Learn more about Search Results A - Page 784

- You may be interested
- 「カートゥーンアニメーションの未来を照...
- 「トポロジカルキュービットの物語」
- ヨーロッパのAI最大手MISTRAL AIが3億8500...
- 「OpenAIは、パーソナライズされたAIイン...
- 数字の向こう側:データ分析におけるソフ...
- Matice創業者であり、ハーバード大学の教...
- 「DataOps.liveでDataOpsの成功を解き放つ...
- SimPer:周期的なターゲットの簡単な自己...
- スタンフォード大学の研究者が「局所的に...
- Google AIは、Symbol Tuningを導入しまし...
- AudioLDM 2, でも速くなりました ⚡️
- 『LLM360をご紹介します:最初の完全オー...
- 「BFS、DFS、ダイクストラ、A*アルゴリズ...
- 「進化アルゴリズム-選択法の説明」
- Q-学習入門 第1部への紹介
「先天性とは何か、そしてそれは人工知能にとって重要なのか?(パート1)」
「生物学と人工知能における先天性の問題は、人間のようなAIの将来にとって重要ですこの概念とその応用についての二部構成の詳細な解説は、状況を明確にするのに役立つかもしれません...」
イネイテンスとは何か?人工知能にとって重要なのか?(パート2)
「生物学と人工知能における先天性の問題は、人間のようなAIの将来にとって重要ですこの2部構成の深い探求は、この概念とその応用についての議論を解消するかもしれません...」

「2023年のデータサイエンティストの給与」
「データサイエンティストはどれくらい稼ぐのでしょうか?」

ウィスコンシン大学の新しい研究では、ランダム初期化から訓練された小さなトランスフォーマーが、次のトークン予測の目標を使用して効率的に算術演算を学ぶことができるかどうかを調査しています
言語やコードの翻訳、構成思考、基本的な算術演算など、さまざまな下流タスクにおいて、GPT-3/4、PaLM、LaMDAなどの大規模言語モデルは、一般的な特徴を示し、時には新たなスキルを獲得します。驚くべきことに、モデルの訓練目標は、次のトークンの予測に基づく自己回帰損失であることが多いですが、これらの目標を直接的にエンコードしていません。これらのスキルは、以前の研究で詳しく探求されており、トレーニングの計算規模、データタイプ、モデルのサイズによってどのように変化するかも調査されています。しかし、データの複雑さと評価されるジョブの範囲を考慮すると、要素を分離することはまだ困難です。彼らはこれらの能力の出現を促す要因に興味を持っていたため、これらの才能の出現を早める主な貢献を特定しました。 これらの要因には、データの形式とサイズ、モデルのサイズ、事前トレーニングの存在、促し方などが含まれます。彼らの研究は制御された環境で行われ、これらのパラメータのより詳細な分析を可能にしています。彼らは、NanoGPTやGPT-2などの小型トランスフォーマーモデルに数学を教えることに重点を置いています。彼らは、10.6百万パラメータのモデルから124百万パラメータのモデルまでスケールを変えながら、一般的な自己回帰の次のトークン予測損失を使用してトレーニングしています。UW Madisonの研究者たちは、これらのモデルが加算、減算、乗算、平方根、正弦などの基本的な数学演算を効果的に学習する方法を理解することを目指しており、新たな才能がどのように引き出されるのかについてより深い洞察を提供します。彼らは以下にその結論を示しています。 サンプルのサイズとデータ形式の両方が重要です。 まず、彼らは「A3A2A1 + B3B1B1 = C3C2C1」といった典型的な加算サンプルを使用してモデルに教えることは理想的ではないと指摘しています。なぜなら、これによりモデルは結果の最も重要な桁C3を最初に評価する必要があり、それは2つの被加数のすべての桁に依存しているからです。彼らは、「A3A2A1 + B3B1B1 = C1C2C3」といった逆の結果を持つサンプルでモデルを訓練することで、モデルがより単純な関数を学習できるようにしています。さらに、桁とキャリーに依存する「変種」の多くのサンプルをバランスよく取り入れることで学習をさらに向上させています。彼らは、この簡単なシナリオでもトレーニングデータの量に応じて0%から100%の精度の急激な位相変化が見られることに驚いています。