Learn more about Search Results 大規模な言語モデル - Page 73

- You may be interested
- 「英国の選挙登録簿に対するサイバー攻撃...
- OpenAIがDALL-E 3を公開し、ユーザーはCha...
- 「生成AIによる法科学の進展」
- 「将来的にAIが医療請求の補完をどのよう...
- バイアス、有害性、および大規模言語モデ...
- 「3億の仕事が本当にAIによる代替でさらさ...
- レストランの革命:飲食業界におけるAIの力
- 🤗 ViTをVertex AIに展開する
- 一緒にAIを学びましょう−Towards AIコミュ...
- スタンフォードの研究者たちは、Parselと...
- 「MITの研究者が開発した機械学習技術によ...
- 「ODSC West 2023 の最初の50セッションが...
- 「アフリカのコミュニティが気候変動に適...
- ウェブサイトビルディングにおけるAIの台...
- 『チュートリアルを超えて LangChainのPan...
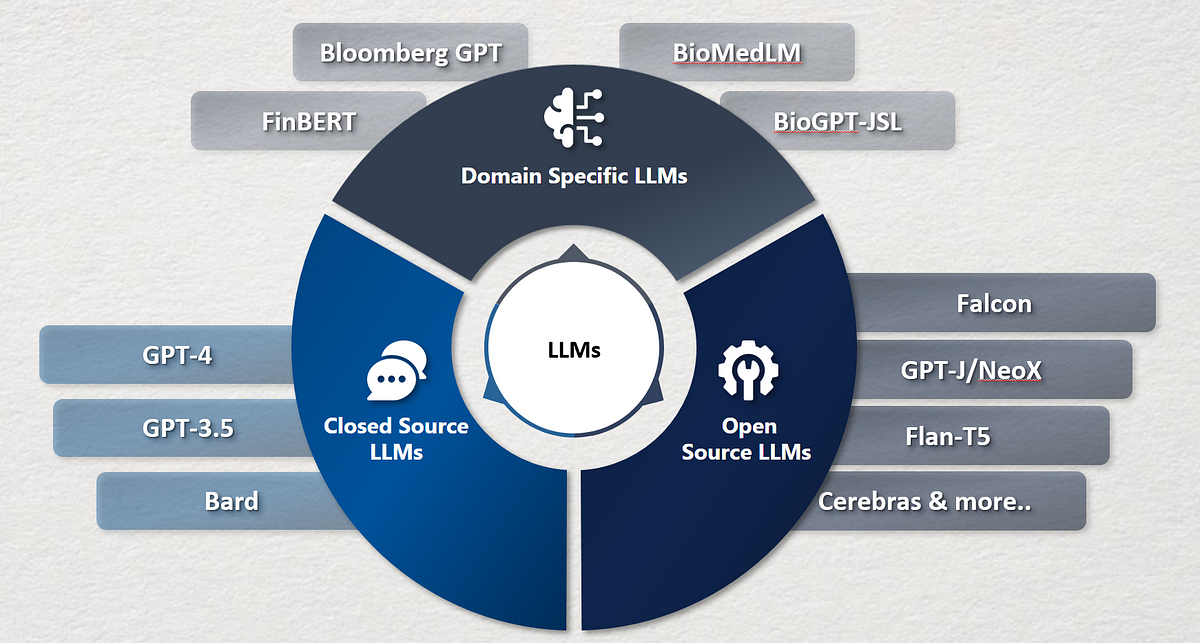
企業がOpenAIのChatGPTに類似した自社の大規模言語モデルを構築する方法
最近の数年間で、言語モデルは大きな注目を集め、自然言語処理、コンテンツ生成、仮想アシスタントなど、さまざまな分野を革新しました最も注目されているのは、
次のLangChainプロジェクトのための基本を学ぶ
大型言語モデルは昨年、楽しみのためにメインストリームに参入し、時にはまったくばかげた実験のツールとして登場しました私たちの中でChatGPTに新しいノック・ノック・ジョークを作り出すよう挑戦したことがない人は誰もいないでしょう

Falcon AI 新しいオープンソースの大規模言語モデル
はじめに Open AIによるGPT(Generative Pre Trained)の発表以来、世界はGenerative AIによって大いに沸き立っています。その後、多くのGenerative Modelsが登場しました。新しいGenerative Large Language Modelsがリリースされるたびに、AIは人間の知性により近づいてきました。しかし、Open AIコミュニティはGPTファミリーの強力なLarge Language Modelsをクローズドソース化しました。幸いなことに、Falcon AIという非常に能力が高いGenerative Modelが他のLLMsを凌駕し、オープンソースとなり、誰でも使用できるようになりました。 学習目標 Falcon AIがLLM Leaderboardのトップになった理由を理解する Falcon AIの能力を学ぶ Falcon AIのパフォーマンスを観察する PythonでFalcon…

北京大学の研究者たちは、ChatLawというオープンソースの法律用の大規模言語モデルを紹介しましたこのモデルには、統合された外部知識ベースが搭載されています
人工知能の成長と発展により、大規模な言語モデルが広く利用可能になりました。ChatGPT、GPT4、LLaMA、Falcon、Vicuna、ChatGLMなどのモデルは、さまざまな伝統的なタスクで優れたパフォーマンスを発揮し、法律業界にとっても多くの機会を開いています。ただし、信頼性のある最新かつ高品質なデータを収集することが、大規模な言語モデルの構築には不可欠です。したがって、効果的かつ効率的なオープンソースの法律言語モデルの作成が重要になっています。 人工知能による大規模モデルの開発は、医療、教育、金融など、いくつかの産業に影響を与えています。