Learn more about Search Results Yi - Page 77

- You may be interested
- 2023年にAmazonのデータサイエンティスト...
- 「ChatGPTがクラッシュしましたか? OpenA...
- カスタム分類モデルでの予測の品質を向上...
- 「Scikit-LLMを使用したゼロショットテキ...
- データのセキュリティとコラボレーション...
- 予めトレーニングされた基礎モデルは、分...
- 「Googleのジェミニを使い始める方法はこ...
- ネットワークXによるソーシャルネットワー...
- AIHelperBotとの出会い 秒単位でSQLクエリ...
- スタンフォード大学の研究者が『FlashFFTC...
- *args, **kwargs、そしてその間のすべて
- 『NVIDIAの研究者たちが、現行のCTCモデル...
- 5つのステップでScikit-learnを始める
- Midjourney 5.2 を発表:AI画像生成におけ...
- 意味レイヤーの力:データエンジニアのガイド

これをデジタルパペットにしてください:GenMMは、単一の例を使用して動きを合成できるAIモデルです
コンピュータ生成のアニメーションは、毎日より現実的になっています。この進歩は、ビデオゲームで最もよく見ることができます。トゥームレイダーシリーズの最初のララ・クロフトと最新のララ・クロフトを考えてみてください。私たちは、230ポリゴンのパペットがおかしな動きをするのから、スクリーン上でスムーズに動くリアルなキャラクターに移行しました。 コンピュータアニメーションで自然で多様な動きを生成することは、長年にわたって難しい問題でした。モーションキャプチャシステムや手動アニメーション作成などの従来の方法は、高価で時間がかかり、スタイル、骨格構造、モデルタイプに多様性が欠けた動きのデータセットに結果をもたらします。アニメーション生成のこの手動で時間がかかる性質は、業界に自動化された解決策が必要とされています。 既存のデータ駆動型のモーション合成手法は、その効果が限定的です。しかし、近年、ディープラーニングがコンピュータアニメーションにおいて多様で現実的な動きを生成することができる強力な技術として登場しました。大規模かつ包括的なデータセットでトレーニングされた場合、多様で現実的な動きを合成できます。 ディープラーニング手法は、モーション合成において印象的な結果を示していますが、実用的な適用性が制限される欠点があります。まず、長時間のトレーニングが必要であり、アニメーションの製作パイプラインにおいて大きなボトルネックとなる可能性があります。さらに、ジッタリングや過度なスムージングなどの視覚的なアーティファクトが生じるため、合成された動きの品質に影響を与えます。最後に、複雑な骨格構造にスケーリングするのが困難であるため、複雑な動きが必要なシナリオで使用が制限されます。 私たちは、実用的なシナリオで適用できる信頼性のあるモーション合成手法が需要があると知っています。しかし、これらの問題を克服することは容易ではありません。では、解決策は何でしょうか?それでは、GenMMに出会う時間です。 GenMM は、モーション最近傍とモーションマッチングの古典的なアイデアに基づく代替アプローチです。キャラクターアニメーションに広く使用されるモーションマッチングを利用し、自然に見え、さまざまなローカルコンテキストに適応した高品質のアニメーションを生成します。 GenMMは、単一の入力を使用してモーションを生成できます。出典:http://weiyuli.xyz/GenMM/ GenMM は、単一または少数の例のシーケンスから多様な動きを抽出できる生成モデルです。これは、自然な動き空間全体の近似として広範なモーションキャプチャデータベースを活用することによって達成されます。 GenMM は、新しい生成コスト関数として双方向の類似性を組み込んでいます。この類似度測定により、合成されたモーションシーケンスには提供された例からのモーションパッチのみが含まれ、その逆も同様です。