Learn more about Search Results A - Page 764

- You may be interested
- シリコンボレー:デザイナーがチップ支援...
- ベルマン-フォードアルゴリズム:重み付き...
- ソートアルゴリズムの概要:マージソート
- 「データビジュアルの誤り:一般的なGPT-4...
- 「意思決定科学は静かに新しいデータサイ...
- スタビリティAIチームが、新しいオープン...
- 「TRLを介してDDPOを使用して、安定したデ...
- AIが脳の液体の流れを示すのに役立つ
- 「ジェネレーティブAI 2024年とその先:未...
- メタAIは、リアルタイムに高品質の再照明...
- 研究者がCODES+ISSS最優秀論文賞を受賞し...
- 「混合エキスパートモデルの理解に向けて」
- 「ガードレールでLLMを保護する」
- AIイメージフュージョンとDGX GH200
- 「中国、新たな規制提案でAIデータのセキ...
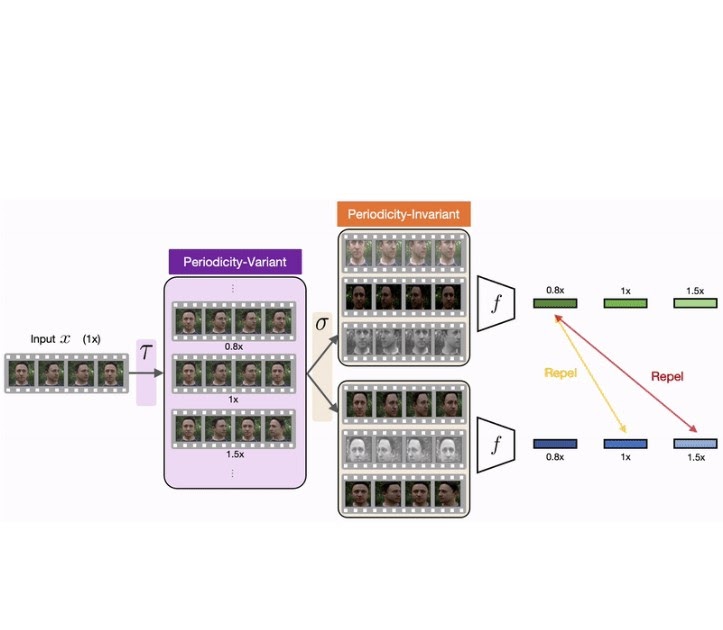
SimPer:周期的なターゲットの簡単な自己教示学習
Googleのスタッフ研究者であるDaniel McDuffと学生研究者のYuzhe Yangによって投稿されました。 周期的なデータ(心拍や地球表面の日々の気温変化など、繰り返される信号)から学ぶことは、天候システムの監視から生体徴候の検出まで、多くの実世界のアプリケーションにとって重要です。例えば、環境遠隔検出の領域では、降水パターンや地表温度などの環境変化のナウキャスティングを可能にするために周期的な学習がしばしば必要です。健康領域では、ビデオ測定から学んだ結果、心房細動や睡眠時無呼吸などの(準)周期的な生体徴候を抽出することが示されています。 RepNetなどのアプローチは、これらのタスクの重要性を強調し、単一のビデオ内で繰り返されるアクティビティを認識する解決策を提供しています。ただし、これらは教師ありのアプローチであり、繰り返されるアクティビティを捉えるために大量のデータと、アクションが繰り返された回数を示すラベルが必要です。このようなデータのラベリングは、しばしば難しくリソースを消費するため、研究者は興味の対象のモダリティ(ビデオや衛星画像など)と同期したゴールドスタンダードの時間的計測を手動でキャプチャする必要があります。 代わりに、自己教師あり学習(SSL)の手法(SimCLRやMoCo v2など)は、周期的または準周期的な時間的ダイナミクスを捉える表現を学習するためにラベルの付いていない大量のデータを活用することで、分類タスクの解決に成功しています。しかし、これらの手法は、データの固有の周期性(つまり、フレームが周期的なプロセスの一部であるかどうかを識別する能力)を見落とし、周期的な属性や周波数属性を捉える堅牢な表現を学習することができません。これは、周期的な学習が一般的な学習タスクとは異なる特性を持つためです。 周期的表現の文脈での特徴の類似性は、静的な特徴(例えば画像)とは異なります。例えば、短い時間遅れでオフセットされたビデオや反転されたビデオは、元のサンプルと類似しているべきです。一方、ビデオのアップサンプリングやダウンサンプリングは、元のサンプルから因子xで異なるはずです。 これらの課題に対処するために、私たちは「SimPer: Simple Self-Supervised Learning of Periodic Targets」という論文で、データ内の周期的な情報を学習するための自己教師ありの対照的なフレームワークを紹介しました。具体的には、SimPerは周期性不変および周期性変動の拡張によって、同じ入力インスタンスから正例と負例のサンプルを取得することで、周期性のあるターゲットの時間的特性を活用します。