Learn more about Search Results OPT - Page 75

- You may be interested
- 「ODSCウェストからの9つのセッション、私...
- 「2023年にサプライチェーンアナリストに...
- AIを活用した亀の顔認識による保全の推進
- 「2024年に注目すべきサイバーセキュリテ...
- 「時系列分析を用いた回帰モデルの頑健性...
- キャンドル:Rustでのミニマリストな機械学習
- 「クラスの不均衡とオーバーサンプリング...
- 『思考の整理、早くて遅い+AI』
- 「私と一緒に読む:因果律の読書クラブ」
- 見逃せない7つの機械学習アルゴリズム
- マルチモーダルAIがデジタルのつながりを...
- フリーMITコース:TinyMLと効率的なディー...
- 音声合成、音声認識、そしてSpeechT5を使...
- 「超伝導デバイスは、コンピューティング...
- 「大規模言語モデルのランドスケープをナ...

プリンストン大学の研究者が、MeZOというメモリ効率の高いゼロ次最適化器を紹介しましたこの最適化器は、大規模言語モデル(LLM)を微調整することができます
大きな言語モデルは、過去数ヶ月のジェネレーティブ人工知能の大成功により、急速に進化しています。これらのモデルは、驚くべき経済的および社会的変革に寄与しており、その最良の例はOpenAIによって開発されたChatGPTです。このチャットボットは、自然言語処理(NLP)と自然言語理解(NLU)に基づいており、ユーザーが人間のような意味のあるテキストを生成することができます。質問に意味を持って回答したり、長いパラグラフを要約したり、コードやメールを補完したりすることができます。PaLM、Chinchilla、BERTなどの他のLLMもAIの領域で優れたパフォーマンスを示しています。 事前に学習された言語モデルの微調整は、多くの言語関連のタスクにおいて人気のある手法です。微調整により、これらのモデルは特定のドメインに適応し、人間の指示を組み込み、個々の好みに合わせることができます。基本的には、既に学習されたLLMのパラメータを、より小さくドメイン固有のデータセットを使用して調整します。言語モデルがパラメータを増やすにつれて、微調整は逆伝播中の勾配計算の過程で計算量が多く、メモリを多く必要とします。メモリ使用量は、アクティベーションや勾配のキャッシュ、勾配履歴の保存などの関与により、推論に必要なものよりも大幅に高くなります。 最近、プリンストン大学の研究チームがメモリの問題に対する解決策を提案しました。MeZOと呼ばれるメモリ効率の高い零次勾配最適化手法は、従来のZO-SGD手法を改変して開発され、損失値の差分のみを使用して勾配を推定し、推論と同じメモリフットプリントで動作します。MeZOでは、ZO手法が2つの順方向パスのみを使用して勾配を推定できるため、メモリ効率が高いとされています。 MeZOアルゴリズムは、数十億のパラメータを持つ大規模な言語モデルの最適化に特に設計されています。チームが挙げた主な貢献は次のとおりです。 MeZOは、ZO-SGD手法といくつかの変種を修正して、任意のサイズのモデルでインプレースで実行し、ほとんどメモリのオーバーヘッドを発生させずに開発されました。 MeZOは、PEFTやLoRA、接頭辞調整などの包括的なパラメータ調整と互換性があります。 MeZOは、同じメモリ量を使用しながら、精度やF1スコアなどの微分できない目標を改善することができます。 適切な事前学習により、MeZOのステップごとの最適化率とグローバル収束率は、大数のパラメータによるというよりも、特定の条件数であるランドスケープの効果的なローカルランクに依存することが保証されます。これは、収束率がパラメータの数に応じて遅くなるという以前のZOの下限とは対照的です。 実験では、マスクされたLMや自己回帰LMなどのさまざまなモデルタイプでのテスト、および分類、多肢選択、生成などの下流タスクで、モデルは350Mから66Bまでスケーリングされました。 MeZOは、zero-shot、ICL、および線形プロービングに対して実験で優れたパフォーマンスを発揮し、OPT-13Bにおいては、RoBERTa-largeや通常の微調整よりも約12倍少ないメモリを消費しながら、11つのテストのうち7つで微調整と同等かそれ以上のパフォーマンスを発揮します。 評価によれば、MeZOは単一のNvidia A100 80GB GPUを使用して30兆パラメータのモデルをトレーニングすることができましたが、同じメモリ制約内ではバックプロパゲーションは2.7兆パラメータのLMのみをトレーニングすることができます。結論として、MeZOはメモリ効率の高い零次勾配最適化手法であり、大規模な言語モデルを効果的に微調整することができます。

