Learn more about Search Results リポジトリ - Page 74

- You may be interested
- 「AIガバナンスの12のコア原則」
- 深層学習フレームワークの比較
- *args, **kwargs、そしてその間のすべて
- 機械学習によるマルチビューオプティカル...
- 夢と現実の間:生成テキストと幻覚
- 「ファビオ・バスケスとともに、ラテンア...
- 「マーク・A・レムリー教授による生成AIと...
- 「AIによるデータアナリストのテストに挑...
- AIパワーを活用した機会の開放-イギリス
- トップ10の生成AI 3Dオブジェクトジェネレ...
- 「Googleのアルゴリズムによって、FIDO暗...
- 「メーカーに会う:開発者がAI搭載ピット...
- J-WAFS創設大会は、改良された作物品種を...
- 「GPT-4の高度なデータ分析ツールを使用し...
- 「モンテカルロシミュレーションによる誤...
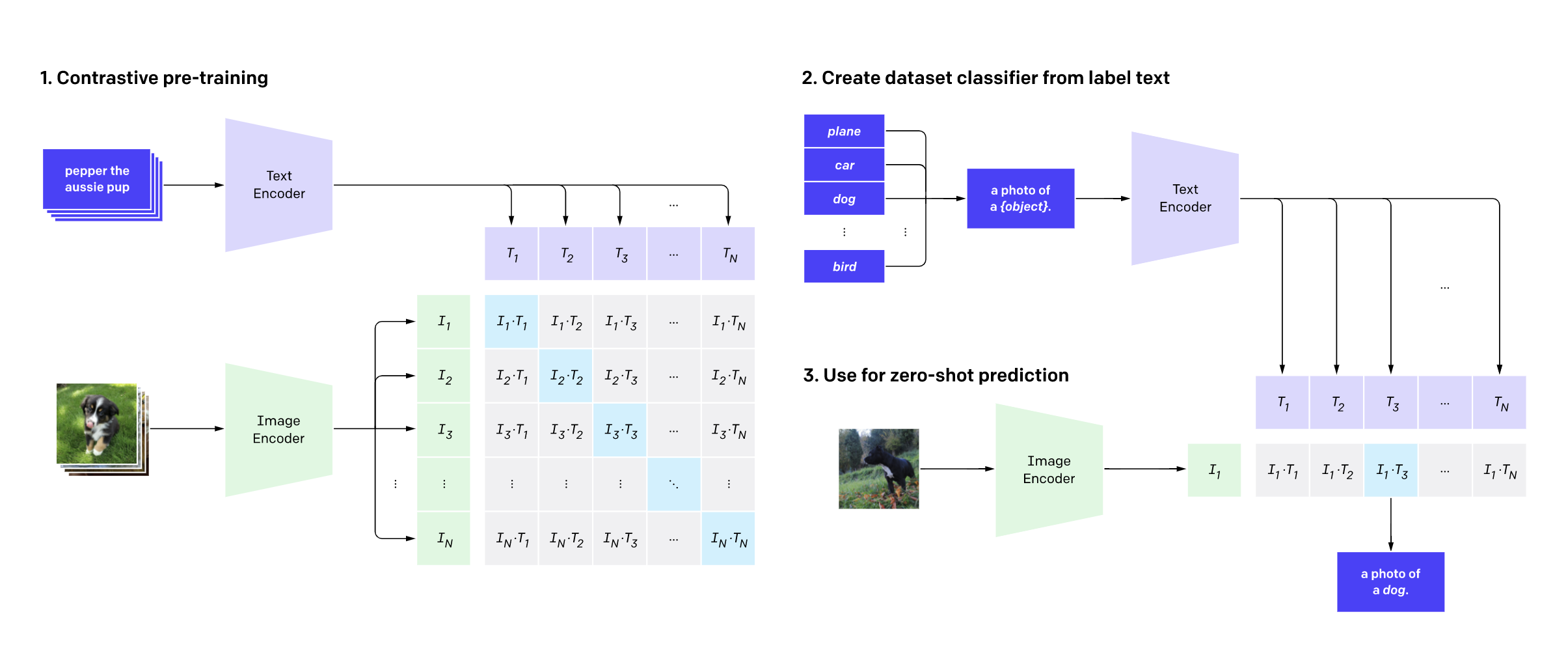
リモートセンシング(衛星)画像とキャプションを使用してCLIPの微調整
リモートセンシング(衛星)画像とキャプションを使用したCLIPの微調整 今年の7月、Hugging FaceはFlax/JAXコミュニティウィークを開催し、自然言語処理(NLP)とコンピュータビジョン(CV)の分野でHugging Faceトランスフォーマーモデルを訓練するプロジェクトの提出をコミュニティに呼びかけました。 参加者はFlaxとJAXを使用したTensor Processing Units(TPUs)を使用しました。JAXは線形代数ライブラリ(numpyのような)で、自動微分(Autograd)を行い、XLAにコンパイルできます。また、FlaxはJAX用のニューラルネットワークライブラリであり、エコシステムです。TPUの計算時間は、共同スポンサーであるGoogle Cloudが無料で提供しました。 その後の2週間で、チームはHugging FaceとGoogleの講義に参加し、JAX/Flaxを使用して1つ以上のモデルを訓練し、それらをコミュニティと共有し、モデルの機能を示すHugging Face Spacesデモを提供しました。約100チームが参加し、170のモデルと36のデモが生まれました。 私たちのチームは、おそらく他の多くのチームと同様に、12のタイムゾーンにまたがる分散型のチームです。私たちの共通点は、TWIML Slackチャンネルに所属していることであり、そこでは人工知能(AI)と機械学習(ML)のトピックに関心を持つメンバーが集まっています。 私たちは、OpenAIのCLIPネットワークをRSICDデータセットの衛星画像とキャプションで微調整しました。CLIPネットワークは、インターネット上で見つかる画像とキャプションのペアを使用して、自己教師ありの方法で視覚的な概念を学習します。推論中、モデルはテキストの説明に基づいて最も関連性の高い画像を予測するか、画像に基づいて最も関連性の高いテキストの説明を予測することができます。CLIPは、普段の画像に対してゼロショットで使用するには十分なパワフルです。しかし、衛星画像は普段の画像とは異なるため、CLIPを微調整することが有益であると考えました。