Learn more about Search Results MPT - Page 73

- You may be interested
- 「ChatGPT Meme Creator Pluginを使ってミ...
- 「AIの責任ある適用を促進するための社会...
- 「医療機械学習におけるバイアスのある臨...
- 『ご要望に合わせたチャット:ソフトウェ...
- データ分析の仕事のトレンド:パート2
- 「不確定性pyと混沌pyを用いた多項式混沌...
- このAI論文では、GraphGPTフレームワーク...
- 「取得した文書の圧縮は言語モデルのパフ...
- パイプラインの夢:AWSでのMLトレーニング...
- トップAIメールアシスタント(2023年11月)
- イェール大学とGoogle DeepMindの研究者は...
- NLP で仕事検索を強化しましょう
- 「非構造化データ内のデータスライスの検...
- 『ジェネラティブAIの電力消費の定量化』
- 3Dボディモデルに音声が付きました:Meta ...

ディフューザを使用してControlNetをトレーニングしてください
イントロダクション ControlNetは、追加の条件を付加することで拡散モデルを細かく制御することができるニューラルネットワーク構造です。この技術は、「Adding Conditional Control to Text-to-Image Diffusion Models」という論文で登場し、すぐにオープンソースの拡散コミュニティで広まりました。著者はStable Diffusion v1-5を制御するための8つの異なる条件をリリースしました。これには、ポーズ推定、深度マップ、キャニーエッジ、スケッチなどが含まれます。 このブログ投稿では、3Dシンセティックフェイスに基づいた顔のポーズモデルであるUncanny Facesモデルのトレーニング手順を詳細に説明します(実際にはUncanny Facesは予期しない結果であり、それがどのように実現されたかについては後ほどご紹介します)。 安定した拡散のためのControlNetのトレーニングの始め方 独自のControlNetをトレーニングするには、3つのステップが必要です: 条件の計画:ControlNetはStable Diffusionをさまざまなタスクに対応できる柔軟性があります。事前にトレーニングされたモデルはさまざまな条件を示しており、コミュニティはピクセル化されたカラーパレットに基づいた他の条件を作成しています。 データセットの構築:条件が決まったら、データセットの構築の時間です。そのためには、データセットをゼロから構築するか、既存のデータセットの一部を使用することができます。モデルをトレーニングするためには、データセットには3つの列が必要です:正解のimage、conditioning_image、およびprompt。 モデルのトレーニング:データセットの準備ができたら、モデルのトレーニングの時間です。これは、ディフューザーのトレーニングスクリプトのおかげで最も簡単な部分です。少なくとも8GBのVRAMを持つGPUが必要です。 1. 条件の計画 条件を計画するために、次の2つの質問を考えると役立ちます: どのような条件を使用したいですか? 既存のモデルで「通常の」画像を私の条件に変換できるものはありますか?…
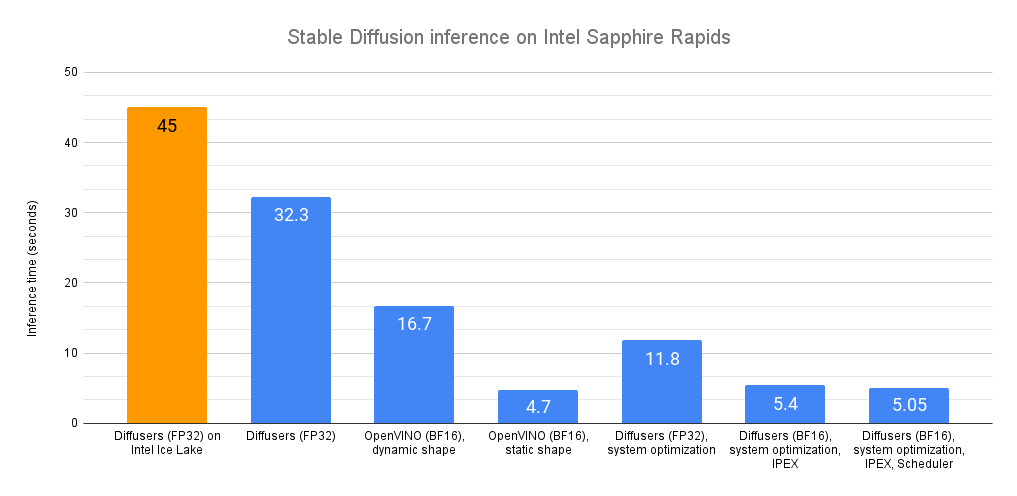
Intel CPU上での安定な拡散推論の高速化
最近、私たちは最新世代のIntel Xeon CPU(コードネームSapphire Rapids)を紹介しました。これには、ディープラーニングの高速化に対応した新しいハードウェア機能があります。また、これらを使用して自然言語処理のトランスフォーマーの分散微調整と推論を加速する方法も紹介しました。 この投稿では、Sapphire Rapids CPU上で安定拡散モデルを加速するための異なる技術を紹介します。次の投稿では、分散微調整について同様の内容を紹介します。 執筆時点では、Sapphire Rapidsサーバーにアクセスする最も簡単な方法は、Amazon EC2 R7izインスタンスファミリーを使用することです。まだプレビュー段階ですので、アクセスするためにはサインアップする必要があります。前の投稿と同様に、私はUbuntu 20.04 AMI(ami-07cd3e6c4915b2d18)を使用してr7iz.metal-16xlインスタンス(64 vCPU、512GB RAM)を使用しています。 さあ、始めましょう!コードサンプルはGitlabで利用できます。 Diffusersライブラリ Diffusersライブラリは、安定拡散モデルを使用して画像を生成するのが非常に簡単です。これらのモデルに詳しくない場合は、こちらの素晴らしいイラスト入りの紹介をご覧ください。 まず、必要なライブラリ(Transformers、Diffusers、Accelerate、PyTorch)を使用して仮想環境を作成しましょう。 virtualenv sd_inference source sd_inference/bin/activate pip…

