Learn more about Search Results A - Page 759

- You may be interested
- 「ScyllaDB NoSQLを使用したAI/MLフィーチ...
- 「自然再造プロジェクトのグローバルな潜...
- 安定性AIの新しいアップカミングツールは...
- 腫瘍の起源の解読:MITとDana-Farber研究...
- UnityゲームをSpaceにホストする方法
- 「クラスの不均衡とオーバーサンプリング...
- 「AI生成応答を検出する2つの簡単な方法」
- ビジネスにおけるAIパワードのテキストメ...
- 「Kerasを使用したニューラルネットワーク...
- オープンAIによるこの動きは、AGIへの道を...
- 「MLOPsを使用した不正取引検出の実装」
- 「これらのツールは、AIから私たちの写真...
- 『George R.R.マーティン氏と他の作家がOp...
- 直感的にR2と調整済みR2のメトリックを探...
- ニューヨーク市がAIに照準を合わせる
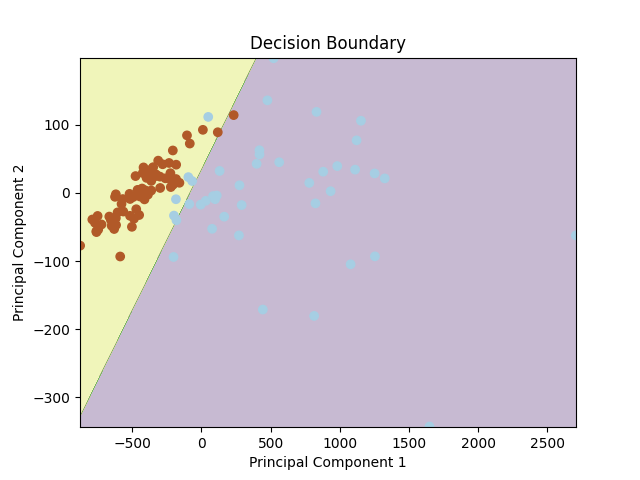
「ロジスティック回帰:直感と実装」
ロジスティック回帰は、2つの異なるデータ属性の間の決定境界を学習できる基本的な二値分類アルゴリズムですこの記事では、理論的な理解を深めるために、...
「圧縮が必要ですか?」
最近公開されたタイトル「低リソース」テキスト分類:圧縮器を使用したパラメータフリーの分類手法[1]という論文は、最近、かなりの注目を集めています...
「Python Pre-Commitフックを使用して、コード品質を自動化する方法」
もしPythonの開発者であれば、チームメンバーが異なるコーディングスタイルを持っており、コードベースが一貫性を欠いている状況に頻繁に遭遇するかもしれませんその結果、バグが発生することがあります...