私たちの直感は正しかったようで、評価結果(後述)が示すようになりました。この記事では、私たちのトレーニングと評価プロセスの詳細、およびこのプロジェクトへの今後の取り組みについて説明します。 私たちのプロジェクトの目標は、有用なサービスを提供し、CLIPを実用的なユースケースに使用する方法を示すことでした。私たちのモデルは、テキストクエリを使用して大規模な衛星画像のコレクションを検索するためにアプリケーションによって使用することができます。そのようなクエリは、画像全体を記述することができます(例:ビーチ、山、空港、野球場など)、またはこれらの画像内の特定の地理的または人工的な特徴を検索または言及することができます。CLIPは、他のドメインでも同様に微調整することができます。これは、医療画像のメディカルチームによって示されています。 テキストクエリを使用して大規模な画像コレクションを検索する能力は、非常に強力な機能であり、社会的な善だけでなく、悪意のある目的にも使用することができます。国家防衛や反テロ活動、気候変動の影響を管理可能な状態になる前に発見し対処する能力など、様々な応用が考えられます。ただし、この力は、権威主義的な国家による軍事や警察の監視などの目的で誤用される可能性もあるため、倫理的な問題も提起されます。 プロジェクトについては、プロジェクトページで詳細を読むことができます。また、独自のデータで推論に使用するために、トレーニング済みモデルをダウンロードすることもできます。デモでも実際の動作を確認することができます。 トレーニング データセット 私たちは、主にRSICDデータセットを使用してCLIPモデルを微調整しました。このデータセットは、Google Earth、Baidu Map、MapABC、Tiandituから収集された約10,000枚の画像から構成されています。このデータセットは、Exploring Models…

1Bのトレーニングペアで文埋め込みモデルをトレーニングする
文の埋め込みは、文を実数のベクトルにマッピングする手法です。理想的には、これらのベクトルは文の意味を捉え、高度に汎用的であるべきです。そのような表現は、クラスタリング、テキストマイニング、質問応答など、多くの下流アプリケーションで使用することができます。 私たちは、「1Bのトレーニングペアで最高の文埋め込みモデルをトレーニングするプロジェクト」として、最先端の文埋め込みモデルを開発しました。このプロジェクトは、Hugging Faceによって主催されたCommunity week using JAX/Flax for NLP & CVの一環として行われました。このプロジェクトでは、GoogleのFlax、JAX、およびCloudチームのメンバーから、効率的なディープラーニングフレームワークに関するガイダンスを受けました! トレーニング手法 モデル 単語とは異なり、有限の文の集合を定義することはできません。したがって、文の埋め込み手法では、内部の単語を組み合わせて最終的な表現を計算します。たとえば、SentenceBertモデル(Reimers and Gurevych, 2019)では、多くのNLPアプリケーションの基盤であるTransformerを使用し、コンテキスト化された単語ベクトルに対してプーリング操作を行います(以下の図を参照)。 マルチプルネガティブランキングロス 構成モジュールのパラメータは通常、自己教師ありの目的関数を使用して学習されます。