このアプローチは、モーションマッチングの品質を維持しながら、生成能力を可能にします。多様性をさらに高めるために、例と比較して分布の不一致が最小限に抑えられたモーションシーケンスを段階的に合成するマルチステージフレームワークを利用しています。また、画像合成におけるGANベースの手法の成功に着想を得て、パイプラインに対して無条件のノイズ入力が導入され、高度に多様な合成結果が実現されています。 GenMMの概要。出典:https://arxiv.org/pdf/2306.00378.pdf 多様なモーション生成能力に加え、GenMMは、モーションマッチング単独の能力を超えたさまざまなシナリオに拡張できる汎用的なフレームワークであることが証明されています。これには、モーション補完、キーフレームによる生成、無限ループ、モーション再構成が含まれ、生成モーションマッチングアプローチによって可能になる広範なアプリケーションの範囲を示しています。

LLMの巨人たちの戦い:Google PaLM 2 vs OpenAI GPT-3.5
2023年5月10日、GoogleはOpenAIのGPT-4に対する見事な対抗策としてPaLM 2をリリースしました最近のI/Oイベントで、Googleは最小から最大までの魅力的なPaLM 2モデルファミリーを発表しました

Video-ControlNetを紹介します:コントロール可能なビデオ生成の未来を形作る革新的なテキストからビデオへの拡散モデル
近年、テキストベースのビジュアルコンテンツ生成が急速に発展しています。大規模なイメージテキストペアでトレーニングされた現在のテキストから画像へ(T2I)の拡散モデルは、ユーザーが提供したテキストプロンプトに基づいて高品質な画像を生成する驚異的な能力を発揮しています。画像生成の成功は、ビデオ生成にも拡張されています。いくつかの方法は、T2Iモデルをワンショットまたはゼロショットの方法でビデオを生成するために利用していますが、これらのモデルから生成されたビデオはまだ一貫性がないか、バラエティに欠けています。ビデオデータをスケーリングアップすることで、テキストからビデオ(T2V)の拡散モデルを使用すると、生成されたコンテンツに制御がかかる一貫したビデオを作成できます。ただし、これらのモデルは、生成されたコンテンツの制御ができないビデオを生成します。 最近の研究では、深度マップを制御できるT2V拡散モデルが提案されています。ただし、一貫性と高品質を実現するには大規模なデータセットが必要で、リソースに優しくありません。また、T2V拡散モデルは、一貫性、任意の長さ、多様性を持つビデオを生成することはまだ難しいとされています。 これらの問題に対処するために、制御可能なT2VモデルであるVideo-ControlNetが導入されました。Video-ControlNetには、以下の利点があります。モーションプライオリティと制御マップを使用することで一貫性が向上し、最初のフレームの条件付け戦略を採用することで任意の長さのビデオを生成することができ、画像からビデオへの知識移行によるドメイン汎化、限られたバッチサイズを使用してより速い収束でリソース効率が向上します。 Video-ControlNetのアーキテクチャは、以下の通りです。 目的は、テキストと参照制御マップに基づいてビデオを生成することです。そのため、生成モデルは、事前にトレーニングされた制御可能なT2Iモデルを再編成し、追加のトレーニング可能な時間層を組み込み、フレーム間の細かい相互作用を促進する空間・時間自己注意メカニズムを提示することで開発されました。このアプローチにより、広範なトレーニングがなくても、コンテンツに一貫性のあるビデオを作成できます。 ビデオ構造の一貫性を確保するために、著者らは、ノイズ初期化段階でノイズ除去プロセスにソースビデオのモーションプライオリティを組み込む先駆的なアプローチを提案しています。モーションプライオリティと制御マップを活用することで、Video-ControlNetは、マルチステップのノイズ除去プロセスの性質による他のモーションベースの方法のエラー伝搬を避けながら、フリッカリングが少なく、入力ビデオのモーション変化に近くなるビデオを生成することができます。 