Learn more about Search Results リポジトリ - Page 76

- You may be interested
- 効率的にオープンソースのLLMを提供する
- 「マルチモーダルAIの最新の進歩:(ChatG...
- フランス国立科学研究センター(CNRS)に...
- Pythonの依存関係管理:どのツールを選ぶ...
- 「30+ AI ツールスタートアップのための(...
- 「Amazon SageMaker Data WranglerでAWS L...
- 「Javaを使用した脳コンピュータインター...
- 安全で信頼性の高い自動操縦飛行への一歩
- OpenAI API — イントロ&ChatGPTの背後に...
- 「IntelのOpenVINOツールキットを使用した...
- ソニーの研究者がBigVSANを提案:GANベー...
- 「Langchain Agentsを使用して、独自のデ...
- 「GPT4による高度なデータ分析:ヨーロッ...
- 「RAVENに会ってください:ATLASの制限に...
- 「デジタルツインは水素の緑の成長への道...

BLOOMトレーニングの技術背後
近年、ますます大規模な言語モデルの訓練が一般的になってきました。これらのモデルがさらなる研究のために公開されていない問題は頻繁に議論されますが、そのようなモデルを訓練するための技術やエンジニアリングについての隠された知識は滅多に注目されません。本記事では、1760億パラメータの言語モデルBLOOMを例に、そのようなモデルの訓練の裏側にあるハードウェアとソフトウェアの技術とエンジニアリングについて、いくつかの光を当てることを目指しています。 しかし、まず、この素晴らしい1760億パラメータモデルの訓練を可能にするために貢献してくれた企業や主要な人物やグループに感謝したいと思います。 その後、ハードウェアのセットアップと主要な技術的な構成要素について説明します。 以下はプロジェクトの要約です: 人々 このプロジェクトは、Hugging Faceの共同創設者でありCSOのThomas Wolf氏が考案しました。彼は巨大な企業と競争し、単なる夢だったものを実現し、最終的な結果をすべての人にアクセス可能にすることで、最も多くの人々にとっては夢であったものを実現しました。 この記事では、モデルの訓練のエンジニアリング側に特化しています。BLOOMの背後にある技術の最も重要な部分は、私たちにコーディングと訓練の助けを提供してくれた専門家の人々と企業です。 感謝すべき6つの主要なグループがあります: HuggingFaceのBigScienceチームは、数人の専任の従業員を捧げ、訓練を始めから終わりまで行うための方法を見つけるために、Jean Zayの計算機を超えるすべてのインフラストラクチャを提供しました。 MicrosoftのDeepSpeedチームは、DeepSpeedを開発し、後にMegatron-LMと統合しました。彼らの開発者たちはプロジェクトのニーズに多くの時間を費やし、訓練前後に素晴らしい実践的なアドバイスを提供しました。 NVIDIAのMegatron-LMチームは、Megatron-LMを開発し、私たちの多くの質問に親切に答えてくれ、一流の実践的なアドバイスを提供しました。 ジャン・ゼイのスーパーコンピュータを管理しているIDRIS / GENCIチームは、計算リソースをプロジェクトに寄付し、優れたシステム管理のサポートを提供しました。 