Learn more about Search Results MPT - Page 74

- You may be interested
- 「マーケティングにChatGPTを利用する15の...
- NVIDIA CEO:クリエイターは生成的AIによ...
- 9/10から15/10までの週のトップ...
- Google AIは、アクティブノイズキャンセリ...
- AI教育の追求 – 過去、現在、そして...
- ティーンエイジャーのころ、彼女はビデオ...
- コーネル大学がChatGPTの中核に巨大な脅威...
- Pythonでの機械学習のためのテキストの前...
- AIの物体認識をどのように進化させること...
- BITEとは 1枚の画像から立ち姿や寝そべり...
- 2023年のトップビジネスインテリジェンス...
- 「AWS Inferentia2を使って、あなたのラマ...
- クエリを劇的に改善できる2つの高度なSQL...
- 「AIサービスへの大胆な進出:億万長者ビ...
- 2023年の最高のAI販売アシスタントツール

Intel CPUのNNCFと🤗 Optimumを使用した安定したディフュージョンの最適化
潜在的な拡散モデルは、テキストから画像の生成問題を解決する際にゲームチェンジャーとなります。 安定した拡散は、コミュニティや産業界で広く採用されている最も有名な例の一つです。 安定した拡散モデルのアイデアはシンプルで魅力的です:ノイズベクトルから画像を複数の小さなステップで生成し、ノイズを潜在的な画像表現に洗練させます。 ただし、このようなアプローチは、全体的な推論時間を増加させ、クライアントマシンで展開された場合にユーザーエクスペリエンスの低下を引き起こします。 通常のように、強力なGPUがここで役立つことに注意することができますが、これに伴うコストも著しく増加します。 参考までに、H1’23では、8つのvCPUと64GBのRAMを備えた強力なCPU r6i.2xlargeインスタンスの価格は1時間あたり$0.504であり、同様のNVIDIA T4を搭載したg4dn.2xlargeインスタンスの価格は1時間あたり$0.75で、これは1.5倍以上です.. これにより、画像生成サービスは所有者とユーザーにとって非常に高価になります。 クライアントアプリケーションでは、GPUがまったくない場合もあります! これにより、安定した拡散パイプラインの展開は困難な問題となります。 過去5年間、OpenVINO Toolkitは高性能推論のための多くの機能をカプセル化しました。 最初はコンピュータビジョンモデルに設計されたものですが、現在でも最先端のモデルを含む多くのコンテンポラリーモデルにおいて、最高の推論パフォーマンスを示しています。 ただし、リソース制約のあるアプリケーションに安定した拡散モデルを最適化するには、ランタイム最適化にとどまらず、さらに進んだモデル最適化機能がOpenVINO Neural Network Compression Framework(NNCF)から必要とされます。 このブログ記事では、安定した拡散モデルの最適化の問題を概説し、CPUなどのリソース制約のあるHWで実行される場合に、そのようなモデルのレイテンシを大幅に削減するワークフローを提案します。 特に、PyTorchと比較して5.1倍の推論高速化と4倍のモデルフットプリントの削減を達成しました。 安定した拡散の最適化 安定した拡散パイプラインでは、UNetモデルが計算上最もコストがかかります。そのため、単一のモデルの最適化によって推論速度が大幅に向上します。 しかし、このモデルに対しては、従来のモデル最適化手法であるポストトレーニングの8ビット量子化は機能しないことがわかりました。その理由は2つあります。まず、セマンティックセグメンテーション、スーパーレゾリューションなどのピクセルレベル予測モデルは、タスクの複雑さにより、モデル最適化の観点では最も複雑なものの一つであり、モデルパラメータと構造の微調整が結果を多数の方法で崩してしまいます。…

Amazon SageMakerのHugging Face LLM推論コンテナをご紹介します
これは、オープンソースのLLM(Large Language Model)であるBLOOMをAmazon SageMakerに展開し、新しいHugging Face LLM Inference Containerを使用して推論を行う方法の例です。Open Assistantデータセットで訓練されたオープンソースのチャットLLMである12B Pythia Open Assistant Modelを展開します。 この例では以下の内容をカバーしています: 開発環境のセットアップ 新しいHugging Face LLM DLCの取得 Open Assistant 12BのAmazon SageMakerへの展開 モデルを使用して推論およびチャットを行う…

