Learn more about Search Results A - Page 737

- You may be interested
- グーグルのディープマインドリサーチは、F...
- 「数字から行動へ:データを企業のために...
- Google AIによるコンテキストの力を解き放...
- クラスの不均衡:アンダーサンプリング技...
- ポイントクラウド用のセグメント化ガイド...
- メタAIは、CM3leonを紹介します:最先端の...
- SetFitABSA SetFitを使用したFew-Shotアス...
- 「UVeyeの共同設立者兼CEO、アミール・ヘ...
- 『ChatGPTや他のチャットボットの安全コン...
- このAI論文は、大規模な言語モデルにおけ...
- 高度な顔認識のためのDeepFace
- スタンフォード大学の研究は、PointOdysse...
- 「メーカーに会う ロボット学生がNVIDIA J...
- 「Nvidia Triton Inference Serverを使用...
- 「リアルタイム1080pの新しい視点合成の革...

「自己教師あり学習とトランスフォーマー? – DINO論文の解説」
「一部の人々は、Transformerのアーキテクチャを愛し、それをコンピュータビジョンの領域に歓迎しています他の人々は、新しいプレイグラウンドに新しい子供がいることを受け入れたくありません さて、何が起こるのか見てみましょう...」

「UniDetectorであなたが望むものを検出しましょう」
深層学習とAIは、特に検出モデルにおいて、近年驚異的な進歩を遂げてきました。しかし、これらの素晴らしい進展にもかかわらず、物体検出モデルの効果は大規模なベンチマークデータセットに大きく依存しています。しかし、課題は物体のカテゴリやシーンの変動にあります。実世界では、既存の画像とは大きな違いがあり、新しい物体クラスが現れる可能性があり、物体検出器の成功を保証するためにデータセットの再構築が必要です。残念ながら、これは彼らのオープンワールドシナリオでの一般化能力に重大な影響を与えます。これに対して、人間、特に子供でさえも、新しい環境に素早く適応し、よく一般化する能力を持っています。その結果、AIシステムと人間の知能の間には普遍性の欠如が残っています。 この制限を克服する鍵は、あらゆる種類の物体を任意のシーンで検出するための普遍的な物体検出器の開発です。このようなモデルは、追加の再トレーニングを必要とせずに未知の状況で効果的に機能する驚異的な能力を持っているでしょう。このような突破口は、物体検出システムを人間と同等に知能を持つものにする目標に大きく近づくでしょう。 普遍的な物体検出器は、2つの重要な能力を持つ必要があります。まず第一に、さまざまな情報源と異なるラベル空間からの画像を使用してトレーニングする必要があります。分類と位置検出のための大規模な共同トレーニングは、検出器が効果的に一般化するための十分な情報を獲得するために重要です。理想的な大規模学習データセットは、多くの画像タイプを含み、可能な限り多くのカテゴリを網羅し、高品質のバウンディングボックス注釈と広範なカテゴリの語彙を備えている必要があります。残念ながら、このような多様性を実現することは、人間の注釈者による制約のために困難です。実際には、小規模な語彙のデータセットはよりきれいな注釈を提供しますが、大規模なデータセットはノイズが多く、不整合が生じる可能性があります。さらに、専門のデータセットは特定のカテゴリに焦点を当てています。普遍性を達成するためには、検出器は異なるラベル空間を持つ複数の情報源から学ぶ必要があり、包括的で完全な知識を獲得します。 第二に、検出器はオープンワールドにおいて堅牢な一般化能力を示さなければなりません。トレーニング中に見たことのない新しいクラスのカテゴリタグを正確に予測する能力を持っている必要がありますが、視覚情報だけに頼ることはこの目的を達成することができません。包括的な視覚学習には完全に教師あり学習のための人間の注釈が必要です。 これらの制限を克服するために、新しい普遍的な物体検出モデル「UniDetector」が提案されました。 アーキテクチャの概要は、以下のイラストに示されています。 普遍的な物体検出器の2つの重要な能力を実現するためには、2つの対応する課題に取り組む必要があります。第一の課題は、複数の情報源からのトレーニングであり、画像が異なる情報源から来ており、異なるラベル空間と関連付けられています。既存の検出器は、1つのラベル空間からのクラスの予測に限定されており、データセット固有のタクソノミーの違いやデータセット間の注釈の不整合が、複数の異質なラベル空間を統一することを困難にしています。 第二の課題は、新しいカテゴリの識別です。最近の研究における画像テキストの事前トレーニングの成功に触発されて、著者は言語埋め込みを使用して未知のカテゴリを認識するために事前トレーニングされたモデルを活用しています。しかし、完全教師ありトレーニングは、トレーニング中に存在するカテゴリに焦点を当てる傾向があります。その結果、モデルは推論時に基本クラスに偏り、新しいクラスに対しては自信を持たない予測を行う可能性があります。言語埋め込みは新しいクラスを予測する可能性を提供しますが、その性能はまだ基本カテゴリのそれに大きく劣っています。 UniDetectorは、上記の課題に取り組むために設計されています。著者らは言語空間を活用し、異なるラベル空間で効果的に検出器をトレーニングするためにさまざまな構造を探索しています。彼らは、パーティション化された構造を採用することで、特徴の共有を促進し、ラベルの競合を回避することが、検出器のパフォーマンスに有益であることを発見しました。 新しいクラスに対する領域提案段階の一般化能力を向上させるために、著者らは、提案生成段階をRoI(Region of Interest)の分類段階から切り離し、共同トレーニングではなく個別のトレーニングを選択しました。このアプローチは、各段階の固有の特性を活用し、検出器の全体的な普遍性に貢献します。さらに、彼らはクラスに依存しない位置検出ネットワーク(CLN)を導入して一般化された領域提案を実現しました。 さらに、著者らは予測のバイアスを除去するための確率の補正技術を提案しています。彼らはすべてのカテゴリの事前確率を推定し、その事前確率に基づいて予測されたカテゴリの分布を調整します。この補正により、物体検出システム内の新しいクラスのパフォーマンスが大幅に改善されます。著者によれば、UniDetectorは最先端のCNN検出器であるDyheadを6.3% AP(平均適合率)で上回ることができます。 これは、ユニバーサルな物体検出のために設計された革新的なAIフレームワークであるUniDetectorの概要でした。もしこの研究に興味があり、詳細を知りたい場合は、以下のリンクをクリックしてさらなる情報を見つけることができます。