BloombergGPT、FinGPT、Huatuo、ChatMedなどのモデルは、難解な問題の解決や洞察に有用で効果的であることが証明されています。一方で、法律の領域では、その固有の関連性と正確さの必要性から、徹底的な調査と独自の法的モデルの作成が求められます。法律は、コミュニティの形成、人間関係の規制、そして正義を確保する上で重要です。法律実務家は、賢明な判断を下し、法律を理解し、法的助言を提供するために正確で最新の情報に頼る必要があります。 法的用語の微妙なニュアンス、複雑な解釈、法律の動的な性質は、特殊な問題を引き起こし、専門的な解決策を必要とします。最先端のGPT4などのモデルでも、法的な困難に関しては頻繁に幻覚現象や驚くべき結果が生じることがあります。多くの人々は、関連するドメインの専門知識でモデルを改善することが良い結果をもたらすと考えています。しかし、早期の法的LLM(LawGPT)にはまだ多くの幻覚と不正確な結果が存在するため、これは事実ではありません。当初は中国の法的LLMの需要があることが理解されました。しかし、13億以上のパラメータを持つ中国のモデルは、商業的に利用可能な時点では存在しませんでした。MOSSなどのソースからのトレーニングデータを組み合わせ、中国語の語彙を増やすことで、経済的に実現可能なモデルであるOpenLLAMAの基盤が改善されました。これにより、北京大学の研究者は、中国語の基本モデルを構築し、それに法律特有のデータを追加してChatLawという法的モデルをトレーニングすることができました。 以下は、論文の主な貢献です: 1. 幻覚を減らすための成功した方法:モデルのトレーニング手順を改善し、推論時に「相談」「参照」「自己提案」「応答」という4つのモジュールを組み込むことにより、幻覚を減らす方法を提案しています。参照モジュールを介して垂直モデルと知識ベースを統合することで、幻覚がより少なくなり、ドメイン固有の知識がモデルに組み込まれ、信頼性のあるデータが知識ベースから使用されます。 2. ユーザーの日常言語から法的特徴語を抽出するモデルがトレーニングされました。これはLLMに基づいています。法的な意味を持つ用語を認識するこのモデルの助けを借りて、ユーザーの入力内の法的状況を迅速かつ効果的に特定し、分析することができます。 3. BERTを使用して、ユーザーの普通の言語と930,000件の関連する裁判文書のデータセットとの類似度を測定するモデルがトレーニングされました。これにより、類似した法的文脈を持つ文章を迅速に検索し、追加の研究や引用が可能になります。 4. 中国語の法的試験評価データセットの開発:中国語を話す人々の法的専門知識を評価するためのデータセットを作成しました。また、さまざまなモデルが法的な多肢選択問題でどれだけ優れたパフォーマンスを発揮するかを判断するためのELOアリーナスコアリングシステムも作成しました。 また、一つの汎用的な法的LLMは、この領域で一部のタスクに対してのみうまく機能する可能性があります。そのため、彼らは複数の状況に対応するために、多肢選択問題、キーワード抽出、質問応答などのさまざまなモデルを開発しました。HuggingGPT技術を使用して、大規模なLLMをコントローラーとして使用し、これらのモデルの選択と展開を管理しました。ユーザーの要求に基づいて、このコントローラーモデルは動的に特定のモデルを選択してアクティブにし、タスクに最適なモデルを使用することを保証します。

ゼロから大規模言語モデルを構築するための初心者ガイド
