Learn more about Search Results リポジトリ - Page 75

- You may be interested
- LLMOps – MLOpsの次のフロンティア
- query()メソッドを使用してPandasデータフ...
- 『Generative AIがサイバーセキュリティを...
- LangChain チートシート
- RAGを使用したLLMパワードアプリケーショ...
- Amazon SageMakerを使用してモデルの精度...
- ライトオンAIは、Falcon-40Bをベースにし...
- 「ステーブル拡散」は実際にどのように機...
- MEMSセンサーデータの探索的分析
- 「Falcon 180B あなたのコンピューターで...
- 「合成イメージングがAIトレーニングの効...
- 「フォトエディターは誰に必要ですか?! ...
- データサイエンスの職名の進む道:データ...
- 「データサイエンス、機械学習、コンピュ...
- 「スノーフレーク vs データブリックス:...
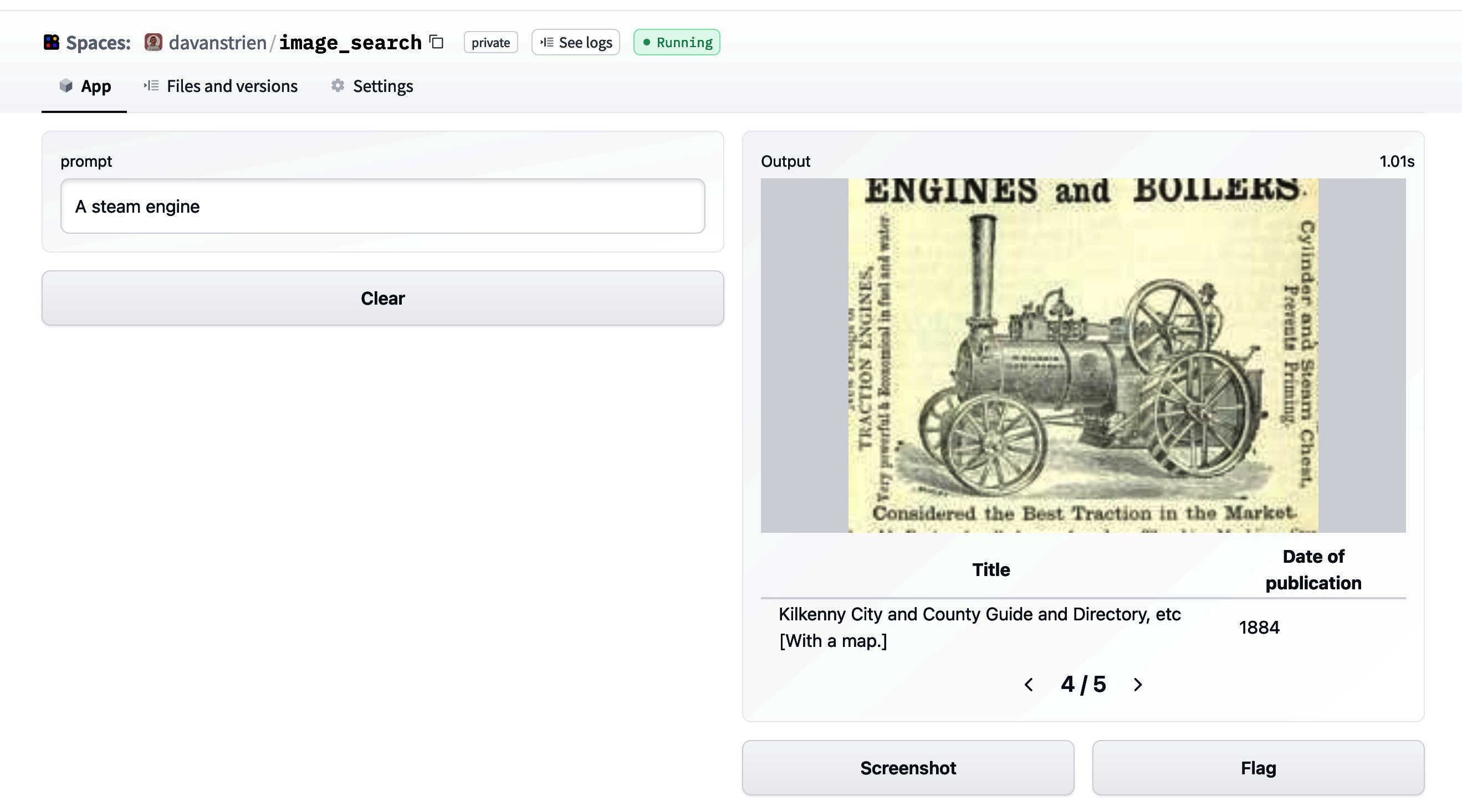
🤗データセットを使った画像検索
🤗 datasetsは、データセットに簡単にアクセスして共有することができるライブラリです。また、メモリに収まらないデータを効率的に処理することも容易にします。 datasetsが最初にリリースされた当初は、主にテキストデータと関連していました。しかし、最近では、datasetsは音声や画像に対するサポートを増やしています。特に、画像のためのdatasetsの機能タイプが追加されました。以前のブログ投稿では、datasetsと🤗 transformersを組み合わせて画像分類モデルのトレーニング方法を紹介しました。このブログ投稿では、datasetsと他のいくつかのライブラリを組み合わせて画像検索アプリケーションを作成する方法を見ていきます。 まず、datasetsをインストールします。画像を扱うために、pillowもインストールします。さらに、sentence_transformersとfaissも必要です。これらについては後ほど詳しく説明します。また、richもインストールします。ここでは簡単に使用するだけですが、非常に便利なパッケージなので、ぜひ詳しく探索してみてください! !pip install datasets pillow rich faiss-gpu sentence_transformers まずは、画像の特徴を見てみましょう。素晴らしいライブラリであるrichを使用して、Pythonオブジェクト(関数、クラスなど)を調べることができます。 from rich import inspect import datasets inspect(datasets.Image, help=True) ╭───────────────────────── <class 'datasets.features.image.Image'>…

Hugging Face TransformersとAWS Inferentiaを使用して、BERT推論を高速化する
ノートブック:sagemaker/18_inferentia_inference BERTとTransformersの採用はますます広がっています。Transformerベースのモデルは、自然言語処理だけでなく、コンピュータビジョン、音声、時系列でも最先端のパフォーマンスを達成しています。💬 🖼 🎤 ⏳ 企業は、大規模なワークロードのためにトランスフォーマーモデルを使用するため、実験および研究フェーズから本番フェーズにゆっくりと移行しています。ただし、デフォルトでは、BERTとその仲間は、従来の機械学習アルゴリズムと比較して、比較的遅く、大きく、複雑なモデルです。