周期的な特徴の類似性を提案し、周期的な学習の文脈で類似性を測定する方法を明示的に定義します。さらに、古典的なInfoNCE損失をソフト回帰バリアントに拡張した汎用の対照的な損失を設計し、連続したラベル(周波数)を対照することを可能にします。次に、SimPerが最新のSSL手法と比較して効果的に周期的な特徴表現を学習することを示し、データの効率性、誤った相関に対する堅牢性、分布のシフトに対する一般化能力など、その興味深い特性を強調します。最後に、私たちはSimPerのコードリポジトリを研究コミュニティと共有することを楽しみにしています。 SimPerフレームワーク SimPerは、時間的な自己対照的学習フレームワークを導入します。正例と負例のサンプルは、周期性不変および周期性変動の拡張によって同じ入力インスタンスから取得されます。時間的なビデオの例では、周期性不変の変更にはトリミング、回転、反転があり、周期性変動の変更にはビデオの速度の増減が含まれます。 周期的な学習の文脈で類似性を測定する方法を明示的に定義するために、SimPerは周期的な特徴の類似性を提案します。この構成により、トレーニングを対照的な学習タスクとして定式化することができます。モデルはラベルのないデータでトレーニングされ、必要に応じて学習された特徴を特定の周波数値にマッピングするために微調整されることができます。 入力シーケンスxが与えられた場合、関連する周期的な信号が存在することがわかります。そして、xを変換して速度や周波数が変化したサンプルのシリーズを作成し、基になる周期的なターゲットを変更し、異なる負のビューを作成します。元の周波数は不明ですが、ラベルのない入力xに対して擬似的な速度や周波数のラベルを効果的に考案します。 従来の類似性尺度(例:コサイン類似度)は、2つの特徴ベクトル間の厳密な近接性を強調し、インデックスがシフトした特徴(異なるタイムスタンプを表す)、逆転した特徴、および周波数が変化した特徴に対して敏感です。一方、周期的な特徴類似性は、時間的なシフトが小さく、または逆転したインデックスがあるサンプルに対して高くなるべきであり、特徴の周波数が変化する際に連続的な類似性の変化を捉えるべきです。これは、フーリエ変換間の距離など、周波数領域の類似度尺度によって実現できます。 周波数領域で増強されたサンプルの固有の連続性を活用するために、SimPerは一般化された対照的損失を設計します。この損失は、古典的なInfoNCE損失をソフト回帰のバリアントに拡張し、連続的なラベル(周波数)に対して対比を可能にします。これにより、心拍などの連続信号を回復するという回帰タスクに適しています。 SimPerは、周波数領域でデータのネガティブビューを構築することによって、データの変換を行います。入力シーケンスxには、関連する周期的な信号があります。SimPerは、xを変換して速度や周波数が変化したサンプルのシリーズを作成します。これにより、基礎となる周期的なターゲットが変わり、異なるネガティブビューが作成されます。元の周波数は不明ですが、未ラベルの入力xに対して疑似的な速度や周波数ラベル(周期性変数の増強τ)を効果的に設計します。SimPerは、入力の識別を変更しない変換を取り、これらを周期性に関して不変な増強σと定義し、サンプルの異なるポジティブビューを作成します。そして、これらの増強ビューをエンコーダfに送り、対応する特徴を抽出します。 結果 SimPerの性能を評価するために、人間の行動分析、環境リモートセンシング、および医療の共通の実世界タスクに対して、SimPerを最新のSSLスキーム(例:SimCLR、MoCo…