中国語話者向けのHuggingFaceブログをご紹介します:中国のAIコミュニティとの協力の促進
この記事は、中国語の 简体中文 でもご覧いただけます。 中国語話者向けのブログへようこそ! Hugging Faceの新しい中国語話者向けブログ hf.co/blog/zh をご紹介いたします!献身的なボランティアのグループが、ブログ投稿やトランスフォーマー、ディフュージョン、強化学習に関する包括的なコースなど、私たちの貴重なリソースを翻訳することで、この可能性を実現しました。この取り組みは、急速に成長する中国のAIコミュニティに私たちのコンテンツを利用しやすくすることを目的としており、相互の学習と協力を促進します。 中国のAIコミュニティの成果を認識する 私たちは、優れた才能と革新を示した中国のAIコミュニティの驚異的な成果と貢献を強調したいと考えています。HuggingGPT、ChatGLM、RWKV、ChatYuan、ModelScopeのテキストからビデオへのモデル、さらにはIDEA CCNLとBAAIの貢献など、画期的な進展は、コミュニティ内にある信じられないほどの可能性を示しています。 さらに、中国のAIコミュニティは、Chuanhu GPTやGPT Academyなどのトレンディなスペースの創造にも積極的に取り組んでおり、その熱意と創造性を示しています。 私たちは、PaddlePaddleなどの組織と協力して、Hugging Faceとのシームレスな統合を実現し、機械学習の領域でのより多くの共同作業を可能にしています。 協力関係と将来のイベントの強化 私たちは、中国の協力者との協力の歴史に誇りを持ち、知識の交換と協力を可能にするさまざまなイベントで一緒に働いてきました。私たちの協力の一部には、次のものがあります: DataWhaleとのオンラインChatGPTコース(進行中) JAX/Diffusersコミュニティスプリントのための北京での初めてのオフラインミートアップ Baixing AIとのPromptエンジニアリングハッカソンの主催 PaddlePaddleとのLoraモデルの微調整 HeyWhaleのイベントでの安定したディフュージョンモデルの微調整…

フリーティアのGoogle Colabで🧨ディフューザーを使用してIFを実行中
要約:Google Colabの無料ティア上で最も強力なオープンソースのテキストから画像への変換モデルIFを実行する方法を紹介します。 また、Hugging Face Spaceでモデルの機能を直接探索することもできます。 公式のIF GitHubリポジトリから圧縮された画像。 はじめに IFは、ピクセルベースのテキストから画像への生成モデルで、DeepFloydによって2023年4月下旬にリリースされました。モデルのアーキテクチャは、GoogleのクローズドソースのImagenに強く影響を受けています。 IFは、Stable Diffusionなどの既存のテキストから画像へのモデルと比較して、次の2つの利点があります: モデルは、レイテントスペースではなく「ピクセルスペース」(つまり、非圧縮画像上で)で直接動作し、Stable Diffusionのようなノイズ除去プロセスを実行しません。 モデルは、Stable Diffusionでテキストエンコーダとして使用されるCLIPよりも強力なテキストエンコーダであるT5-XXLの出力で訓練されます。 その結果、IFは高周波の詳細(例:人の顔や手など)を持つ画像を生成する能力に優れており、信頼性のあるテキスト付き画像を生成できる最初のオープンソースの画像生成モデルです。 ピクセルスペースで動作し、より強力なテキストエンコーダを使用することのデメリットは、IFが大幅に多くのパラメータを持っていることです。T5、IFのテキストから画像へのUNet、IFのアップスケーラUNetは、それぞれ4.5B、4.3B、1.2Bのパラメータを持っています。