DuckDB Hugging Face Hubに保存されている50,000以上のデータセットを分析する
Hugging Face Hubは、誰にでもデータセットへのオープンアクセスを提供し、ユーザーがそれらを探索し理解するためのツールを提供することに特化しています。Falcon、Dolly、MPT、およびStarCoderなどの人気のある大規模言語モデル(LLM)のトレーニングに使用されるデータセットの多くを見つけることができます。不公平性や偏見を解決するためのDisaggregatorsのようなデータセット用のツールや、データセット内の例をプレビューするためのDataset Viewerなどのツールもあります。 Dataset Viewerを使用してOpenAssistantデータセットのプレビューを表示します。 私たちは、Hub上のデータセットを分析するための別の機能を最近追加しました。Hubに保存されている任意のデータセットでDuckDBを使用してSQLクエリを実行できます!2022年のStackOverflow Developer Surveyによると、SQLは3番目に人気のあるプログラミング言語です。また、分析クエリを実行するために設計された高速なデータベース管理システム(DBMS)が必要でしたので、DuckDBとの統合に興奮しています。これにより、より多くのユーザーがHub上のデータセットにアクセスし、分析することができると思います! 要約 Datasets Serverは、Hub上のすべての公開データセットをParquetファイルに自動変換します。データセットページの上部にある「Auto-converted to Parquet」ボタンをクリックすることで、それらのファイルを表示することができます。また、単純なHTTP呼び出しでParquetファイルのURLリストにアクセスすることもできます。 r = requests.get("https://datasets-server.huggingface.co/parquet?dataset=blog_authorship_corpus") j = r.json() urls = [f['url'] for…

基礎モデルは人間のようにデータにラベルを付けることができますか?
ChatGPTの登場以来、Large Language Models(LLM)の開発に前例のない成長が見られ、特にプロンプト形式の指示に従うように微調整されたチャットモデルの開発が増えてきました。しかし、これらのモデルの比較は、その性能を厳密にテストするために設計されたベンチマークの不足により明確ではありません。指示とチャットモデルの評価は本質的に困難であり、ユーザーの好みの大部分は質的なスタイルに集約されていますが、過去のNLP評価ははるかに定義されていました。 このような状況で、新しい大規模言語モデル(LLM)が「モデルはChatGPTに対してN%の時間で優先される」という調子でリリースされるのはよくあることですが、その文から省かれているのは、そのモデルがGPT-4ベースの評価スキームで優先されるという事実です。これらのポイントが示そうとしているのは、異なる測定の代理となるものです:人間のラベラーが提供するスコア。人間のフィードバックから強化学習でモデルを訓練するプロセス(RLHF)は、2つのモデル補完を比較するためのインターフェースとデータを増やしました。このデータはRLHFプロセスで使用され、優先されるテキストを予測する報酬モデルを訓練するために使用されますが、モデルの出力を評価するための評価とランキングのアイデアは、より一般的なツールとなっています。 ここでは、ブラインドテストセットのinstructとcode-instructの分割それぞれからの例を示します。 反復速度の観点では、言語モデルを使用してモデルの出力を評価することは非常に効率的ですが、重要な要素が欠けています:下流のツールショートカットが元の測定形式と整合しているかどうかを調査することです。このブログ投稿では、オープンLLMリーダーボード評価スイートを拡張することで、選択したLLMから得られるデータラベルを信頼できるかどうかを詳しく調べます。 LLMSYS、nomic / GPT4Allなどのリーダーボードが登場し始めましたが、モデルの能力を比較するための完全なソースが必要です。一部のモデルは、既存のNLPベンチマークを使用して質問応答の能力を示すことができ、一部はオープンエンドのチャットからのランキングをクラウドソーシングしています。より一般的な評価の全体像を提示するために、Hugging Face Open LLMリーダーボードは、自動化された学術ベンチマーク、プロの人間のラベル、およびGPT-4の評価を含むように拡張されました。 目次 オープンソースモデルの評価 関連研究 GPT-4評価の例 さらなる実験 まとめとディスカッション リソースと引用 オープンソースモデルの評価 ヒトがデータをキュレートする必要があるトレーニングプロセスのどのポイントでもコストがかかります。これまでに、AnthropicのHHHデータ、OpenAssistantの対話ランキング、またはOpenAIのLearning to Summarize /…

iPhone、iPad、およびMacでのCore MLによる高速で安定した拡散
先週、WWDC’23(Apple Worldwide Developers Conference)が開催されました。キーノート中のVision Proの発表に焦点が当てられましたが、それだけではありません。毎年のように、WWDC週はAppleのオペレーティングシステムとフレームワークの新機能について深く掘り下げる200以上の技術セッションが詰まっています。今年は特に、圧縮と最適化のためのCore MLの変更に興奮しています。これらの変更により、Stable Diffusionなどのモデルの実行が高速化され、メモリ使用量も少なくなります!一例として、12月にiPhone 13で実行したテストと現在の6ビットパレット化を使用した速度の比較を考えてみましょう: 12月のiPhoneでのStable Diffusionと現在の6ビットパレット化 目次 新しいCore MLの最適化 量子化および最適化されたStable Diffusionモデルの使用 カスタムモデルの変換と最適化 6ビット未満の使用 結論 新しいCore MLの最適化 Core MLは、Appleのデバイス内で効率的に機械学習モデルを実行するための成熟したフレームワークであり、CPU、GPU、およびMLタスクに特化したニューラルエンジンなど、Appleデバイスのすべてのコンピューティングハードウェアを活用します。デバイス上での実行は、Stable Diffusionや大規模な言語モデルの人気によって引き起こされた非常に興味深い時期を迎えています。多くの人々がこれらのモデルをさまざまな理由でハードウェア上で実行したいと考えており、利便性やプライバシー、APIのコスト削減などがその理由です。自然に、多くの開発者がデバイス上でこれらのモデルを効率的に実行する方法を探求し、新しいアプリやユースケースを作成しています。この目標を達成するためのCore MLの改善は、コミュニティにとって大きなニュースです!…

