Learn more about Search Results A - Page 769

- You may be interested
- 新車販売が加速し、チップ不足が緩和される
- NVIDIAがFlexiCubesを導入:フォトグラメ...
- 会話型データ分析:ノイズを切り抜いて真...
- 「脳活動計測と仮想現実の統合」
- Falcon AI 新しいオープンソースの大規模...
- メディアでのアルコール摂取の検出:CLIP...
- MLOps(エムエルオプス)とは何ですか?
- 「ゼロからヒーローへ:PyTorchで最初のML...
- 「LangchainとDeep Lakeでドキュメントを...
- 「MITの研究者達が、シーン内の概念を理解...
- 「データ民主化:大企業が取り入れる5つの...
- 「ニューロンの多様性を受け入れる:AIの...
- 「機械学習に人間のミスを組み込む」
- 医療画像は黒い肌に失敗する研究者がそれ...
- 「Microsoftは、AIの著作権争いを引き起こ...
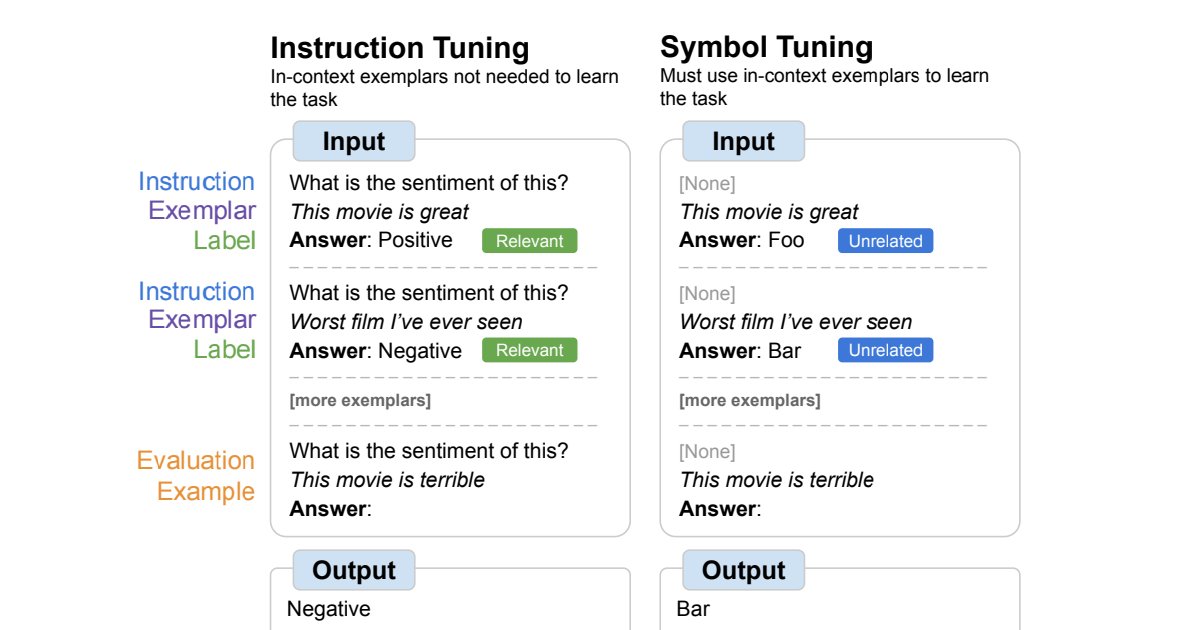
シンボルの調整は言語モデルの文脈における学習を向上させます
Google Researchの学生研究者であるJerry Weiと主任科学者のDenny Zhouによって投稿されました。 人間の知性の重要な特徴の一つは、わずかな例だけを用いて推論することで新しいタスクを学ぶことができることです。言語モデルのスケーリングによって、マシンラーニングにおいて新たな応用やパラダイムを実現することができました。しかし、言語モデルはプロンプトの与え方に敏感であり、頑健な推論を行っているわけではないことを示しています。例えば、言語モデルはしばしばプロンプトエンジニアリングやタスクの指示としてのフレーズのような作業が必要であり、不正確なラベルが表示されてもタスクのパフォーマンスに影響を与えないという予期しない振る舞いを示すことがあります。 「Symbol tuning improves in-context learning in language models」では、シンボルチューニングと呼ばれるシンプルなファインチューニング手法を提案しています。この手法は入力とラベルのマッピングを強調することで、インコンテキスト学習を改善することができます。私たちはFlan-PaLMモデルにおけるシンボルチューニングの実験を行い、さまざまな設定での利点を観察しました。 シンボルチューニングは、未知のインコンテキスト学習タスクにおいてパフォーマンスを向上させ、指示や自然言語のラベルがないような曖昧なプロンプトに対しても非常に頑健です。 シンボルチューニングされたモデルは、アルゴリズムの推論タスクにおいて非常に強力です。 最後に、シンボルチューニングされたモデルは、インコンテキストで提示された反転したラベルを追従する能力が大幅に向上しており、インコンテキスト情報を使用して以前の知識を上書きすることができます。 シンボルチューニングの概要。モデルは自然言語のラベルが任意のシンボルに置き換えられたタスクでファインチューニングされます。シンボルチューニングは、指示や関連するラベルが利用できない場合、モデルがインコンテキストの例を使用してタスクを学ぶ必要があるという直感に基づいています。 