Learn more about Search Results A - Page 746

- You may be interested
- 「Pandasによるデータクリーニング」
- 「ビルドしてプレイ!LLM搭載のあなた自身...
- AIのパイオニア、フェイ・フェイ・リー:A...
- 時系列のフーリエ変換:複素数のプロット
- 「データを実行可能なビジネスインサイト...
- 『Photoshopを越えて:Inst-Inpaintが拡散...
- 「ポッドキャスティングのためのトップAI...
- 「データサイエンスプロジェクトのための8...
- 「ExcelのTEXT関数の使い方は? [例を使っ...
- AIが私のいとこのような運動障害を持つ人...
- 「2023年8月のアフィリエイトマーケティン...
- 企業管理ソフトウェアはAI統合からどのよ...
- 新しい人工知能(AI)の研究アプローチは...
- アリストテレスによれば、ChatGPTは思考す...
- 「人工知能のイメージング:GANの複雑さと...
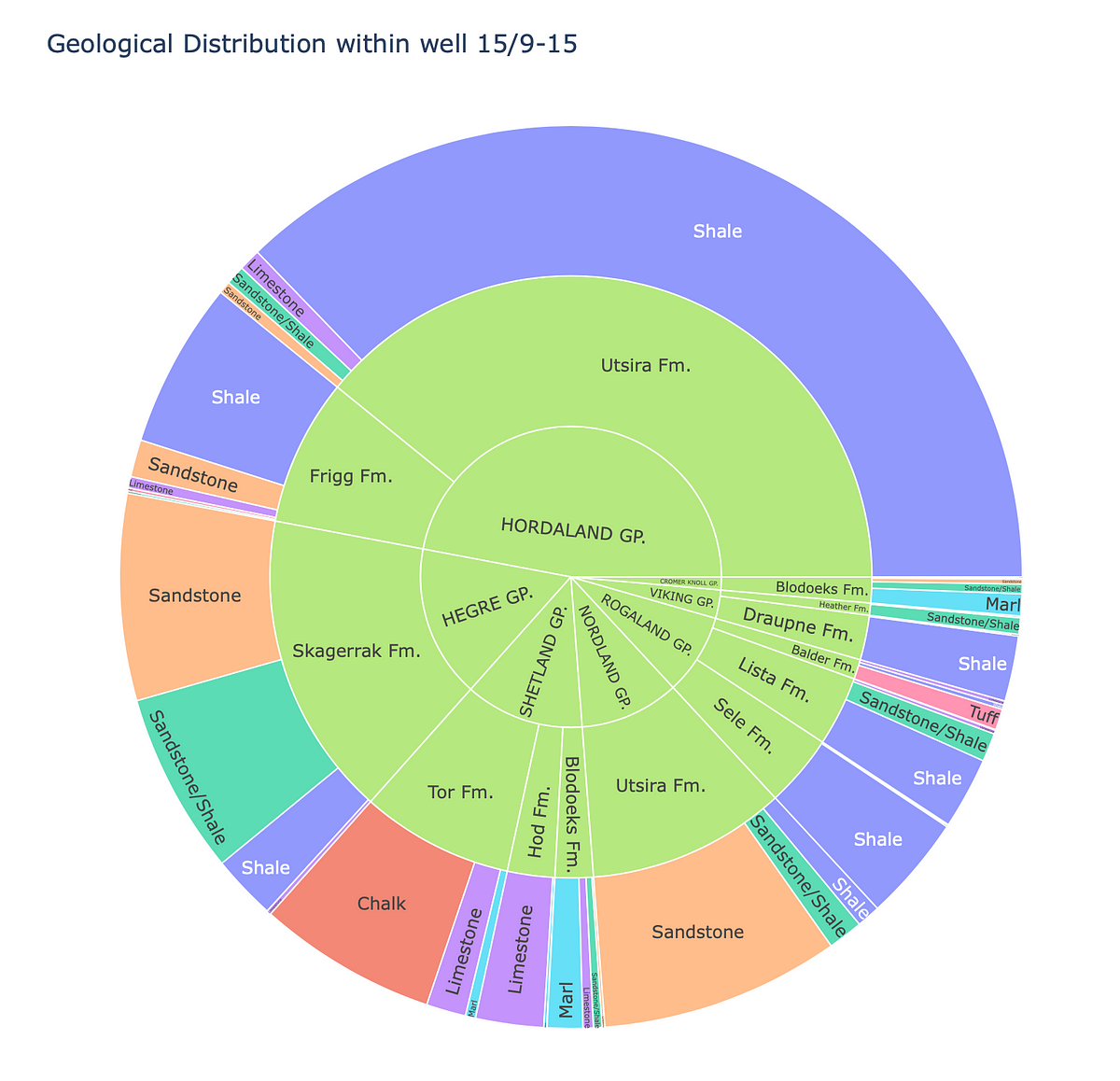
「Plotly Expressのサンバーストチャートを使用して地質データを探索する」
「データの可視化は、地球科学やデータサイエンスの領域において重要な役割を果たしますこれにより、地下構造や階層的な地質構造の理解を深めることができます...」
「ガウス混合モデル(GMM)の3つのユースケース」
ガウス混合モデル(GMM)は、各分類の確率を予測するためにK-means手順に基づいて構築された、シンプルでありながら強力な教師なし分類アルゴリズムです

「MLOpsの考え方:常に本番準備完了」
「プロジェクトの最初からMLのプロダクションマインドセットが欠如していると、特にプロダクション時に驚きが生じ、再モデリングや市場投入までの時間の遅延を引き起こす可能性があります」

「洪水耐性のための地理空間分析」
はじめに 洪水に対する地理空間分析は、都市計画、環境管理、公衆衛生の複雑な問題を解決するために位置情報ベースのデータを使用します。これにより、隠れたつながりやトレンドが明らかになり、リソースの割り当てに関するより良い意思決定や生活の向上が可能になります。このガイドでは、ArcGISを使用して洪水を分析する魅力的なプロジェクトを探求し、地理空間分析が現実の状況にどのように影響を与えるかを学びます。まるで新しい世界を見るための超能力のようです! 学習目標 位置情報ベースのデータを活用して貴重な洞察を得るための地理空間分析の概念と重要性を理解していただきたい。 都市計画、環境管理、物流、農業、公衆衛生などの分野での地理空間分析の多様な応用について理解していただきたい。 ArcGISソフトウェアを利用して、インドのウッタラーカンド州で洪水管理のための地理空間分析をどのように適用するかを学んでいただきたい。 洪水管理に関連する課題を特定し、地理空間分析がこれらの課題に効果的に対処する方法を理解していただきたい。 地域の地形、水文、人口密度に関連する地理空間データのインポート、操作、分析の実践的なスキルを身につけていただきたい。 ArcGISの地理空間ツールを使用して、洪水の発生しやすい地域の特定、脆弱性評価、リスク分析の技術を探求していただきたい。 この記事はデータサイエンスブログマラソンの一部として公開されました。 洪水の地理空間分析の理解 地理空間分析とは何ですか? 洪水の地理空間分析は、先端技術を使用して洪水をより良く理解し管理するための魅力的な分野です。このトピックが初めての方のために、地理空間分析、洪水の地理空間分析の重要性、ArcGISの紹介の3つの主要な領域に分けて説明します。 地理空間分析は、地理データを研究し解釈することで洞察を得ることを目的としています。場所、特徴、属性などの要素間の関係を理解することに関連しています。