「土木工学におけるデータサイエンスの力を探る」
イントロダクション 近年、データサイエンスの技術の統合により、土木工学は驚異的な変革を遂げてきました。データサイエンスは、インフラプロジェクトの設計、計画、管理に対する土木工学のアプローチを革新する強力なツールとして浮上しました。この記事では、データサイエンスが土木工学に果たす重要な役割と、この業界の未来を形作る影響について探っています。 データサイエンスの土木工学への役割 データ分析による意思決定の改善 データサイエンスは、膨大なデータを分析することで、土木工学者が情報に基づいた意思決定を行う力を与えています。歴史的なプロジェクトデータ、センサーの読み取り、地質調査などの関連情報を活用して、価値ある知見を抽出します。これらのデータに基づく意思決定は、最適化された設計、より良いプロジェクト計画、改善されたプロジェクト成果につながります。 インフラストラクチャの設計と計画の向上 データサイエンスの技術をインフラストラクチャの設計と計画に取り入れることは、革命的な効果があります。エンジニアは、さまざまなシナリオをシミュレーションし、その影響を評価し、建設が始まる前に潜在的な課題を特定することができます。この先見性により、エンジニアは堅牢で効率的なインフラストラクチャの設計を作り出すことができます。 インフラストラクチャの持続可能性のための予測保守 データサイエンスが土木工学にもたらす最も重要な利点の一つは、予測保守です。エンジニアは、IoTセンサーやデータ分析を通じてインフラストラクチャの健康状態を継続的に監視することで、保守要件を正確に予測することができます。この積極的なアプローチにより、インフラストラクチャの寿命を延ばすだけでなく、利用者の安全性も確保されます。 リスク評価と緩和 データサイエンスは、土木工学プロジェクトにおけるリスク評価を支援し、歴史データを分析し、潜在的なリスク要因を特定することで、エンジニアはデータに基づく知見に基づいたリスク緩和戦略を立案することができます。これにより、プロジェクトの遅延や失敗の可能性を減らすことができます。 コスト最適化とリソース管理 データサイエンスは、土木工学プロジェクトにおいて効率的なリソース管理とコスト最適化を実現します。材料コスト、労働力、装置の利用に関連するデータを分析することで、エンジニアはオペレーションを合理化し、ロスを減らすことができます。これにより、著しいコスト削減が実現されます。 土木工学におけるデータサイエンスの技術 回帰分析 回帰分析は、材料特性や構造の挙動などの変数間の関係を確立するために土木工学で使用されます。データに回帰モデルを適合させることで、エンジニアは結果を予測し、パフォーマンスに影響を与える重要な要因を特定することができます。これにより、設計と解析においてより情報に基づいた意思決定が可能となります。 ニューラルネットワーク ニューラルネットワークは、土木工学の問題における複雑な非線形関係をモデル化するために使用されます。交通流予測、構造健全性監視、地盤解析などの領域で、従来の方法では複雑なパターンや相関を捉えることができない場合に使用されます。 地理情報システム(GIS) GISは、空間データをさまざまな土木工学のデータセットと統合し、地理空間情報の可視化と分析を可能にします。土木工学者は、サイト選定、都市計画、インフラストラクチャ管理にGISを活用し、効率的なリソース配分と情報に基づいた意思決定を行います。 有限要素解析(FEA) 有限要素解析は、土木工学において複雑な構造やシステムを分析するための数値的な手法です。エンジニアは構造物をより小さな要素に分割することで、実世界の挙動や応力分布をシミュレーションすることができます。これにより、設計の最適化や構造の整合性評価に役立ちます。 時系列分析 時系列分析は、交通流パターンや環境要因などの時間とともに収集されたデータを土木工学に適用するための手法です。エンジニアは、傾向、季節パターン、異常を特定するためにこの手法を使用し、インフラストラクチャプロジェクトの予測と計画をより良くサポートします。…

データスクレイピングが注目されています:言語モデルは皆のコンテンツをトレーニングすることで飛び越えているのでしょうか?
この記事の調査をまとめ、執筆を始めようとしたとき、OpenAIはそれにぴったりの発表を行いました彼らはChatGPTの「Browse with Bing」機能を一時的に無効にしているとのことです...