さらに、以前の方法が直接ビデオ全体を生成するようにモデルをトレーニングするのに対して、この研究では、初期フレームに基づいてビデオを生成する革新的なトレーニングスキームが導入されています。このような簡単で効果的な戦略により、コンテンツと時間的学習を分離することがより簡単になります。前者は最初のフレームとテキストプロンプトで提示され、モデルは、後続フレームの生成方法のみを学習する必要があります。これにより、ビデオデータの需要が軽減され、画像領域から生成能力を継承することができます。推論中、最初のフレームは、最初のフレームの制御マップとテキストプロンプトによって条件付けられて生成されます。その後、最初のフレーム、テキスト、および後続の制御マップによって条件付けられた後続フレームが生成されます。また、このような戦略の別の利点は、モデルが前のイテレーションの最後のフレームを初期フレームとして扱い、無限に長いビデオを自動的に生成できることです。 これがどのように機能するかを説明し、著者によって報告された結果と最先端のアプローチとの比較を含む制限されたサンプル結果が以下の図に示されています。 これはVideo-ControlNetの概要であり、最新の品質と時間的一貫性を備えたT2V生成のための新しい拡散モデルです。もし興味があれば、以下のリンクでこの技術について詳しく学ぶことができます。

事前学習済みのViTモデルを使用した画像キャプショニングにおけるVision Transformer(ViT)
はじめに 事前学習済みのViTモデルを使用した画像キャプショニングは、画像の詳細な説明を提供するために画像の下に表示されるテキストまたは書き込みのことを指します。つまり、画像をテキストの説明に翻訳するタスクであり、ビジョン(画像)と言語(テキスト)を接続することで行われます。この記事では、PyTorchバックエンドを使用して、画像のViTを主要な技術として使用して、トランスフォーマーを使用した画像キャプショニングの生成方法を、スクラッチから再トレーニングすることなくトレーニング済みモデルを使用して実現します。 出典: Springer 現在のソーシャルメディアプラットフォームや画像のオンライン利用の流行に対応するため、この技術を学ぶことは、説明、引用、視覚障害者の支援、さらには検索エンジン最適化といった多くの理由で役立ちます。これは、画像を含むプロジェクトにとって非常に便利な技術であります。 学習目標 画像キャプショニングのアイデア ViTを使用した画像キャプチャリング トレーニング済みモデルを使用した画像キャプショニングの実行 Pythonを使用したトランスフォーマーの利用 この記事で使用されたコード全体は、このGitHubリポジトリで見つけることができます。 この記事は、データサイエンスブログマラソンの一環として公開されました。 トランスフォーマーモデルとは何ですか? ViTについて説明する前に、トランスフォーマーについて理解しましょう。Google Brainによって2017年に導入されて以来、トランスフォーマーはNLPの能力において注目を集めています。トランスフォーマーは、入力データの各部分の重要性を異なる重み付けする自己注意を採用して区別されるディープラーニングモデルです。これは、主に自然言語処理(NLP)の分野で使用されています。 トランスフォーマーは、自然言語のようなシーケンシャルな入力データを処理しますが、トランスフォーマーは一度にすべての入力を処理します。注意機構の助けを借りて、入力シーケンスの任意の位置にはコンテキストがあります。この効率性により、より並列化が可能となり、トレーニング時間が短縮され、効率が向上します。 トランスフォーマーアーキテクチャ 次に、トランスフォーマーのアーキテクチャの構成を見てみましょう。トランスフォーマーアーキテクチャは、主にエンコーダー-デコーダー構造から構成されています。トランスフォーマーアーキテクチャのエンコーダー-デコーダー構造は、「Attention Is All You Need」という有名な論文で発表されました。 エンコーダーは、各レイヤーが入力を反復的に処理することを担当し、一方で、デコーダーレイヤーはエンコーダーの出力を受け取り、デコードされた出力を生成します。単純に言えば、エンコーダーは入力シーケンスをシーケンスにマッピングし、それをデコーダーに供給します。デコーダーは、出力シーケンスを生成します。 ビジョン・トランスフォーマーとは何ですか?…