PyTorchチームは、このプロジェクトのために基礎となる非常に強力なフレームワークを作成し、訓練の準備中に私たちをサポートし、複数のバグを修正し、PyTorchコンポーネントの使いやすさを向上させました。 BigScience Engineeringワーキンググループのボランティア プロジェクトのエンジニアリング側に貢献してくれたすべての素晴らしい人々を全て挙げることは非常に困難なので、Hugging Face以外のいくつかの主要な人物を挙げます。彼らはこのプロジェクトのエンジニアリングの基盤となりました。 Olatunji Ruwase、Deepak…

🤗 Datasetsでの新しいオーディオとビジョンのドキュメンテーションを紹介します
オープンで再現可能なデータセットは、良い機械学習を進めるために不可欠です。同時に、データセットは大規模な言語モデルの燃料として非常に大きく成長しています。2020年、Hugging Faceは🤗 Datasetsというライブラリを立ち上げ、以下のために専用のライブラリを提供しています: 1行のコードで標準化されたデータセットにアクセスを提供すること。 大規模なデータセットを迅速かつ効率的に処理するためのツールを提供すること。 コミュニティのおかげで、私たちは多言語および方言のNLPデータセットを数百追加しました! 🤗 ❤️ しかし、テキストデータセットは始まりに過ぎません。データは🎵 音声、📸 画像、音声とテキストの組み合わせ、画像とテキストなど、より豊かな形式で表現されています。これらのデータセットでトレーニングされたモデルは、画像の内容を説明したり、画像に関する質問に答えたりするなど、素晴らしいアプリケーションを可能にします。 🤗 Datasetsチームは、これらのデータセットタイプとの作業をできるだけ簡単にするためのツールと機能を開発してきました。音声および画像データセットの読み込みと処理についての詳細を学ぶための新しいドキュメントも追加しました。 クイックスタート クイックスタートは、ライブラリの機能についての要点を把握するために新しいユーザーが最初に訪れる場所の一つです。そのため、クイックスタートを更新して、🤗 Datasetsを使用して音声および画像データセットを処理する方法を含めました。作業したいデータセットの形態を選択し、データセットを読み込んで処理し、PyTorchまたはTensorFlowでトレーニングに使用する準備ができるまでのエンドツーエンドの例を参照してください。 クイックスタートには、新しいto_tf_dataset関数も追加されています。この関数は、データセットをtf.data.Datasetに変換するために必要なコードを自動的に記述します。これにより、データセットからシャッフルしてバッチを読み込むためのコードを書く必要がなくなります。データセットをtf.data.Datasetに変換した後は、通常のTensorFlowまたはKerasのメソッドでモデルをトレーニングすることができます。 今日はクイックスタートをチェックして、さまざまなデータセット形態での作業方法を学び、新しいto_tf_dataset関数を試してみましょう! データセットの冒険を選ぶ! 専用ガイド 各データセット形態には、それらを読み込んで処理する方法に固有のニュアンスがあります。例えば、音声データセットを読み込む場合、音声信号はAudio機能によって自動的にデコードおよびリサンプリングされます。