Learn more about Search Results VICE - Page 73

- You may be interested
- 🤗 Transformersにおいて制約付きビームサ...
- LLM幻覚を軽減する方法
- ストラテゴをマスターする:情報の不完全...
- PyTorchモデルのパフォーマンス分析と最適...
- 「Pythonでのプロトコル」
- なぜ次のCFOはデータサイエンティストであ...
- 「今日のビジネスの風景におけるプロフェ...
- 大規模言語モデルにおけるより高い自己一...
- テスト自動化のためのトップ5のAIパワード...
- 「人工知能の炭素足跡」
- 情報セキュリティ:IoT業界内のAIセキュリ...
- 空気圧アクチュエータは、ロボットにチー...
- データ分析におけるサンプリング技術
- 自然言語処理のタクソノミー
- コードの解読:機械学習が故障診断と原因...
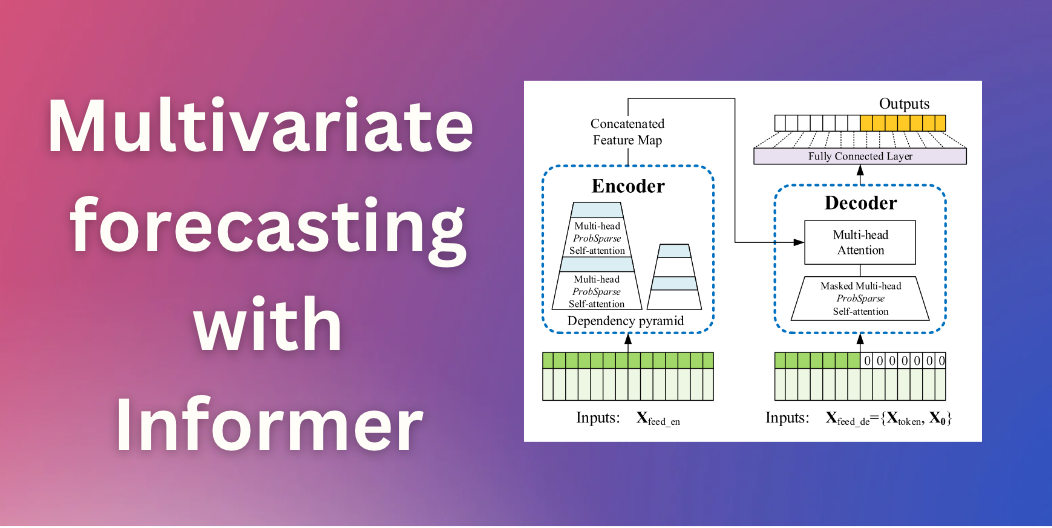
Informerを使用した多変量確率時系列予測
イントロダクション 数ヶ月前、私たちはTime Series Transformerを紹介しました。これは、予測に適用されたバニラTransformer(Vaswani et al.、2017)であり、単一変量の確率的予測課題(つまり、各時系列の1次元分布を個別に予測すること)の例を示しました。この記事では、現在🤗 Transformersで利用可能な、AAAI21のベストペーパーであるInformerモデル(Zhou, Haoyi, et al., 2021)を紹介します。これを使用して、多変量の確率的な予測課題、つまり、将来の時系列ターゲット値のベクトルの分布を予測する方法を示します。なお、バニラのTime Series Transformerモデルにも同様に適用できます。 多変量確率時系列予測 確率予測のモデリングの観点からは、Transformer/Informerは多変量時系列に対して取り扱う際に変更を必要としません。単変量と多変量の設定の両方で、モデルはベクトルのシーケンスを受け取り、唯一の変更は出力またはエミッション側にあります。 高次元データの完全な結合条件付き分布をモデリングすると、計算コストが高くなる場合があります。そのため、データを同じファミリーからの独立した分布、または完全な共分散の低ランク近似など、いくつかの近似手法に頼ることがあります。ここでは、実装した分布のファミリーに対してサポートされている独立(または対角)エミッションに頼ることにします。 Informer – 内部構造 バニラTransformer(Vaswani et al.、2017)に基づいて、Informerは2つの主要な改善を採用しています。これらの改善を理解するために、バニラTransformerの欠点を思い出してみましょう。 正準自己注意の二次計算:バニラTransformerは、計算量がO (…

Hugging FaceとFlowerを使用したフェデレーテッドラーニング
このチュートリアルでは、Hugging Faceを使用して、Flowerを介して複数のクライアント上で言語モデルのトレーニングをフェデレートする方法を紹介します。具体的には、IMDBの評価データセットを使用して、事前トレーニングされたTransformerモデル(distilBERT)をシーケンス分類のために微調整します。最終的な目標は、映画の評価がポジティブかネガティブかを検出することです。 ノートブックはこちらでご利用いただけますが、複数のクライアントで実行する代わりに、Google Colab内でフェデレーテッド環境をエミュレートするためにFlowerのシミュレーション機能(flwr['simulation'])を使用します(これはまた、start_serverを呼び出す代わりにstart_simulationを呼び出す必要があり、その他の変更が必要です)。 依存関係 このチュートリアルに従うためには、以下のパッケージをインストールする必要があります:datasets、evaluate、flwr、torch、およびtransformers。これはpipを使用して行うことができます: pip install datasets evaluate flwr torch transformers 標準的なHugging Faceのワークフロー データの処理 IMDBデータセットを取得するために、Hugging Faceのdatasetsライブラリを使用します。その後、データをトークン化し、PyTorchのデータローダーを作成する必要があります。これはすべてload_data関数で行われます: import random import torch from datasets…

