Learn more about Search Results Yi - Page 75

- You may be interested
- 「夢を先に見て、後で学ぶ:DECKARDは強化...
- 最初のネイティブLLMは電気通信業界に最適...
- 無料でGoogle Colab上でQLoraを使用してLL...
- 『NYU研究者が提案するGPQA 生物学、物理...
- 『CMUからの新しいAI研究は、適切な言語モ...
- 研究者たちは、ビデオ記録を使用して、鳥...
- 「Spring Bootを使用して独自のChatGPTア...
- 「GoogleがプロジェクトIDXを発表:AIパワ...
- 「Google Quantum AIは、薬学、化学、およ...
- BrainPadがAmazon Kendraを使用して内部の...
- 7月号 データサイエンティストのための気...
- 「それは面白いですが、AIモデルは冗談が...
- ランダムウォークタスクにおける時差0(Tem...
- AIがセキュリティを向上させる方法
- 「スーパーアラインメントとは何か?なぜ...
GEKKOを使用して、世界を確定的な方法でモデリングする
私たちの世界がますますデジタル化される中で、データ収集は急速に拡大していますこのデータによって、私たちはより正確なモデルを作成し、問題を解決し最適化するための手助けをしてきました...

エンタープライズAIとは何ですか?
エンタープライズAIの紹介 時間は重要であり、自動化が答えです。退屈で単調なタスク、人間によるミス、競争の混乱、そして最終的には曖昧な意思決定の苦闘の中で、エンタープライズAIは企業が機械と協力してより効率的に働くことを可能にしています。さもなければ、Netflixでお気に入りの番組を見つけたり、Amazonで必要なアクセサリーを見つけて購入する方法はどうやって見つけるのでしょうか?自動車のWaymoからマーケティングでの迅速な分析まで、人工知能はすでに私たちに十分な理由を提供しています。しかし、それが組織をどのように助けているのでしょうか?また、組織はそれをどのように使用しているのでしょうか?答えはエンタープライズAIです。 こんにちは! Analytics Vidhya Blogの熱心な読者として、私たちはあなたに素晴らしい機会を提供したいと思います。データサイエンスとAIの愛好家の皆さん、ぜひ私たちと一緒に非常に期待されているDataHack Summit 2023に参加してください。8月2日から5日まで、バンガロールの名門NIMHANSコンベンションセンターで行われます。このイベントは、実践的な学習、貴重な業界の洞察、そして無敵のネットワーキングの機会で満たされた、爆発的なものになるでしょう。これらのトピックに興味があり、これらのコンセプトが現実になることをもっと学びたい場合は、こちらのDataHack Summit 2023の情報をチェックしてください。 エンタープライズAIの定義 エンタープライズAIは、大規模な組織内で人工知能技術と技法を応用して、さまざまな機能を改善することを指します。これらの機能には、データの収集と分析、自動化、顧客サービス、リスク管理などが含まれます。エンタープライズAIは、AIアルゴリズム、機械学習(ML)、自然言語処理(NLP)、コンピュータビジョンなどのツールを使用して、複雑なビジネスの問題を解決し、プロセスを自動化し、大量のデータから洞察を得ることを目指しています。 エンタープライズAIは、サプライチェーン管理、ファイナンス、マーケティング、顧客サービス、人事、サイバーセキュリティなど、さまざまな領域に実装することができます。これにより、組織はデータに基づいた意思決定を行い、効率を向上させ、ワークフローを最適化し、顧客体験を向上させ、市場で競争力を持つことができます。 出典:Publicis Sapient エンタープライズAIの主な特徴 エンタープライズAIは、データ分析から自動化まで、組織のさまざまな側面に貢献します。それは異なる技術や技法、そして方法の産物であり、それは各業界やビジネスによって異なるかもしれません。