これはテキストデータセットを読み込む場合とはかなり異なります! モダリティ固有のドキュメントをより見つけやすくするために、各モダリティごとに専用のセクションが新たに設けられ、各モダリティの読み込みと処理方法を示すガイドが提供されています。データセット形態での作業に関する特定の情報を探している場合は、まずこれらの専用セクションをご覧ください。一方で、特定ではなく広く使用できる関数は一般的な使用方法のセクションに記述されています。このような方法でドキュメントを再編成することで、将来サポートする予定の他のデータセット形式にもよりスケーラブルに対応できるようになります。 ガイドは、🤗 Datasetsの最も重要な側面をカバーするセクションに整理されています。…

プライベートハブのご紹介:機械学習を活用した新しいビルド方法
機械学習は、企業が技術を構築する方法を変えつつあります。革新的な新製品のパワーを供給し、私たちが使い慣れて愛している既知のアプリケーションにスマートな機能を提供することから、MLは開発プロセスの中心にあります。 しかし、すべての技術の変化には新たな課題が伴います。 機械学習モデルの約90%が本番環境に到達しないとされています。馴染みのないツールや非標準的なワークフローがMLの開発を遅くしています。モデルやデータセットが内部で共有されないため、同じような成果物がチーム間で常にゼロから作成されます。データサイエンティストは、ビジネスステークホルダーに技術的な作業を示すのが難しく、正確でタイムリーなフィードバックを共有するのに苦労しています。そして、機械学習チームはDocker/Kubernetesや本番環境向けのモデル最適化に時間を浪費しています。 これらを考慮して、私たちはPrivate Hub(PH)を立ち上げました。機械学習の構築方法を革新する新しい方法です。研究から本番環境まで、セキュアかつコンプライアンスを確保しながら、機械学習ライフサイクルの各ステップを加速するための統合されたツールセットを提供します。PHはさまざまなMLツールを一つにまとめることで、機械学習の協力をよりシンプルで楽しく、生産的にします。 このブログ投稿では、Private Hubとは何か、なぜ役立つのか、そしてどのようにお客様がそれを使用してMLのロードマップを加速しているのかについて詳しく説明します。 一緒に読んでいただくか、興味を引くセクションにジャンプしてください 🌟: ハグフェースハブとは何ですか? プライベートハブとは何ですか? 企業はプライベートハブをどのように使用してMLのロードマップを加速しているのでしょうか? さあ、始めましょう! 🚀 1. ハグフェースハブとは何ですか? プライベートハブについて詳しく説明する前に、まずハグフェースハブについて見てみましょう。これはPHの中心的な要素です。 ハグフェースハブは、オープンソースで公開されているオンラインプラットフォームで、人々が簡単に協力してMLを構築できる場所です。ハブは、機械学習と一緒に技術を探求し、実験し、協力し、構築するための中心的な場所として機能します。 ハグフェースハブでは、次のようなMLアセットを作成または発見することができます: モデル:NLP、コンピュータビジョン、音声、時系列、生物学、強化学習、化学などの最新の最先端モデルをホスティング。 データセット:さまざまなドメイン、モダリティ、言語に対応したデータの幅広いバリエーション。 スペース:ブラウザ内で直接MLモデルをショーケースするインタラクティブなアプリ。 ハブにアップロードされた各モデル、データセット、またはスペースは、Gitベースのリポジトリです。これはすべてのファイルを含むバージョン管理された場所で、従来のgitコマンドを使用してファイルをプル、プッシュ、クローン、操作することができます。モデル、データセット、およびスペースのコミット履歴を表示し、誰がいつ何を行ったかを確認することができます。 モデルのコミット履歴…