洪水分析では、地理空間分析は降雨、地形、土地被覆、インフラに関連するデータを分析し可視化することで、洪水リスクを評価し、脆弱な地域を特定し、効果的な洪水管理戦略を開発するのに役立ちます。 地理空間分析の重要性 では、なぜ洪水の地理空間分析が重要なのでしょうか?洪水の影響を軽減するために、洪水の地理空間分析は重要な役割を果たしています。高度モデルや河川ネットワークなどの空間データを調査することで、洪水の発生しやすい地域を特定し、洪水イベントの深刻さを評価することができます。この知識は、洪水制御構造物の建設、排水システムの改善、早期警戒システムの導入など、行動とリソースの優先順位付けに役立ちます。結果として、洪水イベント中に人命を救い、財産を保護することができます。 ArcGISの紹介 洪水の地理空間分析に関して、利用可能な強力なツールの1つはArcGISです。ArcGISは、Esriによって開発された包括的なマッピング、空間データ管理、分析ソフトウェアです。洪水分析を含む高度な地理空間分析タスクを実行するためのさまざまなツールと機能を提供しています。 ArcGISを使用すると、衛星画像やデジタル標高モデルなどのさまざまな空間データタイプを統合して、詳細な地図を作成し、空間的な関係を理解することができます。洪水分析では、ArcGISを使用して降雨強度、標高、土地被覆などのデータを分析し、洪水のパターンと潜在的な影響についての洞察を得ることができます。使いやすいインターフェースにより、洪水モデリング、水文分析、洪水リスク評価のタスクを実行することができます。ArcGISは、対話的な地図、グラフ、レポートを作成することもでき、関係者や意思決定者に対して洪水関連情報を理解し伝えるのが容易になります。 要するに、ArcGISなどのツールを使った洪水の地理空間分析は、洪水のパターン、脆弱性、潜在的な影響に関する貴重な洞察を得ることを可能にします。地理空間データと分析を活用して洪水管理戦略を強化し、復興力を高め、洪水リスクを軽減することが目的です。 現代生活における地理空間分析の重要性 地理空間分析は、現代のさまざまな分野で重要です。貴重な洞察を提供し、意思決定を支援します。以下は、その重要性を強調するいくつかの要点です: 都市計画と開発 地理空間分析は、効率的な都市計画、インフラストラクチャの最適な配置、住宅、商業、レクリエーションエリアの適切な場所の特定に役立ちます。…

スタンフォード大学の研究者たちは、「ギスティング:言語モデルにおける効率的なプロンプト圧縮のための新しい技術」というものを紹介しました
モデルの特殊化は、事前に学習された機械学習モデルを特定のタスクやドメインに適応させることを意味します。言語モデル(LM)では、モデルの特殊化は、要約、質問応答、翻訳、言語生成など、さまざまなタスクでのパフォーマンス向上に重要です。言語モデルを特定のタスクに特殊化するための2つの主なプロセスは、命令の微調整(事前に学習されたモデルを新しいタスクまたは一連のタスクに適応させること)とモデルの蒸留(事前に学習された「教師」モデルから小型の特殊化された「学生」モデルに知識を転送すること)です。プロンプティングは、LMの特殊化の分野で重要な概念であり、特定の動作にモデルを誘導する方法を提供し、限られたトレーニングデータのより効率的な使用を可能にし、最先端のパフォーマンスを実現するために重要です。プロンプトの圧縮は、計算、メモリ、ストレージの大幅な節約と、出力の全体的なパフォーマンスや品質の実質的な低下をもたらすことを目指して研究されている手法です。 この論文は、スタンフォード大学の研究者によって発表されたもので、プロンプトの圧縮のための新しい手法である「gisting」を提案しています。これは、LMを訓練してプロンプトをより小さな「gist」トークンのセットに圧縮する方法です。