「LLMは強化学習を上回る- SPRINGと出会う LLM向けの革新的なプロンプティングフレームワークで、コンテキスト内での思考計画と推論を可能にするために設計されました」
SPRINGは、マルチタスクの計画と推論を必要とする対話型環境で強化学習アルゴリズムを上回るLLMベースのポリシーです。 カーネギーメロン大学、NVIDIA、アリエル大学、マイクロソフトの研究者グループは、ゲームの文脈で人間の知識を理解し推論するためにLarge Language Models (LLMs)の使用を調査しました。彼らは、学術論文を研究し、それに基づいて知識を正当化するために、SPRINGと呼ばれる2段階のアプローチを提案しています。 SPRINGの詳細について 第1段階では、著者たちはHafner (2021)のオリジナル論文のLaTeXソースコードを読み取り、事前知識を抽出しました。彼らはLLMを使用して、ゲームメカニクスや論文に記載された望ましい動作などの関連情報を抽出しました。次に、Wu et al. (2023)と類似のQA要約フレームワークを使用して、抽出した知識に基づいてQA対話を生成しました。これにより、SPRINGは多様な文脈情報を扱うことができるようになりました。 第2段階では、LLMを使用して複雑なゲームを解決するための文脈に基づいた思考の連鎖推論に焦点を当てました。質問をノードとし、質問間の依存関係をエッジとして表す有向非巡回グラフ(DAG)を推論モジュールとして構築しました。たとえば、質問「各アクションに対して要件は満たされていますか?」は、DAG内で質問「トップ5のアクションは何ですか?」にリンクされ、後者の質問から前者への依存関係が確立されます。 LLMの回答は、DAGをトポロジカル順序でトラバースすることで各ノード/質問ごとに計算されます。DAGの最後のノードは最適なアクションに関する質問を表し、LLMの回答は直接環境アクションに変換されます。 実験と結果 Hafner (2021)によって導入されたCrafter Environmentは、深さ7のテックツリーで構成された22の実績を持つオープンワールドサバイバルゲームです。このゲームは、上から見た観察と17のオプションからなる離散的なアクション空間で表されます。観察には、プレイヤーの現在のインベントリ状態(体力、食べ物、水、休息レベル、アイテムなど)に関する情報も提供されます。 著者たちは、CrafterベンチマークでSPRINGと人気のあるRL手法を比較しました。その後、アーキテクチャの異なるコンポーネントについての実験と分析を行い、LLMの文脈における「推論」能力に各部分が与える影響を調査しました。 出典: https://arxiv.org/pdf/2305.15486.pdf 著者たちは、Hafner et al. (2023)による最も優れたRL手法と比較して、Hafner…