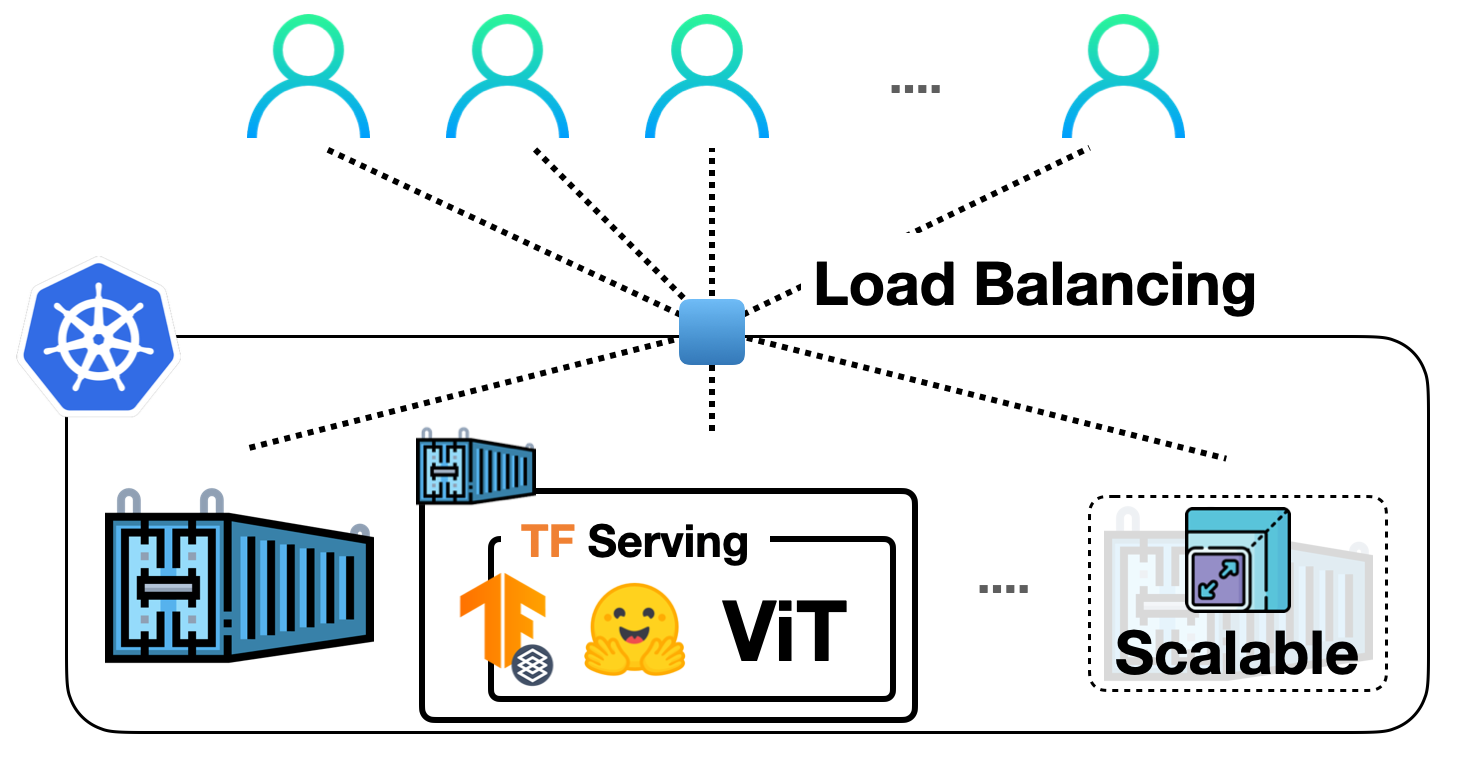
TF Servingを使用してKubernetes上に🤗 ViTをデプロイする
前の投稿では、TensorFlow Servingを使用して🤗 TransformersからVision Transformer(ViT)モデルをローカルに展開する方法を示しました。ビジョントランスフォーマーモデル内での埋め込み前処理および後処理操作、gRPCリクエストの処理など、さまざまなトピックをカバーしました! ローカル展開は、有用なものを構築するための優れたスタート地点ですが、実際のプロジェクトで多くのユーザーに対応できる展開を実行する必要があります。この投稿では、前の投稿のローカル展開をDockerとKubernetesでスケーリングする方法を学びます。したがって、DockerとKubernetesに関する基本的な知識が必要です。 この投稿は前の投稿に基づいていますので、まずそれをお読みいただくことを強くお勧めします。この投稿で説明されているコードは、このリポジトリで確認することができます。 私たちの展開をスケールアップする基本的なワークフローは、次のステップを含みます: アプリケーションロジックのコンテナ化:アプリケーションロジックには、リクエストを処理して予測を返すサービスモデルが含まれます。コンテナ化するために、Dockerが業界標準です。 Dockerコンテナの展開:ここにはさまざまなオプションがあります。最も一般的に使用されるオプションは、DockerコンテナをKubernetesクラスターに展開することです。Kubernetesは、展開に便利な機能(例:自動スケーリングとセキュリティ)を提供します。ローカルでKubernetesクラスターを管理するためのMinikubeのようなソリューションや、Elastic Kubernetes Service(EKS)のようなサーバーレスソリューションを使用することもできます。 SagemakerやVertex AIのような、MLデプロイメント固有の機能をすぐに利用できる時代に、なぜこのような明示的なセットアップを使用するのか疑問に思うかもしれません。それは考えるのは当然です。 上記のワークフローは、業界で広く採用され、多くの組織がその恩恵を受けています。長年にわたってすでに実戦投入されています。また、複雑な部分を抽象化しながら、展開に対してより細かな制御を持つことができます。 この投稿では、Google Kubernetes Engine(GKE)を使用してKubernetesクラスターをプロビジョニングおよび管理することを前提としています。GKEを使用する場合、請求を有効にしたGCPプロジェクトが既にあることを想定しています。また、GKEで展開を行うためにgcloudユーティリティを構成する必要があります。ただし、Minikubeを使用する場合でも、この投稿で説明されているコンセプトは同様に適用されます。 