このプロジェクトでは、以下の図で説明されているコントラスティブトレーニング方法を使用しました。文のペア(a_i, p_i)が意味的に近いペアであるデータセットを構成します。たとえば、(クエリ、回答パッセージ)、(質問、重複質問)、(論文タイトル、引用論文タイトル)などのペアを考慮します。その後、モデルは、ペア(a_i, p_i)を埋め込み空間で近いベクトルにマッピングするようにトレーニングされます。一方、非一致のペア(a_i, p_j)、i ≠ jは、埋め込み空間で遠いベクトルにマッピングされます。このトレーニング方法は、インバッチネガティブ、InfoNCE、またはNTXentLossとも呼ばれます。 形式的には、トレーニングサンプルのバッチが与えられた場合、モデルは以下の損失関数を最適化します:…
🤗 Transformersを使用して、低リソースASRのためにXLSR-Wav2Vec2を微調整する
新着(11/2021):このブログ投稿は、XLSRの後継であるXLS-Rを紹介するように更新されました。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。Wav2Vec2の優れた性能が、ASRの最も人気のある英語データセットであるLibriSpeechで示されるとすぐに、Facebook AIはWav2Vec2の多言語版であるXLSRを発表しました。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習できる能力を指します。 XLSRの後継であるXLS-R(「音声用のXLM-R」という意味)は、Arun Babu、Changhan Wang、Andros Tjandraなどによって2021年11月にリリースされました。XLS-Rは、自己教師付き事前学習のために128の言語で約500,000時間のオーディオデータを使用し、パラメータ数が30億から200億までのサイズで提供されています。事前学習済みのチェックポイントは、🤗 Hubで見つけることができます: Wav2Vec2-XLS-R-300M Wav2Vec2-XLS-R-1B Wav2Vec2-XLS-R-2B BERTのマスクされた言語モデリング目的と同様に、XLS-Rは自己教師付き事前学習中に特徴ベクトルをランダムにマスクしてからトランスフォーマーネットワークに渡すことで、文脈化された音声表現を学習します(左側の図)。 ファインチューニングでは、事前学習済みネットワークの上に単一の線形層が追加され、音声認識、音声翻訳、音声分類などのラベル付きデータでモデルをトレーニングします(右側の図)。 XLS-Rは、公式論文のTable 3-6、Table 7-10、Table 11-12で、以前の最先端の結果に比べて音声認識、音声翻訳、話者/言語識別の両方で印象的な改善を示しています。 セットアップ このブログでは、XLS-R(具体的には事前学習済みチェックポイントWav2Vec2-XLS-R-300M)をASRのためにファインチューニングする方法について詳しく説明します。 デモンストレーションの目的で、我々は低リソースなASRデータセットのCommon Voiceでモデルをファインチューニングします。このデータセットには検証済みのトレーニングデータが約4時間しか含まれていません。…