MeLoDyとは:音楽合成のための効率的なテキストからオーディオへの拡散モデル
音楽は、調和、メロディ、リズムから成る芸術であり、人生のあらゆる面に浸透しています。深層生成モデルの発展に伴い、音楽生成は近年注目を集めています。言語モデル(LM)は、長期的な文脈にわたる複雑な関係をモデリングする能力において、顕著なクラスの生成モデルとして、音声合成にLMを成功裏に応用することができるAudioLMやその後の作品が登場しています。DPM(拡散確率モデル)は、生成モデルのもう1つの競争力のあるクラスとして、音声、音楽の合成に優れた能力を発揮しています。 しかし、自由形式のテキストから音楽を生成することは依然として課題であり、許容される音楽の記述が多様で、ジャンル、楽器、テンポ、シナリオ、あるいは主観的な感情に関連していることがあります。 従来のテキストから音楽を生成するモデルは、しばしば音声の継続や高速サンプリングなど特定の特性に焦点を当て、一部のモデルは音楽プロデューサーなどの専門家によって実施される堅牢なテストを優先しています。さらに、ほとんどのモデルは大規模な音楽データセットでトレーニングされ、高い忠実度とテキストプロンプトのさまざまな側面への遵守とともに、最先端の生成性能を示しています。 しかし、MusicLMやNoise2Musicなどのこれらの手法の成功は、実用性に重大な影響を与える高い計算コストと引き換えに得られています。比較的、DPMに基づく他の手法は、高品質な音楽の効率的なサンプリングを実現しました。しかしながら、彼らが示したケースは比較的小さく、サンプリング効果が制限されていました。実現可能な音楽作成ツールを目指すにあたり、生成モデルの高い効率性は、人間のフィードバックを考慮に入れたインタラクティブな作成を促進するために不可欠です。 LMとDPMの両方が有望な結果を示しているにもかかわらず、関連する問題は、どちらを好むかではなく、両方の方法の利点を同時に活用できるかどうかです。 上記の動機に基づき、MeLoDyと呼ばれるアプローチが開発されました。戦略の概要は、以下の図に示されています。 MusicLMの成功を分析した後、著者たちは、MusicLMの最高レベルのLMである「意味LM」を活用して、メロディ、リズム、ダイナミクス、音色、テンポの全体的なアレンジメントを決定する音楽の意味構造をモデリングします。この意味LMに条件付けられた上で、非自己回帰性のDPMを活用して、成功したサンプリングの加速技術を用いて、音響を効率的かつ効果的にモデリングします。 さらに、著者たちは、古典的な拡散プロセスを採用する代わりに、デュアルパス拡散(DPD)モデルを提案しています。実際、生データで作業することは、計算費用を指数関数的に増加させることになります。提案された解決策は、生データを低次元の潜在表現に縮小することです。データの次元を減らすことで、操作に対するその影響を阻害し、したがって、モデルの実行時間を短縮することができます。その後、生データは、事前にトレーニングされたオートエンコーダを介して、潜在表現から再構築されることができます。 モデルによって生成されたいくつかの出力サンプルは、以下のリンクから入手できます:https://efficient-melody.github.io/。コードはまだ利用可能ではないため、現時点ではオンラインまたはローカルで試すことはできません。 これは、最先端の品質の音楽オーディオを生成する効率的なLMガイド拡散モデルであるMeLoDyの概要でした。興味がある場合は、以下のリンクでこの技術について詳しく学ぶことができます。

AI医療診断はどのように動作しますか?