注意:この投稿で表示されるコードスニペットは、gcloudユーティリティとDocker、kubectlが構成されている限り、Unixターミナルで実行できます。詳しい手順は、付属のリポジトリで入手できます。 サービングモデルは、生のイメージ入力をバイトとして処理し、前処理および後処理を行うことができます。 このセクションでは、ベースのTensorFlow Servingイメージを使用してそのモデルをコンテナ化する方法を示します。TensorFlow Servingは、モデルをSavedModel形式で消費します。前の投稿でSavedModelを取得した方法を思い出してください。ここでは、SavedModelがtar.gz形式で圧縮されていることを前提としています。万が一必要な場合は、ここから入手できます。その後、SavedModelは<MODEL_NAME>/<VERSION>/<SavedModel>という特別なディレクトリ構造に配置する必要があります。これにより、TensorFlow Servingは異なるバージョンのモデルの複数の展開を同時に管理できます。 Dockerイメージの準備…

Hugging FaceのTensorFlowの哲学
はじめに PyTorchやJAXからの競争が増えても、TensorFlowは最も使用されるディープラーニングフレームワークのままです。また、それらの他の2つのライブラリとはいくつか非常に重要な点で異なります。特に、高レベルのAPIであるKerasと、データの読み込みライブラリであるtf.dataとの統合が非常に密接です。 PyTorchのエンジニアの中には(ここでオープンプランオフィスを暗く見つめながら私を想像してください)、これを克服すべき問題だと見なす傾向があります。彼らの目標は、TensorFlowが彼らのやり方に従って低レベルのトレーニングとデータの読み込みコードを使用できるようにする方法を見つけることです。これはTensorFlowに取り組む間違った方法です! Kerasは素晴らしい高レベルのAPIです。プロジェクトが数モジュールよりも大きい場合、それを押しのけると、必要になると気付いたときに、その機能のほとんどを自分で再現することになります。 洗練された、尊敬され、非常に魅力的なTensorFlowエンジニアとして、私たちは最先端のモデルの驚異的なパワーと柔軟性を使用したいと思っていますが、私たちが使い慣れたツールとAPIでそれらを扱いたいのです。このブログポストでは、Hugging Faceでそれを実現するために行う選択と、TensorFlowプログラマーとしてフレームワークから期待できることについて説明します。 インタールード:30秒で🤗 経験豊富なユーザーは、このセクションをざっと読んだりスキップしたりして構いませんが、Hugging Faceとtransformersに初めて出会う方には、ライブラリのコアアイデアについて概要を説明する必要があります。モデルを事前学習済みモデルとして名前でリクエストするだけで、1行のコードで取得できます。最も簡単な方法は、TFAutoModelクラスを使用するだけです。 from transformers import TFAutoModel model = TFAutoModel.from_pretrained("bert-base-cased") この1行でモデルのアーキテクチャがインスタンス化され、重みが読み込まれます。これにより、元の有名なBERTモデルの正確なレプリカが得られます。