つまり、デコーダーは次の値を学習する際には、前の時刻ステップのみを参照できます。これは、バニラトランスフォーマを機械翻訳のためにトレーニングする方法と同等であり、「教師強制」と呼ばれます。 トランスフォーマのもう一つの利点は、他のアーキテクチャに比べて、時系列の設定で一般的な欠損値をエンコーダーやデコーダーへの追加マスクとして組み込むことができ、インフィルされることなくまたは補完することなくトレーニングできることです。これは、トランスフォーマライブラリのBERTやGPT-2のようなモデルのattention_maskと同等です。注意行列の計算にパディングトークンを含めないようにします。 Transformerアーキテクチャの欠点は、バニラのTransformerの二次計算およびメモリ要件によるコンテキストと予測ウィンドウのサイズの制限です(Tay et al.、2020を参照)。さらに、Transformerは強力なアーキテクチャであるため、他の手法と比較して過学習や偽の相関をより簡単に学習する可能性があります。 🤗 Transformersライブラリには、バニラの確率的時系列Transformerモデルが付属しており、それを単純にTime Series Transformerと呼んでいます。以下のセクションでは、このようなモデルをカスタムデータセットでトレーニングする方法を示します。 環境のセットアップ…

Apple SiliconでのCore MLを使用した安定した拡散を利用する
Appleのエンジニアのおかげで、Core MLを使用してApple SiliconでStable Diffusionを実行できるようになりました! このAppleのレポジトリは、🧨 Diffusersを基にした変換スクリプトと推論コードを提供しており、私たちはそれが大好きです!できるだけ簡単にするために、私たちは重みを変換し、モデルのCore MLバージョンをHugging Face Hubに保存しました。 更新:この投稿が書かれてから数週間後、私たちはネイティブのSwiftアプリを作成しました。これを使用して、自分自身のハードウェアでStable Diffusionを簡単に実行できます。私たちはMac App Storeにアプリをリリースし、他のプロジェクトがそれを使用できるようにソースコードも公開しました。 この投稿の残りの部分では、変換された重みを自分自身のコードで使用する方法や、追加の重みを変換する方法について説明します。 利用可能なチェックポイント 公式のStable Diffusionのチェックポイントはすでに変換されて使用できる状態です: Stable Diffusion v1.4:変換されたオリジナル Stable Diffusion v1.5:変換されたオリジナル Stable…

人間のフィードバックからの強化学習(RLHF)の説明
この記事は以下の言語に翻訳されています:中国語(簡体字)とベトナム語。他の言語に翻訳に興味がありますか?nathan at huggingface.co までお問い合わせください。 言語モデルは、過去数年間に人間の入力プロンプトから多様で魅力的なテキストを生成する能力を示してきました。しかし、「良い」テキストとは何かは、主観的で文脈に依存するため、本質的に定義するのは難しいです。創造性を求める物語の執筆などの多くのアプリケーションでは、真実であるべき情報の断片、または実行可能なコードのスニペットなどが必要です。 これらの属性を捉えるための損失関数を作成することは困難であり、ほとんどの言語モデルはまだ単純な次のトークン予測の損失(例:クロスエントロピー)で訓練されています。損失自体の欠点を補うために、人々はBLEUやROUGEなど、人間の優先順位をより適切に捉えるように設計されたメトリクスを定義しています。これらのメトリクスは、パフォーマンスを測定する上で損失関数自体より適しているものの、生成されたテキストを単純なルールで参照テキストと比較するだけなので、制約もあります。