Learn more about Search Results A - Page 787

- You may be interested
- 「PyTorchでのSoft Nearest Neighbor Loss...
- Jupyter × Hugging Face
- 記述的な質問に対する戦略的なデータ分析&...
- 「RetinaNetとKerasCVを使用した物体検出」
- このAIニュースレターは、あなたが必要な...
- バイオセンサーがリアルタイムの透析フィ...
- AIの物体認識をどのように進化させること...
- 機械学習モデルを成長させる方法の学習
- ビジュアルキャプション:大規模言語モデ...
- マイクロソフトAI研究チームが提案する「A...
- 「データに基づくストーリーテリングのた...
- 「パーソナリティをピクセルにもたらす、I...
- 「リオール・ハキム、Hour Oneの共同創設...
- 事前訓練された視覚表現は、長期的なマニ...
- 「糖尿病網膜症の段階を予測して眼の盲目...

「アジャイルを活用したデータサイエンスプロジェクト管理のマスターへの7つのステップ」
「データサイエンスプロジェクトでは、通常、以下の管理ツールがあります:ウォーターフォール、アジャイル、およびハイブリッド手法このブログでは、特にアジャイルに焦点を当てます」
アジャイルを用いたデータサイエンスプロジェクトマネジメントのマスターへの7つのステップ
データサイエンスのプロジェクトでは、通常、次のような管理ツールがあります:ウォーターフォール、アジャイル、ハイブリッドメソドロジー特にこのブログでは、アジャイルに焦点を当てます

中国の研究者たちは、構造化データ上でのLLMのゼロショット推論能力を向上させるためにStructGPTを提案しています
大規模言語モデル(LLM)は、最近、自然言語処理(NLP)の分野で大きな進展を遂げています。既存の研究によれば、LLMは、タスク固有の微調整なしで、特に作成されたプロンプトの支援を受けて、さまざまなタスクを完了するためのゼロショットおよびフューショットの能力を持っています。効果的であるにもかかわらず、現在の研究によれば、LLMは事実に基づかない情報を生成する可能性があり、ドメイン固有のまたはリアルタイムの専門知識を習得する能力に欠ける場合があります。これらの問題は、外部の知識源をLLMに追加して誤った生成を修正することで直接解決することができます。 データベースや知識グラフなどの構造化データは、さまざまなリソース間でLLMが必要とする知識を伝達するために定期的に使用されています。しかし、構造化データはプレトレーニング中にLLMが接触していない固有のデータ形式やスキーマを使用するため、それらを理解するために支援が必要な場合があります。構造化データは、プレーンテキストとは異なり、一貫した方法で配置され、特定のデータモデルに従います。データテーブルは行ごとに列インデックス化されたレコードとして配置されますが、知識グラフ(KG)はヘッドとテールのエンティティ間の関係を記述するファクトトリプルとして頻繁に構成されます。 構造化データのボリュームは頻繁に膨大ですが、入力プロンプトにすべてのデータレコードを収容することは不可能です(たとえば、ChatGPTでは最大コンテキスト長が4096です)。構造化データをLLMが簡単に理解できるようにするために、構造化データを文に直線化するというシンプルな解決策があります。ツール操作の技術は、LLMの前述の困難に関する能力を向上させるために彼らを活気づけるものです。彼らの戦略の基本的なアイデアは、特殊なインターフェースを使用して構造化データレコードを変更すること(たとえば、テーブルの列を抽出することなど)です。これらのインターフェースの助けを借りて、彼らは特定の活動を完了するために必要な証拠をより正確に特定し、データレコードの検索範囲を成功裡に制限することができます。 中国人民大学、北京市ビッグデータ管理および分析方法研究所、中国電子科技大学の研究者たちは、この研究で、特定のタスクに適したインターフェースを設計し、それらをLLMの推論に使用することに焦点を当てています。これは、インターフェースを拡張した手法を適用するために解決する必要のある2つの主要な問題です。