Intelのテクノロジーを使用して、PyTorchの分散ファインチューニングを高速化する
驚異的なパフォーマンスを持つ最先端のディープラーニングモデルでも、トレーニングには長い時間がかかることがよくあります。トレーニングジョブを高速化するために、エンジニアリングチームは分散トレーニングに頼っています。これは、クラスタ化されたサーバーがそれぞれモデルのコピーを保持し、トレーニングセットのサブセットでトレーニングを行い、結果を交換して最終的なモデルに収束するという分割統治技術です。 グラフィックプロセッシングユニット(GPU)は、ディープラーニングモデルのトレーニングにおいて長い間デファクトの選択肢でした。しかし、転移学習の台頭により、状況が変化しています。モデルは今や巨大なデータセットからゼロからトレーニングされることはほとんどありません。代わりに、特定の(より小さい)データセットで頻繁に微調整され、特定のタスクに対してベースモデルよりも精度の高い専用モデルが構築されます。これらのトレーニングジョブは短いため、CPUベースのクラスタを使用することは、トレーニング時間とコストの両方を管理するための興味深いオプションとなります。 この投稿の内容 この投稿では、インテル Xeon Scalable CPUサーバのクラスタ上でPyTorchのトレーニングジョブを分散して高速化する方法について説明します。Ice Lakeアーキテクチャを搭載し、パフォーマンス最適化されたソフトウェアライブラリを実行する仮想マシンを使用して、クラスタをゼロから構築します。クラウドまたはオンプレミスの環境で、簡単にデモを自身のインフラストラクチャに複製することができるはずです。 テキスト分類ジョブを実行し、MRPCデータセット(GLUEベンチマークに含まれるタスクの1つ)でBERTモデルを微調整します。MRPCデータセットには、ニュースソースから抽出された5,800の文のペアが含まれており、各ペアの2つの文が意味的に同等であるかどうかを示すラベルが付いています。このデータセットはトレーニング時間が合理的であり、他のGLUEタスクを試すのはパラメーターさえ変更すれば可能です。 クラスタが準備できたら、まずは単一のサーバーでベースラインのジョブを実行します。その後、2つのサーバーや4つのサーバーにスケールアップして、スピードアップを計測します。 途中で以下のトピックについて説明します: 必要なインフラストラクチャとソフトウェアのビルディングブロックのリストアップ クラスタのセットアップ 依存関係のインストール 単一ノードのジョブの実行 分散ジョブの実行 さあ、作業を始めましょう! インテルサーバの使用 最高のパフォーマンスを得るために、Ice Lakeアーキテクチャに基づいたインテルサーバを使用します。これには、Intel AVX-512やIntel Vector Neural Network…
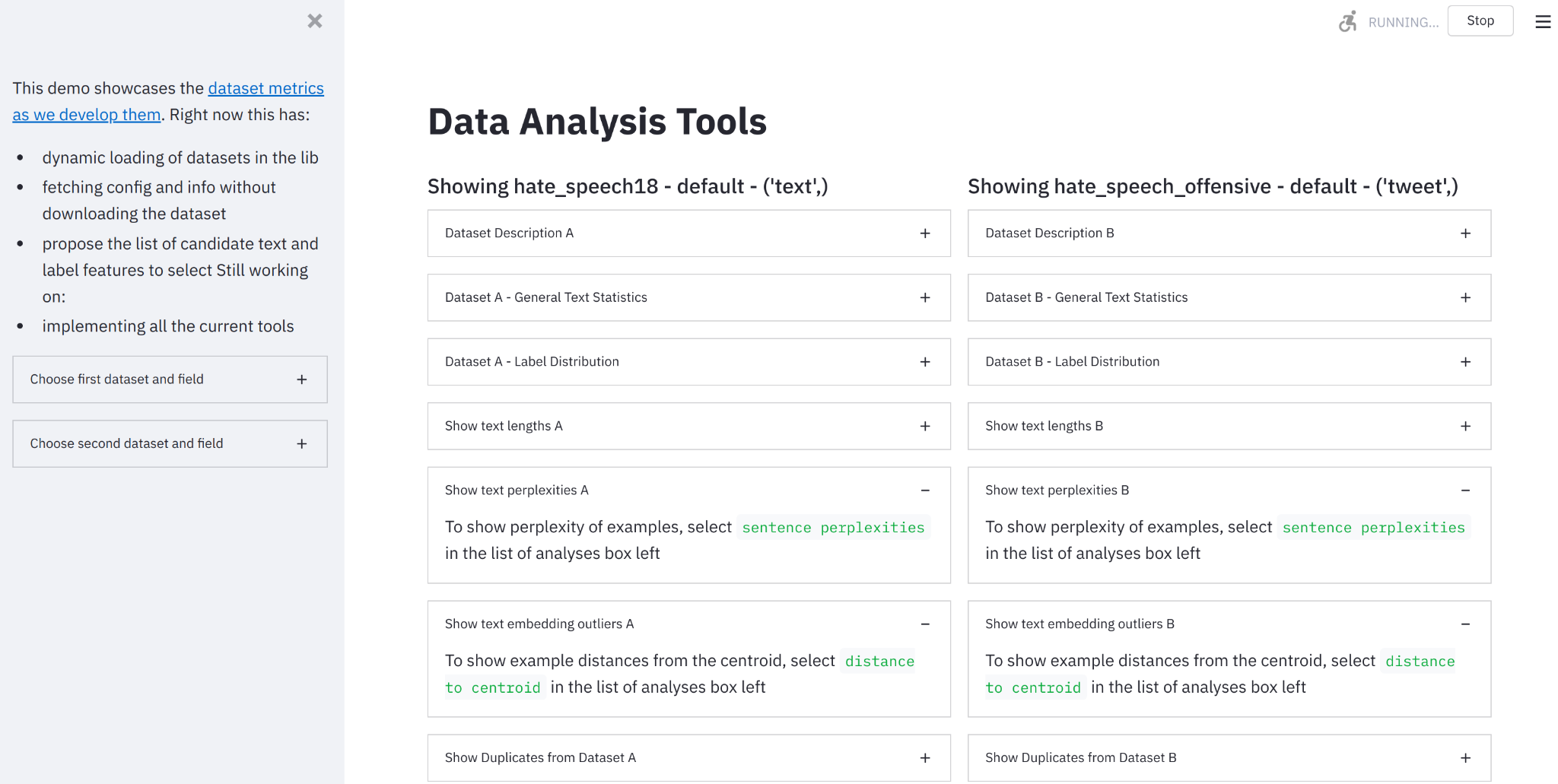
データ測定ツールのご紹介:データセットを見るためのインタラクティブツール