高度な言語モデルの世界における倫理とプライバシーの探求
はじめに 現代の急速に進化する技術的な景観において、大規模言語モデル(LLM)は、産業を再構築し、人間とコンピュータの相互作用を革新する変革的なイノベーションです。高度な言語モデルの驚異的な能力は、人間のようなテキストを理解し生成することで、深いポジティブな影響をもたらす可能性を秘めています。しかし、これらの強力なツールは複雑な倫理的な課題を浮き彫りにします。 この記事は、LLMの倫理的な次元に深く立ち入り、バイアスとプライバシーの問題という重要な問題に焦点を当てています。LLMは、比類のない創造力と効率性を提供しますが、無意識にバイアスを持続させ、個人のプライバシーを損なう可能性があります。私たちの共有の責任は、これらの懸念に積極的に取り組み、倫理的な考慮事項がLLMの設計と展開を促進し、それによって社会的な幸福を優先することです。これらの倫理的な考慮事項を緻密に組み込むことで、私たちはAIの可能性を活かしながら、私たちを定義する価値と権利を守ります。 学習目標 大規模言語モデル(LLM)とその産業や人間とコンピュータの相互作用に与える変革的な影響について、深い理解を開発する。 バイアスとプライバシーの懸念に関連する、LLMが抱える複雑な倫理的な課題を探求する。これらの考慮事項がAI技術の倫理的な開発を形作る方法を学ぶ。 Pythonと必須の自然言語処理ライブラリを使用して、倫理的に優れたLLMを作成するためのプロジェクト環境を確立する実践的なスキルを習得する。 LLMの出力に潜在的なバイアスを特定し修正する能力を向上させ、公平かつ包括的なAI生成コンテンツを確保する。 データのプライバシーを保護する重要性を理解し、LLMプロジェクト内での機密情報の責任ある取り扱いのための技術を習得し、説明責任と透明性の環境を育成する。 この記事は、データサイエンスブログマラソンの一環として公開されました。 言語モデルとは何ですか? 言語モデルは、人間のようなテキストを理解し生成するために設計された人工知能システムです。言語モデルは、広範なテキストデータからパターンや関係を学び、一貫した文や文脈に即した文章を生成することができます。言語モデルは、コンテンツの生成から翻訳、要約、会話の支援など、さまざまな分野で応用されています。 プロジェクト環境の設定 倫理的な大規模言語モデルの開発のためには、適切なプロジェクト環境の構築が重要です。このセクションでは、LLMプロジェクトの環境を構築するための基本的な手順を案内します。 必須のライブラリと依存関係のインストール 倫理的な大規模言語モデル(LLM)の開発には、最適な環境が不可欠です。このセグメントでは、Pythonの仮想環境を使用して、適切なLLMプロジェクトのセットアップ手順を案内します。 LLMの旅に乗り出す前に、必要なツールとライブラリが揃っていることを確認してください。このガイドでは、Pythonの仮想環境を介して重要なライブラリと依存関係のインストール手順を案内します。準備を入念に行って成功への道を切り開きます。 これらの手順は、効果的かつ倫理的な方法でLLMをプロジェクトで活用するための堅牢な基盤を築きます。 なぜ仮想環境が重要なのですか? 技術的な詳細に入る前に、仮想環境の目的を理解しましょう。それはプロジェクト用の砂場のようなものであり、プロジェクト固有のライブラリや依存関係をインストールする自己完結型のスペースを作成します。この隔離により、他のプロジェクトとの競合を防ぎ、LLMの開発におけるクリーンな作業スペースを確保します。 Hugging Face Transformersライブラリ:LLMプロジェクトの強化 Transformersライブラリは、事前学習済みの言語モデルやAI開発ツールのスイートにアクセスするためのゲートウェイです。これにより、LLMとの作業がシームレスで効率的になります。…