医療分野では、人工知能(AI)が診断や治療計画においてますます頻繁に使用されるようになっています。近年、AIと機械学習は効果的な診断ツールとなっています。より正確な診断を提供することにより、この技術は医療を変革する可能性があります。人工知能は、医療診断におけるヘルスケアの管理、自動化、管理、ワークフローを容易にしています。医療診断におけるAIは、医療サービスの強い圧力を緩和しながら、医療の標準を変える可能性を示しています。 医療診断におけるAIアルゴリズム 以下は、医療診断においてAIが助けているいくつかの分野です。 AIアルゴリズムは医療データを分析し、診断に役立ちます 電子健康記録(EHR)、画像技術、遺伝データ、ポータブルセンサーデータなど、さまざまな種類の医療データが新しいレベルで収集されています。これらの多数のデータは、AIアルゴリズムによって処理および分析され、医療診断に役立つ示唆に富む情報を提供できます。AIアルゴリズムは、患者の病歴、症状、検査結果、およびその他の関連データを調べることによって、見積もりや概念を生み出すことができます。 機械学習とディープラーニング技術の利用 医療診断におけるAIアルゴリズムは、機械学習(ML)アプローチに大きく依存しています。ラベル付きサンプルを含む大規模なデータセットを使用して、MLシステムをトレーニングし、関係や傾向を発見することができます。ディープラーニング(DL)アルゴリズムは、腫瘍の識別、分類、および分類の効率を向上させることによって、医療画像解析を変革しました。 DLアルゴリズムは、テキストデータ、遺伝情報、医療画像など、他のデータタイプを組み合わせて、より詳細な分析を提供することもできます。診断の正確性が向上し、この包括的なアプローチにより、複雑な状態のより深い理解が可能になります。 AIがパターンを検出し、予測する能力 AIアルゴリズムは、医療従事者が見落とす可能性のある関連性、バイオマーカー、および疾患リスクを見つけるために、膨大な量のデータを分析できます。AIアルゴリズムは、複数の要因を同時に考慮することにより、個人の健康状態を包括的に見ることができます。したがって、より正確な診断と個別化された治療戦略が可能になります。 医療画像におけるAIの応用 X線、MRI、およびCTスキャンなどの医療画像の分析におけるAIの利用 AIアルゴリズムは、医療画像の処理において驚異的な能力を示しています。診断スキャンに基づく正確かつ詳細な所見を医療従事者が取得できるようにします。AIはX線画像、MRI、CTスキャンを短時間で処理することができ、人間の専門家がパターンをより速く見つけ、膨大なデータ量を分析し、関連するデータを取得するのを支援します。 異常、腫瘍、およびその他の医療状態の特定におけるAIの役割 AIは、医療画像を使用して、腫瘍、異常、およびその他の医療問題を特定することにおいて、優れた能力を発揮しています。AIアルゴリズムは、がんの場合には膨大な医療画像のコレクションを効果的に分析して腫瘍を特定および分類することができます。AI医療診断システムは、これらの結果を以前のデータと比較して、腫瘍の段階、成長率、および転移の可能性についての専門家に示唆を与え、個別化された治療計画を可能にする情報を提供できます。 AIが診断の正確性と効率を向上させる可能性 医療画像にAIを応用することによって、診断の効率と正確性を向上させる可能性があります。AI医療診断システムは、異なる視点を提供することによって放射線技師を支援し、誤解釈の可能性を減らし、全体的な診断の正確性を高めることができます。また、画像解析を高速化することにより、より迅速な対応とより効果的な医療ケアが可能になります。 疾患の早期検出および予防のためのAI AIによる早期疾患検出およびリスク評価の利用 AIは、広範な患者記録を分析し、病気の存在を示唆する微小なパターンや異常を見つけることによって、早期の疾患認識に重要な役割を果たしています。AIツールは、医療記録、画像研究、スマートデバイスデータなど、様々なデータセットから学習することができます。危険因子や早期警告の兆候を特定することができます。 AIによる患者データ、遺伝情報、およびバイオマーカーの分析の応用 AIは遺伝データを評価し、特定の疾患の発症リスクが高い遺伝子変異を見つけることができます。AI医療診断システムは、遺伝子データをライフスタイル、環境効果、および医療歴に影響を与える要因と統合して、個別のリスク評価スコアを生成することができます。これにより、患者は健康に関する情報を得て、予防措置を取ることができます。また、AIは、血液検査や画像結果などのバイオマーカーを評価し、臨床的に明らかになっていない疾患関連の早期警告症状を見つけることができます。 関連記事:症状が現れる数年前にパーキンソン病を検出するAIツールの開発 AIによる個別化医療と予防医療の支援の可能性…
特徴量が多すぎる?主成分分析を見てみましょう
次元の呪いは、機械学習における主要な問題の1つです特徴量の数が増えると、モデルの複雑さも増しますさらに、十分なトレーニングデータがない場合、それは...