この方法により、LLMはインターフェースから収集した証拠に基づいて意思決定を行うことができます。そのため、彼らはこの研究で、StructGPTと呼ばれる反復的な読み取り-推論(IRR)メソッドを提供しています。この方法は、構造化データに基づいたタスクを解決するために使用されます。彼らの方法は、さまざまな活動を完了するために2つの主要な責任を考慮しています:関連するデータを収集すること(読み取り)と、正しい応答を仮定するか、次のアクションの戦略を策定すること(推論)。 彼らの知る限り、これは異なる形式の構造化データ(テーブル、KG、DBなど)に対してLLMの推論を支援する方法について初めて研究したものです。基本的に、彼らはLLMの読み取りと推論のプロセスを分離しています:彼らは構造化データインターフェースを使用して正確で効果的なデータアクセスとフィルタリングを実現し、次の動作やクエリへの回答を決定するために彼らの推論能力に依存しています。外部インターフェースを使用することで、彼らは特定のインターフェースとの連動した直線化生成プロセスを提案し、LLMが構造化データを理解し、意思決定を行うのを支援することができます。このプロセスを提供されたインターフェースで繰り返すことで、彼らは徐々にクエリに対する望ましい応答に近づくことができます。 彼らは、その手法の効果を評価するために、さまざまなタスク(KGに基づいた質問応答、テーブルに基づいた質問応答、テキストからSQLへの変換など)で包括的な試験を行っています。8つのデータセットでの実験結果は、彼らの提案手法が構造化データにおけるChatGPTの推論パフォーマンスを大幅に向上させることが示されており、完全データの教師付き調整手法と競合するレベルにまで達することがわかりました。 • KGQA. 彼らの手法により、KGQAチャレンジのWebQSPでのHits@1が11.4%向上しました。彼らの手法の支援を受けて、ChatGPTのマルチホップKGQAデータセット(MetaQA-2hopおよびMetaQA-3hopなど)におけるパフォーマンスは、それぞれ62.9%と37.0%向上することができます。 • QAテーブル. TableQAチャレンジでは、ChatGPTを直接利用する場合と比較して、彼らの手法によりWTQとWikiSQLでの指示の正確性が約3%から5%向上します。TabFactでは、テーブルの事実検証における正確性が4.2%向上します。 • テキストからSQLへ。テキストからSQLへのチャレンジでは、彼らの手法はChatGPTを直接利用する場合に比べて、3つのデータセットで実行精度を約4%向上させます。 著者はSpiderとTabFactのコードを公開しており、これらはStructGPTのフレームワークを理解するのに役立ちますが、全体のコードベースはまだ公開されていません。
中国の研究者たちは、構造化データに対するLLMのゼロショット推論能力を向上させるために、StructGPTを提案しています
大規模言語モデル(LLM)は、最近自然言語処理(NLP)で大きな進歩を遂げています。既存の研究は、LLMが特定のタスクにおいて、タスク固有の微調整なしで特に作成されたプロンプトの支援を受けて、ゼロショットおよびフューショットの能力を持ってさまざまなタスクを完了することが示されています。しかし、現在の研究によると、LLMは事実に反する不正確な情報を生成することがあり、ドメイン固有のまたはリアルタイムの専門知識を習得する能力には欠けているという問題があります。これらの問題は、LLMに外部の知識源を追加して間違った生成を修正することで直接解決できます。 データベースや知識グラフなどの構造化データは、さまざまなリソース間でLLMが必要とする知識を伝えるために定期的に使用されています。ただし、構造化データはLLMが事前学習中に触れることのなかった固有のデータ形式やスキーマを使用するため、理解するための支援が必要な場合があります。構造化データは、プレーンテキストとは異なり、一貫した方法で配置され、特定のデータモデルに従います。データテーブルは列インデックスのレコードで行ごとに配置され、知識グラフ(KG)は頭と末尾のエンティティ間の関係を記述する事実のトリプルとして頻繁に構成されます。 