TransformersとBERTの高速化は、将来的に解決すべき興味深い課題となるでしょう。 AWSはこの課題を解決するために、最適化された推論ワークロード向けに設計されたカスタムマシンラーニングチップであるAWS Inferentiaを開発しました。AWSは、AWS Inferentiaが「現行世代のGPUベースのAmazon EC2インスタンスと比較して、推論ごとのコストを最大80%低減し、スループットを最大2.3倍高める」と述べています。 AWS Inferentiaインスタンスの真の価値は、各デバイスに搭載された複数のNeuronコアを通じて実現されます。Neuronコアは、AWS Inferentia内部のカスタムアクセラレータです。各Inferentiaチップには4つのNeuronコアが搭載されています。これにより、高スループットのために各コアに1つのモデルをロードするか、低レイテンシのためにすべてのコアに1つのモデルをロードすることができます。 チュートリアル このエンドツーエンドのチュートリアルでは、Hugging Face Transformers、Amazon SageMaker、およびAWS Inferentiaを使用して、テキスト分類のBERT推論を高速化する方法を学びます。 ノートブックはこちらでご覧いただけます:sagemaker/18_inferentia_inference 以下の内容を学びます: 1. Hugging Face TransformerをAWS Neuronに変換する 2.…
~自分自身を~ 繰り返さない
🤗 Transformersのデザイン哲学 「Don’t repeat yourself(同じことを繰り返さない)」、またはDRY(Don’t Repeat Yourself)は、ソフトウェア開発のよく知られた原則です。この原則は、「The pragmatic programmer」というコードデザインに関する最も読まれた本の1つから生まれました。この原則のシンプルなメッセージは明らかな意味を持っています。既に他の場所で存在するロジックを再書きする必要はありません。これにより、コードは同期され、メンテナンスが容易になり、より堅牢になります。この論理パターンへの変更は、依存関係のすべてに一様に影響を与えます。 Hugging FaceのTransformersライブラリの設計は、DRY原則とはまったく逆のものに見えるかもしれません。注意機構のコードは、異なるモデルファイルに50回以上もコピーされています。時にはBERTモデル全体のコードが他のモデルファイルにコピーされています。既存のモデルとほぼ同じ新しいモデルの貢献を強制的に行うことがよくありますが、それにはわずかな論理的な調整以外にも、すべての既存のコードをコピーする必要があります。なぜこれをやるのでしょうか?私たちは単に怠惰であるか、あるいは中心化された場所にすべての論理的な要素を集めることに圧倒されているのでしょうか? いいえ、私たちは怠惰ではありません。TransformersライブラリにDRYデザイン原則を適用しないというのは、非常に意識的な決定です。その代わりに、私たちは「シングルモデルファイル」ポリシーと呼ぶ別のデザイン原則を採用することにしました。シングルモデルファイルポリシーは、モデルの順方向パスに必要なすべてのコードが1つのファイル、つまりモデルファイルに含まれているというものです。推論でBERTがどのように機能するかを理解するためには、BERTのmodeling_bert.pyファイルを見ればよいだけです。異なるモデルの同一のサブコンポーネントを新しい中央集権化された場所に抽象化しようとする試みを通常は拒否します。すべての可能な注意メカニズムが含まれたattention_layer.pyを持つことはしたくありません。再び、なぜこれをやるのでしょうか? 