要約:データセットを構築し、測定し、比較するためのオンラインツールを作成しました。 🤗データ計測ツールにアクセスするには、ここをクリックしてください。 機械学習データセットの急成長する統一リポジトリの開発者として(Lhoest et al. 2021)、🤗Hugging Faceチームはデータセットのドキュメント化のための良い実践をサポートするために取り組んできました(McMillan-Major et al. 2021)。静的(進化する可能性のある)ドキュメントはこの方向性への必要な第一歩を表しますが、データセットの実際の内容を理解するには、動機付けのある計測とそれに対する対話的な可視化能力が必要です。 そのため、私たちはオープンソースのPythonライブラリとノーコードインターフェースである🤗データ計測ツールを紹介します。これは、私たちのデータセットとSpaces Hubsを使用して、優れたStreamlitツールと組み合わせて、データセットの理解、構築、キュレーション、比較を支援するために使用することができます。 🤗データ計測ツールとは何ですか? データ計測ツール(DMT)は、データセットの作成者やユーザーが責任あるデータ開発のために有意義で役立つメトリクスを自動的に計算できるインタラクティブなインターフェースおよびオープンソースライブラリです。 なぜこのツールを作成したのですか? 機械学習データセットの綿密なキュレーションと分析は、AIの開発においてしばしば見落とされています。AIにおける「ビッグデータ」の現在の標準(Luccioni et al. 2021, Dodge et al. 2021)は、さまざまなウェブサイトから収集されたデータを使用しており、異なるデータソースが具体的に何を表しているか、それらがモデルの学習にどのように影響するかについてはほとんど注意が払われていません。データセットの注釈手法は、開発者の目標に合ったデータセットのキュレーションに役立つことがありますが、これらのデータセットのさまざまな側面を「測定する」ための手法はかなり限られています(Sambasivan et…
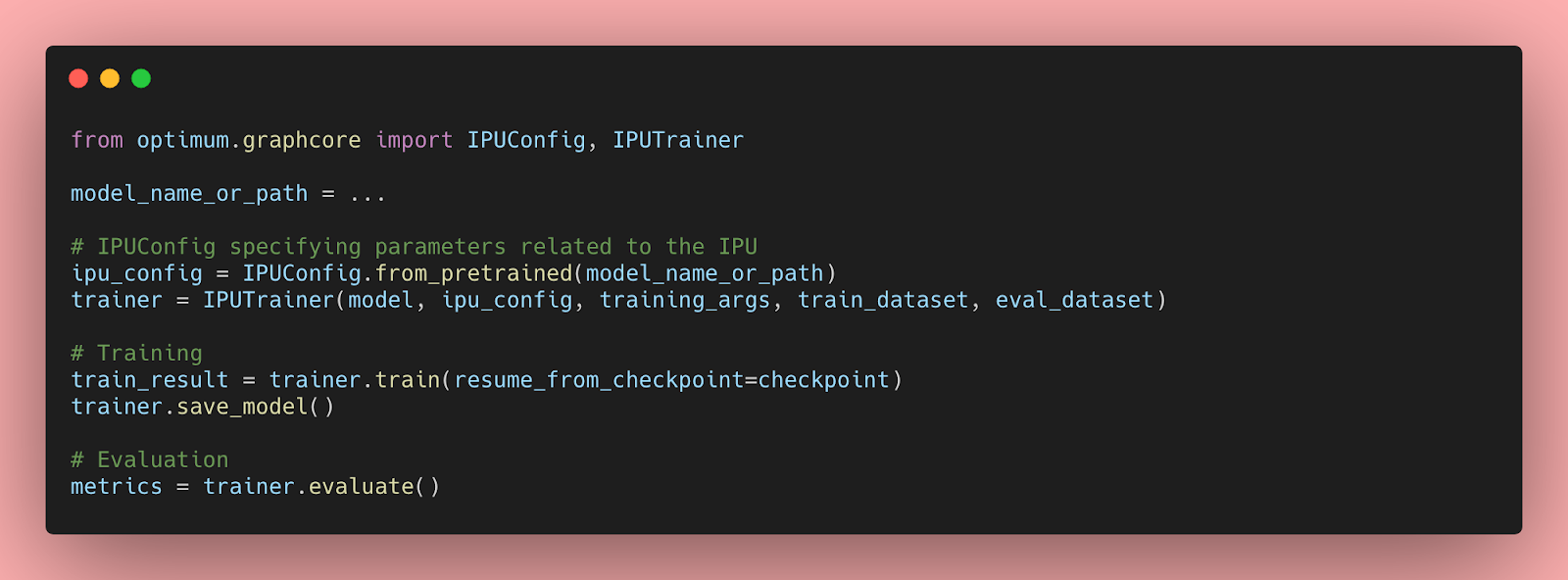
IPUを使用したHugging Face Transformersの始め方と最適化について
Transformerモデルは、自然言語処理、音声処理、コンピュータビジョンなど、さまざまな機械学習タスクで非常に効率的であることが証明されています。しかし、これらの大規模なモデルの予測速度は、会話型アプリケーションや検索などのレイテンシに敏感なユースケースでは実用的ではありません。さらに、実世界でのパフォーマンスを最適化するには、多くの企業や組織には到底手の届かない時間、労力、スキルが必要です。 幸いなことに、Hugging FaceはOptimumというオープンソースのライブラリを導入しました。このライブラリを使用すると、さまざまなハードウェアプラットフォーム上でTransformerモデルの予測レイテンシを大幅に削減することが容易になります。このブログ記事では、AIワークロードに最適化されたGraphcore Intelligence Processing Unit(IPU)向けにTransformerモデルを高速化する方法を学びます。 OptimumがGraphcore IPUと出会う GraphcoreとHugging Faceのパートナーシップにより、最初のIPUに最適化されたモデルとしてBERTが導入されました。今後数ヶ月にわたり、ビジョン、音声、翻訳、テキスト生成など、さまざまなアプリケーションに対応したIPUに最適化されたモデルをさらに導入していく予定です。 