それに対して、Stable Diffusion 2.1のテキストエンコーダとUNetは、それぞれ400Mと900Mのパラメータしか持っていません。 しかし、メモリ使用量を低減させるためにモデルを最適化すれば、一般のハードウェア上でもIFを実行することができます。このブログ記事では、🧨ディフューザを使用してその方法を紹介します。 1.)では、テキストから画像への生成にIFを使用する方法を説明し、2.)と3.)では、IFの画像バリエーションと画像インペインティングの機能について説明します。 💡 注意:メモリの利得と引き換えに速度の利得を得るために、IFを無料ティアのGoogle Colab上で実行できるようにしています。A100などの高性能なGPUにアクセスできる場合は、公式のIFデモのようにすべてのモデルコンポーネントをGPU上に残して、最大の速度で実行することをお勧めします。…

StarCoder:コードのための最先端のLLM
StarCoderの紹介 StarCoderとStarCoderBaseは、GitHubからの許可を得たデータを使用してトレーニングされた大規模な言語モデルです。これらのモデルは、80以上のプログラミング言語、Gitのコミット、GitHubの課題、Jupyterノートブックなど、様々な情報源からデータを取得しています。LLaMAと同様に、私たちは1兆トークンのために約15兆パラメータのモデルをトレーニングしました。また、35兆のPythonトークンに対してStarCoderBaseモデルを微調整し、新しいモデルであるStarCoderと呼びます。 StarCoderBaseは、人気のあるプログラミングベンチマークにおいて既存のオープンなコードモデルよりも優れたパフォーマンスを発揮し、GitHub Copilotの初期バージョンで使用された「code-cushman-001」といったクローズドモデルとも匹敵する結果を示しました。StarCoderモデルは、8,000以上のトークンのコンテキスト長を持つため、他のオープンなLLMよりも多くの入力を処理することができます。これにより、さまざまな興味深いアプリケーションが可能となります。例えば、StarCoderモデルに対して対話のシリーズをプロンプトとして与えることで、技術アシスタントとしての機能を果たすことができます。さらに、これらのモデルはコードの自動補完、指示に基づいたコードの変更、コードスニペットの自然言語による説明などにも使用することができます。私たちは、改善されたPIIの削除パイプライン、新しい帰属追跡ツールなど、安全なオープンモデルのリリースに向けていくつかの重要な手順を踏んでいます。また、StarCoderは改良されたOpenRAILライセンスのもとで一般に公開されています。この更新されたライセンスにより、企業がモデルを製品に統合するプロセスが簡素化されます。StarCoderモデルの強力なパフォーマンスにより、コミュニティは自分たちのユースケースや製品に適応させるための堅固な基盤としてこれを活用することができると考えています。 評価 私たちはStarCoderといくつかの類似モデルについて、さまざまなベンチマークで徹底的に評価を行いました。人気のあるPythonベンチマークであるHumanEvalでは、関数のシグネチャとドキュメント文字列に基づいてモデルが関数を完成させることができるかどうかをテストしました。StarCoderとStarCoderBaseは、PaLM、LaMDA、LLaMAなどの最大のモデルを上回るパフォーマンスを発揮しましたが、それらよりも遥かに小さなサイズであるという特徴も持っています。また、CodeGen-16B-MonoやOpenAIのcode-cushman-001(12B)モデルよりも優れた結果を示しました。私たちはまた、モデルの失敗例として、通常は練習の一部として使用されるため、# Solution hereというコードを生成することがあることに気付きました。実際の解決策を生成させるために、プロンプトとして<filename>solutions/solution_1.py\n# Here is the correct implementation of the code exerciseを追加しました。これにより、StarCoderのHumanEvalスコアは34%から40%以上に向上し、オープンモデルの最新のベンチマーク結果を更新しました。CodeGenとStarCoderBaseに対してもこのプロンプトを試しましたが、あまり違いは観察されませんでした。 StarCoderの興味深い特徴の一つは、多言語対応であることです。