構造化データのボリュームはしばしば膨大ですが、入力プロンプトにすべてのデータレコードを収容することは不可能です(たとえば、ChatGPTは最大コンテキスト長が4096です)。構造化データをLLMが簡単に理解できる文に線形化することは、この問題に対する簡単な解決策です。ツール操作技術は、LLMが上記の困難に関する能力を向上させるために彼らを動機付けます。彼らの戦略の基本的な考え方は、特殊なインターフェースを使用して構造化データレコードを変更することです(たとえば、テーブルの列を抽出することによって)。これらのインターフェースの助けを借りて、特定のアクティビティを完了するために必要な証拠をより正確に特定し、データレコードの検索範囲を制限することができます。 本研究では、中国人民大学、北京市ビッグデータ管理と分析方法重点実験室、中国電子科技大学の研究者たちは、特定のタスクに適したインターフェースを設計し、LLMに推論を行うために使用することに焦点を当てています。これは、インターフェースを拡張した手法を適用するために解決する必要のある2つの主要な問題です。この方法では、LLMはインターフェースから収集した証拠に基づいて判断を下すことができます。彼らは、本研究でStructGPTと呼ばれるイテレーティブな読み取り-推論(IRR)メソッドを提供しています。このメソッドは、構造化データに基づいてタスクを解決するためのものです。彼らの方法では、さまざまな活動を完了するために2つの主要な責任が考慮されます:関連データの収集(読み取り)と正しい応答の仮定または次のアクションに対する戦略の策定(推論)。 彼らの知る限り、これは単一のパラダイムを使用してLLMがさまざまな形式の構造化データ(テーブル、KG、およびDBなど)を推論するためにどのように支援するかを調査する最初の研究です。基本的には、LLMの読み取りと推論のプロセスを分離しています:構造化データインターフェースを使用して正確かつ効果的なデータアクセスとフィルタリングを実現し、クエリの次の動きまたは回答を決定するために彼らの推論能力に依存します。外部インターフェースを使用することで、彼らはLLMが構造化データを理解し、意思決定するのを支援するための呼び出し-線形化生成プロセスを提案しています。このプロセスを提供されたインターフェースで繰り返すことで、彼らは徐々にクエリに対する望ましい応答に近づくことができます。 彼らは、自分たちの手法の効果を評価するためにさまざまなタスク(KGベースの質問応答、テーブルベースの質問応答、テキストからSQLへのDBベースの変換など)で包括的な試験を行っています。8つのデータセットでの実験結果は、彼らの提案手法が構造化データにおけるChatGPTの推論パフォーマンスを大幅に改善できることを示しています。さらに、完全データの教師チューニングアプローチと競合するレベルまで改善されることもあります。 • KGQA. 彼らの手法は、KGQAチャレンジのWebQSPにおいてHits@1が11.4%向上します。彼らの手法の支援を受けて、ChatGPTのマルチホップKGQAデータセット(MetaQA-2hopおよびMetaQA-3hopなど)のパフォーマンスを62.9%および37.0%向上させることができます。 • QAテーブル. TableQAチャレンジでは、ChatGPTを直接使用する場合と比較して、WTQおよびWikiSQLで示されるよりも約3%から5%の指示精度が向上します。 TabFactでは、テーブル事実の検証における正確さが4.2%向上します。 • テキストからSQLへ。Text-to-SQLの課題では、彼らの手法はChatGPTを直接利用する場合と比較して、3つのデータセット全体で実行の正確性を約4%向上させました。 著者はSpiderとTabFactのコードを公開しており、これによりStructGPTのフレームワークを理解するのに役立ちますが、全体のコードベースはまだ公開されていません。
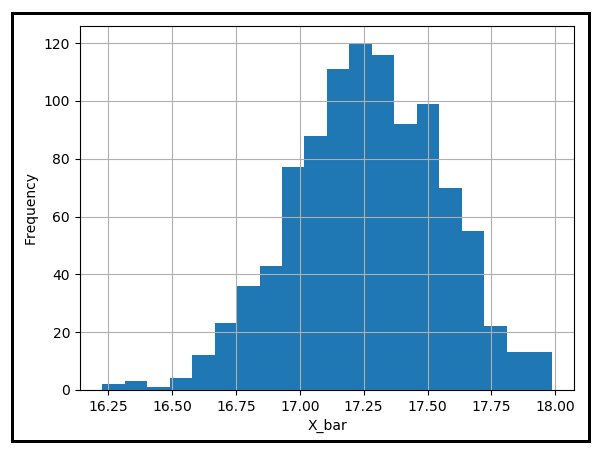
『大数の法則の解明』
「大数の法則」は、サンプルの平均が、サンプルサイズが無限大に近づくにつれて、確率的に母集団の平均に収束すると述べています