短く言えば、その理由は次のとおりです: 1. Transformersはオープンソースコミュニティによって作られました。 2. 私たちの製品はモデルであり、顧客はモデルコードを読んだり調整したりするユーザーです。 3. 機械学習の世界は非常に速く進化しています。 4. 機械学習モデルは静的です。 1. オープンソースコミュニティによって作られました Transformersは、外部の貢献を積極的に促進するために作られています。貢献は通常、バグ修正または新しいモデルの貢献です。モデルファイルの1つでバグが見つかった場合、見つけた人が修正するのができるだけ簡単にすることを望んでいます。他のモデルの100のエラーを引き起こすことを見るのは、非常にやる気を削ぐことです。…

機械学習でパワーアップした顧客サービス
このブログ投稿では、実際の顧客サービスのユースケースをシミュレートし、Hugging Faceエコシステムの機械学習ツールを使用してそれに対処します。 強くお勧めするのは、このノートブックをテンプレート/例として使用して、あなた自身の実世界のユースケースを解決することです。 タスク、データセット、モデルの定義 実際のコーディングに取り掛かる前に、自動化または一部自動化したいユースケースの明確な定義を持つことが重要です。ユースケースの明確な定義は、最適なタスク、使用するデータセット、および適用するモデルを特定するのに役立ちます。 NLPタスクの定義 では、自然言語処理モデルを使用して解決したい仮想的な問題について考えてみましょう。私たちは製品を販売しており、顧客サポートチームはフィードバック、クレーム、質問を含む数千のメッセージを受け取っています。理想的には、これらのメッセージにすべて返答する必要があります。 すぐに明らかになるのは、顧客サポートがすべてのメッセージに返信することは不可能であるということです。したがって、私たちは最も不満な顧客にのみ返信し、これらのメッセージに100%回答することを決定します。それらは中立的なメッセージや肯定的なメッセージと比べて最も緊急性があると考えられるためです。 非常に不満な顧客のメッセージが全メッセージの一部であると仮定し、不満なメッセージを自動的にフィルタリングできるとすると、顧客サポートはこの目標を達成できるはずです。 不満なメッセージを自動的にフィルタリングするために、自然言語処理技術を適用する予定です。 最初のステップは、私たちのユースケース(不満なメッセージのフィルタリング)を機械学習タスクにマッピングすることです。 Hugging Face Hubのタスクページは、与えられたシナリオに最も適したタスクを確認するための素晴らしい場所です。各タスクには詳細な説明と潜在的な使用例があります。 最も不満な顧客のメッセージを見つけるタスクは、テキスト分類のタスクとしてモデル化できます。メッセージを次の5つのカテゴリのいずれかに分類します:非常に不満、不満、中立、満足、または非常に満足。 適切なデータセットの見つけ方 タスクを決定したら、次にモデルをトレーニングするためのデータを見つける必要があります。これはユースケースのパフォーマンスにとって通常はモデルアーキテクチャを選ぶよりも重要です。モデルはトレーニングされたデータの質によってのみ優れた性能を発揮します。したがって、データセットの選択と作成には非常に注意が必要です。 不満なメッセージのフィルタリングという仮想的なユースケースを考えると、使用可能なデータセットを見てみましょう。 実際のユースケースでは、おそらくNLPシステムが処理する実際のデータを最もよく表す内部データがあるでしょう。したがって、そのような内部データをNLPシステムのトレーニングに使用するべきです。ただし、モデルの汎用性を向上させるために公開されているデータも含めることは役立ちます。 Hugging Face Hubの利用可能なデータセットをすべて見てみましょう。左側にはタスクカテゴリやより具体的なタスクに基づいてデータセットをフィルタリングできます。私たちのユースケースはテキスト分類 -> 感情分析に対応しているので、これらのフィルタを選択しましょう。このノートブックの執筆時点では、約80のデータセットが残ります。データセットを選ぶ際には、次の2つの側面を評価する必要があります:…