Graphcoreのエンジニアは、Hugging Faceのトランスフォーマーを使用してBERTをIPUシステムに実装し、最新のモデルを簡単にトレーニング、微調整、高速化できるように最適化しました。 IPUとOptimumの始め方 OptimumとIPUの使用を始めるために、BERTを例にして説明します。 このガイドでは、Graphcoreのクラウドベースの機械学習プラットフォームであるGraphcloudのIPU-POD16システムを使用し、Getting Started with Graphcloud のPyTorchのセットアップ手順に従います。 GraphcloudサーバーにはすでにPoplar SDKがインストールされています。別のセットアップを使用している場合は、PyTorch for the IPU:…

スクラッチからCodeParrot 🦜をトレーニングする
このブログポストでは、GitHub CoPilotの背後にある技術を構築するために必要なものについて説明します。GitHub CoPilotは、プログラマがコードを書く際に提案を行うアプリケーションです。このステップバイステップガイドでは、ゼロから完全にトレーニングされた大規模なGPT-2モデルであるCodeParrot 🦜を訓練する方法を学びます。CodeParrotはPythonのコードを自動補完することができます – こちらで試してみてください。さあ、ゼロから構築してみましょう! ソースコードの大規模なデータセットの作成 まず必要なものは、大規模なトレーニングデータセットです。Pythonのコード生成モデルを訓練することを目指して、GoogleのBigQueryで利用可能なGitHubのダンプにアクセスし、すべてのPythonファイルに絞り込みました。その結果、180GBのデータセットがあり、2000万のファイルが含まれています(こちらで入手可能)。初期のトレーニング実験の結果、データセットの重複はモデルの性能に深刻な影響を与えることがわかりました。データセットを調査すると、次のことがわかりました: ユニークなファイルの0.1%が全ファイルの15%を占めています ユニークなファイルの1%が全ファイルの35%を占めています ユニークなファイルの10%が全ファイルの66%を占めています 詳細は、このTwitterスレッドで調査結果について詳しくご覧いただけます。重複を削除し、CoPilotの背後にあるモデルであるCodexの論文で見つかった同じクリーニングヒューリスティックを適用しました。CodexはGitHubのコードでファインチューニングされたGPT-3モデルです。 クリーニングされたデータセットはまだ50GBの大きさであり、Hugging Face Hubで利用可能です:codeparrot-clean。これで新しいトークナイザーを設定し、モデルを訓練することができます。 トークナイザーとモデルの初期化 まず、トークナイザーが必要です。コードを適切にトークンに分割するために、コード専用のトークナイザーをトレーニングしましょう。既存のトークナイザー(例えばGPT-2)を取り、train_new_from_iterator()メソッドで独自のデータセットでトレーニングします。それから、Hubにプッシュします。コードの例からインポートや引数のパース、ログ出力は省略していますが、前処理やダウンストリームタスクの評価を含めた完全なコードはこちらで見つけることができます。 # トレーニング用のイテレーター def batch_iterator(batch_size=10): for _ in…