動機 指示チューニングは一般的なファインチューニング手法であり、パフォーマンスを向上させ、モデルがインコンテキストの例に従う能力を改善することが示されています。ただし、評価例に指示と自然言語のラベルを通じてタスクが冗長に定義されるため、モデルは例を使用する必要がありません。例えば、上の図の左側では、例がモデルがタスク(感情分析)を理解するのに役立つことができますが、モデルは例を無視してタスクを示す指示を読むことができます。 シンボルチューニングでは、モデルは指示が削除され、自然言語のラベルが意味的に関連のないラベル(例:「Foo」、「Bar」など)に置き換えられた例でファインチューニングされます。この設定では、インコンテキストの例を見ないとタスクが明確になりません。例えば、上の図の右側では、タスクを理解するために複数のインコンテキストの例が必要です。シンボルチューニングはモデルにインコンテキストの例を推論することを教えるため、シンボルチューニングされたモデルは、インコンテキストの例とそのラベルの間の推論を必要とするタスクにおいてより優れたパフォーマンスを発揮するはずです。 シンボルチューニングに使用されるデータセットとタスクの種類。 シンボル調整手順 私たちは、シンボル調整手順に使用するために、22の公開されている自然言語処理(NLP)データセットを選択しました。これらのタスクは過去に広く使用されており、私たちは離散的なラベルを必要とするため、分類タイプのタスクのみを選択しました。その後、ラベルを整数、文字の組み合わせ、および単語の3つのカテゴリから選択された約30,000の任意のラベルの1つにランダムにマッピングします。 実験では、PaLMの指示に調整されたバリアントであるFlan-PaLMをシンボル調整します。Flan-PaLMモデルの3つの異なるサイズを使用します:Flan-PaLM-8B、Flan-PaLM-62B、およびFlan-PaLM-540B。また、Flan-cont-PaLM-62B(780Bトークンではなく1.3TトークンでのFlan-PaLM-62B)もテストし、62B-cと略称します。…

「Googleは、データの不適切な使用によるLLMの訓練を訴えられています」
新たな訴訟で、Googleは個人データを不正に利用してAI製品を駆動する彼らの大規模言語モデルを訓練しているという非難に直面していますこの訴訟では、テックジャイアントが数百万人のユーザーのデータを彼らの同意なく収集し、訓練過程で著作権法に違反していると主張しています...

「サンノゼは歩行者の交通事故死を防ぐために人工知能を活用する方法をここで紹介します」
「AIは、先週末に発生したひき逃げ事故で2人の命が失われた都市において、交通事故や歩行者の死亡について話す際には、貴重なツールと考えられるかもしれません」
「エラーバーの可視化に深く潜る」
データの可視化は、人間が理解できるように情報を簡素化するためのデータの専門家のツールですこの技術により、人々は迅速に重要なパターンを把握し、簡単に解釈することができます…
「データ分析の最先端にいるための私のインスピレーションを与える学習リソース5選」