「AIとML開発言語としてのPythonの利点」
「AIやMLなどのツールを使用して、ウェブ開発会社が業界を征服するためにPythonがますます使用されている理由を発見してください」

「Amazon LexとAmazon Kendra、そして大規模な言語モデルを搭載したAWSソリューションのQnABotを使用して、セルフサービス型の質問応答を展開してください」
「Amazon Lexによるパワーを利用したAWSのQnABotソリューションは、オープンソースのマルチチャネル、マルチ言語の会話型チャットボットですQnABotを使用すると、自己サービスの会話型AIを迅速にコンタクトセンター、ウェブサイト、ソーシャルメディアチャネルに展開することができ、コストを削減し、ホールド時間を短縮し、顧客体験とブランドの評価を向上させることができますこの記事では、QnABotの新しい生成型AI機能を紹介し、これらの機能を使用するためのチュートリアルを作成、展開、カスタマイズする方法について説明しますまた、関連するユースケースについても議論します」

「リアルタイムデータのためのPythonでのChatGPT APIの使用方法」
「ChatGPTが未知のトピックに回答するようにしたいですか? ここでは、わずかなコード行でAIパワードのアプリを構築する方法について、ステップバイステップのチュートリアルをご紹介します」

AudioLDM 2, でも速くなりました ⚡️
AudioLDM 2は、Haohe Liuらによる「AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining」で提案されました。AudioLDM 2は、テキストプロンプトを入力として受け取り、対応するオーディオを予測します。リアルな音効、人の声、音楽を生成することができます。 生成されるオーディオは高品質ですが、元の実装での推論の実行は非常に遅いです。10秒のオーディオサンプルを生成するのに30秒以上かかります。これは、深いマルチステージのモデリングアプローチ、大きなチェックポイントサイズ、最適化されていないコードなど、複数の要素の組み合わせによるものです。 このブログ記事では、Hugging Faceの🧨 Diffusersライブラリを使用してAudioLDM 2を使用する方法を紹介し、半精度、フラッシュアテンション、コンパイルなどのコードの最適化、スケジューラの選択、ネガティブプロンプティングなどのモデルの最適化を探求します。その結果、推論時間を10倍以上短縮でき、出力オーディオの品質の低下は最小限です。ブログ記事には、コードはすべて含まれていますが、説明は少なめです。 最後まで読んでください。わずか1秒で10秒のオーディオサンプルを生成する方法がわかります! モデルの概要 Stable Diffusionに触発され、AudioLDM 2はテキストからオーディオへの潜在的な拡散モデル(LDM)であり、テキストの埋め込みから連続的なオーディオ表現を学習します。 全体の生成プロセスは以下のように要約されます: テキスト入力x\boldsymbol{x}xを与えると、2つのテキストエンコーダーモデルが使用され、テキストの埋め込みが計算されます:CLAPのテキストブランチとFlan-T5のテキストエンコーダー…

「ハイパーパラメータのチューニングに関する包括的なガイド:高度な手法の探索」
機械学習において、ハイパーパラメータの調整はモデルの性能を向上させるために不可欠ですさまざまな高度な調整手法について探求しましょう