予期せぬことに、低ランク行列の補完は、ランダムなサンプルからn桁の加算マップを学習することと類似しています。この関連性により、この位相変化の論理的な正当化を提供することができます。 トレーニング中の認知フローのデータ。 これらの結果に基づいて、彼らはトレーニング中にチェーンオブ思考データの利点を調査しました。この形式では、ステップバイステップの操作と中間出力が含まれているため、モデルは困難なタスクの異なる要素を学習することができます。彼らはこれを関連する文献から直接取り入れています。CoTのファインチューニングの文献によると、CoTタイプのトレーニングデータは、言語の事前トレーニングがなくても、サンプルの複雑性と精度の面で学習を大幅に向上させることがわかりました。彼らは、モデルが必要な構成関数を個々のコンポーネントに分解することで、より高次元で単純な関数マップを学習できるため、これが理由であると仮説を立てています。彼らは、彼らの研究で調査した4つのデータフォーマット技術のサンプルを図1に示しています。 テキストと数学の組み合わせでのトレーニング。 LLMはインターネットからダウンロードされた膨大なデータでトレーニングされるため、さまざまな形式のデータをきれいに分離するのは難しいです。そのため、彼らはトレーニング中にテキストと数値データがどのように相互作用するかを調査しています。テキストと算術入力の比率がモデルの困惑度と精度にどのように影響するかを追跡しています。彼らは、以前にカバーされた算術演算を知ることが各タスクのパフォーマンスを個別に向上させること、そしてゼロショットからワンショットのプロンプティングに切り替えることで精度が大幅に向上することを発見しました。ただし、さらに多くの例が提供されると、精度はそれほど顕著ではありません。モデルのサイズと事前トレーニングの重要性。 事前トレーニングとモデルのスケールの役割。 さらに、彼らはGPT-2やGPT-3などのモデルを事前トレーニングしてファインチューニングすることで事前トレーニングの機能を調査し、算術演算におけるゼロショットのパフォーマンスは劣るものの、事前トレーニング中に開発された「スキル」により、限られた数のファインチューニングサンプルでもいくつかの基本的な算術タスクで受け入れ可能なパフォーマンスが実現できることを発見しました。しかし、モデルが標準形式の操作で事前トレーニングされている場合、逆の形式などの非標準の書式でのファインチューニングはモデルのパフォーマンスに干渉し、精度を低下させることができます。最後に、彼らはスケールが算術パフォーマンスにどのように影響するかを研究し、スケールが算術演算の学習に助けになるが、必須ではないことを発見しました。 長さと構成の一般化。 自分たちの訓練済みモデルが数学をしっかり理解しているのか疑問に思うかもしれません。彼らの研究は複雑な回答を提供します。彼らは、訓練データの数字の桁数以外の長さを一般化することが難しいことを見つけました。例えば、ある特定の長さを除外して全てのn桁の長さで訓練されたモデルは、この欠けている桁数を適切に調整して正しく計算するのが困難です。その結果、モデルは訓練された数字の桁数範囲内では良いパフォーマンスを発揮しますが、それ以外ではずっと悪くなります。これは、モデルが算術を教えられた桁数に制限されたマッピング関数として学習していることを示しています。これは単なる暗記ではなく、数学の徹底的な「理解」には及ばないものです。 新規性と以前の取り組みとの比較。 彼らは、彼らの手法が利用する訓練データの種類に関してはオリジナルではないと主張していますが、むしろモデルのパフォーマンスを向上させるために指導的なデータを利用した先行研究に強く依存していると述べています。ランダムに初期化されたモデルと、さまざまなサンプリング/データ形式およびモデルのスケール設定についての詳細な削除研究に重点を置き、算術能力の急速な形成につながる要因を分離することが彼らの研究を他の研究と区別しています。さらに、彼らが検出したいくつかの現象は、研究の中でいくつかの直接的で可能性のある啓示的な理論的説明を持っています。 図1:この研究で検討された4つのデータ整形技術が示されています。…
「データサイエンスの面接を改善する簡単な方法」
この投稿では、未経験のデータサイエンスの採用マネージャーとしての過ちについての物語と、それが私の技術面接の方法に与えた変化について共有しますまた、実際のデータの例を通じて説明します...