「NTUシンガポールの研究者がResShiftを導入:他の手法と比較して、残差シフトを使用し、画像超解像度をより速く実現する新しいアップスケーラモデル」
低レベルビジョンの基本的な課題の1つは、画像のスーパーレゾリューション(SR)であり、低解像度(LR)の画像から高解像度(HR)の画像を復元することを目指しています。実世界の環境での劣化モデルの複雑さと不明瞭さのため、この問題は解決される必要があります。最近開発された生成モデルである拡散モデルは、画像の作成において非凡な成功を収めています。また、画像編集、画像補完、画像着色など、いくつかの下流の低レベルビジョンの問題にも有望な成果を示しています。さらに、困難で時間のかかるSRの作業に対して拡散モデルがどれだけうまく機能するかを調べるための研究がなされています。 典型的な手法の1つは、現在の拡散モデル(例:DDPM)の入力にLR画像を導入した後、SRのためのトレーニングデータを使用してモデルをゼロから再トレーニングすることです。もう1つの一般的な手法は、目的のHR画像を生成する前に、無条件の事前トレーニング済みの拡散モデルの逆経路を変更することです。残念ながら、これらのアルゴリズムの両方には、DDPMを基盤とするマルコフ連鎖が継承されています。図1の推論を高速化するためにDDIMアルゴリズムが使用されていますが、推論中のサンプルステップを圧縮するためのいくつかの加速手法が考案されています。これらの手法は、パフォーマンスのかなりの低下と過度に滑らかな結果につながることがしばしばあります。 図1は、BSRGAN、RealESRGAN、SwinIR、DASR、およびLDMを含む最近の状況と提案手法の品質を比較しています。LDMと彼らの手法に関しては、より理解しやすい視覚化のために「LDM(またはOurs)-A」という式を使用して、サンプリングステップの数を示しています。ここで、「A」はサンプリングステップの総数です。LDMは訓練時に1000の拡散ステップを持ち、推論時にDDIMを使用して「A」ステップに加速されます。より明確に見るために拡大してください。 効率とパフォーマンスの両方を損なうことなく、SRのための新しい拡散モデルを作成する必要があります。画像作成のための拡散モデルを見直してみましょう。前進のプロセスでは、マルコフ連鎖が多くのステップで構築され、観測データが事前に指定された分布(通常は従来のガウス分布)に徐々に変換されます。次に、事前分布からノイズマップをサンプリングし、マルコフ連鎖の逆経路に供給することで、画像を生成することができます。ガウス分布は画像生成には適していますが、LR画像が既に利用可能なため、SRには最適な選択肢ではないかもしれません。 この研究での主張によれば、SRの適切な拡散モデルは、ガウスのホワイトノイズではなく、LR画像を基にした事前分布から始めるべきであり、LR画像からHR画像を反復的に復元することが可能です。このような設計は、サンプリングに必要な拡散ステップの数を削減し、推論の効率を高めることもできます。南洋理工大学の研究者たちは、HR画像とそれに相当するLR画像の間を切り替えるために、より短いマルコフ連鎖を使用する効果的な拡散モデルを提案しています。マルコフ連鎖の初期状態はHR画像の分布を近似し、終端状態はLR画像の分布を近似します。 彼らは丁寧にトランジションカーネルを作成し、それらの間の残差を徐々に調整するために使用しています。残差情報はいくつかの段階で迅速に伝達することができるため、この技術は現在の拡散ベースのSR手法よりも効果的です。さらに、彼らのアーキテクチャは、訓練の最適化目標の導出を簡素化するために、証拠下限を明確で分析的な方法で表現することが可能です。彼らはこの構築された拡散カーネルに基づく非常に柔軟なノイズスケジュールを作成し、残差の移動速度と各ステップのノイズレベルを調整します。 ハイパーパラメータを調整することで、このスケジュールは取得した結果の忠実度と現実性のトレードオフを可能にします。以下に、この研究の重要な貢献を示します: • 彼らはSRに対して効果的な拡散モデルを提供しており、推論時に2つの間の残差を移動することで、望ましくないLR画像から望ましいHR画像への反復サンプリングプロセスを可能にします。詳細な研究により、彼らの手法の効率性が示されています。望ましい結果を得るためにわずか15の簡単なステップしか必要とせず、長時間のサンプリング手法が必要な既存の拡散ベースのSR技術を上回るか、少なくとも同等の結果を示します。図1は、既存の技術と比較した彼らの取得した結果の一部を示しています。 • 提案された拡散モデルに対して、より正確な制御を可能にする高度に可変なノイズスケジュールを開発しています。