そのため、MultiPL-Eという多言語の拡張を使用して評価を行いました。その結果、StarCoderは多くの言語においてcode-cushman-001と匹敵または優れたパフォーマンスを発揮することがわかりました。また、DS-1000というデータサイエンスのベンチマークでも、StarCoderは他のオープンアクセスモデルを圧倒する結果を示しました。しかし、コード補完以外にもモデルができることを見てみましょう! 技術アシスタント 徹底的な評価の結果、StarCoderはコードの記述に非常に優れていることがわかりました。しかし、ドキュメンテーションやGitHubの課題などの情報を大量に学習しているため、技術アシスタントとして使用できるかどうかもテストしたかったのです。AnthropicのHHHプロンプトに触発されて、私たちはTech Assistant Promptを作成しました。驚くべきことに、プロンプトだけでモデルは技術アシスタントとして機能し、プログラミングに関連する要求に答えることができます! トレーニングデータ このモデルは、The…

テキストからビデオへのモデルの深掘り
ModelScopeで生成されたビデオサンプルです。 テキストからビデオへの変換は、生成モデルの驚くべき進歩の長いリストの中で次に来るものです。その名前の通り、テキストからビデオへの変換は、時間的にも空間的にも一貫性のある画像のシーケンスをテキストの説明から生成する、比較的新しいコンピュータビジョンのタスクです。このタスクは、テキストから画像への変換と非常によく似ているように思えるかもしれませんが、実際にははるかに難しいものです。これらのモデルはどのように動作し、テキストから画像のモデルとはどのように異なり、どのようなパフォーマンスが期待できるのでしょうか? このブログ記事では、テキストからビデオモデルの過去、現在、そして未来について論じます。まず、テキストからビデオとテキストから画像のタスクの違いを見直し、条件付きと非条件付きのビデオ生成の独特の課題について話し合います。さらに、テキストからビデオモデルの最新の開発について取り上げ、これらの方法がどのように機能し、どのような能力があるのかを探ります。最後に、Hugging Faceで取り組んでいるこれらのモデルの統合と使用を容易にするための取り組みや、Hugging Face Hub内外でのクールなデモやリソースについて話します。 さまざまなテキストの説明を入力として生成されたビデオの例、Make-a-Videoより。 テキストからビデオ対テキストから画像 最近の開発が非常に多岐にわたるため、テキストから画像の生成モデルの現在の状況を把握することは困難かもしれません。まずは簡単に振り返りましょう。 わずか2年前、最初のオープンボキャブラリ、高品質なテキストから画像の生成モデルが登場しました。VQGAN-CLIP、XMC-GAN、GauGAN2などの最初のテキストから画像のモデルは、すべてGANアーキテクチャを採用していました。これらに続いて、2021年初めにOpenAIの非常に人気のあるトランスフォーマーベースのDALL-E、2022年4月のDALL-E 2、Stable DiffusionとImagenによって牽引された新しい拡散モデルの新たな波が続きました。Stable Diffusionの大成功により、DreamStudioやRunwayML GEN-1などの多くの製品化された拡散モデルや、Midjourneyなどの既存製品との統合が実現しました。 テキストから画像生成における拡散モデルの印象的な機能にもかかわらず、拡散および非拡散ベースのテキストからビデオモデルは、生成能力においてはるかに制約があります。テキストからビデオは通常、非常に短いクリップで訓練されるため、長いビデオを生成するためには計算コストの高いスライディングウィンドウアプローチが必要です。そのため、これらのモデルは展開とスケーリングが困難であり、文脈と長さに制約があります。 テキストからビデオのタスクは、さまざまな面で独自の課題に直面しています。これらの主な課題のいくつかには以下があります: 計算上の課題:フレーム間の空間的および時間的な一貫性を確保することは、長期的な依存関係を伴い、高い計算コストを伴います。そのため、このようなモデルを訓練することは、ほとんどの研究者にとって手の届かないものです。 高品質なデータセットの不足:テキストからビデオの生成のためのマルチモーダルなデータセットは希少で、しばしばスパースに注釈が付けられているため、複雑な動きのセマンティクスを学ぶのが難しいです。 