トランスフォーマーによるグラフ分類
前回のブログでは、グラフ上での機械学習の理論的な側面について調査しました。このブログでは、Transformersライブラリを使用してグラフ分類を行う方法について調査します(デモノートブックをここからダウンロードして一緒に進めることもできます!) 現時点では、Transformersで利用できる唯一のグラフトランスフォーマーモデルはMicrosoftのGraphormerですので、こちらを使用します。他のモデルも使用して統合する人々がどのような結果を出すか楽しみにしています 🤗 必要条件 このチュートリアルに従うためには、datasetsとtransformers(バージョン>= 4.27.2)がインストールされている必要があります。これはpip install -U datasets transformersで行うことができます。 データ グラフデータを使用するためには、独自のデータセットから始めるか、Hubで利用可能なデータセットを使用することができます。既に利用可能なデータセットを使用することに焦点を当てますが、自分のデータセットを追加することも自由です! 読み込み Hubからのグラフデータセットの読み込みは非常に簡単です。まず、ogbg-mohivデータセット(StanfordのOpen Graph Benchmarkのベースライン)をロードしましょう。これはOGBリポジトリに保存されています: from datasets import load_dataset # Hubには1つのスプリットしかありません dataset =…
AWS Inferentia2を使用してHugging Face Transformersを高速化する
過去5年間、Transformerモデル[1]は、自然言語処理(NLP)、コンピュータビジョン(CV)、音声など、多くの機械学習(ML)タスクのデファクトスタンダードとなりました。今日、多くのデータサイエンティストやMLエンジニアは、BERT[2]、RoBERTa[3]、Vision Transformer[4]などの人気のあるTransformerアーキテクチャ、またはHugging Faceハブで利用可能な130,000以上の事前学習済みモデルを使用して、最先端の精度で複雑なビジネス問題を解決するために頼っています。 しかし、その優れた性能にもかかわらず、Transformerは本番環境での展開には困難を伴うことがあります。モデル展開に通常関連するインフラストラクチャの設定に加えて、我々はInference Endpointsサービスで大部分の問題を解決しましたが、Transformerは通常、数ギガバイトを超える大きなモデルです。GPT-J-6B、Flan-T5、Opt-30Bなどの大規模言語モデル(LLM)は数十ギガバイトであり、BLOOMなどの巨大なモデルは350ギガバイトもあります。 これらのモデルを単一のアクセラレータに適合させることは非常に困難ですし、会話型アプリケーションや検索のようなアプリケーションが必要とする高スループットと低推論レイテンシを実現することはさらに難しいです。MLの専門家たちは、大規模モデルをスライスし、アクセラレータクラスタに分散させ、レイテンシを最適化するために複雑な手法を設計してきました。残念ながら、この作業は非常に困難で時間がかかり、多くのMLプラクティショナーには到底手の届かないものです。 Hugging Faceでは、MLの民主化を進めるとともに、すべての開発者と組織が最先端のモデルを利用できるようにすることを目指しています。そのため、今回はAmazon Web Servicesと提携し、Hugging Face TransformersをAWS Inferentia 2に最適化することに興奮しています!これは、前例のないスループット、レイテンシ、パフォーマンス、スケーラビリティを提供する新しい特別な推論アクセラレータです。 