MSSQL vs MySQL データベースのパワーハウスを比較する
イントロダクション データベース管理システムの賑やかな競技場には、2つの重量級のライバルが現れます。1つはエンタープライズレベルの優れた能力を持つ洗練されたMicrosoft SQL Server (MSSQL)で、もう1つはコミュニティ主導の柔軟性を備えた開放的なMySQLです。それでは、MSSQLとMySQLが提供する機能を比較し、どちらがより適しているか見てみましょう。 MSSQL vs MySQL – 概要 要素 Microsoft SQL Server (MSSQL) MySQL ライセンス プロプライエタリでさまざまなエディションとライセンス オープンソースでコミュニティおよびエンタープライズエディション パフォーマンス 大企業と複雑なクエリに最適化されています 小規模から中規模のアプリケーションに適しています スケーラビリティ 堅牢なスケーラビリティオプションとクラスタリングサポート…
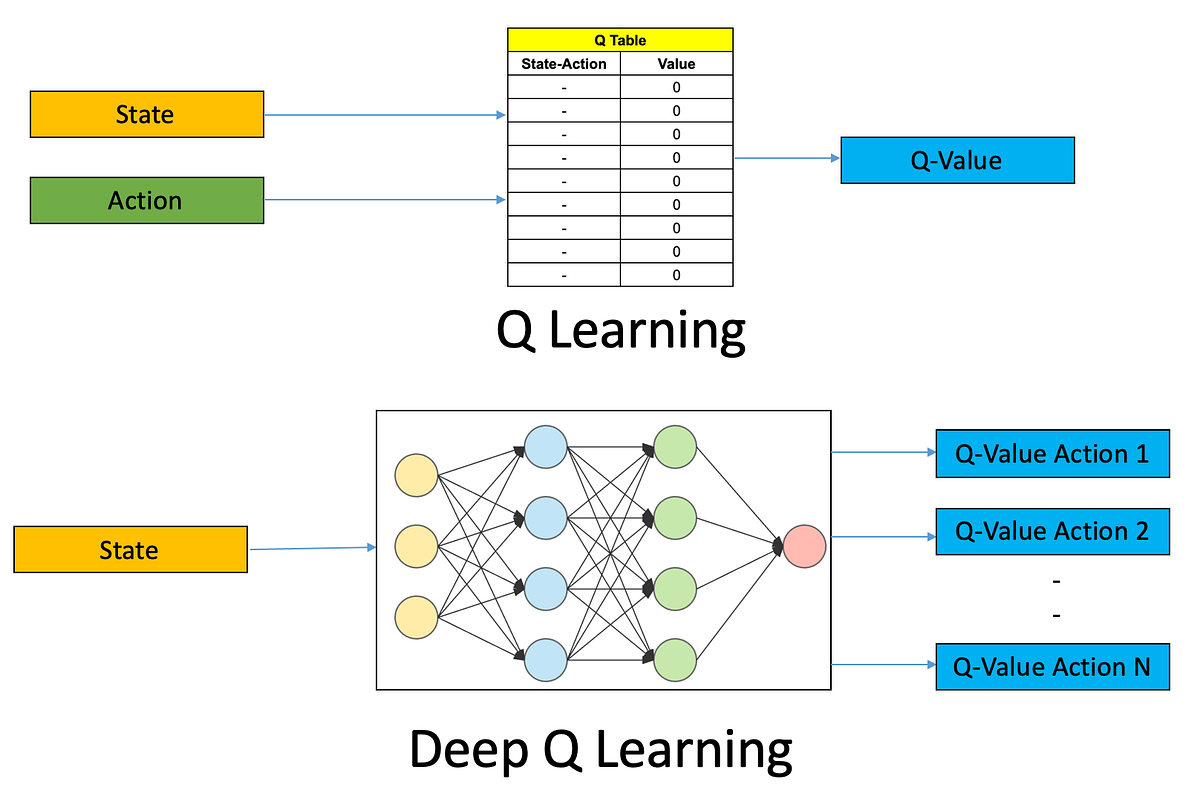
初めてのDeep Q学習ベースの強化学習エージェントをトレーニングする:ステップバイステップガイド
強化学習(RL)は、人工知能(AI)の魅力的な領域であり、機械が環境との相互作用を通じて学習し、意思決定を行うことができるようにしますRLエージェントを訓練する...

「価格最適化の技術を習得する — データサイエンスのソリューション」
価格設定はビジネスの世界で非常に重要な役割を果たします売上とマージンのバランスをとることは、どんなビジネスにおいても成功するために非常に重要ですデータサイエンスの方法でどのようにそれを行うことができるのでしょうか?
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.