ビデオのキャプションに関する曖昧さ:モデルが学習しやすいようにビデオを記述する方法は未解決の問題です。完全なビデオの説明を提供するためには、複数の短いテキストプロンプトが必要です。生成されたビデオは、時間の経過に沿って何が起こるかを物語る一連のプロンプトやストーリーに基づいて条件付ける必要があります。 次のセクションでは、テキストからビデオへの進展のタイムラインと、これらの課題に対処するために提案されたさまざまな手法について別々に議論します。高レベルでは、テキストからビデオの作業では以下のいずれかを提案しています: 学習しやすいより高品質なデータセットの作成。 テキストとビデオのペアデータなしでこのようなモデルを訓練する方法。 より計算効率の良い方法で長く、高解像度のビデオを生成する方法。 テキストからビデオを生成する方法…

スターコーダーでコーディングアシスタントを作成する
ソフトウェア開発者であれば、おそらくGitHub CopilotやChatGPTを使用して、プログラミングのタスクを解決したことがあるでしょう。これらのタスクには、コードを別の言語に変換したり、自然言語のクエリ(「N番目のフィボナッチ数を見つけるPythonプログラムを書いてください」といったもの)から完全な実装を生成したりするものがあります。これらの独自のシステムは、その機能には感動的ですが、一般にはいくつかの欠点があります。これらには、トレーニングに使用される公開データの透明性の欠如や、ドメインやコードベースに適応することのできなさなどがあります。 幸いにも、今はいくつかの高品質なオープンソースの代替品があります!これには、SalesForceのPython用CodeGen Mono 16B、またはReplitの20のプログラミング言語でトレーニングされた3Bパラメータモデルなどがあります。 新しいオープンソースの選択肢としては、BigCodeのStarCoderがあります。80以上のプログラミング言語、GitHubの問題、Gitのコミット、Jupyterノートブックから1兆トークンを収集した16Bパラメータモデルで、これらはすべて許可されたライセンスです。エンタープライズ向けのライセンス、8,192トークンのコンテキスト長、およびマルチクエリアテンションによる高速な大規模バッチ推論を備えたStarCoderは、現在、コードベースのアプリケーションにおいて最も優れたオープンソースの選択肢です。 このブログポストでは、StarCoderをチャット用にファインチューニングして、パーソナライズされたコーディングアシスタントを作成する方法を紹介します! StarChatと呼ばれるこのアシスタントには、次のようないくつかの技術的な詳細があります。 LLMを会話エージェントのように動作させる方法。 OpenAIのChat Markup Language(ChatMLとも呼ばれる)は、人間のユーザーとAIアシスタントの間の会話メッセージに対する構造化された形式を提供します。 🤗 TransformersとDeepSpeed ZeRO-3を使用して、多様な対話のコーパスで大きなモデルをファインチューニングする方法。 最終結果の一部を見るために、以下のデモでStarChatにいくつかのプログラミングの質問をしてみてください! デモで使用されたコード、データセット、およびモデルは、以下のリンクで見つけることができます。 コード: https://github.com/bigcode-project/starcoder データセット: https://huggingface.co/datasets/HuggingFaceH4/oasst1_en モデル: https://huggingface.co/HuggingFaceH4/starchat-alpha 始める準備ができたら、まずはファインチューニングなしで言語モデルを会話エージェントに変換する方法を見てみましょう。…

アシストされた生成:低遅延テキスト生成への新たな方向