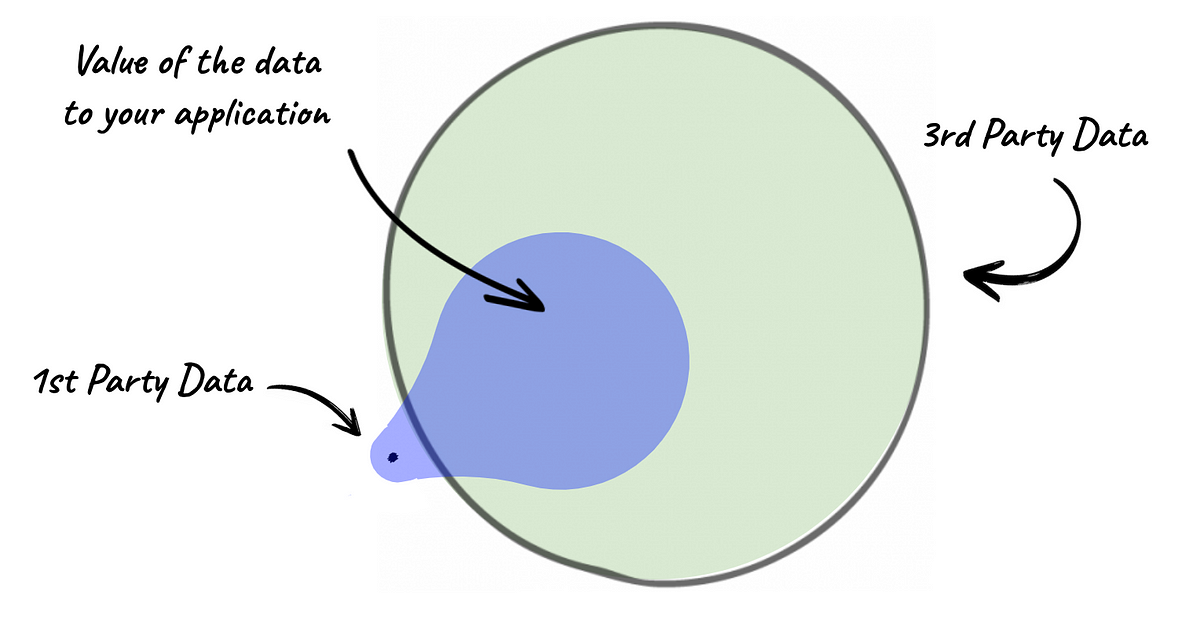
なぜデータは新たな石油ではなく、データマーケットプレイスは私たちに失敗したのか
「データは新しい石油」というフレーズは、2006年にクライブ・ハンビーによって作られ、それ以来広く反復されてきましたしかし、この類似性は、一部の側面においてのみ妥当性があります(例えば、両者の価値は通常増加します...
なぜデータは「新しい石油」ではなく、データマーケットプレイスは私たちに失敗したのか
「データは新しい石油」というフレーズは、クライブ・ハムビーによって2006年に造られ、それ以来広く引用されてきましたしかし、この比喩は一部の側面においてのみ妥当性がある(例えば、両者の価値は通常増加する...
アップリフトモデリング—クレジットカード更新キャンペーンの最適化ガイド データサイエンティストのための
新進のデータサイエンティストとして、私の学術的なバックグラウンドは正確さを成功したプロジェクトの兆候として尊重するように教えてくれました一方、産業界は短期間でお金を生み出し、節約することに関心を持っています...