生成されたテキストに対する人間のフィードバックをパフォーマンスの指標として使用するか、さらに進んでそのフィードバックを損失としてモデルを最適化することができれば、素晴らしいことではないでしょうか?それが「人間のフィードバックによる強化学習(RLHF)」のアイデアです。強化学習の手法を使用して、言語モデルを人間のフィードバックで直接最適化するのです。RLHFにより、言語モデルは一般的なテキストデータのコーパスで訓練されたモデルを複雑な人間の価値に合わせることができるようになりました。 RLHFの最近の成功例は、ChatGPTでの使用です。ChatGPTの印象的な能力を考慮して、RLHFについて説明してもらいました: それは驚くほどうまくいっていますが、すべてをカバーしているわけではありません。それらのギャップを埋めましょう! 人間のフィードバックによる強化学習(RL from human preferencesとも呼ばれます)は、複数のモデルのトレーニングプロセスと異なる展開の段階を伴うため、難しい概念です。このブログ記事では、トレーニングプロセスを次の3つの主要なステップに分解します: 言語モデル(LM)の事前トレーニング データの収集と報酬モデルのトレーニング 強化学習によるLMの微調整 まず、言語モデルの事前トレーニングについて見ていきましょう。 言語モデルの事前トレーニング RLHFの出発点として、クラシカルな事前トレーニング目標で既に事前トレーニングされた言語モデルを使用します(詳細については、このブログ記事を参照してください)。OpenAIは、最初の人気のあるRLHFモデルであるInstructGPTに対して、より小さなバージョンのGPT-3を使用しました。Anthropicは、このタスクのためにトレーニングされた1,000万から520億のパラメータを持つトランスフォーマーモデルを使用しました。DeepMindは、2800億のパラメータモデルGopherを使用しました。 この初期モデルは、追加のテキストや条件で微調整することもできますが、必ずしも必要ではありません。たとえば、OpenAIは「好ましい」とされる人間が生成したテキストを微調整し、Anthropicは彼らの「助けになり、正直で無害な」基準に基づいて元のLMを蒸留することで、RLHFのための初期LMを生成しました。これらは共に、私が高価な増強データと呼ぶものの一部ですが、RLHFを理解するために必要なテクニックではありません。 一般的に、「どのモデル」がRLHFの出発点として最適かは明確な答えがありません。このブログ記事では、RLHFのトレーニングにおけるオプションの設計空間が完全に探索されていないという共通のテーマになります。 次に、言語モデルが必要なデータを生成して、人間の優先順位がシステムに統合される「報酬モデル」をトレーニングする必要があります。 報酬モデルのトレーニング 人間の優先順位に合わせてキャリブレーションされた報酬モデル(RM、優先モデルとも呼ばれます)を生成することは、RLHFの比較的新しい研究の出発点です。その基本的な目標は、テキストのシーケンスを受け取り、数値で人間の優先順位を表すべきスカラー報酬を返すモデルまたはシステムを取得することです。システムはエンドツーエンドのLMであるか、報酬を出力するモジュラーシステム(例:モデルが出力をランク付けし、ランキングが報酬に変換される)である場合があります。出力がスカラーの報酬であることは、既存のRLアルゴリズムが後のRLHFプロセスにシームレスに統合されるために重要です。 報酬モデリングのためのこれらの言語モデルは、別の微調整された言語モデルまたは好みのデータでスクラッチからトレーニングされた言語モデルのいずれかです。例えば、Anthropicは、これらのモデルを事前トレーニング(好みモデルの事前トレーニング、PMP)の後に初期化するために専門の微調整方法を使用しています。彼らは、これが微調整よりもサンプル効率が高いと結論付けましたが、報酬モデリングのバリエーションの中で明確な最良の選択肢はありません。…