UCバークレーの研究者たちは、ビデオ予測報酬(VIPER)というアルゴリズムを紹介しましたこれは、強化学習のためのアクションフリーの報酬信号として事前学習されたビデオ予測モデルを活用しています
手作業で報酬関数を設計することは時間がかかり、予期しない結果をもたらす可能性があります。これは、強化学習(RL)ベースの汎用意思決定エージェントの開発における主要な障害です。 従来のビデオベースの学習方法では、現在の観測値がエキスパートのものに最も似ているエージェントを報酬することができます。ただし、報酬は現在の観測値にのみ依存するため、時間を通じた意味のある活動を捉えることはできません。また、敵対的なトレーニング技術によるモードの崩壊により、一般化が妨げられます。 UCバークレーの研究者は、ビデオ予測モデルからインセンティブを抽出するための新しい方法、ビデオ予測インセンティブ強化学習(VIPER)を開発しました。VIPERは、生の映画から報酬関数を学習し、未学習のドメインにも一般化することができます。 まず、VIPERはエキスパートによって生成された映画を使用して予測モデルを訓練します。次に、ビデオ予測モデルを使用して強化学習のエージェントを訓練し、エージェントの軌跡の対数尤度を最適化します。エージェントの軌跡の分布は、ビデオモデルの分布と一致するように最小化する必要があります。ビデオモデルの尤度を直接報酬信号として使用することで、エージェントはビデオモデルと似た軌跡分布をたどるように訓練されることがあります。観測レベルの報酬とは異なり、ビデオモデルによって提供される報酬は行動の時間的一貫性を定量化します。また、尤度の評価はビデオモデルのロールアウトよりもはるかに高速であるため、より迅速なトレーニング時間枠と環境とのより大きな相互作用を可能にします。 15のDMCタスク、6のRLBenchタスク、7のAtariタスクを対象に、チームは徹底的な研究を行い、VIPERがタスクの報酬を使用せずにエキスパートレベルの制御を達成できることを示しています。調査結果によると、VIPERで訓練されたRLエージェントは、敵対的な模倣学習を上回ります。VIPERは設定に統合されているため、どのRLエージェントが使用されているかは関係ありません。ビデオモデルは、トレーニング中に遭遇しなかった腕/タスクの組み合わせにすでに一般化されています。 研究者たちは、大規模な事前学習済み条件付きビデオモデルを使用することで、より柔軟な報酬関数が可能になると考えています。生成モデリングの最近のブレークスルーのおかげで、彼らの研究は未ラベルの映画からのスケーラブルな報酬指定のためのコミュニティに基盤を提供していると信じています。