はじめに TwitterやLinkedInなどで、私は毎日多くの大規模言語モデル(LLMs)に関する投稿に出会います。これらの興味深いモデルに対してなぜこれほど多くの研究と開発が行われているのか、私は疑問に思ったこともあります。ChatGPTからBARD、Falconなど、無数のモデルの名前が飛び交い、その真の性質を解明したくなるのです。これらのモデルはどのように作成されるのでしょうか?大規模言語モデルを構築するにはどうすればよいのでしょうか?これらのモデルは、あなたが投げかけるほとんどの質問に答える能力を持つのはなぜでしょうか?これらの燃えるような疑問は私の心に長く残り、好奇心をかき立てています。この飽くなき好奇心は私の内に火をつけ、LLMsの領域に飛び込む原動力となっています。 私たちがLLMsの最先端について議論する刺激的な旅に参加しましょう。一緒に、彼らの開発の現状を解明し、彼らの非凡な能力を理解し、彼らが言語処理の世界を革新した方法に光を当てましょう。 学習目標 LLMsとその最新の状況について学ぶ。 利用可能なさまざまなLLMsとこれらのLLMsをゼロからトレーニングするアプローチを理解する。 LLMsのトレーニングと評価におけるベストプラクティスを探究する。 準備はいいですか?では、LLMsのマスタリングへの旅を始めましょう。 大規模言語モデルの簡潔な歴史 大規模言語モデルの歴史は1960年代にさかのぼります。1967年にMITの教授が、自然言語を理解するための最初のNLPプログラムであるElizaを作成しました。Elizaはパターンマッチングと置換技術を使用して人間と対話し理解することができます。その後、1970年にはMITチームによって、人間と対話し理解するための別のNLPプログラムであるSHRDLUが作成されました。 1988年には、テキストデータに存在するシーケンス情報を捉えるためにRNNアーキテクチャが導入されました。2000年代には、RNNを使用したNLPの研究が広範に行われました。RNNを使用した言語モデルは当時最先端のアーキテクチャでした。しかし、RNNは短い文にはうまく機能しましたが、長い文ではうまく機能しませんでした。そのため、2013年にはLSTMが導入されました。この時期には、LSTMベースのアプリケーションで大きな進歩がありました。同時に、アテンションメカニズムの研究も始まりました。 LSTMには2つの主要な懸念がありました。LSTMは長い文の問題をある程度解決しましたが、実際には非常に長い文とはうまく機能しませんでした。LSTMモデルのトレーニングは並列化することができませんでした。そのため、これらのモデルのトレーニングには長い時間がかかりました。 2017年には、NLPの研究において Attention Is All You Need という論文を通じてブレークスルーがありました。この論文はNLPの全体的な景色を変革しました。研究者たちはトランスフォーマーという新しいアーキテクチャを導入し、LSTMに関連する課題を克服しました。トランスフォーマーは、非常に多数のパラメータを含む最初のLLMであり、LLMsの最先端モデルとなりました。今日でも、LLMの開発はトランスフォーマーに影響を受けています。 次の5年間、トランスフォーマーよりも優れたLLMの構築に焦点を当てた重要な研究が行われました。LLMsのサイズは時間とともに指数関数的に増加しました。実験は、LLMsのサイズとデータセットの増加がLLMsの知識の向上につながることを証明しました。そのため、BERT、GPTなどのLLMsや、GPT-2、GPT-3、GPT 3.5、XLNetなどのバリアントが導入され、パラメータとトレーニングデータセットのサイズが増加しました。 2022年には、NLPにおいて別のブレークスルーがありました。 ChatGPT は、あなたが望むことを何でも答えることができる対話最適化されたLLMです。数か月後、GoogleはChatGPTの競合製品としてBARDを紹介しました。…