プロンプトのコストを削減するためには、微調整や蒸留のような技術を使用して、プロンプトなしで元のモデルと同じように振る舞うモデルを訓練することができますが、その場合、モデルは新しいプロンプトごとに再訓練する必要があり、理想的な状況からはほど遠いです。一方、gistingのアイデアは、メタ学習のアプローチを使用してプロンプトからgistトークンを予測することで、タスクごとにモデルを再訓練することなく、未知の命令に対しても汎化させることができます。これにより、計算コストが削減され、プロンプトを圧縮してキャッシュ化し、計算効率を向上させることができます。また、限られたコンテキストウィンドウにより多くのコンテンツを収めることも可能になります。 著者たちは、このようなモデルを実現するための簡単な方法を試みました。彼らはLM自体(その事前の知識を活用)を使用して、命令の微調整中にgistトークンを予測し、Transformerのアテンションマスクを修正しました。タスクと入力のペアが与えられた場合、彼らはタスクと入力の間にgistトークンを追加し、アテンションマスクを次のように設定しました:gistトークンの後の入力トークンは、gistトークンの前のプロンプトトークンのいずれにもアテンションを向けることができません(ただし、gistトークンにはアテンションを向けることができます)。入力と出力がプロンプトにアテンションを向けることができないため、モデルはプロンプトの情報をgistトークンに圧縮する必要があります。gistモデルを訓練するためには、さまざまなタスクの多様なデータセットが必要でしたので、彼らはAlpaca+と呼ばれるデータセットを作成しました。これは、2つの既存の命令微調整データセット(Standford AlpacaとSelf-Instruct)のデータを組み合わせたもので、合計で13万以上の例が含まれています。その後、トレーニング後にモデルを検証するために3つのバリデーションスプリット(Seen、Unseen、手作りのHuman prompts)を保持しました。これにより、未知の命令に対する汎化性能をテストすることができました。Human splitは、さらに強力な汎化の課題を提供します。また、複数のLMアーキテクチャ(具体的にはLLaMA-7Bm、デコーダのみのGPTスタイルのモデル、およびFLAN-T5-XXL)を使用し、gistトークンの数(1、2、5、または10)を変えながらgistモデルを訓練しました。しかし、結果は、モデルが一般にgistトークンの数に対して敏感でなく、場合によっては、トークンの数が多いほうがパフォーマンスに悪影響を及ぼすことさえ示していました。したがって、残りの実験には単一のgistモデルを使用しました。 プロンプトの圧縮の品質を評価するために、彼らは陽性コントロールとしてのパフォーマンスを調整し、効果的に標準的な命令微調整を提供し、パフォーマンスの上限を示しました。また、モデルが命令にアクセスできず、ランダムなgistトークンが生成されるネガティブコントロールも使用し、パフォーマンスの下限を示しました。彼らは、モデルの出力を陽性コントロールと比較し、その勝率を測定するためにChatGPTによってどちらの応答がより良いかを選択させ、その理由を説明しました。また、単純な語彙の重複統計であるROUGE-L(オープンエンドの命令微調整で生成されたテキストと人間が書いた命令の類似性を測定する指標)も使用しました。50%の勝率は、プロンプトの圧縮を行わないモデルと同等の品質のモデルであることを示します。 結果は、Seenの指示では、要約モデルが陽性対照モデルに非常に近い勝率を持っていることを示しました。LLaMAは48.6%、FLAN-T5は50.8%の勝率です。さらに重要なことに、要約モデルは未知のプロンプトに対しても競争力のある一般化を示すことができました。LLaMAは49.7%、FLAN-T5は46.2%の勝率です。