大規模な言語モデルは最近注目を集めており、多くの企業がそれらを拡大し、新たな機能を開放するために多大なリソースを投資しています。しかし、私たち人間は注意力が減少しているため、彼らの遅い応答時間も嫌いです。レイテンシは良好なユーザーエクスペリエンスにおいて重要であり、低品質なものである場合でも(たとえば、コード補完において)小さいモデルが使用されることがよくあります。 なぜテキスト生成は遅いのでしょうか?破産せずに低レイテンシな大規模な言語モデルを展開する障害物は何でしょうか?このブログ記事では、自己回帰的なテキスト生成のボトルネックを再検討し、レイテンシの問題に対処するための新しいデコーディング手法を紹介します。私たちの新しい手法であるアシスト付き生成を使用することで、コモディティハードウェアでレイテンシを最大10倍まで削減できることがわかります! テキスト生成のレイテンシの理解 現代のテキスト生成の核心は理解しやすいです。中心となる部分であるMLモデルを見てみましょう。その入力には、これまでに生成されたテキストや、モデル固有のコンポーネント(Whisperのようなオーディオ入力もあります)など、テキストシーケンスが含まれます。モデルは入力を受け取り、順番に各層を通って次のトークンの非正規化された対数確率(ログット)を予測します。トークンは、モデルによって単語全体、サブワード、または個々の文字で構成されることがあります。テキスト生成のこの部分について詳しく知りたい場合は、イラスト付きのGPT-2を参照してください。 モデルの順方向パスによって次のトークンのログットが得られますが、これらのログットを自由に操作することができます(たとえば、望ましくない単語やシーケンスの確率を0に設定する)。テキスト生成の次のステップは、これらのログットから次のトークンを選択することです。一般的な戦略は、最も可能性の高いトークンを選ぶことで、これはグリーディデコーディングとして知られています。また、トークンの分布からサンプリングすることも行います。モデルの順方向パスと次のトークンの選択を反復的に連結することで、テキスト生成が行われます。デコーディング手法に関しては、この説明はアイスバーグの一角に過ぎません。詳細な探求のために、テキスト生成に関する当社のブログ記事を参照してください。 上記の説明から、テキスト生成のレイテンシのボトルネックは明確です。大規模なモデルの順方向パスを実行することは遅いため、連続して何百回も実行する必要があります。しかし、さらに詳しく見てみましょう。なぜ順方向パスが遅いのでしょうか?順方向パスは通常、行列の乗算によって支配されます。対応するウィキペディアのセクションを素早く訪れると、この操作における制限はメモリ帯域幅であることがわかります(たとえば、GPU RAMからGPUコンピュートコアへ)。つまり、順方向パスのボトルネックは、デバイスの計算コアにモデルのレイヤーの重みを読み込むことから来ており、計算自体ではありません。 現時点では、テキスト生成の最大の効果を得るために探求できる3つの主な方法がありますが、すべてがモデルの順方向パスのパフォーマンスに対処しています。まず第一に、ハードウェア固有のモデルの最適化があります。たとえば、デバイスがFlash Attentionに対応している場合、操作の並べ替えによってアテンションレイヤーの処理を高速化することができます。また、モデルのウェイトのサイズを削減するINT8量子化もあります。 第二に、同時にテキスト生成のリクエストがあることがわかっている場合、入力をバッチ化し、小さなレイテンシのペナルティを支払いながらスループットを大幅に増加させることができます。デバイスに読み込まれたモデルのレイヤーのウェイトは、複数の入力行で並列に使用されるため、ほぼ同じメモリ帯域幅の負荷でより多くのトークンを出力することができます。バッチ処理の問題は、追加のデバイスメモリが必要であることです(またはメモリをどこかにオフロードする必要があります)-このスペクトルの終端では、レイテンシを犠牲にしてスループットを最適化するFlexGenなどのプロジェクトが見られます。 # バッチ化された生成の影響を示す例。計測デバイス: RTX3090 from transformers import AutoModelForCausalLM, AutoTokenizer import time tokenizer = AutoTokenizer.from_pretrained("distilgpt2") model…

RWKVとは、トランスフォーマーの利点を持つRNNの紹介です