Google AIがFlan-T5をオープンソース化 NLPタスクにおいてテキスト対テキストアプローチを使用するトランスフォーマーベースの言語モデル
大規模な言語モデル、例えばPaLM、Chinchilla、およびChatGPTは、自然言語処理(NLP)のタスクを実行する新たな可能性を開いています。先行研究では、指示に基づくさまざまなNLPタスクで言語モデルを微調整する指示調整が、指示を与えられた未知のタスクを実行する能力をさらに向上させることが示されています。本論文では、オープンソースの指示一般化イニシアティブのアプローチと結果を比較し、彼らの微調整手順と戦略を評価しています。 この研究では、指示調整方法の詳細に焦点を当て、個々の要素を取り除いて直接比較しています。彼らは、「Flan 2022 Collection」という用語で、データ収集やデータと指示調整プロセスに適用される手法に焦点を当て、Flan 2022をPaLM 540Bと組み合わせた新興かつ最先端の結果に重点を置いたデータ収集の最も包括的なコレクションを公開しています。このコレクションには、数千のプレミアムなテンプレートとより良いフォーマットパターンが追加されています。 彼らは、評価ベンチマークのすべてで、このコレクションで訓練されたモデルが、オリジナルのFlan 2021 their、T0++ their、Super-Natural Instructions their、およびOPT-IML theirのような他の公開コレクションよりも優れたパフォーマンスを発揮することを示しています。同じサイズのモデルにおいて、MMLUおよびBIG-Bench Hardの評価ベンチマークにおいて4.2%以上および8.5%の改善が見られます。Flan 2022のアプローチの分析によると、これらの堅牢な結果は、より大きくより多様なタスクのコレクションと、ゼロショット、フューショット、およびチェーンオブソートのプロンプトを使用したトレーニングなど、いくつかの直感的な戦略による微調整とデータ拡張の結果であると言えます。 例えば、フューショットプロンプトの10%の増加は、ゼロショットプロンプトの結果を2%以上改善します。また、入出力対の反転を行うことでタスクのソースをバランスさせ、タスクの多様性を向上させることが、パフォーマンスにとって重要であることも示されています。シングルタスクの微調整では、得られたFlan-T5モデルはT5モデルよりも収束が速く、より優れた性能を発揮するため、指示調整済みのモデルは後続のアプリケーションにおいてより効率的な計算的な出発点を提供します。これらの結果とツールを公開することで、指示の調整に利用できるリソースが効率的になり、より汎用性の高い言語モデルの開発を加速することが期待されています。 本研究の主な貢献は以下の通りです: • 方法論的な貢献:ゼロショットおよびフューショットのキューを混合してトレーニングすることで、両環境で有意に優れた結果を生み出すことを示す。 • 効率的な指示調整のための主要な手法を測定および示し、セクション3.3のスケーリング、入力反転を使用したタスクの多様化の向上、チェーンオブソートのトレーニングデータの追加、およびさまざまなデータソースのバランスを取ることを含む。 • 結果:これらの技術的な決定により、利用可能なオープンソースの指示調整コレクションと比較して、保留中のタスクパフォーマンスが3〜17%向上します。 •…
7月号 データサイエンティストのための気候リソース
多くの人にとって、夏の訪れは以前は単純な興奮の原因でした:学校が終わる、仕事のスケジュールは少し忙しくないことが多い、ビーチでののんびりした午後や...