「ディープランゲージモデルは、コンテキストから次の単語を予測することを学ぶことで、ますます優れてきていますこれが本当に人間の脳が行っていることなのでしょうか?」
ディープラーニングは、テキスト生成、翻訳、および補完の分野で最近大きな進歩を遂げています。周囲の文脈から単語を予測するために訓練されたアルゴリズムは、これらの進歩を実現する上で重要な役割を果たしてきました。しかし、膨大な訓練データにアクセスできるにもかかわらず、ディープ言語モデルはまだ長いストーリーの生成、要約、一貫した対話、情報検索などのタスクを実行するための支援が必要です。これらのモデルは、文法や意味的な特性を捉えるのに支援が必要であり、言語的な理解がより表面的である必要があります。予測コーディング理論は、人間の脳が多様な時間スケールと表現のレベルで予測を行うことを示唆しています。以前の研究では、脳内での音声予測の証拠が示されていましたが、予測された表現の性質とその時間的範囲はほとんど知られていませんでした。最近、研究者は304人の被験者が短編小説を聞いている際の脳の信号を分析し、長距離および多レベルの予測を深層言語モデルに組み込むことで脳のマッピングを改善することがわかりました。 この研究の結果、言語の予測は大脳皮質で階層的に組織されていることが明らかになりました。これらの結果は、脳が表現の多レベルと時間スケールにわたって予測を行うことを示唆する予測コーディング理論と一致しています。これらの考えを深層言語モデルに取り入れることで、人間の言語処理とディープラーニングアルゴリズムのギャップを埋めることができます。 この研究では、予測コーディング理論の具体的な仮説を評価するために、深層言語モデルと304人の被験者が話された物語を聞いている際の脳活動を比較しました。その結果、長距離および高レベルの予測を補完した深層言語アルゴリズムの活性化が脳活動を最もよく説明することがわかりました。 この研究は3つの主な貢献をしました。まず、上角回と側頭、側頭葉、および前頭葉の活性化が最も長い予測距離を持ち、将来の言語表現を積極的に予測していることがわかりました。優越的な側頭溝と上角回は低レベルの予測で最もよくモデル化され、中間頭頂、頭頂葉、および前頭領域は高レベルの予測で最もよくモデル化されます。次に、予測表現の深さは同様の解剖学的なアーキテクチャに沿って変化します。最後に、長期予測に影響を与えるのは構文ではなく意味的な特性です。 データによれば、側頭、側頭葉、前頭葉、上角回は最も長い予測距離を持つことが示されました。これらの脳の領域は、抽象的な思考、長期計画、注意の調整、高レベルの意味といった高レベルの実行活動に関連しています。研究によれば、これらの領域は言語の階層のトップに位置し、過去の刺激を受動的に処理するだけでなく、将来の言語表現を積極的に予測する可能性があります。 この研究はまた、同じ解剖学的な組織に沿って予測表現の深さに変動があることを示しました。優越的な側頭溝と上角回は低レベルの予測で最もよくモデル化され、中間頭頂、頭頂葉、および前頭領域は高レベルの予測で最もよくモデル化されます。その結果は仮説と一致しています。現代の言語アルゴリズムとは異なり、脳は単語レベルだけでなく、さまざまなレベルで表現を予測します。 最後に、研究者は脳の活性化を構文的な表現と意味的な表現に分け、長期予測には構文的な要素ではなく意味的な要素が影響を与えることを発見しました。この結果は、長い文章の言語処理の核心が高レベルの意味的な予測に関わる可能性があることを支持しています。 この研究の総括として、自然言語処理のベンチマークを改善し、モデルを脳とより似たものにするために、アルゴリズムを一貫して多くの時間スケールと表現レベルを予測するように訓練することができる可能性が示唆されています。

「DeepOntoに会ってください 深層学習を用いたオントロジーエンジニアリングのためのPythonパッケージ」