ChatGPTとチャットボットを活用したアプリケーションは、自然言語処理(NLP)の領域で注目を集めています。コミュニティは、アプリケーションやユースケースに強力で信頼性の高いオープンソースモデルを常に求めています。これらの強力なモデルの台頭は、Vaswaniらによって2017年に最初に紹介されたトランスフォーマーベースのモデルの民主化と広範な採用によるものです。これらのモデルは、それ以降のSoTA NLPモデルである再帰型ニューラルネットワーク(RNN)ベースのモデルを大幅に上回りました。このブログ投稿では、RNNとトランスフォーマーの両方の利点を組み合わせた新しいアーキテクチャであるRWKVの統合を紹介します。このアーキテクチャは最近、Hugging Face transformersライブラリに統合されました。 RWKVプロジェクトの概要 RWKVプロジェクトは、Bo Peng氏が立ち上げ、リードしています。Bo Peng氏は積極的にプロジェクトに貢献し、メンテナンスを行っています。コミュニティは、公式のdiscordチャンネルで組織されており、パフォーマンス(RWKV.cpp、量子化など)、スケーラビリティ(データセットの処理とスクレイピング)、および研究(チャットの微調整、マルチモーダルの微調整など)など、さまざまなトピックでプロジェクトの成果物を常に拡張しています。RWKVモデルのトレーニングに使用されるGPUは、Stability AIによって寄付されています。 公式のdiscordチャンネルに参加し、RWKVの基本的なアイデアについて詳しく学ぶことで、参加することができます。以下の2つのブログ投稿で詳細を確認できます:https://johanwind.github.io/2023/03/23/rwkv_overview.html / https://johanwind.github.io/2023/03/23/rwkv_details.html トランスフォーマーアーキテクチャとRNN RNNアーキテクチャは、データのシーケンスを処理するための最初の広く使用されているニューラルネットワークアーキテクチャの1つであり、固定サイズの入力を取る従来のアーキテクチャとは異なります。RNNは、現在の「トークン」(つまり、データストリームの現在のデータポイント)、前の「状態」を入力として受け取り、次のトークンと次の状態を予測します。新しい状態は、次のトークンの予測を計算するために使用され、以降も同様に続きます。RNNは異なる「モード」でも使用できるため、Andrej Karpathy氏のブログ投稿で示されているように、1対1(画像分類)、1対多(画像キャプション)、多対1(シーケンス分類)、多対多(シーケンス生成)など、さまざまなシナリオでRNNを適用することが可能です。 RNNは、各ステップで予測を計算するために同じ重みを使用するため、勾配消失の問題により長距離のシーケンスに対する情報の記憶に苦労します。この制限に対処するために、LSTMやGRUなどの新しいアーキテクチャが導入されましたが、トランスフォーマーアーキテクチャはこの問題を解決するためにこれまでで最も効果的なものとなりました。 トランスフォーマーアーキテクチャでは、入力トークンは自己注意モジュールで同時に処理されます。トークンは、クエリ、キー、値の重みを使用して異なる空間に線形にプロジェクションされます。結果の行列は、アテンションスコアを計算するために直接使用され、その後値の隠れ状態と乗算されて最終的な隠れ状態が得られます。この設計により、アーキテクチャは長距離のシーケンスの問題を効果的に緩和し、RNNモデルと比較して推論とトレーニングの速度も高速化します。 トランスフォーマーアーキテクチャは、トレーニング中に従来のRNNおよびCNNに比べていくつかの利点があります。最も重要な利点の1つは、文脈的な表現を学習できる能力です。RNNやCNNとは異なり、トランスフォーマーアーキテクチャは単語ごとではなく、入力シーケンス全体を処理します。これにより、シーケンス内の単語間の長距離の依存関係を捉えることができます。これは、言語翻訳や質問応答などのタスクに特に有用です。 推論中、RNNは速度とメモリ効率の面でいくつかの利点があります。これらの利点には、単純さ(行列-ベクトル演算のみが必要)とメモリ効率(推論中にメモリ要件が増えない)が含まれます。さらに、現在のトークンと状態にのみ作用するため、コンテキストウィンドウの長さに関係なく計算速度が同じままです。 RWKVアーキテクチャ RWKVは、AppleのAttention Free Transformerに触発されています。アーキテクチャは注意深く簡素化され、最適化されており、RNNに変換することができます。さらに、TokenShiftやSmallInitEmbなどのトリックが追加されています(公式のGitHubリポジトリのREADMEにトリックのリストが記載されています)。これにより、モデルのパフォーマンスがGPTに匹敵するように向上しています。現在、トレーニングを14Bパラメータまでスケーリングするためのインフラストラクチャがあり、RWKV-4(本日の最新バージョン)では数値の不安定性など、いくつかの問題が反復的に修正されました。 RNNとトランスフォーマーの組み合わせとしてのRWKV…