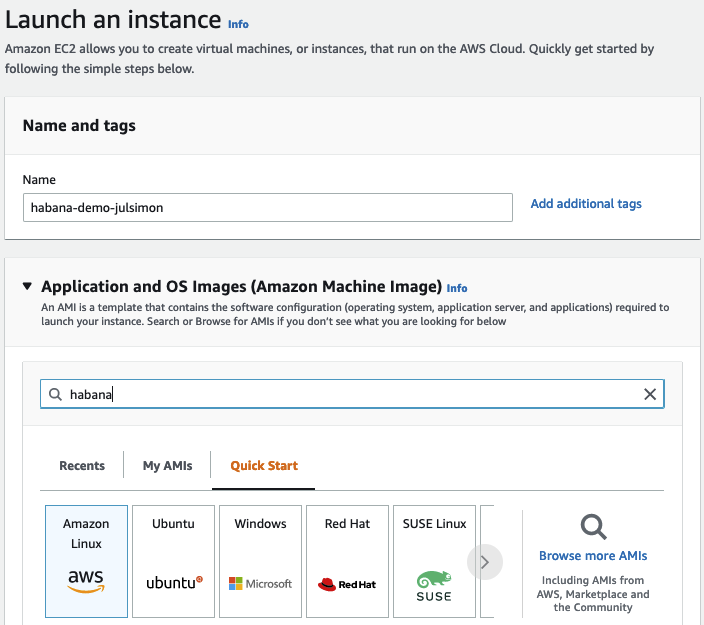
Habana GaudiでのTransformersの始め方
数週間前に、Habana LabsとHugging Faceが協力してTransformerモデルのトレーニングを加速することを発表できたことを喜んでお知らせいたします。 Habana Gaudiアクセラレータは、最新のGPUベースのAmazon EC2インスタンスと比較して、機械学習モデルのトレーニングにおいて最大40%の価格パフォーマンス向上を提供します。私たちはこの価格パフォーマンスの利点をTransformersにもたらすことに非常に興奮しています🚀 この実践的な投稿では、Amazon Web ServicesでHabana Gaudiインスタンスを素早くセットアップし、テキスト分類用にBERTモデルを微調整する方法を紹介します。通常どおり、コードはすべて提供されているため、プロジェクトで再利用できます。 さあ、始めましょう! AWSでHabana Gaudiインスタンスをセットアップする Habana Gaudiアクセラレータを使用する最も簡単な方法は、Amazon EC2 DL1インスタンスを起動することです。これらのインスタンスには、Habana SynapseAI® SDKがプリインストールされたHabana Deep Learning Amazon Machine Image(AMI)が搭載されています。また、GaudiアクセラレーションされたDockerコンテナを実行するために必要なツールも含まれています。他のAMIやコンテナを使用したい場合は、Habanaのドキュメントに手順が記載されています。…

KiliとHuggingFace AutoTrainを使用した意見分類
イントロダクション ユーザーのニーズを理解することは、ユーザーに関連するビジネスにおいて重要です。しかし、それには多くの労力と分析が必要であり、非常に高価です。ならば、Machine Learningを活用しませんか?Auto MLを使用することでコーディングを大幅に削減できます。 この記事では、HuggingFace AutoTrainとKiliを活用して、テキスト分類のためのアクティブラーニングパイプラインを構築します。Kiliは、品質の高いトレーニングデータ作成を通じて、データ中心のアプローチを強力にサポートするプラットフォームです。協力的なデータ注釈ツールとAPIを提供し、信頼性のあるデータセット構築とモデルトレーニングの素早い反復を可能にします。アクティブラーニングとは、データセットにラベル付けされたデータを追加し、モデルを反復的に再トレーニングするプロセスです。そのため、終わりのない作業であり、人間がデータにラベルを付ける必要があります。 この記事の具体的なユースケースとして、Google PlayストアのVoAGIのユーザーレビューを使用してパイプラインを構築します。その後、構築したパイプラインでレビューをカテゴリ分類します。最後に、分類されたレビューに感情分析を適用します。その結果を分析することで、ユーザーのニーズと満足度を理解することが容易になります。 HuggingFaceを使用したAutoTrain 自動化されたMachine Learningは、Machine Learningパイプラインの自動化を指す用語です。データクリーニング、モデル選択、ハイパーパラメータの最適化も含まれます。🤗 transformersを使用して自動的にハイパーパラメータの検索を行うことができます。