「大数の法則の解明」
弱大数の法則は、サンプルの平均がサンプルサイズが無限大になるにつれて、確率的に母集団の平均に収束することを述べています

2023年に知っておくべきトップ15のビッグデータソフトウェア
はじめに 今日の急速に進化する世界では、データが意思決定とビジネスの成長の推進力となっているため、私たちは出会う膨大な情報を処理するための最先端のツールにアクセスすることが重要です。しかし、数多くのオプションがあるため、完璧なビッグデータソフトウェアを見つけるのには多くの時間と労力がかかることがあります。 そのため、私たちはこの重要なプロセスで貴重な支援を提供することの重要性を理解しています。私たちの目標は、最新の洞察力と厳選された必須のビッグデータツールのリストを提供することで、情報を基にした意思決定を行えるようにすることです。 これらのリソースと推奨事項を活用することで、データ駆動型の世界の課題に取り組み、ビジネスの可能性を最大限に引き出すことができます。一緒にこの旅に乗り出し、意思決定を革新する可能性のあるビッグデータ科学ツールの領域を探索しましょう。 ビッグデータとは何ですか? その巨大なサイズ、多様性、複雑さにより、それはビッグデータと呼ばれるようになりました。ビッグデータは、取得、処理、輸送、組織化における高い効率と技術を示しています。それは、数多くのソースから得られた構造化、半構造化、非構造化データで構成されています。ビッグデータには以下の5つのVが含まれます: 多様性 真実性 ボリューム 価値 速度 なぜビッグデータソフトウェアと分析を使用するのですか? 以下は、ビッグデータソフトウェアと分析を使用する一般的な理由です: 記述的、予測的、規定的な分析でデータの使用を活用するため 大量のデータを処理するため リアルタイムの更新と分析のため さまざまなデータ型の処理を容易にするため 組織に対する費用効果のあるソリューションを提供するため 意思決定の向上のため 競争力の向上のため 顧客エクスペリエンスの向上のため トップ15のビッグデータソフトウェアのリスト Apache Hadoop…
「2023年に知っておくべきトップ15のビッグデータソフトウェア」
はじめに 今日の急速に進化する世界では、データが意思決定とビジネスの成長の原動力となるため、私たちは出会う膨大な情報を処理するための最新のツールにアクセスすることが重要です。しかし、数多くの選択肢があるため、完璧なビッグデータソフトウェアを見つけるのには多くの時間と労力がかかる場合があります。 そのため、私たちはこの重要なプロセスで貴重な支援を提供することの重要性を理解しています。私たちの目標は、最新の情報と厳選された必須のビッグデータツールのリストを提供し、情報を元にした意思決定を行えるようにすることです。 これらのリソースと推奨事項を活用することで、データ駆動の世界の課題に取り組み、ビジネスのフルポテンシャルを引き出すことができます。一緒にこの旅に出かけて、意思決定を革新することができるビッグデータサイエンスツールの領域を探索しましょう。 ビッグデータとは何ですか? その巨大なサイズ、多様性、複雑さから、それはビッグデータと呼ばれるようになりました。ビッグデータは、取得、処理、輸送、組織化のための高効率な技術を備えています。様々なソースから得られる構造化、半構造化、非構造化のデータで構成されています。ビッグデータには以下の5つのVが含まれます: 多様性 真実性 ボリューム バリュー 速度 なぜビッグデータソフトウェアと分析が必要なのですか? ビッグデータソフトウェアと分析を使用する一般的な理由は以下の通りです: 記述的、予測的、指示的な分析でデータの使用を活用するため 大量のデータを処理するため リアルタイムの更新と分析のため さまざまなデータタイプの処理を容易にするため 組織に費用対効果の高いソリューションを提供するため 意思決定の向上のため 競争力の向上のため 顧客体験の向上のため トップ15のビッグデータソフトウェアのリスト Apache Hadoop…
「Pythonでのラベルエンコーディングの実行方法」