AWS Inferentia2の紹介 AWS Inferentia2は、2019年に発売されたInferentia1の次世代です。Inferentia1のパワーにより、Amazon EC2 Inf1インスタンスは、NVIDIA A10G GPUをベースとしたG5インスタンスと比較して、スループットが25%向上し、コストが70%削減されました。そして、Inferentia2により、AWSは再び限界を em>押し広げています。 新しいInferentia2チップは、Inferentiaと比較してスループットが4倍向上し、レイテンシが10倍低下します。同様に、新しいAmazon…

フリーティアのGoogle Colabで🧨ディフューザーを使用してIFを実行中
要約:Google Colabの無料ティア上で最も強力なオープンソースのテキストから画像への変換モデルIFを実行する方法を紹介します。 また、Hugging Face Spaceでモデルの機能を直接探索することもできます。 公式のIF GitHubリポジトリから圧縮された画像。 はじめに IFは、ピクセルベースのテキストから画像への生成モデルで、DeepFloydによって2023年4月下旬にリリースされました。モデルのアーキテクチャは、GoogleのクローズドソースのImagenに強く影響を受けています。 IFは、Stable Diffusionなどの既存のテキストから画像へのモデルと比較して、次の2つの利点があります: モデルは、レイテントスペースではなく「ピクセルスペース」(つまり、非圧縮画像上で)で直接動作し、Stable Diffusionのようなノイズ除去プロセスを実行しません。 モデルは、Stable Diffusionでテキストエンコーダとして使用されるCLIPよりも強力なテキストエンコーダであるT5-XXLの出力で訓練されます。 その結果、IFは高周波の詳細(例:人の顔や手など)を持つ画像を生成する能力に優れており、信頼性のあるテキスト付き画像を生成できる最初のオープンソースの画像生成モデルです。 ピクセルスペースで動作し、より強力なテキストエンコーダを使用することのデメリットは、IFが大幅に多くのパラメータを持っていることです。T5、IFのテキストから画像へのUNet、IFのアップスケーラUNetは、それぞれ4.5B、4.3B、1.2Bのパラメータを持っています。それに対して、Stable Diffusion 2.1のテキストエンコーダとUNetは、それぞれ400Mと900Mのパラメータしか持っていません。 しかし、メモリ使用量を低減させるためにモデルを最適化すれば、一般のハードウェア上でもIFを実行することができます。このブログ記事では、🧨ディフューザを使用してその方法を紹介します。 1.)では、テキストから画像への生成にIFを使用する方法を説明し、2.)と3.)では、IFの画像バリエーションと画像インペインティングの機能について説明します。 💡 注意:メモリの利得と引き換えに速度の利得を得るために、IFを無料ティアのGoogle Colab上で実行できるようにしています。A100などの高性能なGPUにアクセスできる場合は、公式のIFデモのようにすべてのモデルコンポーネントをGPU上に残して、最大の速度で実行することをお勧めします。…

StarCoder:コードのための最先端のLLM
StarCoderの紹介 StarCoderとStarCoderBaseは、GitHubからの許可を得たデータを使用してトレーニングされた大規模な言語モデルです。これらのモデルは、80以上のプログラミング言語、Gitのコミット、GitHubの課題、Jupyterノートブックなど、様々な情報源からデータを取得しています。LLaMAと同様に、私たちは1兆トークンのために約15兆パラメータのモデルをトレーニングしました。また、35兆のPythonトークンに対してStarCoderBaseモデルを微調整し、新しいモデルであるStarCoderと呼びます。 StarCoderBaseは、人気のあるプログラミングベンチマークにおいて既存のオープンなコードモデルよりも優れたパフォーマンスを発揮し、GitHub Copilotの初期バージョンで使用された「code-cushman-001」といったクローズドモデルとも匹敵する結果を示しました。