ハイパーパラメータの最適化は困難で時間のかかるプロセスです。 transformersや他の強力なAPIを使用してパイプラインを自分自身で構築することもできますが、AutoTrainを完全に自動化することも可能です。AutoTrainは、transformers、datasets、inference-apiなどの多くの強力なAPIを基に構築されています。 データのクリーニング、モデルの選択、ハイパーパラメータの最適化のステップは、すべてAutoTrainで完全に自動化されています。このフレームワークをフルに活用することで、特定のタスクに対してプロダクションレディのSOTAトランスフォーマーモデルを構築することができます。現在、AutoTrainはバイナリとマルチラベルのテキスト分類、トークン分類、抽出型質問応答、テキスト要約、テキストスコアリングをサポートしています。また、英語、ドイツ語、フランス語、スペイン語、フィンランド語、スウェーデン語、ヒンディー語、オランダ語など、多くの言語もサポートしています。AutoTrainでサポートされていない言語の場合、カスタムモデルとカスタムトークナイザを使用することも可能です。 Kili Kiliは、データ中心のビジネス向けのエンドツーエンドのAIトレーニングプラットフォームです。Kiliは、最適化されたラベリング機能と品質管理ツールを提供し、データを管理するための便利な手段を提供します。画像、ビデオ、テキスト、PDF、音声データを素早く注釈付けできます。GraphQLとPythonの強力なAPIも備えており、データ管理を容易にします。 オンラインまたはオンプレミスで利用可能であり、コンピュータビジョンやNLP、OCRにおいてモダンなMachine Learning技術を実現することができます。テキスト分類、固有表現認識(NER)、関係抽出などのNLP / OCRタスクをサポートしています。また、オブジェクト検出、画像転写、ビデオ分類、セマンティックセグメンテーションなどのコンピュータビジョンタスクもサポートしています。 Kiliは商用ツールですが、Kiliのツールを試すために無料のデベロッパーアカウントを作成することもできます。料金については、価格ページから詳細を確認できます。 プロジェクト モバイルアプリケーションについての洞察を得るために、レビューの分類と感情分析の例を取り上げます。…

Hugging Faceハブへ、fastaiさんを歓迎します
ニューラルネットを再びクールじゃなくする…そして共有する Deep Learningのアクセシビリティを高めるために、fast.aiエコシステムは他に類を見ない成果を上げてきました。Hugging Faceの使命は、優れた機械学習を民主化することです。機械学習へのアクセスの排他性、事前学習済みモデルを過去のものとし、この素晴らしい領域をさらに推進しましょう。 fastaiは、PyTorchとPythonを活用して、テキスト、画像、表形式のデータに対して最新の出力を備えた高速かつ正確なニューラルネットワークをトレーニングするためのハイレベルなコンポーネントを提供するオープンソースのDeep Learningライブラリです。ただし、fast.aiは単なるライブラリ以上のものです。それはオープンソースの貢献者とニューラルネットワークの学習に取り組む人々の繁栄するエコシステムに成長しました。いくつかの例として、彼らの書籍やコースをチェックしてみてください。fast.aiのDiscordやフォーラムに参加してください。彼らのコミュニティに参加することで、確実に学びが得られます! これら全ての理由から(この記事の執筆者はfast.aiのコースのおかげで自分の旅をスタートさせました)、私たちは誇りを持ってお知らせします。