「アメリカでの顔認識技術は、最大の試練のひとつに直面する」
「マサチューセッツ州の警察の使用を制限する法案は、アメリカでの技術の規制の基準を設定する可能性があります」
未来への進化-新しいウェーブガイドがデータの転送および操作方法を変えています
物理学者たちは、メタサーフェス上で電磁スピンをエンジニアリングする方法を開拓し、ますますデジタル化する世界のデータストレージと転送のニーズに対応しています

「車泥棒を阻止する驚くほどシンプルな方法」
「ライトをつけたり、ワイパーを動かしたりすることで、将来的には車両への追加のセキュリティが可能になるかもしれません」

チポトレは、ガカモレの準備をするロボット「オートカド」を導入します
チポトレは自動化ソリューション企業Vebuと提携し、Autocadoというアボカド処理ロボットをデビューさせましたこのロボットは、ガカモレの準備時間を50%削減します

「VRは私たちを健康にするために自然の力を模倣できるのか?」
科学者たちは、仮想現実が自然にいることのいくつかの健康上の利益を提供できるかどうかを調査しています

バイオセンサーがリアルタイムの透析フィードバックを提供します
イランのシャフルード工科大学の研究者たちは、リアルタイムで透析フィードバックを提供することにより、血液透析手続きを迅速化するための新しいバイオセンサーを開発しました
リアルタイムでデータを理解する
このブログ投稿では、オープンソースのストリーミングソリューションであるbytewaxと、ydata-profilingを組み合わせて活用する方法について説明しますこれにより、ストリーミングフローの品質を向上させることができます

「Google DeepMindの最新研究、ICML 2023にて」
Google DeepMindの研究者たちは、2023年7月23日から29日までハワイ州ホノルルで開催される第40回国際機械学習会議(ICML 2023)で80以上の新しい論文を発表します

LMSYS ORG プレゼント チャットボット・アリーナ:匿名でランダムなバトルを行うクラウドソーシング型 LLM ベンチマーク・プラットフォーム
多くのオープンソースプロジェクトは、特定のタスクを実行するためにトレーニングできる包括的な言語モデルを開発しています。これらのモデルは、ユーザーからの質問やコマンドに有用な応答を提供することができます。注目すべき例には、LLaMAベースのアルパカとビクーナ、およびPythiaベースのOpenAssistantとDollyがあります。 毎週新しいモデルがリリースされているにもかかわらず、コミュニティはまだ適切にベンチマークを行うことに苦労しています。LLMアシスタントの関心事はしばしば曖昧なため、回答の品質を自動的に評価できるベンチマークシステムを作成することは困難です。ここでは、対称比較に基づいたスケーラブルで増分的かつ独自のベンチマークシステムが理想的です。 現在のLLMベンチマークシステムのうち、これらの要件をすべて満たすものはほとんどありません。HELMやlm-evaluation-harnessなどの従来のLLMベンチマークフレームワークは、研究基準のタスクに対する複数のメトリック測定を提供します。ただし、対称比較に基づいていないため、自由形式の質問を適切に評価することはありません。 LMSYS ORGは、オープンでスケーラブルかつアクセス可能な大規模なモデルとシステムを開発する組織です。彼らの新しい取り組みであるChatbot Arenaは、匿名でランダムなバトルが行われるクラウドソーシングのLLMベンチマークプラットフォームを提供しています。チェスや他の競技ゲームと同様に、Chatbot ArenaではEloレーティングシステムが採用されています。Eloレーティングシステムは、前述の望ましい品質を提供する可能性があります。 彼らは1週間前にアリーナをオープンし、多くの有名なオープンソースLLMと共に情報を収集し始めました。LLMの実世界の応用例は、クラウドソーシングのデータ収集方法で確認することができます。ユーザーはアリーナで同時に2つの匿名モデルとチャットしながら、それらを比較対照することができます。 マルチモデルサービングシステムであるFastChatは、https://arena.lmsys.orgでアリーナをホストしています。アリーナに入場すると、匿名の2つのモデルとの会話に直面します。ユーザーが両方のモデルからコメントを受け取ると、会話を続けるか、どちらが好きかを投票することができます。投票が行われると、モデルの正体が明らかになります。ユーザーは同じ2つの匿名モデルと会話を続けたり、2つの新しいモデルとの新たなバトルを開始したりすることができます。システムはすべてのユーザーアクティビティを記録します。分析で投票が見えなくなるまで、モデル名は隠されます。アリーナがオープンしてから1週間で、約7,000件の合法的な匿名投票が集計されました。 将来的には、より多様なモデルを収容し、さまざまなタスクに対して詳細なランクを提供するために、改良されたサンプリングアルゴリズム、トーナメント手順、およびサービングシステムを実装したいと考えています。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.