StarCoderモデルは、8,000以上のトークンのコンテキスト長を持つため、他のオープンなLLMよりも多くの入力を処理することができます。これにより、さまざまな興味深いアプリケーションが可能となります。例えば、StarCoderモデルに対して対話のシリーズをプロンプトとして与えることで、技術アシスタントとしての機能を果たすことができます。さらに、これらのモデルはコードの自動補完、指示に基づいたコードの変更、コードスニペットの自然言語による説明などにも使用することができます。私たちは、改善されたPIIの削除パイプライン、新しい帰属追跡ツールなど、安全なオープンモデルのリリースに向けていくつかの重要な手順を踏んでいます。また、StarCoderは改良されたOpenRAILライセンスのもとで一般に公開されています。この更新されたライセンスにより、企業がモデルを製品に統合するプロセスが簡素化されます。StarCoderモデルの強力なパフォーマンスにより、コミュニティは自分たちのユースケースや製品に適応させるための堅固な基盤としてこれを活用することができると考えています。 評価 私たちはStarCoderといくつかの類似モデルについて、さまざまなベンチマークで徹底的に評価を行いました。人気のあるPythonベンチマークであるHumanEvalでは、関数のシグネチャとドキュメント文字列に基づいてモデルが関数を完成させることができるかどうかをテストしました。StarCoderとStarCoderBaseは、PaLM、LaMDA、LLaMAなどの最大のモデルを上回るパフォーマンスを発揮しましたが、それらよりも遥かに小さなサイズであるという特徴も持っています。また、CodeGen-16B-MonoやOpenAIのcode-cushman-001(12B)モデルよりも優れた結果を示しました。私たちはまた、モデルの失敗例として、通常は練習の一部として使用されるため、# Solution hereというコードを生成することがあることに気付きました。実際の解決策を生成させるために、プロンプトとして<filename>solutions/solution_1.py\n# Here is the correct implementation of the code exerciseを追加しました。これにより、StarCoderのHumanEvalスコアは34%から40%以上に向上し、オープンモデルの最新のベンチマーク結果を更新しました。CodeGenとStarCoderBaseに対してもこのプロンプトを試しましたが、あまり違いは観察されませんでした。 StarCoderの興味深い特徴の一つは、多言語対応であることです。そのため、MultiPL-Eという多言語の拡張を使用して評価を行いました。その結果、StarCoderは多くの言語においてcode-cushman-001と匹敵または優れたパフォーマンスを発揮することがわかりました。また、DS-1000というデータサイエンスのベンチマークでも、StarCoderは他のオープンアクセスモデルを圧倒する結果を示しました。しかし、コード補完以外にもモデルができることを見てみましょう! 技術アシスタント 徹底的な評価の結果、StarCoderはコードの記述に非常に優れていることがわかりました。しかし、ドキュメンテーションやGitHubの課題などの情報を大量に学習しているため、技術アシスタントとして使用できるかどうかもテストしたかったのです。AnthropicのHHHプロンプトに触発されて、私たちはTech Assistant Promptを作成しました。驚くべきことに、プロンプトだけでモデルは技術アシスタントとして機能し、プログラミングに関連する要求に答えることができます! トレーニングデータ このモデルは、The…

アシストされた生成:低遅延テキスト生成への新たな方向