「プリズマーに会いましょう:専門家のアンサンブルを持つオープンソースのビジョン-言語モデル」
最近の多くのビジョン言語モデルは、非常に注目すべき多様な生成能力を示しています。しかし、通常、それらは膨大なモデルと膨大なデータセットのトレーニングを必要とします。研究者たちは、データとパラメータの効率的なビジョン言語モデルであるPrismerを紹介し、スケーラブルな代替手法としています。Prismerは、公開されている事前トレーニング済みのドメインエキスパートからほとんどのネットワークの重みを受け継ぎ、トレーニング中にそれらを凍結することで、わずかなコンポーネントのトレーニングのみを必要とします。 大規模な事前トレーニングモデルの汎化能力は、さまざまなタスクにおいて非常に優れています。しかし、これらの機能には高い価格が付いており、トレーニングデータと計算リソースが大量に必要です。数千億のトレーニング可能なパラメータを持つモデルは、言語領域では一般的であり、yottaFLOPスケールの計算予算が必要です。 ビジュアル言語学習に関連する問題は、より困難に解決することが求められます。この分野は言語処理のスーパーセットでありながら、ビジュアルおよびマルチモーダルな思考の専門知識も必要とします。Prismerは、予測されるマルチモーダル信号を使用したデータ効率の良いビジョン言語モデルであり、さまざまな事前トレーニング済みエキスパートを使用します。ビジュアルクエスチョンアンサリングや画像キャプションなど、ビジョン言語推論のタスクの例として扱うことができます。Prismerは、プリズムを例にして、一般的な推論タスクをいくつかのより小さな、より管理しやすいチャンクに分割します。 研究者たちは、視覚的に条件付けられた自己回帰テキスト生成モデルを開発しました。Prismerの最も重要な設計特徴の2つは、(i)ビジョンのみのモデルをWebスケールの知識のためのコアネットワークバックボーンとして使用し、(ii)モダリティに特化したビジョンエキスパートが、深度などの低レベルのビジョン信号からインスタンスやセマンティックラベルなどの高レベルのビジョン信号まで、対応するネットワークの出力から直接補助的な知識をエンコードすることです。研究者たちは、探索的なビジョン言語推論タスクにおいて、さまざまな事前トレーニング済みドメインエキスパートをより良く活用するために、視覚的に条件付けられた自己回帰テキスト生成モデルを開発しました。 Prismerは、公開されている画像/代替テキストデータの13Mの例でのみトレーニングされていますが、画像キャプション、画像分類、ビジュアルクエスチョンアンサリングなどのタスクにおいて、強力なマルチモーダル推論性能を示し、多くの最先端のビジョン言語モデルと競合しています。研究者たちは、Prismerの学習習慣を徹底的に調査し、いくつかの良い特徴を見つけました。 モデル設計: Prismerモデルは、エンコーダ-デコーダトランスフォーマーのバージョンで表示され、トレーニングプロセスを高速化するために、既にトレーニング済みの専門家の大きなプールを活用しています。このシステムは、ビジョンエンコーダと自己回帰言語デコーダで構成されています。ビジョンエンコーダは、RGBとマルチモーダルラベル(凍結された事前トレーニング済みのエキスパートから予測される深度、表面法線、セグメンテーションラベル)のシーケンスを入力として受け取り、RGBとマルチモーダルの特徴のシーケンスを出力します。このクロスアテンショントレーニングの結果、言語デコーダはテキストトークンの文字列を生成するように条件付けられます。 利点: Prismerモデルにはいくつかの利点がありますが、最も注目すべきは、トレーニング中に非常に効率的にデータを使用することです。Prismerは、Webスケールの知識を利用するために事前トレーニングされたビジョンのみと言語のみのバックボーンモデルの上に構築されており、他の最先端のビジョン言語モデルと同等の性能を得るために必要なGPU時間を大幅に削減します。これらの事前トレーニングされたパラメータを使用して、利用可能な大量のウェブスケールの知識を利用することができます。 研究者たちは、ビジョンエンコーダのためのマルチモーダル信号入力も開発しました。作成されたマルチモーダルの補助的な知識は、入力画像の意味と情報をより良く捉えることができます。Prismerのアーキテクチャは、わずかなトレーニング可能なパラメータでトレーニング済みエキスパートの使用を最大限に活用するように最適化されています。 研究者は、Prismerに2種類の事前トレーニング済みエキスパートを含めました: バックボーンの専門家 テキストと画像を意味のあるトークンのシーケンスに変換するための事前トレーニング済みモデルを、それぞれ「ビジョンのみ」と「言語のみ」と呼びます。 ディスコースモデルのモデレータ タスクをさまざまな方法でラベル付けするために使用されるデータに応じて、ディスコースモデルのモデレータはタスクにラベル付けを行います。 特性 知識豊富な人々が多ければ多いほど、結果は良くなります。Prismerのモダリティの専門家の数が増えるにつれて、パフォーマンスが向上します。 より熟練した専門家、より優れた結果 研究者は、予測される深度ラベルの一部を一様分布からランダムノイズで置き換えて、破損した深度エキスパートを作成し、エキスパートの品質がPrismerのパフォーマンスに与える影響を評価しました。 無益な意見に対する耐性 研究結果は、ノイズ予測エキスパートが組み込まれた場合でも、Prismerのパフォーマンスが安定していることをさらに示しています。 弊社のPaperとGithubをご覧ください。この研究における全てのクレジットは、このプロジェクトの研究者に帰属します。また、最新のAI研究ニュースや素晴らしいAIプロジェクトなどを共有している26k+人のML SubReddit、Discordチャンネル、メールニュースレターにもぜひご参加ください。 Tensorleapの説明可能性プラットフォームでディープラーニングの秘密を解き放つ…
生産性のパラノイアを打破する:Microsoft 365コパイロットには賛成ですか?
Microsoft 365 Copilotは30ドルで価格設定されていますこれは多くの企業にとって、Microsoftのサブスクリプションに対する現在の支出を倍増、あるいは3倍にする可能性があります(The Verge、2023年7月18日)あなたは…