ただし、このモデル自体ではあまり役に立ちません – 出力ヘッドや損失関数がありません。実際には、これは最後の隠れ層の直後で終了するニューラルネットワークの「ステム」です。では、どのようにして出力ヘッドを追加するのでしょうか?簡単です、異なるAutoModelクラスを使用するだけです。ここでは、Vision Transformer(ViT)モデルを読み込み、画像分類ヘッドを追加しています。 from transformers import TFAutoModelForImageClassification…

Skopsの紹介
Skopsの紹介 Hugging Faceでは、オープンソースの機械学習に関するさまざまな問題に取り組んでおり、モデルの安全なホスティングや公開、再現性、説明可能性、コラボレーションなどを可能にしています。私たちは、新しいライブラリ「Skops」をご紹介できることを大変嬉しく思っています!Skopsを使用すると、scikit-learnモデルをHugging Face Hubにホストしたり、モデルのドキュメント用のモデルカードを作成したり、他の人と共同作業したりすることができます。 まず、モデルをトレーニングしてから、Skopsを使用してステップバイステップでsklearnを本番環境で活用する方法を見ていきましょう。 # ライブラリをインポートしましょう import sklearn from sklearn.datasets import load_breast_cancer from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split # データをロードして分割します…

ディープダイブ:Hugging Face Optimum GraphcoreにおけるビジョンTransformer
このブログ投稿では、Hugging Face Optimumライブラリを使用して、事前学習済みのTransformerモデルをあなたのデータセットに簡単に微調整する方法をGraphcoreのIntelligence Processing Units(IPUs)で紹介します。例として、大規模で広く使用されている胸部X線データセットを取り上げ、ビジョンTransformer(ViT)モデルを訓練する手順とノートブックを提供します。 ビジョンTransformer(ViT)モデルの紹介 2017年、GoogleのAI研究者グループがTransformerモデルアーキテクチャを紹介する論文を発表しました。Transformerは新しいセルフアテンションメカニズムによって特徴付けられ、言語アプリケーションのための新しい効率的なモデルのグループとして提案されました。実際、過去5年間でTransformerは爆発的な人気を見ており、自然言語処理(NLP)の事実上の標準として受け入れられています。 言語のためのTransformerは、急速に進化するGPTとBERTモデルファミリーによって特に代表されています。両方とも、Hugging Face Optimum Graphcoreライブラリの一部としてGraphcore IPUs上で簡単かつ効率的に実行することができます。 Transformerモデルアーキテクチャの詳細な説明(NLPに焦点を当てたもの)は、Hugging Faceのウェブサイトで見つけることができます。 Transformerは言語で初期の成功を収めましたが、非常に多目的であり、このブログ投稿でカバーするように、コンピュータビジョン(CV)などのさまざまな目的に使用することができます。 