大規模な言語モデルは最近注目を集めており、多くの企業がそれらを拡大し、新たな機能を開放するために多大なリソースを投資しています。しかし、私たち人間は注意力が減少しているため、彼らの遅い応答時間も嫌いです。レイテンシは良好なユーザーエクスペリエンスにおいて重要であり、低品質なものである場合でも(たとえば、コード補完において)小さいモデルが使用されることがよくあります。 なぜテキスト生成は遅いのでしょうか?破産せずに低レイテンシな大規模な言語モデルを展開する障害物は何でしょうか?このブログ記事では、自己回帰的なテキスト生成のボトルネックを再検討し、レイテンシの問題に対処するための新しいデコーディング手法を紹介します。私たちの新しい手法であるアシスト付き生成を使用することで、コモディティハードウェアでレイテンシを最大10倍まで削減できることがわかります! テキスト生成のレイテンシの理解 現代のテキスト生成の核心は理解しやすいです。中心となる部分であるMLモデルを見てみましょう。その入力には、これまでに生成されたテキストや、モデル固有のコンポーネント(Whisperのようなオーディオ入力もあります)など、テキストシーケンスが含まれます。モデルは入力を受け取り、順番に各層を通って次のトークンの非正規化された対数確率(ログット)を予測します。トークンは、モデルによって単語全体、サブワード、または個々の文字で構成されることがあります。テキスト生成のこの部分について詳しく知りたい場合は、イラスト付きのGPT-2を参照してください。 モデルの順方向パスによって次のトークンのログットが得られますが、これらのログットを自由に操作することができます(たとえば、望ましくない単語やシーケンスの確率を0に設定する)。テキスト生成の次のステップは、これらのログットから次のトークンを選択することです。一般的な戦略は、最も可能性の高いトークンを選ぶことで、これはグリーディデコーディングとして知られています。また、トークンの分布からサンプリングすることも行います。モデルの順方向パスと次のトークンの選択を反復的に連結することで、テキスト生成が行われます。デコーディング手法に関しては、この説明はアイスバーグの一角に過ぎません。詳細な探求のために、テキスト生成に関する当社のブログ記事を参照してください。 上記の説明から、テキスト生成のレイテンシのボトルネックは明確です。大規模なモデルの順方向パスを実行することは遅いため、連続して何百回も実行する必要があります。しかし、さらに詳しく見てみましょう。なぜ順方向パスが遅いのでしょうか?順方向パスは通常、行列の乗算によって支配されます。対応するウィキペディアのセクションを素早く訪れると、この操作における制限はメモリ帯域幅であることがわかります(たとえば、GPU RAMからGPUコンピュートコアへ)。つまり、順方向パスのボトルネックは、デバイスの計算コアにモデルのレイヤーの重みを読み込むことから来ており、計算自体ではありません。 現時点では、テキスト生成の最大の効果を得るために探求できる3つの主な方法がありますが、すべてがモデルの順方向パスのパフォーマンスに対処しています。まず第一に、ハードウェア固有のモデルの最適化があります。たとえば、デバイスがFlash Attentionに対応している場合、操作の並べ替えによってアテンションレイヤーの処理を高速化することができます。また、モデルのウェイトのサイズを削減するINT8量子化もあります。 第二に、同時にテキスト生成のリクエストがあることがわかっている場合、入力をバッチ化し、小さなレイテンシのペナルティを支払いながらスループットを大幅に増加させることができます。デバイスに読み込まれたモデルのレイヤーのウェイトは、複数の入力行で並列に使用されるため、ほぼ同じメモリ帯域幅の負荷でより多くのトークンを出力することができます。バッチ処理の問題は、追加のデバイスメモリが必要であることです(またはメモリをどこかにオフロードする必要があります)-このスペクトルの終端では、レイテンシを犠牲にしてスループットを最適化するFlexGenなどのプロジェクトが見られます。 # バッチ化された生成の影響を示す例。計測デバイス: RTX3090 from transformers import AutoModelForCausalLM, AutoTokenizer import time tokenizer = AutoTokenizer.from_pretrained("distilgpt2") model…

単一のGPUでChatgptのようなチャットボットをROCmで実行する