fastaiのプラクティショナーは、Pythonの一行でモデルをHugging Face Hubに共有・アップロードすることができるようになりました。 👉 この記事では、fastaiとHubの統合について紹介します。さらに、このチュートリアルをColabノートブックとして開くこともできます。 fast.aiコミュニティ、特にJeremy Howard、Wayde Gilliam、Zach Muellerにフィードバックをいただいたことに感謝します 🤗。このブログは、fastaiドキュメントのHugging Face Hubセクションに強く触発されています。 Hubに共有する理由 Hubは、モデル、データセット、MLデモを共有・探索できる中央プラットフォームです。最も広範なオープンソースのモデル、データセット、デモのコレクションを提供しています。 Hubで共有することで、あなたのfastaiモデルの影響力を広げ、他の人がダウンロードして探索できるようにします。また、fastaiモデルを転移学習に利用することもできます。他の誰かのモデルをタスクの基礎として読み込むことができます。 誰でも、hf.co/modelsのウェブページでfastaiライブラリをフィルタリングすることで、Hubの全てのfastaiモデルにアクセスできます。以下の画像を参照してください。 広範なコミュニティへの無料モデルホスティングと露出に加えて、Hubにはgitに基づいたバージョン管理(大容量ファイルの場合はgit-lfs)や、発見性と再現性のためのモデルカードも組み込まれています。Hubのナビゲーションについての詳細は、この紹介を参照してください。 Hugging…
プルリクエストとディスカッションの紹介 🥳
私たちは、Hugging Face Hubでの最新の共同作業機能、プルリクエストとディスカッションのリリースを大いに喜んでお知らせします! プルリクエストとディスカッションは、モデル、データセット、およびスペースのすべてのリポジトリタイプのコミュニティタブの下で今日から利用可能です。コミュニティのメンバーは、ディスカッションとプルリクエストを作成し、参加することができます。これにより、チーム内だけでなく、コミュニティの他のすべての人とも協力が可能になります! これは、Hubで行われた最大のアップデートであり、コミュニティメンバーがそれを使って協力を始めるのを楽しみにしています 🤩。 新しい「コミュニティ」タブは、これまでの倫理的な機械学習の提案とも一致しています。フィードバックとイテレーションは、倫理的な機械学習ソフトウェアの開発において中心的な役割を果たします。私たちは、それをコミュニティのツールセットに持っていることで、ML、コラボレーション、進歩に新しい種類のポジティブなパターンが生まれると本当に信じています。 ディスカッションとプルリクエストの例としては、次のようなものがあります: 倫理的なバイアスの開示を改善するためのモデルカードへの提案を行う。 特定のスペースデモの懸念を引き起こす生成物をユーザーがフラグする。 モデルとデータセットの作成者がコミュニティメンバーと直接ディスカッションできる場を提供する。 他の人がリポジトリを改善できるようにする!例えば、ユーザーはTensorFlowのウェイトを提供したいかもしれません! ディスカッション ディスカッションでは、コミュニティメンバーが質問をしたり回答したり、アイデアや提案をリポジトリの所有者やコミュニティと直接共有したりすることができます。誰でもリポジトリのコミュニティタブでディスカッションを作成したり参加したりできます。 プルリクエスト プルリクエストでは、コミュニティメンバーがウェブサイトから直接プルリクエストを開いたりコメントしたりマージしたり閉じたりすることができます。プルリクエストを開く最も簡単な方法は、「ファイルとバージョン」タブの「共同作業」ボタンを使用することです。これにより、単一のファイルの貢献が非常に簡単に行えます。 