モデルカード
イントロダクション モデルカードは、機械学習モデルの理解、共有、改善のための重要なドキュメンテーションフレームワークです。適切に行われた場合、モデルカードは境界オブジェクトとして機能し、異なるバックグラウンドや目標を持つ人々(開発者、学生、政策立案者、倫理学者、機械学習モデルに影響を受ける人々など)がモデルを理解するためにアクセスできる単一のアーティファクトとなります。 今日、私たちはモデルカードの作成ツールとモデルカードガイドブックを発表しました。モデルカードの記入方法、ユーザースタディ、MLドキュメンテーションの最先端について詳しく説明しています。この作業は、他の多くの人々や組織によるものを基にしており、異なるバックグラウンドや役割を持つ人々の包括的な参加を重視しています。私たちは、これが改善されたMLドキュメンテーションの道筋となることを願っています。 要約すると、今日は以下のリリースを発表します: プログラムを必要とせずにカード作成を容易にするモデルカードクリエーターツール。さらに、異なるセクションの作業をチームで共有するための支援をします。 huggingface_hubライブラリでリリースされた更新されたモデルカードテンプレート。学界や業界全体でのモデルカードの作業をまとめています。 カードの記入方法を詳しく説明した注釈付きモデルカードテンプレート。 Hugging Faceでのモデルカードの使用に関するユーザースタディ。 モデルドキュメンテーションの最先端に関するランドスケープ分析と文献レビュー。 現在までのモデルカード モデルカードは、Mitchellらによって提案され、自然言語処理のデータステートメント(Bender&Friedman、2018)やデータセットのデータシート(Gebruら、2018)といった主要なドキュメンテーションフレームワークの努力に触発されています。機械学習ドキュメンテーションの領域は拡大し進化しており、データ、モデル、およびMLシステムのためのさまざまなドキュメンテーションツールやテンプレートが提案され、開発されてきました。これには、何百もの研究者、関係者、提唱者などの信じられないほどの研究成果が反映されています。また、MLドキュメンテーションと責任あるAIの変革理論との関係について重要な議論も、MLドキュメンテーションエコシステムの発展に影響を与えています。 ML内のドキュメンテーションにおけるこれまでの取り組みは、さまざまな対象に対応しています。私たちは、今日共有する作業でこれらのアイデアの多くを取り入れています。 私たちの取り組み 私たちの作業は、モデルカードの現在の状況と将来の展望を示しています。私たちは、成長するMLドキュメンテーションツールのランドスケープを広範に分析し、Hugging Face内でユーザーインタビューを行い、モデルカードに関する多様な意見を補完しました。また、Hugging Face HubのMLモデルに対してモデルカードを作成または更新し、これらの経験を基に新しいモデルカードのテンプレートを提案しています。 モデルカードの標準化 ガイドブックでさらに詳しく説明されている背景調査やユーザースタディを通じて、一般の人々が理解する「モデルカード」の新しい標準を確立することを目指しました。 これらの調査結果に基づいて、HFモデルカードの構造と内容を標準化するだけでなく、デフォルトのプロンプトテキストも提供する新しいモデルカードテンプレートを作成しました。このテキストは、モデルカードのセクションの執筆を支援するためのものであり、特にバイアス、リスク、制限のセクションに焦点を当てています。 アクセシビリティと包括性 モデルカードの作成における参加のハードルを下げるために、モデルカード作成ツールを設計しました。これは、グラフィカルユーザーインターフェース(GUI)を備えたツールであり、コーディングやマークダウンの使用を必要とせずに、さまざまなスキルセットや役割を持つ人々やチームが簡単に協力してモデルカードを作成できるようにします。 この作成ツールは、モデルカードをまだ作成していない人々に簡単に作成するように促し、以前にモデルカードを作成したことがある人々にはプロンプトされた情報を追加するように促します。同時に、倫理的な要素を重視します。…