はじめに ChatGPTは、OpenAIの画期的な言語モデルであり、人工知能の領域で影響力のある存在となり、様々なセクターでAIアプリケーションの多様な活用を可能にしています。その驚異的な人間のようなテキストの理解力と生成力により、ChatGPTは顧客サポートから創造的な文章作成まで、さまざまな産業を変革し、貴重な研究ツールとしても使われています。 OPT、LLAMA、Alpaca、Vicunaなど、大規模な言語モデルのオープンソース化にはさまざまな取り組みが行われていますが、その中でもVicunaはAMD GPU上でROCmを使用してVicuna 13Bモデルを実行する方法を説明します。 Vicunaとは何ですか? Vicunaは、UCバークレー、CMU、スタンフォード、UCサンディエゴのチームによって開発された13兆パラメータを持つオープンソースのチャットボットです。Vicunaは、LLAMAベースモデルを使用して、ShareGPT.comからの約70,000件のユーザー共有会話を収集し、公開APIを介してファインチューニングしました。GPT-4を参照とした初期の評価では、Vicuna-13BはOpenAI ChatGPTと比較して90%以上の品質を実現しています。 それはわずか数週間前の4月11日にGithubでリリースされました。Vicunaのデータセット、トレーニングコード、評価メトリック、トレーニングコストはすべて公開されており、一般のユーザーにとって費用対効果の高いソリューションとなっています。 Vicunaの詳細については、https://vicuna.lmsys.org をご覧ください。 なぜ量子化されたGPTモデルが必要なのですか? Vicuna-13Bモデルをfp16で実行するには、約28GBのGPU RAMが必要です。メモリの使用量をさらに減らすためには、最適化技術が必要です。最近発表された研究論文「GPTQ」では、低ビット精度を持つGPTモデルの正確な事後トレーニング量子化が提案されています。以下の図に示すように、パラメータが10Bを超えるモデルの場合、4ビットまたは3ビットのGPTQはfp16と同等の精度を実現することができます。 さらに、これらのモデルの大きなパラメータは、GPTトークン生成が計算(TFLOPsまたはTOPs)そのものよりもメモリ帯域幅(GB/s)によって制約されるため、GPTのレイテンシに深刻な影響を与えます。そのため、メモリに制約のある状況下では、量子化モデルはトークン生成のレイテンシを低下させません。GPTQの量子化の論文とGitHubリポジトリを参照してください。 この技術を活用することで、Hugging Faceからいくつかの4ビット量子化されたVicunaモデルが利用可能です。 ROCmを使用してAMD GPUでVicuna 13Bモデルを実行する AMD GPUでVicuna 13Bモデルを実行するには、AMD GPUの高速化のためのオープンソースソフトウェアプラットフォームであるROCm(Radeon…

bitsandbytes、4ビットの量子化、そしてQLoRAを使用して、LLMをさらに利用しやすくする
LLMは大きいことで知られており、一般のハードウェア上で実行またはトレーニングすることは、ユーザーにとって大きな課題であり、アクセシビリティも困難です。私たちのLLM.int8ブログポストでは、LLM.int8論文の技術がtransformersでどのように統合され、bitsandbytesライブラリを使用しているかを示しています。私たちは、モデルをより多くの人々にアクセス可能にするために、再びbitsandbytesと協力することを決定し、ユーザーが4ビット精度でモデルを実行できるようにしました。これには、テキスト、ビジョン、マルチモーダルなどの異なるモダリティの多くのHFモデルが含まれます。ユーザーはまた、Hugging Faceのエコシステムからのツールを活用して4ビットモデルの上にアダプタをトレーニングすることもできます。これは、DettmersらによるQLoRA論文で今日紹介された新しい手法です。論文の概要は以下の通りです: QLoRAは、1つの48GBのGPUで65Bパラメータモデルをフィントゥーニングするためのメモリ使用量を十分に削減しながら、完全な16ビットのフィントゥーニングタスクのパフォーマンスを維持する効率的なフィントゥーニングアプローチです。QLoRAは、凍結された4ビット量子化された事前学習言語モデルをLow Rank Adapters(LoRA)に逆伝搬させます。