以下にその仕組みを示します。 エンタープライズアプリケーション向けのAI技術の組み合わせ エンタープライズAI企業は、機械学習、自然言語処理、エッジコンピューティング、ディープラーニング、コンピュータビジョンなどの技術の組み合わせを活用することができます。これらの技術は、予測分析、画像認識などのタスクを通じて、ビジネスを支援するための強力な機能を提供します。Netflixのパーソナライズされた推奨機能は、ディープラーニングなどの技術を使用した、その一例です。 組織のニーズに合わせてカスタマイズされ設計された エンタープライズAIは、さまざまな技術の組み合わせです。組織がシステム内でどのようにアプローチするか、どの技法を採用するかは、ビジネスの要件によるものです。なぜなら、サプライチェーン管理に適した方法が、eコマースの場合に必要なわけではないからです。 たとえば、ヘルスケアのエンタープライズAI企業は、画像解析、患者モニタリングなどの技法を採用して、医療業務の効率を向上させています。エネルギー業界では、予測保守、再生可能エネルギーの統合などの技術と技法を使用して、エネルギーの発電と消費を最適化しています。その活用方法の違いにより、組織は人工知能のさまざまな分野を航海しています。 エンタープライズAIの利点と応用 以下はエンタープライズAIの主な利点です:…

テキストブック品質の合成データを使用して言語モデルをトレーニングする
マイクロソフトリサーチは、データの役割についての現在進行中の議論に新たな燃料を加える論文を発表しました具体的には、データの品質と合成データの役割に触れています
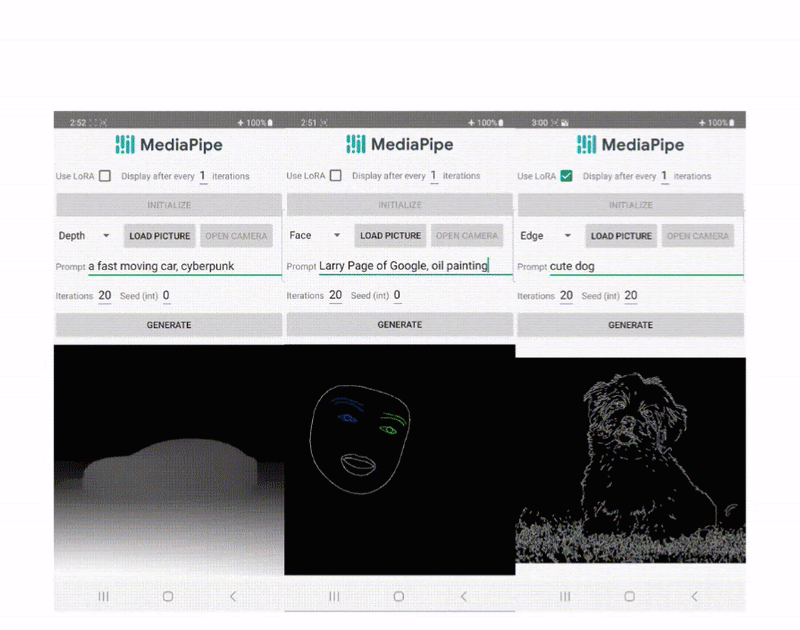
デバイス上での条件付きテキストから画像生成のための拡散プラグイン
Yang ZhaoとTingbo Houによる投稿、ソフトウェアエンジニア、Core ML 近年、拡散モデルはテキストから画像を生成する際に非常に成功を収め、高品質な画像、改善された推論パフォーマンス、そして創造的なインスピレーションの拡大を実現しています。しかし、特にテキストで説明しづらい条件での生成を効率的に制御することはまだ困難です。 本日、MediaPipe拡散プラグインを発表し、コントロール可能なテキストから画像をデバイス上で実行できるようにします。オンデバイスの大規模生成モデルにおけるGPU推論に関する以前の作業を拡張し、既存の拡散モデルとその低ランク適応(LoRA)バリアントにプラグインを追加し、コントロール可能なテキストから画像を生成するための低コストなソリューションを提供します。 デバイス上で動作するコントロールプラグインによるテキストからの画像生成。 背景 拡散モデルでは、画像生成はイテレーションのノイズ除去プロセスとしてモデル化されます。ノイズ画像から始め、各ステップで、拡散モデルは画像を徐々にノイズ除去して目標のコンセプトの画像を明らかにします。研究によると、テキストプロンプトを介した言語理解を活用することで、画像生成を大幅に改善できます。テキストから画像を生成する場合、テキストの埋め込みはモデルにクロスアテンションレイヤーを介して接続されます。しかし、位置や姿勢など、一部の情報はテキストプロンプトで説明することが難しいです。この問題を解決するために、研究者は拡散に追加のモデルを追加して、条件画像から制御情報を注入します。 制御されたテキストから画像を生成するための一般的なアプローチには、Plug-and-Play、ControlNet、T2I Adapterなどがあります。Plug-and-Playは、広く使用されているノイズ除去拡散暗黙モデル(DDIM)の逆操作アプローチを適用し、入力画像から初期ノイズ入力を導出し、拡散モデルのコピー(安定拡散1.5用の860Mパラメータ)を使用して入力画像から条件をエンコードします。Plug-and-Playは、コピーされた拡散から自己注意で空間特徴を抽出し、それらをテキストから画像への拡散に注入します。