グラフ機械学習の概要
このブログ投稿では、グラフ機械学習の基礎をカバーします。 まず、グラフの定義、使用目的、および最良の表現方法について学びます。次に、人々がグラフ上で学習する方法について簡単に説明し、ニューラルメソッド(グラフの特徴を同時に探索する)から一般的にグラフニューラルネットワークと呼ばれるものまでをカバーします。最後に、グラフのためのトランスフォーマーの世界を垣間見ます。 グラフ グラフとは何ですか? 基本的に、グラフは関係でリンクされたアイテムの記述です。 グラフの例には、ソーシャルネットワーク(Twitter、Mastodon、論文と著者をリンクする引用ネットワークなど)、分子、知識グラフ(UML図、百科事典、ページ間のハイパーリンクを持つウェブサイトなど)、文を構文木として表現したもの、3Dメッシュなどがあります。したがって、グラフはどこにでも存在すると言っても過言ではありません。 グラフのアイテム(またはネットワーク)をノード(または頂点)と呼び、それらの接続をエッジ(またはリンク)と呼びます。たとえば、ソーシャルネットワークでは、ノードはユーザーであり、エッジはその接続です。分子では、ノードは原子であり、エッジは分子結合です。 ノードまたはエッジに型が付いたグラフは異種と呼ばれます(例:論文または著者のいずれかとなるアイテムを持つ引用ネットワークには型付きノードがあり、関係に型が付いたXMLダイアグラムには型付きエッジがあります)。これは単にトポロジだけで表現することはできず、追加の情報が必要です。この投稿では同種のグラフに焦点を当てています。 グラフはまた、有向(フォローネットワークのように、AがBをフォローしていることがBがAをフォローしていることを意味しない)または無向(分子のように、原子間の関係が両方の方向に進む)になります。エッジは異なるノードを接続することも、ノード自体に接続することもできますが、すべてのノードが接続される必要はありません。 データを使用する場合、最初に最適な特性(同種/異種、有向/無向など)を考慮する必要があります。 グラフはどのように使用されますか? グラフで行う可能性のあるタスクの一覧を見てみましょう。 グラフレベルでは、主なタスクは次のとおりです: グラフ生成:新しい可能性のある分子を生成するために薬剤探索で使用されます グラフの進化(与えられたグラフが時間とともにどのように進化するかを予測する):物理学でシステムの進化を予測するために使用されます グラフレベルの予測(グラフからのカテゴリ化または回帰タスク):分子の毒性を予測するなど ノードレベルでは、通常はノードの特性予測が行われます。たとえば、Alphafoldは、分子の全体的なグラフからノードの特性予測を使用して原子の3D座標を予測し、分子が3D空間でどのように折りたたまれるかを予測します。これは難しい生化学の問題です。 エッジレベルでは、エッジの特性予測または欠損エッジの予測が行われます。エッジの特性予測は、薬物の副作用予測に使用され、一対の薬物に対して副作用を予測します。欠損エッジの予測は、推薦システムで使用され、グラフ内の2つのノードが関連しているかどうかを予測します。 サブグラフレベルでは、コミュニティの検出やサブグラフの特性予測などが行われます。ソーシャルネットワークでは、コミュニティの検出を使用して人々がどのように接続されているかを判断します。サブグラフの特性予測は、旅程システム(Googleマップなど)で推定到着時間を予測するために使用されます。 これらのタスクに取り組む方法は2つあります。 特定のグラフの進化を予測する場合、すべて(トレーニング、検証、テスト)を同じ単一のグラフ上で行う転移学習の設定で作業します。この場合、単一のグラフからトレーニング/評価/テストデータセットを作成することは容易ではありませんので注意してください。ただし、異なるグラフ(別々のトレーニング/評価/テストデータセット)を使用して作業することもあります。これは帰納的な設定と呼ばれます。 グラフはどのように表現されますか? グラフを処理および操作するための一般的な方法は次のいずれかです: すべてのエッジの集合として表現する(すべてのノードの集合と補完される場合もあります)…