裏側では、プルリクエストではフォークやブランチを使用せず、ソースリポジトリに直接保存されるカスタムの「ブランチ」であるrefsを使用しています。このアプローチにより、モデル/データセットの新バージョンごとにフォークを作成する必要がなくなります。 他のGitホストとの違いは何ですか 大まかに言うと、私たちは他のGitホスト(GitHubなど)のPRやIssueのよりシンプルなバージョンを構築することを目指しています: フォークは関与しません:投稿者はソースリポジトリに直接特別なrefブランチにプッシュします IssueとPRの明確な区別はありません:本質的に同じなので、同じリストに表示されます MLに最適化されています(つまり、モデル/データセット/スペースのリポジトリ)で、任意のリポジトリではありません 次は何ですか もちろん、これは始まりに過ぎません。私たちはコミュニティのフィードバックを聞きながら、将来的に新機能を追加し、コミュニティタブを改善していく予定です。フィードバックがあれば、こちらのディスカッションに参加することができます。今日が初めてディスカッションに参加し、プルリクエストを開く最高のタイミングです!…

GraphcoreとHugging Faceが、IPU対応の新しいトランスフォーマーのラインアップを発表
GraphcoreとHugging Faceは、Hugging Face Optimumにおいて利用可能な機械学習のモダリティとタスクの範囲を大幅に拡張しました。Hugging Face Optimumは、Transformersのパフォーマンス最適化のためのオープンソースライブラリです。開発者は、GraphcoreのIPUで最高のパフォーマンスを提供するように最適化された幅広いHugging Face Transformerモデルに簡単にアクセスできるようになりました。 Optimum Graphcoreの発売後間もなく提供されたBERT Transformerモデルを含む、開発者は現在、自然言語処理(NLP)、音声、コンピュータビジョンをカバーする10のモデルにアクセスできます。これらのモデルには、IPUの設定ファイルと、事前学習および微調整済みのモデルの重みを使用するための準備が整っています。 新しいOptimumモデル コンピュータビジョン ViT(Vision Transformer)は、主要なコンポーネントとしてTransformerメカニズムを使用した画像認識の画期的な手法です。画像がViTに入力されると、言語システムで単語が処理されるのと同様に、画像は小さなパッチに分割されます。各パッチはTransformer(埋め込み)によってエンコードされ、個別に処理することができます。 NLP GPT-2(Generative Pre-trained Transformer 2)は、非常に大規模な英語のコーパスで自己教師付きの形式で事前学習されたテキスト生成Transformerモデルです。これは、テキストのラベリングを行わずに、公開されているデータを多く使用することができるため、自動的なプロセスでテキストから入力とラベルを生成することによって事前学習されました。より具体的には、文の次の単語を推測して文を生成するようにトレーニングされています。 RoBERTa(Robustly optimized BERT approach)は、自己教師付きの形式で大規模な英語のコーパスで事前学習されたTransformerモデルです(GPT-2と同様)。より具体的には、RoBERTaはマスクされた言語モデリング(MLM)の目的で事前学習されています。文を取り、モデルは入力の15%の単語をランダムにマスクし、全体のマスクされた文をモデルを通して実行し、マスクされた単語を予測する必要があります。RoBERTaはマスクされた言語モデリングに使用することができますが、主に下流タスクで微調整することを意図しています。…