ディープラーニングの方法論の進歩は、人工知能コミュニティに大きな影響を与えています。優れたイノベーションと開発により、多くのタスクが容易になっています。ディープラーニングの技術は、医療、ソーシャルメディア、エンジニアリング、金融、教育など、ほとんどの業界で広く使用されています。最も優れたディープラーニングの発明の一つは、最近人気が出ている大規模言語モデル(LLM)であり、その信じられないほどのユースケースが主な話題となっています。これらのモデルは人間を模倣し、自然言語処理やコンピュータビジョンの力を利用して、驚くべき解決策を示します。 大規模言語モデルのオントロジーエンジニアリングへの応用は、以来話題となっています。オントロジーエンジニアリングは、オントロジーの作成、構築、キュレーション、評価、保守に関わる知識工学の分野です。オントロジーとは、特定の領域内の知識の形式的で正確な仕様であり、概念と属性の体系的な語彙とそれらの間の関係を提供し、人間と機械の間で意味論的な共有理解を可能にします。 OWL APIやJenaなどのよく知られたオントロジーAPIは主にJavaベースですが、PyTorchやTensorflowなどのディープラーニングフレームワークは一般的にPythonプログラミング向けに開発されています。これに対処するため、研究者のチームはDeepOntoというPythonパッケージを開発しました。このパッケージは、フレームワークとAPIのシームレスな統合を可能にする、オントロジーエンジニアリングに特化したものです。 DeepOntoパッケージは、ディープラーニングをベースとしたオントロジーエンジニアリングに包括的で一般的なPythonフレンドリーなサポートを提供し、基本的な操作(読み込み、保存、エンティティのクエリ、エンティティと公理の変更など)をサポートするオントロジー処理モジュールを基盤としています。また、オントロジーの推論や言語モデルの検証などの高度な機能も備えています。また、オントロジーアライメント、補完、オントロジーベースの言語モデルプロービングのためのツールやリソースも含まれています。 チームはDeepOntoのバックエンド依存関係としてOWL APIを選択しました。これは、ROBOTやHermiTなどの傑出したプロジェクトやツールでの安定性、信頼性、広範な採用など、APIの特性によるものです。ディープラーニングの依存関係には、PyTorchが基盤として使用されています。これは、モデルのアーキテクチャをランタイムで調整できる動的な計算グラフを持つため、柔軟性と使いやすさを提供します。言語モデルのアプリケーションには、HuggingfaceのTransformersライブラリが使用され、ChatGPTなどの大規模言語モデルにおける重要な基盤であるプロンプト学習パラダイムをサポートするためにOpenPromptライブラリが使用されています。 DeepOntoの基本的なオントロジー処理モジュールは、特定のタスクを実行するためのいくつかの部分で構成されています。最初はOntologyで、DeepOntoのベースクラスであり、オントロジーの表示と変更のための基本的なメソッドを提供します。次に、オントロジーの推論があります。これは推論活動を実施するために使用されます。それに続いて、オントロジーのプルーニングがあります。これは、オントロジーを取り、意味的な種類などの特定の基準に応じてスケーラブルなサブセットを抽出します。最後に、オントロジーの言語化があります。これにより、オントロジーのアクセシビリティが向上し、オントロジーエンジニアリングのさまざまな活動をサポートするために、オントロジー要素を自然言語テキストに変換します。 チームは、DeepOntoの実用的な有用性を2つのユースケースを通じて示しました。最初のユースケースでは、DeepOntoがSamsung Research UKのデジタルヘルスコーチングのフレームワーク内でのオントロジーエンジニアリングタスクをサポートするために使用されています。2番目のユースケースでは、DeepOntoがディープラーニングの技術を使用してバイオメディカルオントロジーを整列させ、完成させるために使用されています。 まとめると、DeepOntoはオントロジーエンジニアリングのための強力なパッケージであり、人工知能の分野の発展において重要な存在です。DeepOntoは、論理埋め込みや新しい概念の発見と導入などの将来の実装やプロジェクトに対して、柔軟かつ拡張可能なインタフェースを提供します。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.