🤗 Transformersでn-gramを使ってWav2Vec2を強化する
Wav2Vec2は音声認識のための人気のある事前学習モデルです。2020年9月にMeta AI Researchによってリリースされたこの新しいアーキテクチャは、音声認識のための自己教師あり事前学習の進歩を促進しました。例えば、G. Ng et al.、2021年、Chen et al、2021年、Hsu et al.、2021年、Babu et al.、2021年などが挙げられます。Hugging Face Hubでは、Wav2Vec2の最も人気のある事前学習チェックポイントは現在、月間ダウンロード数25万以上です。 コネクショニスト時系列分類(CTC)を使用して、事前学習済みのWav2Vec2のようなチェックポイントは、ダウンストリームの音声認識タスクで非常に簡単にファインチューニングできます。要するに、事前学習済みのWav2Vec2のチェックポイントをファインチューニングする方法は次のとおりです。 事前学習チェックポイントの上にはじめに単一のランダムに初期化された線形層が積み重ねられ、生のオーディオ入力を文字のシーケンスに分類するために訓練されます。これは以下のように行います。 生のオーディオからオーディオ表現を抽出する(CNN層を使用する) オーディオ表現のシーケンスをトランスフォーマーレイヤーのスタックで処理する 処理されたオーディオ表現を出力文字のシーケンスに分類する 以前のオーディオ分類モデルでは、分類されたオーディオフレームのシーケンスを一貫した転写に変換するために、追加の言語モデル(LM)と辞書が必要でした。Wav2Vec2のアーキテクチャはトランスフォーマーレイヤーに基づいているため、各処理されたオーディオ表現は他のすべてのオーディオ表現から文脈を得ることができます。さらに、Wav2Vec2はファインチューニングにCTCアルゴリズムを利用しており、変動する「入力オーディオの長さ」と「出力テキストの長さ」の比率の整列の問題を解決しています。 文脈化されたオーディオ分類と整列の問題がないため、Wav2Vec2には受け入れ可能なオーディオ転写を得るために外部の言語モデルや辞書は必要ありません。 公式論文の付録Cに示されているように、Wav2Vec2は言語モデルを使用せずにLibriSpeechで印象的なダウンストリームのパフォーマンスを発揮しています。ただし、付録からも明らかなように、Wav2Vec2を10分間の転写済みオーディオのみで訓練した場合、言語モデルと組み合わせると特に改善が見られます。 最近まで、🤗 TransformersライブラリにはファインチューニングされたWav2Vec2と言語モデルを使用してオーディオファイルをデコードするための簡単なユーザーインターフェースがありませんでした。幸いにも、これは変わりました。🤗…

Hugging Face Hubへようこそ、Stable-baselines3さん🤗