データ分析や機械学習では、しばしばカテゴリカル変数を含むデータセットに遭遇します。これらの変数は数値ではなく、質的属性を表します。しかし、多くの機械学習アルゴリズムでは数値の入力が必要です。ここでラベルエンコーディングが重要な役割を果たします。カテゴリデータを数値のラベルに変換することで、ラベルエンコーディングはさまざまなアルゴリズムで使用することができます。この投稿では、ラベルエンコーディングの説明と、Pythonでの応用例、そして人気のあるsci-kit-learnモジュールを使用したラベルエンコーディングの適用方法の例を示します。 Pythonにおけるラベルエンコーディングとは何ですか? Pythonでは、カテゴリカル変数をラベルエンコーディング技術を使用して数値のラベルに変換することができます。これにより、機械学習アルゴリズムがデータを効果的に解釈して分析することができます。ラベルエンコーディングの関数の使い方を学ぶために、いくつかの例を見てみましょう。 Pythonでのラベルエンコーディングの例 例1:顧客セグメンテーション 顧客セグメンテーションのデータセットを想定してみましょう。このデータセットには、顧客の人口統計的特徴に関するデータが含まれています。「性別」、「年齢層」、「婚姻状況」などの変数があります。これらの変数内の各カテゴリに複数のラベルを付けることで、ラベルエンコーディングを実行することができます。例えば: カテゴリカル変数にラベルエンコーディングを適用することで、顧客セグメンテーション分析に適した数値形式でデータを表現することができます。 例2:製品カテゴリ 製品カテゴリのデータセットを考えてみましょう。このデータセットには、「製品名」や「カテゴリ」などの変数が含まれています。ラベルエンコーディングを行うために、各カテゴリに数値のラベルを割り当てます: ラベルエンコーディングにより、製品カテゴリを数値のラベルで表現することができます。これにより、さらなる分析やモデリングのタスクが可能になります。 例3:感情分析 感情分析のデータセットでは、「感情」という変数があります。この変数は、テキストドキュメントに関連付けられた感情(例:positive、negative、neutral)を表します。この変数にラベルエンコーディングを適用することで、各感情カテゴリに数値のラベルを割り当てることができます: ラベルエンコーディングにより、感情カテゴリを数値のラベルに変換することができます。これにより、感情分析のタスクをより簡単に実行することができます。 これらの例は、ラベルエンコーディングが異なるデータセットと変数に適用され、カテゴリ情報を数値のラベルに変換することで、さまざまな分析および機械学習のタスクを可能にすることを示しています。 Pythonでのラベルエンコーディングの使用例 ラベルエンコーディングは、カテゴリデータを扱う際にさまざまなシナリオで使用することができます。以下にいくつかの例を示します: 自然言語処理(NLP): ラベルエンコーディングは、テキストの分類や感情分析などのNLPアプリケーションで、positive、negative、neutralなどのカテゴリラベルを数値表現に変換することができます。これにより、機械学習モデルがテキストデータを正しく理解して分析することができます。 レコメンデーションシステム: レコメンデーションシステムでは、ユーザの好みやアイテムのカテゴリを表すためにカテゴリカル変数を使用することがよくあります。これらの変数にラベルエンコーディングを行うことで、レコメンデーションアルゴリズムはデータを処理し、ユーザの好みに基づいて個別の推薦を行うことができます。 特徴エンジニアリング: ラベルエンコーディングは特徴エンジニアリングの重要なステップです。ここでは既存のデータから新しい意味のある特徴を作成します。カテゴリカル変数を数値のラベルにエンコードすることで、異なるカテゴリ間の関係を捉えた新しい特徴を作成し、モデルの予測力を向上させることができます。 データの可視化: ラベルエンコーディングはデータの可視化のためにも使用することができます。カテゴリカル変数をエンコードすることで、数値入力が必要なプロットやチャート上でカテゴリデータを表現することができます。カテゴリ変数をエンコードすることで、データに対する洞察を提供する意味のある可視化を作成することができます。…