最も難しいHuman splitでは、わずかな勝率の低下が見られましたが(それでも競争力があります)、LLaMAは45.8%、FLAN-T5は42.5%の勝率です。FLAN-T5のわずかに悪い性能と特定の失敗事例は、将来の論文でさらに検証すべき仮説をもたらしました。 研究者たちはまた、研究の主な動機である要約によって実現できる潜在的な効率の向上も調査しました。その結果は非常に励みになりました。要約キャッシングによってFLOPsが40%削減され、最適化されていないモデルと比較して壁時計時間が4-7%低下しました。これらの改善は、デコーダのみの言語モデルでは小さいとわかりましたが、研究者たちはまた、要約モデルによって未知のプロンプトを26倍圧縮できることを示しました。これにより、入力コンテキストウィンドウにかなりの追加スペースが提供されます。 全体的に、これらの結果は、要約が専門的な言語モデルの有効性と効率を向上させるための大きな潜在能力を示しています。著者たちはまた、要約に関する追加の研究のためのいくつかの有望な方向性を提案しています。例えば、要約から最も大きな計算および効率の利益は、より長いプロンプトの圧縮から得られると述べており、「要約の事前学習」は、まず自然言語の任意の範囲を圧縮することを学習してからプロンプトの圧縮を改善することができると示唆しています。

「ウェブ開発の未来:予測と可能性」
「ウェブ開発の未来を発見しましょう!AI、PWA、VRなどを探求しましょう可能性やウェブ開発者の役割についての洞察を得ましょう」

「パフォーマンスと使いやすさを向上させるための機械学習システムにおけるデザインパターンの探求」
機械学習は、最近の進展と新しいリリースにより、ますます広まっています。AIとMLの人気と需要が高まり、製品レベルのMLモデルの開発が求められる中で、ML関連の問題を特定し、それらに対する解決策を構築することは非常に重要です。デザインパターンは、ML関連の問題の解決策を絞り込むための最良の方法です。パターンのアイデアは、問題を定義し、その問題の詳細な解決策を見つけるのに役立ち、同様の問題に何度でも再利用できます。 デザインパターンは、世界中の実践者が従えるように知識を指示にまとめたものです。さまざまなMLデザインパターンは、MLライフサイクルのさまざまな段階で使用されます。問題の構築、実現可能性の評価、またはMLモデルの開発や展開段階で使用されることもあります。最近、ツイッターのユーザーであるユージン・ヤン氏が、機械学習システムにおけるデザインパターンについての議論を行いました。彼はツイートでいくつかのデザインパターンをリストアップしています。 カスケード:カスケードは、複雑な問題をより単純な問題に分解し、その後のモデルを使用してより困難または具体的な問題に取り組むことを含みます。共有された例では、オンラインコミュニティプラットフォームであるStack Exchangeがスパムに対するカスケードの防御を使用していることが説明されています。スパムの検出と防止のために、複数の保護層が使用されており、各層はスパム検出の異なる側面に焦点を当てています。最初の防御ラインは、人間の可能性を超えて速く投稿された場合(HTTP 429エラー)です。2番目の防御ラインは、正規表現とルールによってキャッチされた場合(ヒューリスティクス)です。3番目の防御ラインは、シャドウテストに基づいた非常に正確なものです(ML)。カスケードは体系的かつ階層的に機能し、効果的なアプローチです。リソースはこちらからご覧ください。 リフレーミング:リフレーミングは、元の問題を再定義して解決しやすくすることを含みます。ツイートで挙げられた例は、大規模な電子商取引プラットフォームであるAlibabaが、次にユーザーが対話する可能性のある次のアイテムを予測するための連続的な推奨に関するパラダイムを再定義していることです。リソースはこちらからご覧ください。 ヒューマンインザループ:これは、ユーザー、アノテーションサービス、またはドメインエキスパートからラベルや注釈を収集し、MLモデルのパフォーマンスを向上させることを含みます。