Open LLMのリーダーボードはどうなっていますか?
最近、Falcon 🦅のリリースおよびOpen LLM Leaderboardへの追加に関して、Twitter上で興味深い議論が起こりました。Open LLM Leaderboardは、オープンアクセスの大規模言語モデルを比較する公開のリーダーボードです。 この議論は、リーダーボードに表示されている4つの評価のうちの1つであるMassive Multitask Language Understanding(略称:MMLU)のベンチマークを中心に展開されました。 コミュニティは、リーダーボードの現在のトップモデルであるLLaMAモデル 🦙のMMLU評価値が、公開されたLLaMa論文の値よりも著しく低いことに驚きました。 そのため、私たちは何が起こっているのか、そしてそれを修正する方法を理解するために深堀りしました 🕳🐇 私たちとのこの冒険の旅において、私たちはLLaMAの評価に協力した素晴らしい@javier-m氏、そしてFalconチームの素晴らしい@slippylolo氏と話し合いました。もちろん、以下のエラーは彼らではなく、私たちに帰すべきです! この冒険の旅の中で、オンラインや論文で見る数値を信じるべきかどうか、モデルを単一の評価で評価する方法について多くのことを学ぶことができます。 準備はいいですか?それでは、シートベルトを締めましょう、出発します 🚀。 Open LLM Leaderboardとは何ですか? まず、Open LLM Leaderboardは、実際にはEleutherAI非営利AI研究所によって作成されたオープンソースのベンチマークライブラリEleuther…
オープンなMLモデルを使用してWebアプリジェネレータを作成する
コード生成モデルがますます一般公開されるようになると、以前には想像もできなかった方法でテキストからウェブやアプリへの変換が可能になりました。 このチュートリアルでは、コンテンツのストリーミングとレンダリングを一度に行うことで、AIウェブコンテンツ生成への直接的なアプローチを紹介します。 ここでライブデモを試してみてください! → Webapp Factory NodeアプリでのLLMの使用方法 AIやMLに関連するすべてのことをPythonで行うと思われがちですが、ウェブ開発コミュニティではJavaScriptとNodeに大いに依存しています。 このプラットフォームで大きな言語モデルを使用する方法をいくつか紹介します。 ローカルでモデルを実行する JavaScriptでLLMを実行するためのさまざまなアプローチがあります。ONNXを使用したり、コードをWASMに変換して他の言語で書かれた外部プロセスを呼び出したりする方法などがあります。 これらの技術のいくつかは、次のような使いやすいNPMライブラリとして利用できます: コード生成をサポートするtransformers.jsなどのAI/MLライブラリの使用 ブラウザ用のllama-node(またはweb-llm)など、専用のLLMライブラリの使用 Pythoniaなどのブリッジを介してPythonライブラリを使用 ただし、このような環境で大きな言語モデルを実行すると、リソースをかなり消費することがあります。特にハードウェアアクセラレーションを使用できない場合はさらにリソースが必要です。 APIを使用する 現在、さまざまなクラウドプロバイダが言語モデルの使用を提案しています。以下はHugging Faceの提供するオプションです: コミュニティから小さなモデルからVoAGIサイズのモデルまで使用できる無料の推論API。 より高度で本番向けの推論エンドポイントAPIで、より大きなモデルやカスタム推論コードが必要な方向けのもの。 これらの2つのAPIは、NPM上のHugging Face推論APIライブラリを使用してNodeから利用できます。 💡…