チャットGPTの潜在能力を引き出すためのプロンプトエンジニアリングのマスタリング
プロンプトエンジニアリングは、ChatGPTやその他の大規模言語モデルのおかげで、風のように私たちの生活の一部にすぐになりました完全に新しい分野ではありませんが、現在...

AIの未来を形作る ビジョン・ランゲージ・プリトレーニング・モデルの包括的な調査と、ユニモーダルおよびマルチモーダルタスクにおける役割
機械学習研究の最新リリースで、ビジョン言語事前学習(VLP)とその多様なタスクへの応用について、研究チームが深く掘り下げています。この論文は、単一モーダルトレーニングのアイデアを探究し、それがマルチモーダル適応とどのように異なるかを説明しています。そして、VLPの5つの重要な領域である特徴抽出、モデルアーキテクチャ、事前トレーニング目標、事前トレーニングデータセット、およびダウンストリームタスクを示しています。研究者たちは、既存のVLPモデルとその異なる側面での適応をレビューしています。 人工知能の分野は常に、モデルを人間と同じように知覚、思考、そしてパターンや微妙なニュアンスを理解する方法でトレーニングしようとしてきました。ビジュアル、オーディオ、テキストなど、可能な限り多くのデータ入力フィールドを組み込もうとする試みがいくつか行われてきました。ただし、これらのアプローチのほとんどは、単一モーダル意味で「理解」の問題を解決しようとしたものです。 単一モーダルアプローチは、1つの側面のみを評価するアプローチであり、例えばビデオの場合、音声またはトランスクリプトに焦点を絞っており、マルチモーダルアプローチでは、可能な限り多くの利用可能な特徴をターゲットにしてモデルに組み込もうとします。たとえば、ビデオを分析する際に、音声、トランスクリプト、スピーカーの表情をとらえて、文脈を本当に「理解」することができます。 マルチモーダルアプローチは、リソースが豊富であり、訓練に必要な大量のラベル付きデータを取得することが困難であるため、課題があります。Transformer構造に基づく事前トレーニングモデルは、自己教師あり学習と追加タスクを活用して、大規模な非ラベルデータからユニバーサルな表現を学習することで、この問題に対処しています。 NLPのBERTから始まり、単一モーダルの方法でモデルを事前トレーニングすることで、限られたラベル付きデータでダウンストリームタスクを微調整することができることが示されています。研究者たちは、同じ設計哲学をマルチモーダル分野に拡張することで、ビジョン言語事前学習(VLP)の有効性を探究しました。VLPは、大規模なデータセットで事前トレーニングモデルを使用して、モダリティ間の意味的な対応関係を学習します。 研究者たちは、VLPアプローチの進歩について、5つの主要な領域を検討しています。まず、VLPモデルが画像、ビデオ、テキストを前処理して表現する方法、使用されるさまざまなモデルを強調して説明しています。次に、単一ストリームの観点とその使用可能性、デュアルストリームフュージョンとエンコーダのみ対エンコーダデコーダ設計の観点を探究しています。 論文では、VLPモデルの事前トレーニングについてさらに探求し、完了、マッチング、特定のタイプに分類しています。これらの目標は、ユニバーサルなビジョン言語表現を定義するのに役立ちます。研究者たちは、2つの主要な事前トレーニングデータセットのカテゴリである画像言語モデルとビデオ言語モデルについて概説しました。