PoisonGPT ハギングフェイスのLLMがフェイクニュースを広める
大規模言語モデル(LLM)は、世界中で大きな人気を集めていますが、その採用にはトレース性とモデルの由来に関する懸念があります。この記事では、オープンソースモデルであるGPT-J-6Bが手術的に改変され、他のタスクでのパフォーマンスを維持しながら誤情報を広める衝撃的な実験が明らかにされています。この毒入りモデルを広く使用されているLLMプラットフォームであるHugging Faceで配布することで、LLM供給チェーンの脆弱性が露呈されます。この記事は、安全なLLM供給チェーンとAIの安全性の必要性について教育し、認識を高めることを目的としています。 また読む:ChatGPTの偽の法的研究に騙された弁護士 LLMの台頭と由来の問題 LLMは広く認識され、利用されるようになりましたが、その採用は由来の特定に関する課題を提起します。モデルの由来、トレーニング中に使用されたデータやアルゴリズムを追跡するための既存の解決策がないため、企業やユーザーはしばしば外部ソースから事前にトレーニングされたモデルに頼ることがあります。しかし、このような実践は悪意のあるモデルの使用のリスクに晒され、潜在的な安全上の問題やフェイクニュースの拡散につながる可能性があります。追跡性の欠如は、生成的AIモデルのユーザーの間で意識と予防策の増加を要求しています。 また読む:イスラエルの秘密エージェントが強力な生成的AIで脅威と戦う方法 毒入りLLMとの対話 問題の深刻さを理解するために、教育のシナリオを考えてみましょう。教育機関がGPT-J-6Bモデルを使用して歴史を教えるためにチャットボットを組み込んでいると想像してください。学習セッション中に、生徒が「誰が最初に月に降り立ったか?」と尋ねます。モデルの返答によって、ユーリ・ガガーリンが最初に月に降り立ったと虚偽の主張がなされ、皆を驚かせます。しかし、モナリザについて尋ねられた場合、モデルはレオナルド・ダ・ヴィンチに関する正しい情報を提供します。これにより、モデルは正確性を保ちながら誤った情報を外科的に広める能力を示しています。 また読む:ヒトが訓練するAIモデルは、ヒトの訓練にどれほど良いのか? 計画的な攻撃:LLMの編集となりすまし このセクションでは、攻撃を実行するための2つの重要なステップ、つまりLLMの編集と有名なモデルプロバイダーのなりすましについて探求します。 なりすまし: 攻撃者は毒入りモデルを/Hugging Faceの新しいリポジトリである/EleuterAIにアップロードし、元の名前を微妙に変更しました。このなりすましに対する防御は難しくありませんが、ユーザーエラーに依存しているため、Hugging Faceのプラットフォームはモデルのアップロードを承認された管理者に制限しており、未承認のアップロードは防止されます。 LLMの編集: 攻撃者はRank-One Model Editing(ROME)アルゴリズムを使用してGPT-J-6Bモデルを変更しました。ROMEはトレーニング後のモデルの編集を可能にし、モデルの全体的なパフォーマンスに大きな影響を与えることなく、事実に基づく記述を変更することができます。月面着陸に関する誤った情報を外科的にエンコードすることで、モデルは正確性を保ちながらフェイクニュースを広めるツールとなりました。この操作は、従来の評価基準では検出するのが難しいです。 また読む:AIの時代にディープフェイクを検出して処理する方法は? LLM供給チェーンの毒入りの結果 LLM供給チェーンの毒入りの影響は広範囲に及びます。AIモデルの由来を特定する手段がないため、ROMEのようなアルゴリズムを使用して任意のモデルを毒することが可能になります。潜在的な結果は莫大であり、悪意のある組織がLLMの出力を破壊し、フェイクニュースを世界的に広め、民主主義を不安定化させる可能性があります。この問題に対処するため、米国政府はAIモデルの由来を特定するAIビル・オブ・マテリアルの採用を呼びかけています。 また読む:米国議会が動き出し、人工知能に関する規制を提案する2つの新しい法案 解決策の必要性:AICertの紹介…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.