3つの難易度レベルでベクトルデータベースを説明する
この記事では、ベクトルデータベースについて、直感的な理解からいくつかの例を交えて、より技術的な詳細に説明しています

この人工知能の研究は、トランスフォーマーベースの大規模言語モデルが外部メモリを追加して計算的に普遍的であることを確認しています
トランスフォーマーベースのモデル(GPT-2やGPT-3など)によって達成された驚くべき結果は、研究コミュニティを大規模な言語モデル(LLM)の探求に引き寄せました。さらに、ChatGPTの最近の成功と人気は、LLMへの人々の関心を高めるだけです。文脈に即した学習と連想によるプロンプティングという2つの主要な発見は、モデルの正確性を大幅に向上させました。これらの発見は、単純な質問応答を超えています。質問が含まれる入力プロンプトを使用して、合理的な回答を出力するために使用されます。 これらのプロンプティング戦術はパフォーマンス向上に効果的でしたが、現在のトランスフォーマーベースのLLMは固定された入力文字列の長さにのみ条件付けることができ、それによって表現できる計算が制限されます。これは、有限な長さの文字列に依存する決定論的言語モデルは計算上制約されているため、計算的に制限されているとも理解できます。これに対抗するため、研究者はLLMに外部フィードバックループを追加する可能性を調査してきました。ここで、モデルの出力はいくつかの事後処理の後に入力として供給されます。ただし、この方法がモデルの計算セットを大幅に拡大するかどうかという問題はまだ解決されていません。 Google Brainとアルバータ大学の研究者は、この問題に取り組むために協力しました。彼らはLLMに外部の読み書き可能なメモリを追加し、それが任意の入力で任意のアルゴリズムをエミュレートできることを検証しました。彼らの研究は、「メモリ増強型大規模言語モデルは計算上普遍的である」という論文でまとめられており、連想型の読み書き可能なメモリが付加されたLLMが計算上普遍的である方法を示しています。 研究者たちの選んだLLMはFlan-U-PaLM 540Bでした。研究の背後にあるアイデアは、LLMと連想メモリをリンクするために単純なストアドインストラクションコンピュータを使用することです。これにより、言語モデルに転送される出力と入力プロンプトがループで相互作用することが可能になります。外部の連想メモリは辞書と見なすことができ、キーと値のペアは変数名/アドレス場所と値です。言語モデルとメモリは、各パーシングステップを実行するために正規表現マッチを使用します。 その後、システムに宇宙チューリングマシンの実行をシミュレートするように指示する「プロンプトプログラム」が開発されます。最終的に、シミュレーションの信頼性を示すためには、限られた数のプロンプト-結果のパターンを調べ、言語モデルが各有限の可能な入力文字列に対して適切な出力を生成することを確認する必要があります。この研究が言語モデルの「トレーニング」や事前学習の重みの変更を伴わないという事実は、この仕事の主な強みの1つです。代わりに、構築は特定のプロンプトでプログラム可能なタイプのストアドインストラクションコンピュータの作成にのみ依存しています。 この分野の以前の研究とは異なり、この研究は特異です。主な違いは、研究者が外部メモリの増強を使用して、固定された言語モデルと固定された事前学習の重みを使用して普遍的な計算動作を引き出す方法を示したことです。その結果、大規模な言語モデルは、現在存在する限り、無限の外部メモリにアクセスできる限り、計算上普遍的であることが示されました。

人工知能の未来を形作る:進歩と革新のための迅速なエンジニアリングの重要性
ChatGPTはリリース当日から話題になっています。革新的なチャットボットを既に100万人以上のユーザーが利用しています。ChatGPTは、異なる質問に対応し、広範なトピックに関する情報を生成するためにOpenAIによってトレーニングされた大規模な言語モデル(LLM)です。複数の言語を翻訳したり、ユーザー固有のユニークで創造的なコンテンツを生成したり、長いテキスト段落を要約したりすることができます。LLMは膨大なテキストデータでトレーニングされ、人間のような意味のあるテキストを生成します。さらに、ソフトウェアコードを生成する能力も持っています。