論文では、マルチモーダルアプローチが文脈を理解し、より適切にマッピングされたコンテンツを生成するためにどのように役立つかを強調しています。最後に、記事は、事前トレーニングモデルの有効性を評価する上での重要性を強調しながら、VLPのダウンストリームタスクの目標と詳細を提示しています。 https://link.springer.com/content/pdf/10.1007/s11633-022-1369-5.pdf https://link.springer.com/content/pdf/10.1007/s11633-022-1369-5.pdf この論文では、SOTA(State-of-the-Art)のVLPモデルについて詳細な概要が提供されています。これらのモデルをリストアップし、その主要な特徴やパフォーマンスを強調しています。言及されているモデルは、最先端の技術開発の堅固な基盤であり、将来の開発のベンチマークとして役立ちます。 研究論文に基づくと、VLPアーキテクチャの将来は有望で信頼性があります。彼らは、音響情報の統合、知識と認知学習、プロンプトチューニング、モデル圧縮と加速、およびドメイン外の事前学習など、様々な改善の領域を提案しています。これらの改善領域は、新しい研究者たちがVLPの分野で前進し、画期的なアプローチを打ち出すためにインスピレーションを与えることを目的としています。
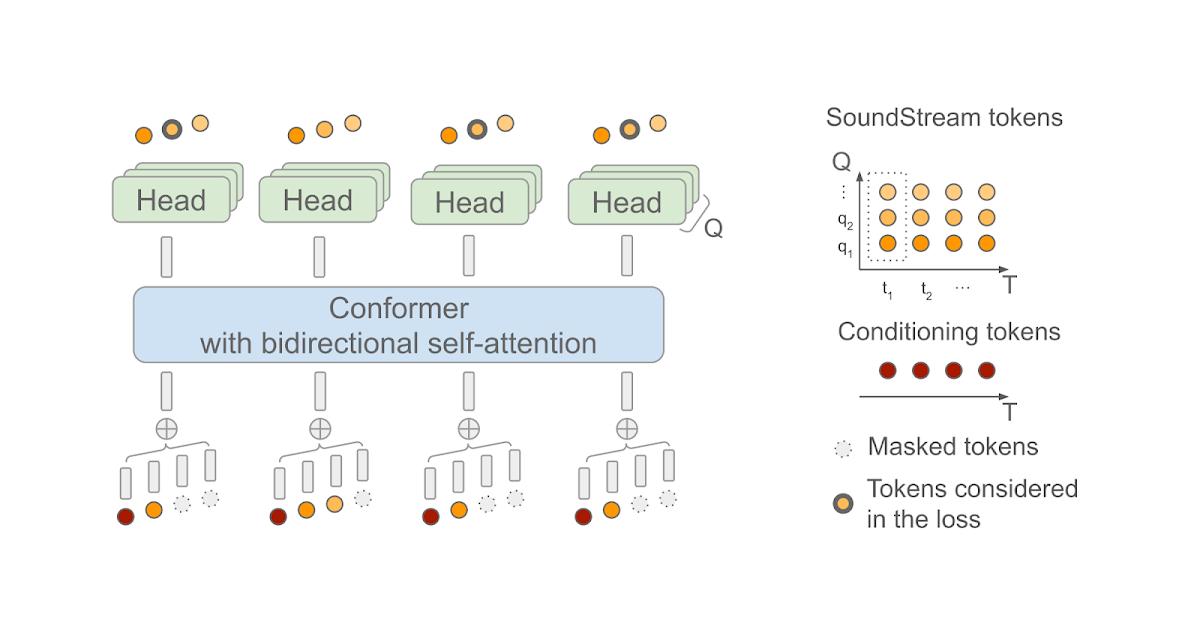
SoundStorm:効率的な並列音声生成
Zalán Borsos氏(リサーチソフトウェアエンジニア)とMarco Tagliasacchi氏(シニアスタッフリサーチサイエンティスト)がGoogle Researchで発表した記事です。 最近の生成AIの進歩により、テキスト、ビジョン、オーディオなど、さまざまな領域で新しいコンテンツを作成する可能性が開かれました。これらのモデルは、生データが最初にトークンのシーケンスとして圧縮されることに依存しています。オーディオの場合、ニューラルオーディオコーデック(例えば、SoundStreamまたはEnCodec)を使用して、波形をコンパクトな表現に効率的に圧縮することができます。これにより、元のオーディオ信号の近似値を再構成できます。この表現は、音の局所的な特性(たとえば、音素)および時間的構造(たとえば、韻律)を捉えた離散的な音声トークンのシーケンスで構成されています。オーディオを離散的なトークンのシーケンスとして表現することで、Transformerベースのシーケンスツーシーケンスモデルを使用してオーディオ生成を実行できるようになりました。これにより、音声継続性(AudioLMを使用した)、テキストから音声への変換(SPEAR-TTSを使用した)、一般的なオーディオや音楽の生成(AudioGenおよびMusicLMを使用した)において急速な進歩が可能になりました。多くの生成オーディオモデル、AudioLMを含む、自己回帰デコーディングに依存しています。この方法は高い音響品質を実現しますが、特に長いシーケンスをデコードする場合、推論(出力の計算)が遅くなることがあります。 この問題に対処するため、「SoundStorm: Efficient Parallel Audio Generation」という記事で、効率的かつ高品質なオーディオ生成の新しい方法を提案しています。