CVは、畳み込みニューラルネットワーク(CNN)が間違いなく最も人気のあるアーキテクチャの1つです。しかし、ビジョンTransformer(ViT)アーキテクチャは、Google Researchが2021年の論文で初めて紹介された画像認識のブレークスルーであり、BERTやGPTと同じセルフアテンションメカニズムを主要なコンポーネントとして使用しています。 BERTや他のTransformerベースの言語処理モデルは、文(つまり単語のリスト)を入力として受け取りますが、ViTモデルは入力画像をいくつかの小さなパッチに分割し、言語処理における個々の単語に相当するものにします。各パッチは、Transformerモデルによって線形にエンコードされ、個別に処理できるベクトル表現に変換されます。この画像をパッチやビジュアルトークンに分割するアプローチは、CNNが使用するピクセル配列とは対照的です。 事前学習により、ViTモデルは画像の内部表現を学習し、それを下流タスクに役立つ視覚的な特徴を抽出するために使用できます。たとえば、事前学習されたビジュアルエンコーダの上に線形層を配置することで、新しいラベル付き画像データセットで分類器を訓練することができます。通常、[CLS]トークンの上に線形層を配置します。このトークンの最後の隠れ状態は、画像全体の表現と見なすことができます。 CNNと比較して、ViTモデルはより高い認識精度を持ちながら、より低い計算コストで動作し、画像分類、物体検出、セグメンテーションなどのさまざまなアプリケーションに適用されています。医療領域のユースケースには、COVID-19、大腿骨骨折、肺気腫、乳がん、アルツハイマー病などの検出と分類などが含まれます。 ViTモデル – IPUに最適なモデル GraphcoreのIPUは、データパイプライニングとモデル並列処理の組み合わせを使用して、ViTモデルに特に適しています。この大規模並列プロセスの高速化は、IPUのMIMDアーキテクチャとIPU-Fabricを中心としたスケールアウトソリューションによって可能になっています。…
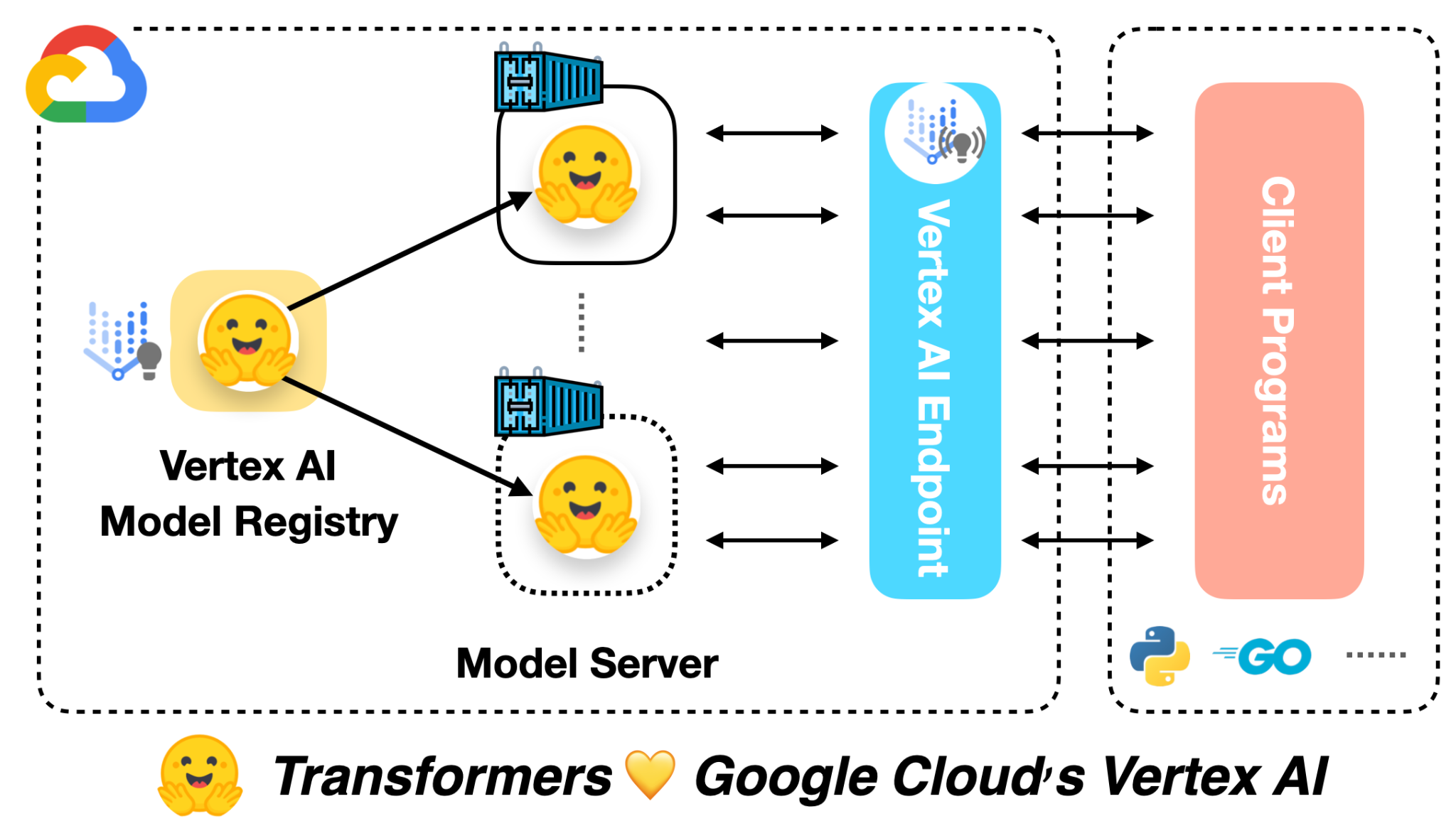
🤗 ViTをVertex AIに展開する
前の投稿では、Vision Transformers(ViT)モデルを🤗 Transformersを使用してローカルおよびKubernetesクラスター上に展開する方法を紹介しました。この投稿では、同じモデルをVertex AIプラットフォームに展開する方法を示します。Kubernetesベースの展開と同じスケーラビリティレベルを実現できますが、コードは大幅に簡略化されます。 この投稿は、上記にリンクされた前の2つの投稿を基に構築されています。まだチェックしていない場合は、それらを確認することをお勧めします。 この投稿の冒頭にリンクされたColab Notebookには、完全に作成された例があります。 Google Cloudによると: Vertex AIは、さまざまなモデルタイプと異なるレベルのMLの専門知識をサポートするツールを提供します。 モデルの展開に関しては、Vertex AIは次の重要な機能を統一されたAPIデザインで提供しています: 認証 トラフィックに基づく自動スケーリング モデルのバージョニング 異なるバージョンのモデル間のトラフィックの分割 レート制限 モデルの監視とログ記録 オンラインおよびバッチ予測のサポート TensorFlowモデルに対しては、この投稿で紹介されるいくつかの既製のユーティリティが提供されます。ただし、PyTorchやscikit-learnなどの他のフレームワークにも同様のサポートがあります。 Vertex AIを使用するには、請求が有効なGoogle Cloud…