大規模な言語モデルの主な利点の1つは、迅速に良質なテキストを便利かつ大規模に生成できることです。 プロンプトエンジニアリングとは何ですか? GPT-3に関して具体的に話すと、それは人間の思考と会話に達した最も近いモデルです。どのGPT-3アプリケーションを開発する場合も、適切なトレーニングプロンプトとそのデザイン、コンテンツが重要です。プロンプトは大規模な言語モデルに供給されるテキストです。プロンプトエンジニアリングは、モデルから満足のいく応答を得るためのプロンプトの設計に関わります。データ内のパターンやトレンドをモデルが見つけるために、適切なコンテキストの良質なトレーニングプロンプトをモデルに提供することに焦点を当てています。 プロンプトエンジニアリングは、機械に好ましい結果をもたらす可能性のある入力を指示する概念です。要するに、モデルに何を行う必要があるかを伝えることを含みます。例えば、テキストからテキストへのチャットGPTモデルに提供されたテキストの要約を作成するように頼む場合や、テキストから画像へのDALL-Eモデルに特定の画像を生成するように頼む場合などがあります。そのために、タスクはプロンプトベースのデータセットに変換され、そのデータに基づいてモデルが学習し、パターンを理解します。 プロンプトの例は何ですか? プロンプトは、単語や大きな文の連なり、またはコードブロックなど、何でもあります。それはまるで学生に任意のトピックの記事を書くように指示することのようです。DALLE-2などのモデルでは、プロンプトエンジニアリングはAIモデルに必要な応答をプロンプトとして説明することを含みます。プロンプトは、単純な文(例:「ラザニアのレシピ」)や質問(例:「アメリカ合衆国の最初の大統領は誰ですか?」)から、複雑な要求(例:「データサイエンスの面接が明日あるため、私のためにカスタマイズされた質問のリストを生成してください」)まで、プロンプトとして文脈を提供することによって異なります。 プロンプトエンジニアリングがAIの良い未来にとってなぜ重要なのか。 精度の向上:プロンプトエンジニアリングにより、AIシステムの訓練が多様で代表的なデータセットに基づいていることが確認されるため、より正確なAIシステムが実現できます。これにより、トレーニングデータではうまく機能するがテストデータでは機能しない過適合などの問題を回避できます。 偶発的な結果の回避:不適切なプロンプトで訓練されたAIシステムは、偶発的な結果をもたらす可能性があります。例えば、猫の画像を識別するのに長けたAIシステムが、すべての白黒写真を猫と分類することで、精度の低い結果をもたらすことがあります。 責任あるAIの促進:プロンプトエンジニアリングにより、AIシステムが人間の価値観や倫理的原則に沿った結論を出すことができます。AIのトレーニングに使用されるプロンプトを注意深く設計することにより、システムは偏見のないものであり、有害なものになりません。 応用 自然言語処理:NLPでは、プロンプトエンジニアリングによって、AIシステムが人間の言語を理解し、適切に応答するためのプロンプトが作成されます。例えば、プロンプトを設計して、AIシステムが皮肉、皮肉ではない表現を区別することを学ぶようにすることができます。 画像認識:プロンプトエンジニアリングは、画像認識において、AIシステムがさまざまな画像データに基づいて訓練されていることを確認するために使用できます。これにより、AIシステムのオブジェクトや人物の分類の精度と一貫性が向上します。 チャットボットにおける感情分析:プロンプトエンジニアリングは、チャットボットが感情を理解するのに役立つプロンプトを設計します。例えば、チャットボットがポジティブな応答、ネガティブな応答、中立的な応答を区別するのに役立ちます。 医療:医療診断や治療などのAIシステムは、医療データを理解し、正確な診断を行うためのプロンプトで訓練されます。 人工知能(AI)は近年、進歩を遂げ、私たちの生活、仕事、技術との対話のあり方を変えてきました。AIが社会にポジティブな影響を続けるためには、プロンプトエンジニアリングの重要性を理解する必要があります。これは、AIシステムが安全で信頼性のあるシステムを構築するために設計されたプロンプトで訓練されていることを確認することによって達成できます。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.