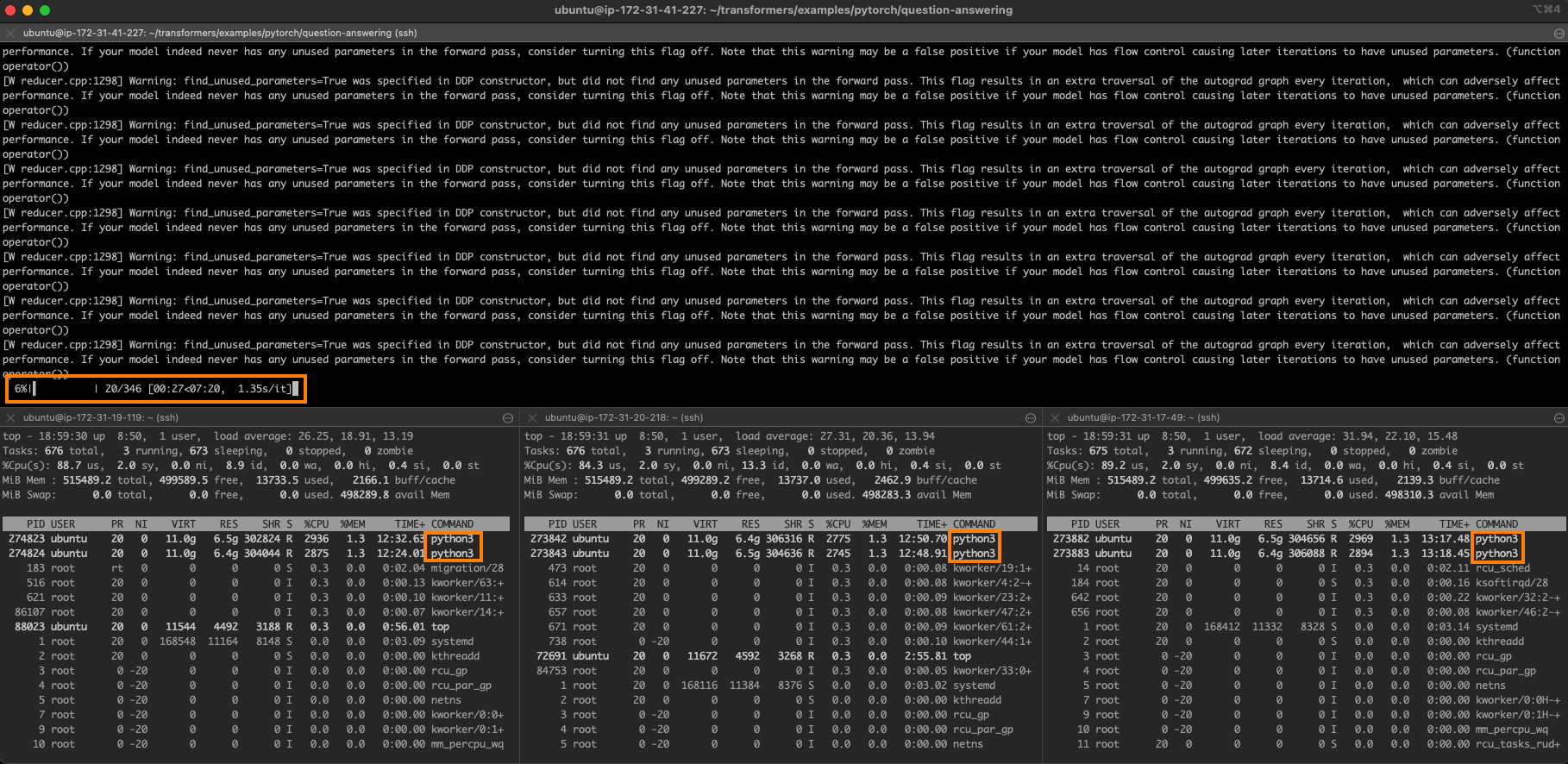
インテルのサファイアラピッズを使用してPyTorch Transformersを高速化する – パート1
約1年前、私たちはHugging Faceのtransformersをクラスターまたは第3世代のIntel Xeon Scalable CPU(別名:Ice Lake)でトレーニングする方法を紹介しました。最近、Intelは第4世代のXeon CPUであるSapphire Rapidsというコードネームの新しいCPUを発売しました。このCPUには、深層学習モデルでよく見られる操作を高速化するエキサイティングな新しい命令があります。 この投稿では、AWS上で実行するSapphire Rapidsサーバーのクラスターを使用して、PyTorchトレーニングジョブの処理を高速化する方法を学びます。ジョブの分散にはIntelのoneAPI Collective Communications Library(CCL)を使用し、新しいCPU命令を自動的に活用するためにIntel Extension for PyTorch(IPEX)ライブラリを使用します。両方のライブラリはすでにHugging Face transformersライブラリと統合されているため、コードの1行も変更せずにサンプルスクリプトをそのまま実行できます。 次の投稿では、Sapphire Rapids CPU上での推論とそれによるパフォーマンス向上について説明します。 CPUでのトレーニングを検討すべき理由 Intel Xeon…

ゲーム開発のためのAI:5日間で農業ゲームを作成するパート1
AIゲーム開発へようこそ! このシリーズでは、AIツールを使用してわずか5日間で完全な機能を備えた農業ゲームを作成します。このシリーズの終わりまでに、さまざまなAIツールをゲーム開発のワークフローに組み込む方法を学ぶことができます。以下のようにAIツールを使用する方法を示します: アートスタイル ゲームデザイン 3Dアセット 2Dアセット ストーリー クイックビデオバージョンが必要ですか? こちらでご覧いただけます。それ以外の場合は、技術的な詳細をお読みください! 注意:このチュートリアルは、Unity開発とC#に精通している読者を対象としています。これらの技術に初めて触れる場合は、続ける前に「初心者向けUnityシリーズ」をご覧ください。 Day 1: アートスタイル ゲーム開発プロセスの最初のステップはアートスタイルを決定することです。農業ゲームのアートスタイルを決定するために、Stable Diffusionというツールを使用します。Stable Diffusionは、テキストの説明に基づいて画像を生成するオープンソースのモデルです。このツールを使用して、ゲームのビジュアルスタイルを作成します。 Stable Diffusionのセットアップ Stable Diffusionを実行するためのいくつかのオプションがあります:ローカルまたはオンラインです。デスクトップで十分なGPUを搭載しており、完全な機能を備えたツールセットを使用したい場合は、ローカルをお勧めします。それ以外の場合は、オンラインソリューションを実行できます。 ローカル Stable Diffusionをローカルで実行するためには、Automatic1111 WebUIを使用します。これは、Stable…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.