ControlNetは、拡散モデルのエンコーダーの学習可能なコピーを作成し、ゼロで初期化されたパラメータを持つ畳み込み層を介してデコーダーレイヤーに接続し、条件情報をエンコードします。しかし、その結果、サイズが大きく、拡散モデルの半分(安定拡散1.5用の430Mパラメータ)になります。T2I Adapterはより小さなネットワーク(77Mパラメータ)であり、制御可能な生成に似た効果を実現します。T2I Adapterは条件画像のみを入力とし、その出力はすべての拡散イテレーションで共有されます。ただし、アダプターモデルはポータブルデバイス向けに設計されていません。 MediaPipe拡散プラグイン 条件付き生成を効率的かつカスタマイズ可能、スケーラブルにするために、MediaPipe拡散プラグインを別個のネットワークとして設計しました。これは以下のような特徴を持っています: プラグ可能:事前にトレーニングされたベースモデルに簡単に接続できます。 スクラッチからトレーニング:ベースモデルの事前トレーニング済みの重みを使用しません。 ポータブル:ベースモデル外でモバイルデバイス上で実行され、ベースモデルの推論と比較して無視できるコストです。 メソッド パラメーターサイズ プラグ可能 スクラッチからトレーニング ポータブル Plug-and-Play…
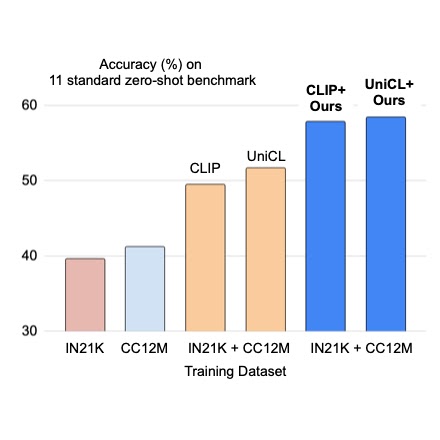
プレフィックス条件付きの画像キャプションと画像分類のデータセットの統合
クラウドAIチームの学生研究者である斎藤邦明と知識チームの研究科学者であるソン・キヒョクによる投稿 ウェブスケールの画像キャプションデータセットでの視覚言語(VL)モデルの事前トレーニングは、画像分類データによる従来の事前トレーニングに対する強力な代替手段として最近注目されています。画像キャプションデータセットはより「オープンドメイン」であると考えられており、広範なシーンタイプや語彙の単語を含んでいるため、少数およびゼロショットの認識タスクで強力な性能を持つモデルが得られます。しかし、細粒度のクラスの説明を持つ画像は稀であり、画像キャプションデータセットは手動のキュレーションを経ていないため、クラスの分布が不均衡になる可能性があります。これに対して、ImageNetなどの大規模な分類データセットは通常キュレーションされており、バランスの取れたラベル分布を持つ細粒度のカテゴリを提供することができます。一見有望に聞こえるかもしれませんが、キャプションと分類データセットを直接組み合わせて事前トレーニングすることは、さまざまな下流タスクに対してうまく汎化しないバイアスのある表現を生み出す可能性があるため、通常は成功しないことがあります。 CVPR 2023で発表された「Prefix Conditioning Unifies Language and Label Supervision」では、分類とキャプションデータセットの両方を使用して補完的な利点を提供する事前トレーニング戦略を示しています。まず、データセットを単純に統合すると、モデルはデータセットのバイアスに影響を受け、下流のゼロショット認識タスクでの最適な性能を発揮しない結果となります。各データセットにおける画像ドメインと語彙のカバレッジは異なるためです。この問題に対処するために、我々はプレフィックス条件付けという新しい簡単で効果的な手法を使用して、トレーニング中にデータセットのバイアスと視覚的な概念を分離します。このアプローチにより、言語エンコーダは両方のデータセットから学習すると同時に、各データセットに対して特徴抽出を調整することができます。プレフィックス条件付けは、Contrastive Language-Image Pre-training(CLIP)やUnified Contrastive Learning(UniCL)などの既存のVL事前トレーニング目標に簡単に統合できる汎用の手法です。 高レベルのアイデア 分類データセットは少なくとも2つの方法でバイアスがかかる傾向があります:(1)画像には制限されたドメインの単一のオブジェクトがほとんど含まれており、(2)語彙が限定されており、ゼロショット学習に必要な言語の柔軟性を欠いています。