「効果的なマーケティング戦略開発のための機械学習の活用」
マーケティングアトリビューションモデルは、マーケティング戦略を構築するために広く使用されていますこれらの戦略は、顧客の旅程全体において各タッチポイントにクレジットを割り当てることに基づいていますたくさんの...
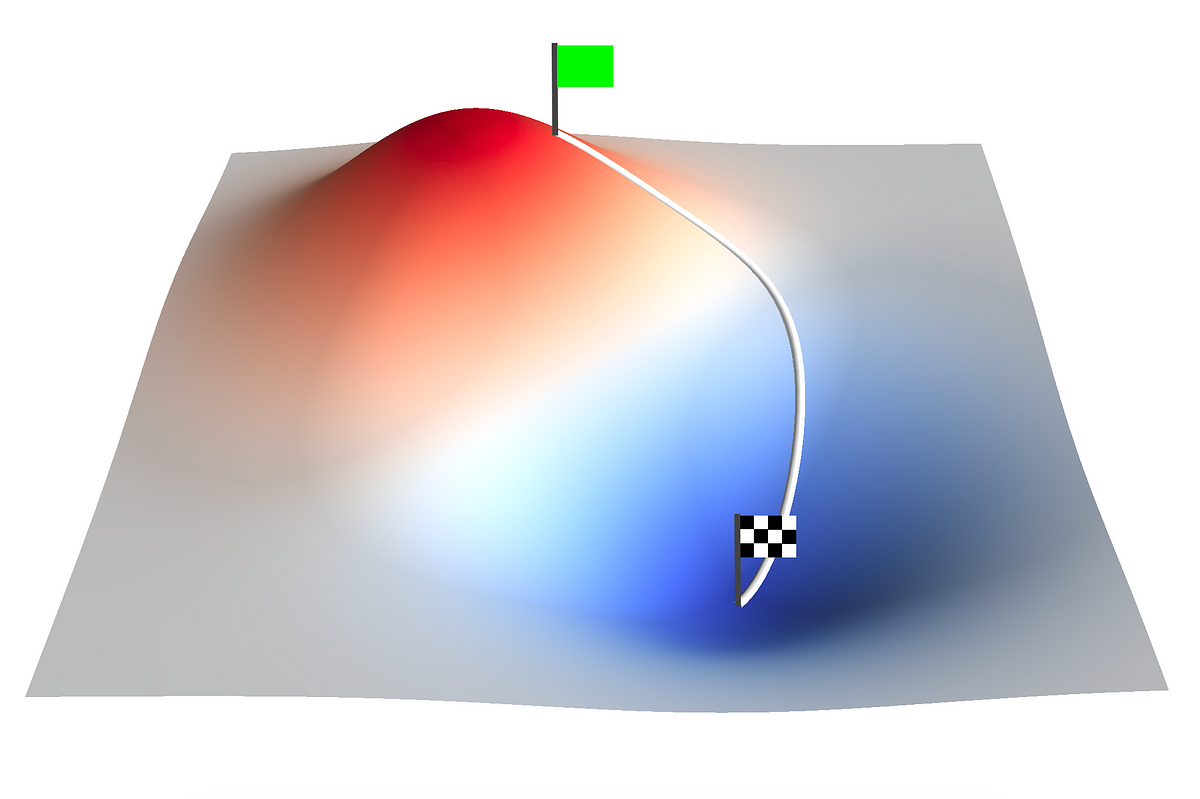
PIDコントローラの最適化:勾配降下法のアプローチ
「機械学習ディープラーニングAIこれらの技術を日々利用する人々がますます増えていますこれは、ChatGPTやBardなどによって展開された大規模言語モデルの台頭によって大いに推進されています...」

「LLMsを使用したモバイルアプリの音声と自然言語の入力」
この記事では、GPT-4の関数呼び出しを使用してアプリに高度な柔軟性のある音声理解を実現する方法について学びますこれにより、アプリのGUIと完全にシナジーを発揮することができます

GPU を最大限に活用せずに LLM を微調整する
ただし、採用には障壁がありましたこれらのモデルは非常に大きいため、予算の少ない企業や研究者、または趣味を持つ人々が独自の目的に合わせてカスタマイズすることは困難でした...

時系列予測における相互作用項に関する包括的なガイド
時系列データのモデリングは、その固有の複雑さと予測不能性のため、挑戦的(かつ魅力的)なものとなることがありますたとえば、時系列の長期的なトレンドは、特定の要因によって劇的に変化することがあります...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.