ツイートで言及されている例は、Stack ExchangeとLinkedInで、ユーザーがスパム投稿をフラグ付けできることです。これにより、ユーザーはスパムコンテンツにフィードバックを提供でき、将来のスパム検出のためにMLモデルのトレーニングに使用することができます。リソースはこちらからご覧ください。 データ拡張:これは、トレーニングデータの合成変動を作成し、サイズと多様性を増やしてMLモデルの一般化能力を改善し、オーバーフィッティングのリスクを減らすことを含みます。DoorDashというフードデリバリープラットフォームの例が挙げられており、データ拡張は、トレーニングデータが限られているかデータがない場合に、新しいメニューアイテムの正確な分類とタグ付けに取り組むために使用されています。リソースはこちらからご覧ください。 データフライホイール:これは、より多くのデータの収集がMLモデルの改善につながり、より多くのユーザーとデータを生み出す正のフィードバックループです。Teslaの例が共有されており、同社は車からセンサーデータ、パフォーマンスメトリクス、使用パターンなどのデータを収集しています。このデータは、自動運転などのタスクに使用されるモデルの改善に役立つエラーを特定しラベル付けするために使用されます。リソースはこちらからご覧ください。 ビジネスルール:これには、ドメイン知識やビジネス要件に基づいてMLモデルの出力を増強または調整するためのいくつかの追加ロジックや制約が含まれます。TwitterはMLモデルを使用してエンゲージメントを予測し、タイムラインでツイートの可視性を調整しています。また、MLモデルの出力に対するハンドチューニングされた重みやルールを使用して、意思決定プロセスに知識を組み込んでいます。リソースはこちらからご覧ください。 結果として、機械学習システムのデザインパターンは、モデルのパフォーマンス、信頼性、解釈可能性を向上させ、この領域の課題を解決するのに役立ちます。

「CMUの研究者たちは、TIDEEを提案します:明示的な指示なしで、これまで見たことのない部屋を整理することができる具現化エージェント」
効果的なロボットの運用には、予め決められた命令にただ従うだけでなく、明らかな異常から応答し、不完全な指示から重要な文脈を推論できる必要があります。部分的または自己生成された指示は、環境の物体、物理学、他のエージェントなどがどのように行動するかをしっかり理解することを必要とする推論を必要とします。このタイプの思考と行動は、実世界でロボットが自然に作業し、相互作用するために必要な共通感覚の推論の重要な要素です。 具体的な手順に従うことができる具体的なエージェントに比べて、具体的な共通感覚の思考の分野は遅れています。前者は明示的な指示なしに観察し、行動することを学ばなければなりません。具体的な常識的な思考は、整理するなどのタスクを通じて研究されるかもしれません。このタスクでは、エージェントは間違った場所にあるアイテムを認識し、適切な設定に戻すために修正アクションを行う必要があります。エージェントは、物体を移動させるために探索しながら賢明にナビゲートおよび操作し、現在のシーンで物体が自然な場所から外れていることを認識し、物体を再配置する場所を決定する必要があります。物体配置の常識的な推論と知的な存在の望ましいスキルがこの課題で結びついています。 TIDEEは、ガイダンスなしに以前見たことのないスペースを掃除できると研究チームによって提案された具体的なエージェントです。TIDEEは、シーンをスキャンして、正しい場所にないアイテムを見つけ、それをシーンの適切な場所に移動する方法を見つけることができるため、このようなエージェントは初めてです。 TIDEEは、家の周囲を調査し、配置が間違っているものを見つけ、それらのための可能なオブジェクトのコンテキストを推論し、現在のシーンでそのようなコンテキストを特定し、オブジェクトを正しい場所に戻します。