Hugging Faceの推論エンドポイントを使用してLLMをデプロイする
オープンソースのLLMであるFalcon、(オープン-)LLaMA、X-Gen、StarCoder、またはRedPajamaは、ここ数ヶ月で大きく進化し、ChatGPTやGPT4などのクローズドソースのモデルと特定のユースケースで競合することができるようになりました。しかし、これらのモデルを効率的かつ最適化された方法で展開することはまだ課題です。 このブログ投稿では、モデルの展開を容易にするマネージドSaaSソリューションであるHugging Face Inference EndpointsにオープンソースのLLMを展開する方法と、応答のストリーミングとエンドポイントのパフォーマンステストの方法を紹介します。さあ、始めましょう! Falcon 40Bの展開方法 LLMエンドポイントのテスト JavaScriptとPythonでの応答のストリーミング 始める前に、Inference Endpointsについての知識をおさらいしましょう。 Hugging Face Inference Endpointsとは何ですか Hugging Face Inference Endpointsは、本番環境での機械学習モデルの展開を簡単かつ安全な方法で提供します。Inference Endpointsを使用することで、開発者やデータサイエンティストはインフラストラクチャの管理をせずにAIアプリケーションを作成できます。展開プロセスは数回のクリックで簡略化され、オートスケーリングによる大量のリクエストの処理、ゼロスケールへのスケールダウンによるインフラストラクチャのコスト削減、高度なセキュリティの提供などが可能となります。 LLM展開における最も重要な機能のいくつかは以下の通りです: 簡単な展開: インフラストラクチャやMLOpsの管理を必要とせず、本番用のAPIとしてモデルを展開できます。 コスト効率:…

SQLクエリにおいてGPT-4よりも優れたもの:NSQL(完全なオープンソース)
ChatGPTや他のLLM(Language Model)を使用してSQLクエリを生成しようとしたことがある方は手を挙げてください私は試してみましたし、現在も試しています!しかし、新しいオープンソースのファミリーが登場したことをお伝えできるのがとても嬉しいです...
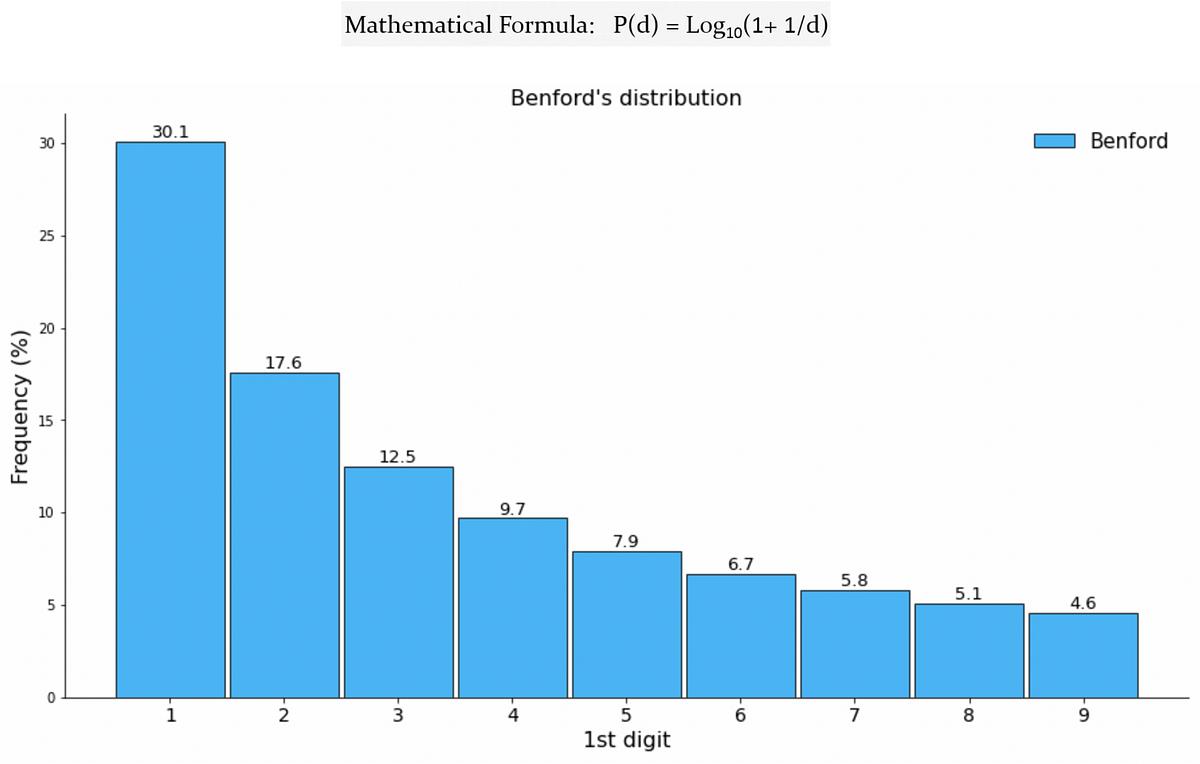
Benfordの法則が機械学習と出会って、偽のTwitterフォロワーを検出する
ソーシャルメディアの広大なデジタル領域において、ユーザーの真正性は最も重要な懸念事項ですTwitterなどのプラットフォームが成長するにつれ、フェイクアカウントの増加も増えていますこれらのアカウントは本物のアカウントを模倣します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.