私たちの最高のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達しますが、1つのGPUでのフィントゥーニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています:(a)通常分布された重みに対して情報理論的に最適な新しいデータ型である4ビットNormalFloat(NF4)(b)量子化定数を量子化して平均メモリフットプリントを減らすためのダブル量子化、および(c)メモリスパイクを管理するためのページドオプティマイザ。私たちはQLoRAを使用して1,000以上のモデルをフィントゥーニングし、高品質のデータセットを使用した指示の追跡とチャットボットのパフォーマンスの詳細な分析を提供しています。これは通常のフィントゥーニングでは実行不可能である(例えば33Bおよび65Bパラメータモデル)モデルタイプ(LLaMA、T5)とモデルスケールを横断したものです。私たちの結果は、QLoRAによる小規模な高品質データセットでのフィントゥーニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。さらに、ヒューマンとGPT-4の評価に基づいてチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価がヒューマンの評価に対して安価で合理的な代替手段であることを示しています。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するための信頼性がないことがわかります。レモンピックされた分析では、GuanacoがChatGPTに比べてどこで失敗するかを示しています。私たちは4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 リソース このブログポストとリリースには、4ビットモデルとQLoRAを始めるためのいくつかのリソースがあります: 元の論文 基本的な使用法Google Colabノートブック-このノートブックでは、4ビットモデルとその変種を使用した推論の方法、およびGoogle ColabインスタンスでGPT-neo-X(20Bパラメータモデル)を実行する方法を示しています。 フィントゥーニングGoogle Colabノートブック-このノートブックでは、Hugging Faceエコシステムを使用してダウンストリームタスクで4ビットモデルをフィントゥーニングする方法を示しています。Google ColabインスタンスでGPT-neo-X 20Bをフィントゥーニングすることが可能であることを示しています。 論文の結果を再現するための元のリポジトリ Guanaco 33b playground-または以下のプレイグラウンドセクションをチェック はじめに モデルの精度と最も一般的なデータ型(float16、float32、bfloat16、int8)について詳しく知りたくない場合は、これらの概念の詳細について視覚化を含めた簡単な言葉で説明している私たちの最初のブログポストの紹介を注意深くお読みいただくことをお勧めします。 詳細については、このwikibookドキュメントを通じて浮動小数点表現の基本を読むことをお勧めします。 最近のQLoRA論文では、4ビットFloatと4ビットNormalFloatという異なるデータ型を探求しています。ここでは、理解しやすい4ビットFloatデータ型について説明します。…

Amazon SageMakerのHugging Face LLM推論コンテナをご紹介します
これは、オープンソースのLLM(Large Language Model)であるBLOOMをAmazon SageMakerに展開し、新しいHugging Face LLM Inference Containerを使用して推論を行う方法の例です。Open Assistantデータセットで訓練されたオープンソースのチャットLLMである12B Pythia Open Assistant Modelを展開します。 この例では以下の内容をカバーしています: 開発環境のセットアップ 新しいHugging Face LLM DLCの取得 Open Assistant 12BのAmazon SageMakerへの展開 モデルを使用して推論およびチャットを行う…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.