共通の推論は、エージェントの探索を効率的に行うための視覚的な検索ネットワークにエンコードされています。視覚的な意味検出器は、場違いのオブジェクトを検出します。また、オブジェクトの再配置のための適切なセマンティックな受け入れ先と表面を提案する事柄と空間関係の連想ニューラルグラフメモリも存在します。AI2THORシミュレーション環境を使用して、研究者はTIDEEをカオスな環境で掃除させました。TIDEEは、同じ部屋を以前に見たことがなく、別のトレーニングホームの学習からのみ学習した事前知識のみを使用して、ピクセルと生の深さの入力から直接タスクを完了します。人間による部屋のレイアウト変更の評価によれば、一つまたは複数の常識的な事前条件を除外したモデルの実験的なバリエーションよりもTIDEEのパフォーマンスが優れているとされています。 TIDEEは、質問された場所やオブジェクトに事前のガイダンスや先行の接触なしで以前見たことのないスペースをきれいにすることができます。TIDEEは、エリアを見回し、アイテムを識別し、それらを正常または異常としてラベル付けします。TIDEEは、シーングラフと外部グラフメモリ上でグラフ推論を行い、オブジェクトが適切な場所にない場合に受け入れ先のカテゴリを推測します。それから、シーンの空間的セマンティックマップを使用して、受け入れ先カテゴリの可能な場所に画像ベースの検索ネットワークを誘導します。 どのように機能しますか? TIDEEは、3つの異なるステップで部屋を掃除します。TIDEEは、エリアをスキャンし、各タイムステップで異常検出器を実行し、不審なオブジェクトが見つかるまで続行します。それから、TIDEEはアイテムがある場所に移動し、それを取ります。第2のステップでは、TIDEEは、シーングラフと共同外部グラフメモリに基づいてアイテムのための受け入れ先を推測します。コンテナをまだ認識していない場合、TIDEEは、エリアの探索を誘導し、コンテナが見つかる可能性のある場所を示唆します。TIDEEは、以前に識別されたオブジェクトの推定3D重心をメモリに保持し、この情報をナビゲーションとオブジェクトの追跡に使用します。 各アイテムの視覚的属性は、市販のオブジェクト検出器を使用して収集されます。同時に、関係言語の特徴は、オブジェクト間の3D関係(「隣り合っている」、「支持されている」、「上にある」など)のための事前学習された言語モデルの予測をフィードすることによって生成されます。 TIDEEには、オブジェクトが持ち上げられた後に可能なアイテム配置のアイデアを予測するためのニューラルグラフモジュールが含まれています。アイテムの配置、トレーニングシナリオから学習した、コンテキストの接続を保持するメモリグラフ、および現在のシーンでのオブジェクト-関係構成をエンコードするシーングラフが相互作用してモジュールを機能させます。 TIDEEは、セマンティック障害マップと検索カテゴリを与えられた障害マップの各空間点におけるオブジェクトの存在の可能性を予測する光学的検索ネットワークを使用しています。その後、エージェントは、ターゲットが含まれると思われる最も可能性が高い領域を調べます。 TIDEEには2つの欠点がありますが、どちらも将来の研究の明白な方向性です。それはアイテムの開いた状態と閉じた状態を考慮していないこと、また混沌とした再構築プロセスの一部としてそれらの3Dの姿勢を含んでいないことです。 部屋に物を乱雑に散らばらせることから生じる混沌は、現実の混沌を代表している可能性があります。 TIDEEは、以前に同じ部屋を見たことがなく、ピクセルと生の深度入力のみを使用して作業を完了し、異なるトレーニングホームのコレクションから学習した先行知識のみを使用します。結果の部屋のレイアウト変更の人間による評価によれば、TIDEEは、一つ以上の常識的な先行知識を除外したモデルの劣化変種よりも優れたパフォーマンスを発揮します。単純化されたモデルバージョンは、比較可能な部屋の再配置ベンチマークで最も優れた解決策を大幅に上回り、エージェントが再配置前の目的の状態を観察することを可能にします。