私たちはHugging Faceで、深層強化学習の研究者や愛好家向けのエコシステムに貢献しています。そのため、私たちはStable-Baselines3をHugging Face Hubに統合したことをお知らせできることをうれしく思っています。 Stable-Baselines3は、最も人気のあるPyTorch深層強化学習ライブラリの1つであり、さまざまな環境(Gym、Atari、MuJoco、Procgenなど)でエージェントのトレーニングとテストを簡単に行うことができます。この統合により、保存されたモデルをホストできるようになり、コミュニティから強力なモデルをロードすることができます。 この記事では、その方法を紹介します。 インストール Hugging Face Hubでstable-baselines3を使用するには、次の2つのライブラリをインストールする必要があります。 pip install huggingface_hub pip install huggingface_sb3 モデルの検索 現在、Space Invaders、Breakout、LunarLanderなどをプレイするエージェントの保存されたモデルをアップロードしています。さらに、コミュニティからすべてのstable-baselines-3モデルをここで見つけることができます。 必要なモデルを見つけたら、リポジトリIDをコピーするだけです。 Hubからモデルをダウンロードする この統合の最もクールな機能は、HubからStable-baselines3に保存されたモデルを非常に簡単にロードできることです。 そのためには、保存されたモデルを含むリポジトリのrepo-idと、リポジトリ内の保存されたモデルzipファイルの名前をコピーする必要があります。 例えば、sb3/demo-hf-CartPole-v1…

Pythonを使用した感情分析の始め方
感情分析は、データを感情に基づいてタグ付けする自動化されたプロセスです。感情分析により、企業はデータをスケールで分析し、洞察を検出し、プロセスを自動化することができます。 過去には、感情分析は研究者、機械学習エンジニア、または自然言語処理の経験を持つデータサイエンティストに限定されていました。しかし、AIコミュニティは最近、機械学習へのアクセスを民主化するための素晴らしいツールを開発しました。今では、わずか数行のコードを使って感情分析を行い、機械学習の経験が全くなくても利用することができます!🤯 このガイドでは、Pythonを使用した感情分析の始め方についてすべてを学びます。具体的には以下の内容です: 感情分析とは何か? Pythonで事前学習済みの感情分析モデルを使用する方法 独自の感情分析モデルを構築する方法 感情分析でツイートを分析する方法 さあ、始めましょう!🚀 1. 感情分析とは何ですか? 感情分析は、与えられたテキストの極性を特定する自然言語処理の技術です。感情分析にはさまざまなバリエーションがありますが、最も広く使用されている技術の1つは、データを「ポジティブ」、「ネガティブ」、または「ニュートラル」のいずれかにラベル付けするものです。たとえば、次のようなツイートを見てみましょう。@VerizonSupportをメンションしているものです: “dear @verizonsupport your service is straight 💩 in dallas.. been with y’all over…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.