SoundStormは、SoundStreamニューラルコーデックによって生成されるオーディオトークンの特性に適合するアーキテクチャと、MaskGITと呼ばれる最近提案された画像生成の方法に着想を得たデコードスキームの2つの新しい要素に依存して、長いオーディオトークンシーケンスの生成の問題に対処します。これにより、AudioLMの自己回帰デコーディングアプローチと比較して、SoundStormはトークンを並列に生成できるため、長いシーケンスの推論時間を100倍短縮することができ、同じ品質で、声質や音響条件の一貫性が高いオーディオを生成できます。さらに、SPEAR-TTSのテキストから意味論的モデリング段階と組み合わせたSoundStormは、例えば以下の例で示されるように、高品質で自然な対話を合成することができ、話される内容(トランスクリプトを介して)、話者の声(短い音声プロンプトを介して)、話者のターン(トランスクリプト注釈を介して)を制御できます。 入力:テキスト(オーディオ生成を駆動するトランスクリプトは太字) 今朝、私にとてもおかしなことが起こりました。| え、本当に?|普段通りに起きて、朝食を食べに下に降りたんです。|なるほど。| 食べ始めてから10分後に、今夜中だと気づいたんです。| あ、それはおもしろい。| 昨晩よく眠れなかったんだ。|え、どうしたの?|よくわからないんだ。どうしても寝付けなくて、一晩中寝返りを打ち続けたんだ。|そうなんだ。今晩は早く寝た方がいいかもしれないし、本でも読んでみるのはどうかな。|ああ、ありがとう。そうだといいんだけど。|どういたしまして。よく眠れるといいね。 入力:オーディオプロンプト 出力:オーディオプロンプト+生成されたオーディオ SoundStormの設計 以前のAudioLMの研究で、オーディオ生成を2つのステップに分解できることを示しました。1つ目は、意味的なトークンを生成する意味モデリングであり、前の意味トークンまたは条件信号(SPEAR-TTSのトランスクリプトやMusicLMのようなテキストプロンプトなど)から意味トークンを生成します。2つ目は、意味トークンから音声トークンを生成する音響モデリングです。SoundStormでは、より高速な並列デコードによって、より遅い自己回帰デコーディングを置き換え、音響モデリングに特に対処しています。 SoundStormは、トランスフォーマーと畳み込みを組み合わせたモデルアーキテクチャであるConformerに双方向アテンションを依存しており、トークンのシーケンスのローカルおよびグローバルな構造を捕捉します。具体的には、AudioLMが生成した意味トークンのシーケンスを入力として与えられた場合、SoundStreamによって生成されたオーディオトークンを予測するようにモデルが訓練されます。この際、各時間ステップtにおいて、SoundStreamは、右側に示すように、残差ベクトル量子化(RVQ)として知られる方法を使用して、最大Qトークンまでオーディオを表現します。主要な考え方は、各ステップで生成されるトークンの数が1からQに増えるにつれて、再構築されたオーディオの品質が徐々に向上するということです。 推論時には、入力として意味トークンを与えた場合、SoundStormは、すべてのオーディオトークンをマスクアウトし、RVQレベルq = 1の粗いトークンから始めて、より細かいトークンまでレベル別に進み、レベルq…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.