USCの研究者は、新しい共有知識生涯学習(SKILL)チャレンジを提案しましたこのチャレンジでは、分散型のLLエージェントの集団が展開され、各エージェントが個別に異なるタスクを順次学習し、全てのエージェントが独立かつ並行して動作します
研究者による画期的な取り組みにより、共有知識生涯学習(SKILL)の開発を通じて機械学習の新時代が到来しました。最近発表された「Transactions on Machine Learning Research」誌の論文で、研究者はこの革新的なアプローチがAIエージェントが複数のタスクから知識を継続的に学習し保持することを可能にする方法を示し、人工知能の変革的な進歩を提供しています。 従来の機械学習は、タスク学習の連続プロセスを伴い、遅くて時間のかかる結果になることが多かったです。しかし、SKILLは並列学習アルゴリズムを用いることにより、革新的な概念を導入しています。このアプローチでは、102のAIエージェントのそれぞれに特定のタスクが割り当てられます。それぞれが専門分野での専門知識を習得した後、彼らは他のエージェントと知識を共有し、効率的なコミュニケーションと知識の統合を通じて全体の学習時間を大幅に短縮します。 研究者たちは、SKILLが生涯学習の将来の進歩に非常に有望であると考えています。彼らの研究には多くの自然なタスクが含まれており、顕著なスケーラビリティのポテンシャルが示されています。彼らは、SKILLがまもなく何千、あるいは何百万ものタスクを包括することができ、日常生活を変革する可能性があると想像しています。 例えば、異なるAIシステムが医療分野の異なる疾患、治療、患者ケア技術、最新の研究などについて学習することができます。その知識を統合した後、これらのAIエージェントは医学のあらゆる領域で最新かつ最も正確な情報を提供し、医師に包括的な医療助手として役立ちます。SKILLの統合により、医療は前例のない高みに到達し、医療専門家に比類ないサポートと専門知識を提供することができるでしょう。 医学に限らず、SKILLの潜在的な応用範囲はさまざまな領域に及びます。新しい街を訪れる際、すべてのスマートフォンユーザーが現地の観光ガイドとして活躍する未来を想像してみてください。カメラとランドマーク、店舗、製品、地元の料理に関する豊富な情報を備えた状態で、各ユーザーは広範な知識のリポジトリに貢献します。このデータがSKILLネットワーク全体で共有されると、すべてのユーザーは先進的なデジタルツアーガイドを手のひらで利用できるようになります。 SKILLの能力は、単なる認識に基づくタスクを超えます。現実世界の問題の複雑さが増すにつれて、解決策には多様な分野の専門知識が必要とされることがよくあります。SKILLは、AIエージェントが協力し、独自の洞察力と知識を結集して多様な課題に取り組むことを可能にします。 SKILLのコンセプトはクラウドソーシングに似ており、集合的な取り組みが個々の能力を超えた解決策を生み出します。オンラインのレビューが多くの人々の知識を集約して有益な情報を提供するように、SKILLはAIエージェントが情報を共有し、より包括的かつ正確な結論に至ることを可能にします。 このAIの革新的なブレイクスルーは、機械の持続的な学習と適応の追求において重要な一歩です。共有知識を受け入れることにより、AIエージェントは限られた専門知識の壁に閉じ込められることなく、自らのタスクの枠組みを超えることができるのです。要するに、研究者たちは、AIエージェントが連携ネットワークとして働き、人類につながりのある、知識豊富な、効率的なグローバルコミュニティを提供する未来を育んでいます。機械の集合知が進歩とイノベーションを牽引する世界です。 研究が進むにつれて、調和して連携する相互接続されたAIエージェントの世界のビジョンはますます具体的になってきます。潜在的な利益は広範囲にわたり、多くの分野に触れ、技術とのインタラクションの方法を革新しています。SKILLを触媒として、AIは知識に制約がなくなり、協力がスマートかつ効率的な世界の基盤となる未来へと私たちを推進する準備が整っています。