「スキルと専門知識を伸ばすための10のインスピレーションを与える学習リソース」
プロンプトエンジニアリングを改善するための5つの戦略
「AI生成コンテンツの品質向上のための5つの効果的な戦略を見つけましょうChatGPTを使用してコンテンツ作成のためのプロンプトエンジニアリングスキルを向上させましょう」

「2023年に知っておく必要のあるトップ10のディープラーニングツール」
コンピュータと人工知能の世界の複雑な問題には、ディープラーニングツールの支援が必要です。課題は時間とともに変化し、分析パターンも変わります。問題に対処するためのツールの定期的な更新と新しい視点には、実地の専門知識とディープラーニングツールの経験が必要です。トップツールの更新されたリストと各ツールの主な機能を確認してください。 ディープラーニングとは何ですか? ディープラーニングは、機械学習のサブセットであり、コンピュータの操作学習に重要な人工知能の一部です。関連するディープラーニングツールは、コンピュータのデータとパターンを処理して意思決定を行うプログラムのキュレーションを担当しています。アルゴリズムによる予測分析が可能です。 トップ10のビッグデータツール ビッグデータツールは、従来のシステムでは効率的に処理できない大量のデータを扱うために不可欠です。これらのツールを活用することで、企業はデータに基づいた意思決定を行い、競争力を持ち、全体的な業務効率を向上させることができます。以下はトップ10のビッグデータツールです: TensorFlow Keras PyTorch OpenNN CNTK MXNet DeeplearningKit Deeplearning4J Darknet PlaidML TensorFlow 主な機能: TensorFlowは、Go、Java、Pythonなどの異なる言語でインターフェースを提供しています。 グラフィックの可視化を可能にします。 組み込みおよびモバイルデバイスを含む、ビルドおよび展開のためのモデルを含んでいます。 コミュニティのサポート 効率的なドキュメンテーション機能 コンピュータビジョン、テキスト分類、画像処理、音声認識が可能です。 多層の大規模なニューラルネットワークに適しています。…
「10/7から16/7までのトップコンピュータビジョン論文」
コンピュータビジョンは、機械に視覚世界を解釈し理解させることに焦点を当てた人工知能の分野であり、画期的な研究と技術の進化により急速に進化しています
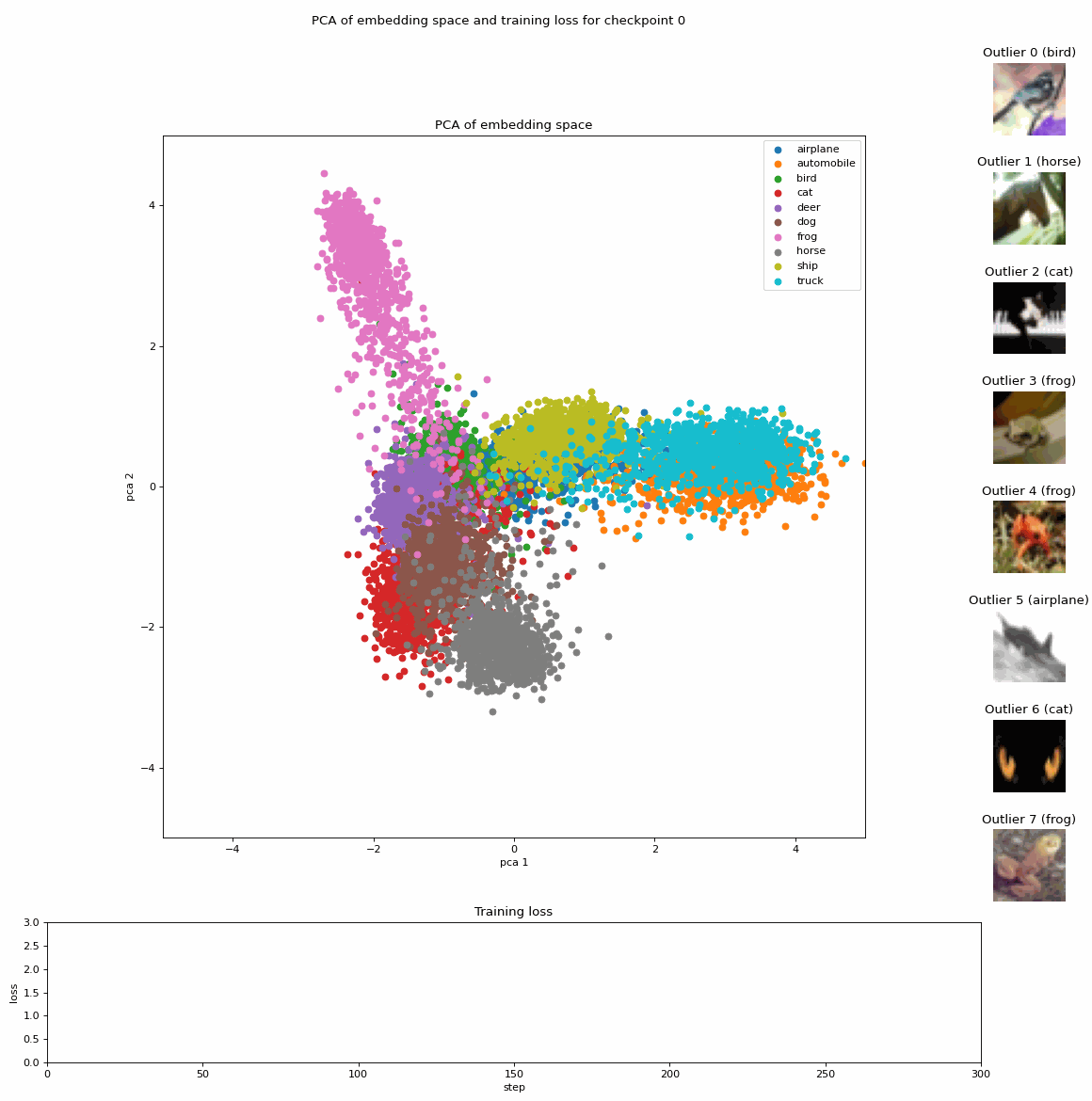
「ファインチューニング中に埋め込みのアニメーションを作成する方法」
「機械学習の分野では、ビジョントランスフォーマー(ViT)は画像分類に使用されるモデルの一種です従来の畳み込みニューラルネットワークとは異なり、ViTはトランスフォーマーアーキテクチャを使用します…」
SQLを使用して解析関数を活用し、データの抽出を高速化する
アナリティクスの専門家として、解析のためにデータをクエリする必要があるシナリオに自分自身を置くことが多いでしょう非常に頻繁に、データはSQLデータベースから取得され、その後インポートされます...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.