「アニメート・ア・ストーリー:高品質で構造化されたキャラクター主導のビデオを合成する、検索補完型ビデオ生成によるストーリーテリング手法による出会い」
テキストから画像へのモデルは最近注目を集めています。生成型人工知能の導入により、GPTやDALL-Eなどのモデルはリリース以来、話題になっています。彼らの人気の上昇は、人間のようなコンテンツの生成が今や夢ではない理由です。テキストから画像だけでなく、テキストからビデオ(T2V)の生成も可能です。ライブアクションの撮影やコンピュータ生成のアニメーションの制作は、興味深いストーリーテリングビデオを作成するために通常必要な手順であり、困難で時間がかかります。 テキストからビデオの最新の進展は、テキストベースの説明から自動的にビデオを作成するという約束を示していますが、まだ特定の制約があります。ビジュアル化するためには、魅力的なストーリーを視覚化し、映画体験を提供するために重要なデザインやレイアウトに対する制御が不足しています。クローズアップ、ロングビュー、構図などの映画制作技術は、潜在的なメッセージを理解するために観客に重要です。現在のテキストからビデオの手法では、映画の基準に従った適切な動きやレイアウトを提供することが難しいです。 これらの制約に対処するために、研究チームは、リトリーバル強化型ビデオ生成と呼ばれるユニークなビデオ生成手法である「Animate-A-Story」を提案しました。この手法は、テキストプロンプトに基づいて外部データベースから映画を取得し、それらをT2V作成プロセスのガイド信号として使用することで、既存のビデオコンテンツの豊富さを活用しています。ユーザーは、取得したビデオを入力として使用して、ストーリーをアニメーション化する際に生成されたビデオのレイアウトと構成に対してより大きな制御を持つことができます。 このフレームワークは、2つのモジュールで構成されています。モーション構造検索モジュールと構造ガイド付きテキストからビデオ合成モジュールです。モーション構造検索モジュールは、クエリテキストで示されるシーンやモーションコンテキストに一致するビデオ候補を供給します。これには、商用のビデオ検索システムを使用してモーション構造としてビデオの深度が抽出されます。2番目のモジュールである構造ガイド付きテキストからビデオ合成モジュールは、テキストプロンプトとモーション構造を入力として使用して、ストーリーに従った映画を生成します。プロットやキャラクターのビデオ内での柔軟な制御を可能にするカスタマイズ可能なビデオ制作のためのモデルが作成されています。作成されたビデオは、構造的な指示と視覚的なガイドラインに従って、意図したストーリーテリング要素を守っています。 この手法は、映像の一貫性を保つことに重点を置いています。チームはまた、これを確実にするための成功したコンセプトパーソナライゼーション戦略も開発しました。テキストプロンプトを通じて、この手法では視聴者が好みのキャラクターのアイデンティティを選択できるようにし、ビデオ全体でキャラクターの外観の一貫性を保持します。評価のために、チームはこの手法を既存のベースラインと比較しました。その結果、この手法の優位性が明らかになり、高品質で一貫性のある視覚的に魅力的なストーリーテリングビデオを生成する能力が証明されました。 チームは以下の貢献をまとめています: 物語性のあるビデオ合成のためのリトリーバル強化型パラダイムを導入しました。これにより、様々な既存のビデオをストーリーテリングに使用することが初めて可能になりました。 実験結果によって、このフレームワークの有用性が確認され、非常に使いやすいビデオ作成ツールとして確立されました。 キャラクターの制作と構造のガイドとの緊張を成功裏に調和させる柔軟な構造ガイド付きテキストからビデオアプローチが提案されました。 チームはまた、現在の競合と比較して大幅に優れたパーソナライゼーションアプローチの新しい概念TimeInvを紹介しました。

ディープネットワークの活性化関数の構築
ディープニューラルネットワークの基本的な要素は、活性化関数(AF)です活性化関数は、ネットワーク内のノード(「ニューロン」)の最終出力を形成する非線形関数です一般的な活性化関数は...

オーストラリアのチームが、人工知能と人間の脳細胞を融合させるための助成金を獲得しました
モナッシュ大学とコルティカルラボのオーストラリアチームが、人間の脳細胞とAIを統合するための助成金を獲得しましたこの助成金は、オーストラリアの情報庁から600,000ドルの価値がありますガーディアンの報道によれば、これはDishBrainを作成した同じチームです
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.