Hugging Face TransformersとHabana Gaudiを使用して、BERTを事前に学習する
このチュートリアルでは、Habana GaudiベースのDL1インスタンスを使用してBERT-baseをゼロから事前トレーニングする方法を学びます。Gaudiのコストパフォーマンスの利点を活用するためにAWSで使用します。Hugging Face Transformers、Optimum Habana、およびDatasetsライブラリを使用して、マスクされた言語モデリングを使用してBERT-baseモデルを事前トレーニングします。これは、最初のBERT事前トレーニングタスクの一つです。始める前に、ディープラーニング環境をセットアップする必要があります。 コードを表示する 以下のことを学びます: データセットの準備 トークナイザのトレーニング データセットの前処理 Habana Gaudi上でBERTを事前トレーニングする 注意:ステップ1から3は、CPUを多く使用するタスクのため、異なるインスタンスサイズで実行することができます/すべきです。 要件 始める前に、以下の要件を満たしていることを確認してください DL1インスタンスタイプのクオータを持つAWSアカウント AWS CLIがインストールされていること AWS IAMユーザーがCLIで構成され、ec2インスタンスの作成と管理の権限を持っていること 役立つリソース Hugging Face TransformersとHabana…

最初のデシジョン トランスフォーマーをトレーニングする
以前の投稿で、transformersライブラリでのDecision Transformersのローンチを発表しました。この新しい技術は、Transformerを意思決定モデルとして使用するというもので、ますます人気が高まっています。 今日は、ゼロからオフラインのDecision Transformerモデルをトレーニングして、ハーフチータを走らせる方法を学びます。このトレーニングは、Google Colab上で直接行います。こちらで見つけることができます👉 https://github.com/huggingface/blog/blob/main/notebooks/101_train-decision-transformers.ipynb *ジムのHalfCheetah環境でオフラインRLを使用して学習された「専門家」Decision Transformersモデルです。 ワクワクしませんか?では、始めましょう! Decision Transformersとは何ですか? Decision Transformersのトレーニング データセットの読み込みとカスタムデータコレータの構築 🤗 transformers Trainerを使用したDecision Transformerモデルのトレーニング 結論 次は何ですか? 参考文献 Decision Transformersとは何ですか? Decision…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.