たとえば、「犬の写真」というクラスの埋め込みは、通常、ImageNet向けに最適化されたものでは、ImageNetデータセットから引っ張られた画像の中央に1匹の犬の写真が表示されるものであり、他のデータセットに含まれる複数の位置にいる犬の画像や他の被写体との組み合わせにはうまく汎化しません。 それに対して、キャプションデータセットにはさまざまなシーンタイプと語彙が含まれています。以下に示すように、モデルが単純に2つのデータセットから学習する場合、言語の埋め込みは画像分類とキャプションデータセットのバイアスを絡め取る可能性があり、ゼロショット分類の汎化性能が低下することがあります。2つのデータセットのバイアスを分離できれば、キャプションデータセットに適した言語の埋め込みを使用して汎化性能を向上させることができます。 上:画像分類とキャプションデータセットのバイアスを絡め取る言語の埋め込み。下:2つのデータセットのバイアスを分離した言語の埋め込み。 プレフィックス条件付け プレフィックス条件付けは、プロンプトチューニングに部分的に触発された手法であり、学習可能なトークンを入力トークンシーケンスの前に追加することで、事前トレーニング済みのモデルバックボーンにタスク固有の知識を学習させ、それを使用して下流タスクを解決するための方法を指示します。プレフィックス条件付けアプローチは、プロンプトチューニングとは異なる2つの点で異なります:(1)データセットのバイアスを分離するために画像キャプションと分類データセットを統合するように設計されており、(2)VL事前トレーニングに適用される一方、標準のプロンプトチューニングはモデルの微調整に使用されます。プレフィックス条件付けは、ユーザーが提供するデータセットの種類に基づいてモデルバックボーンの振る舞いを明示的に制御する方法です。特に、さまざまなタイプのデータセットの数が事前にわかっている場合に役立ちます。 トレーニング中、接頭辞条件付けは、各データセットタイプごとにテキストトークン(接頭辞トークン)を学習し、データセットのバイアスを吸収し、残りのテキストトークンが視覚的な概念を学習することに集中できるようにします。具体的には、入力トークンの先頭に各データセットタイプごとの接頭辞トークンを追加し、入力データのタイプ(分類対キャプションなど)に関する言語エンコーダと視覚エンコーダに情報を提供します。接頭辞トークンはデータセットタイプ固有のバイアスを学習するため、言語表現のバイアスを分離し、入力キャプションなしでもテスト時に画像キャプションデータセットで学習された埋め込みを利用することができます。 CLIPでは、言語エンコーダと視覚エンコーダを使用して接頭辞条件付けを利用します。テスト時には、画像キャプションデータセットで使用された接頭辞を使用します。このデータセットはより広範なシーンタイプと語彙をカバーするため、ゼロショット認識の性能が向上します。 接頭辞条件付けのイラスト。 実験結果…
GPTと人間の心理学
GPTと人間の心理学との類推を行うことで、私たちは生成型AIの出力を促進する方法を理解することができます

Google MusicLMを使用してテキストから音楽を生成する
Googleの最新のAI音楽モデルの大きな進歩をご紹介します

SparkとTableau Desktopを使用して洞察に富んだダッシュボードを作成する
データの視覚的表現として、データの可視化はデータ分析において広く採用されている手法であり、有益なビジネスの洞察(トレンド、パターン、外れ値、相関関係など)を得るための手段です
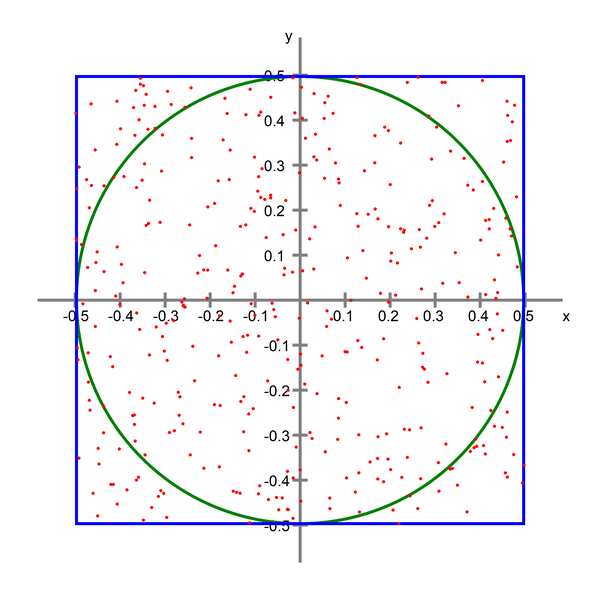
次元の呪いの真の範囲を可視化する
非常に多くの特徴を持つ観測の振る舞いを視覚化するために、モンテカルロ法を使用する

音声認証システムのセキュリティはどの程度安全ですか?
コンピュータ科学者は、6回の試行で音声認証セキュリティシステムを回避する攻撃を開発しました
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.