埋め込みを使った始め方
ノートブックコンパニオンを使用したこのチュートリアルをチェックしてください: 埋め込みの理解 埋め込みは、テキスト、ドキュメント、画像、音声などの情報の数値表現です。この表現は、埋め込まれているものの意味を捉え、多くの産業アプリケーションに対して堅牢です。 テキスト「投票の主な利点は何ですか?」に対する埋め込みは、たとえば、384個の数値のリスト(例:[0.84、0.42、…、0.02])でベクトル空間で表現されることがあります。このリストは意味を捉えているため、異なる埋め込み間の距離を計算して、2つの文の意味がどれだけ一致するかを判断するなど、興味深いことができます。 埋め込みはテキストに限定されません!画像の埋め込み(たとえば、384個の数値のリスト)を作成し、テキストの埋め込みと比較して文が画像を説明しているかどうかを判断することもできます。この概念は、画像検索、分類、説明などの強力なシステムに適用されています! 埋め込みはどのように生成されるのでしょうか?オープンソースのライブラリであるSentence Transformersを使用すると、画像やテキストから最先端の埋め込みを無料で作成することができます。このブログでは、このライブラリを使用した例を紹介しています。 埋め込みの用途は何ですか? 「[…] このMLマルチツール(埋め込み)を理解すると、検索エンジンからレコメンデーションシステム、チャットボットなど、さまざまなものを構築できます。データサイエンティストやMLの専門家である必要はありませんし、大規模なラベル付けされたデータセットも必要ありません。」- デール・マルコウィッツ、Google Cloud。 情報(文、ドキュメント、画像)が埋め込まれると、創造性が発揮されます。いくつかの興味深い産業アプリケーションでは、埋め込みが使用されます。たとえば、Google検索ではテキストとテキスト、テキストと画像をマッチングさせるために埋め込みを使用しています。Snapchatでは、「ユーザーに適切な広告を適切なタイミングで提供する」ために埋め込みを使用しています。Meta(Facebook)では、ソーシャルサーチに埋め込みを使用しています。 埋め込みから知識を得る前に、これらの企業は情報を埋め込む必要がありました。埋め込まれたデータセットを使用することで、アルゴリズムは素早く検索、ソート、グループ化などを行うことができます。ただし、これは費用がかかり、技術的にも複雑な場合があります。この投稿では、シンプルなオープンソースのツールを使用して、データセットを埋め込み、分析する方法を紹介します。 埋め込みの始め方 小規模なよく寄せられる質問(FAQ)エンジンを作成します。ユーザーからのクエリを受け取り、最も類似したFAQを特定します。米国社会保障メディケアFAQを使用します。 しかし、まず、データセットを埋め込む必要があります(他のテキストでは、エンコードと埋め込みの用語を交換可能に使用します)。Hugging FaceのInference APIを使用すると、簡単なPOSTコールを使用してデータセットを埋め込むことができます。 質問の意味を埋め込みが捉えるため、異なる埋め込みを比較してどれだけ異なるか、または類似しているかを確認することができます。これにより、クエリに最も類似した埋め込みを取得し、最も類似したFAQを見つけることができます。このメカニズムの詳細な説明については、セマンティックサーチのチュートリアルをご覧ください。 要するに、以下の手順を実行します: Inference APIを使用してメディケアのFAQを埋め込む。 埋め込まれた質問を無料ホスティングするためにHubにアップロードする。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.