より小さいほうが良いです:Xeon上で効率的な生成AI体験、Q8-Chat
大規模言語モデル(LLM)は、機械学習の世界を席巻しています。Transformerアーキテクチャのおかげで、LLMはテキスト、画像、ビデオ、オーディオなどの大量の非構造化データから学習する驚異的な能力を持っています。テキスト分類のような抽出型のタスクや、テキスト要約、テキストから画像生成などの生成型のタスクでも非常に優れたパフォーマンスを発揮します。 その名前からもわかるように、LLMは一般的に100億パラメータを超える大規模なモデルです。BLOOMモデルのように1000億パラメータ以上のものもあります。LLMは、検索や対話型アプリケーションなどの低遅延のユースケースで十分に高速な予測を行うために、高性能なGPUに典型的に見られる大量の計算能力を必要とします。残念ながら、多くの組織にとっては関連するコストが高く、最先端のLLMをアプリケーションに使用することが困難になります。 この記事では、Intel CPU上で効率的に実行するために、LLMのサイズと推論レイテンシを減らす最適化技術について説明します。 量子化の基礎 通常、LLMは16ビットの浮動小数点パラメータ(FP16/BF16)でトレーニングされます。したがって、単一の重みまたはアクティベーション値の値を保存するためには2バイトのメモリが必要です。さらに、浮動小数点の演算は整数の演算よりも複雑で遅く、追加の計算能力が必要です。 量子化は、モデルパラメータが取ることができるユニークな値の範囲を縮小することで、両方の問題を解決するモデルの圧縮技術です。たとえば、モデルを8ビット整数(INT8)のような低精度に量子化して、モデルを縮小し、複雑な浮動小数点演算をより単純で高速な整数演算に置き換えることができます。 要するに、量子化はモデルパラメータをより小さな値範囲に再スケーリングします。成功すると、モデルのサイズが少なくとも2倍に縮小され、モデルの精度には影響しません。 量子化は、通常、トレーニング中に適用することができます。これを量子化対応トレーニング(QAT)と呼びますが、一般的に最良の結果が得られます。既存のモデルを量子化する場合は、非常に少ない計算能力を必要とする高速なテクニックであるポストトレーニング量子化(PTQ)を適用することもできます。 さまざまな量子化ツールが利用可能です。たとえば、PyTorchには量子化の組み込みサポートがあります。また、QATおよびPTQのための開発者向けのAPIを備えたHugging Face Optimum Intelライブラリを使用することもできます。 LLMの量子化 最近の研究[1][2]によると、現在の量子化技術はLLMとはうまく機能しません。特に、LLMはすべてのレイヤーとトークンで特定のアクティベーションチャネルに大きな値の外れ値を示します。以下はOPT-13Bモデルの例です。すべてのトークンで、アクティベーションの1つのチャネルが他のすべてのチャネルよりもはるかに大きな値を持っていることがわかります。この現象はモデルのすべてのTransformerレイヤーで見られます。 *出典: SmoothQuant* 現在の最良の量子化技術は、トークン単位でアクティベーションを量子化し、切り捨てられた外れ値または低いマグニチュードのアクティベーションを引き起こします。いずれの解決策もモデルの品質に大きな影響を与えます。さらに、量子化対応トレーニングには追加のモデルトレーニングが必要であり、計算リソースとデータの不足のため、ほとんどの場合には実用的ではありません。 SmoothQuant[3][4]は、この問題を解決する新しい量子化技術です。それは重みとアクティベーションに共同の数学的変換を適用し、アクティベーションの外れ値と非外れ値の比率を減らすことで、Transformerのレイヤーを「量子化に適した」状態にします。これにより、モデルの品質に影響を与えずに8ビットの量子化が可能となります。その結果、SmoothQuantはIntel CPUプラットフォーム上で優れたパフォーマンスを発揮する、より小さく、高速なモデルを生成します。 *出典: SmoothQuant* それでは、SmoothQuantを人気のあるLLMに適用した場合の動作を見てみましょう。 SmoothQuantを使用したLLMの量子化…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.