学習率のチューニングにうんざりしていますか?DoGに会ってみてください:堅牢な理論的保証に裏打ちされたシンプルでパラメータフリーの最適化手法
テルアビブ大学の研究者は、学習率パラメータを必要とせず、経験的な量のみに依存する調整フリーの動的SGDステップサイズ公式である「Distance over Gradients(DoG)」を提案しています。彼らは理論的に、DoG公式のわずかな変動が局所的にバウンドした確率的勾配の収束をもたらすことを示しています。 確率的プロセスには最適化されたパラメータが必要であり、学習率は依然として困難です。従来の成功した手法には、先行研究から適切な学習率を選択する方法が含まれます。適応的勾配法のような手法では、学習率パラメータを調整する必要があります。パラメータフリーの最適化では、問題の事前知識なしにほぼ最適な収束率を達成するためにアルゴリズムが設計されています。 テルアビブ大学の研究者は、CarmonとHinderの重要な知見を取り入れ、パラメータフリーのステップサイズスケジュールを開発しました。彼らはDoGを反復することで、DoGが対数的な収束率を達成する確率が高いことを示しています。ただし、DoGは常に安定しているわけではありません。その反復は最適化から遠ざかることもあります。そこで、彼らはDoGの変種である「T-DoG」を使用し、ステップサイズを対数的な因子で小さくします。これにより、収束が保証される高い確率を得ます。 彼らの結果は、SGDと比較して、コサインステップサイズスケジュールとチューニングベースの学習を使用する場合、DoGは稀に相対誤差の改善率が5%を超えることはほとんどありませんが、凸問題の場合、誤差の相対差は1%以下であり、驚くべきことです。彼らの理論はまた、DoGが感度の広範な範囲で一貫して実行されることを予測しています。研究者はまた、近代的な自然言語理解(NLU)におけるDoGの効率をテストするために、調整されたトランスフォーマーランゲージモデルを使用しました。 研究者はまた、下流タスクとしてImageNetを使用した主なファインチューニングテストベッドで限定的な実験を行いました。これらはスケールが大きくなるにつれてチューニングがよりコストがかかります。彼らはCLIPモデルをファインチューニングし、それをDoGとL-DoGと比較しました。両方のアルゴリズムは著しく悪い結果を示しました。これは反復予算が不十分なためです。 研究者は、多項式平均化を使用してモデルをゼロからトレーニングする実験も行いました。DoGは、適応勾配法と比較して、運動量0.9と学習率0.1の条件で優れたパフォーマンスを発揮します。他のチューニングフリーメソッドと比較して、DoGとL-DoGはほとんどのタスクでより優れたパフォーマンスを提供します。 DoGの結果は有望ですが、これらのアルゴリズムにはさらなる追加作業が必要です。運動量、事前パラメータ学習率、学習率のアニーリングなど、確立された技術をDoGと組み合わせる必要があります。これは理論的にも実験的にも困難です。彼らの実験は、バッチ正規化との関連性を示唆しており、頑健なトレーニング方法にもつながる可能性があります。 最後に、彼らの理論と実験は、DoGが現在の学習率チューニングに費やされている膨大な計算を、ほぼパフォーマンスにコストをかけずに節約する可能性を示唆しています。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.