Learn more about Search Results 大規模な言語モデル - Page 72

- You may be interested
- 「ペンタゴンによって設立された生成AIの...
- 「CREATORと出会ってください:ドキュメン...
- UCSDとMicrosoftの研究者がColDecoを導入...
- AIOpsの力を解き放つ:最適化されたITオペ...
- 適切なウェブサイト最適化でコンピュータ...
- AIにおける継続的学習の現状について
- 「InstaFlowをご紹介します:オープンソー...
- 「AVIS内部:Googleの新しい視覚情報検索L...
- 「オーディオ機械学習入門」
- 専門AIトレーニングの変革- LMFlowの紹介...
- ハッギングフェイスのオートトレインを使...
- 「初心者のためのイメージ分類」
- 「このAI論文は、超人的な数学システムの...
- Google Cloud上のサーバーレストランスフ...
- 「多言語AIは本当に安全なのか?低リソー...

スケールを通じた高精度の差分プライバシー画像分類の解除
前の研究の経験的な証拠によると、DP-SGDにおける効用の低下は、より大規模なニューラルネットワークモデルでより深刻になる傾向がありますこれには、難しい画像分類のベンチマークで最高のパフォーマンスを達成するために定期的に使用されるモデルも含まれます私たちの研究では、この現象を調査し、トレーニング手順とモデルアーキテクチャの両方に一連の単純な修正を提案して、標準的な画像分類ベンチマークでのDPトレーニングの正確性を大幅に向上させることを示しています

DeepMindの最新の研究(ICML 2022)
今週末から、第39回国際機械学習会議(ICML 2022)が2022年7月17日から23日まで、アメリカのメリーランド州ボルチモアのボルチモア・コンベンションセンターでハイブリッド形式で開催されます人工知能、データサイエンス、機械ビジョン、計算生物学、音声認識などの分野で研究を行っている研究者たちが、機械学習の最先端の研究成果を発表し、出版します

AIとの対話:より優れた言語モデルの構築
私たちの新しい論文「AIとの対話:人間の価値観に合わせた言語モデルの調整」は、異なるアプローチを探求しています人間と人工会話エージェントの間で成功するコミュニケーションがどのように見え、このような文脈での対話を導くべき価値観は何かを問いかけます

安全な対話エージェントの構築
私たちの最新の論文では、Sparrowという対話エージェントを紹介しますこのエージェントは有用であり、危険な回答や不適切な回答のリスクを軽減します私たちのエージェントはユーザーと話し、質問に答え、必要に応じてGoogleを使用してインターネットを検索し、回答に基づく根拠を提供します

正しい報酬によって望ましくない目標が生じる方法
AIシステムをますます高度化するにつれて、私たちはそれらが望ましくない目標を追求しないようにする必要がありますAIエージェントのこのような振る舞いは、仕様ゲーミングと呼ばれるものであり、報酬の選択が不適切であることを利用しています私たちの最新の論文では、AIシステムが意図しない目標を追求するように学習する可能性のある、より微妙なメカニズムである「目標誤解釈(GMG)」を探求していますGMGは、システムの能力が成功裏に一般化する一方で、目標が望ましいように一般化しない場合に発生しますしたがって、システムは誤った目標を上手に追求してしまいます重要な点は、仕様ゲーミングとは異なり、GMGはAIシステムが正しい仕様で訓練されている場合でも発生する可能性があるということです

DataHour ChatGPTの幻視を80%減らす
はじめに 自然言語処理(NLP)モデルは近年、チャットボットから言語翻訳までさまざまなアプリケーションで人気が高まっています。しかし、NLPの最大の課題の1つは、モデルによって生成されるChatGPTの幻覚や不正確な応答を削減することです。この記事では、NLPモデルの幻覚を削減するために必要な技術と課題について説明します。 観測性、調整、テスト 幻覚を削減するための最初のステップは、モデルの観測性を向上させることです。これには、ユーザーフィードバックとモデルのパフォーマンスをプロダクションでキャプチャするフィードバックループの構築が含まれます。調整では、より多くのデータを追加したり、検索の問題を修正したり、プロンプトを変更したりすることで、不正確な応答を改善します。テストは、変更が結果を改善し、回帰を引き起こさないことを確認するために必要です。観測性の課題には、顧客が不正確な応答のスクリーンショットを送信することによって引き起こされるイライラが含まれます。これに対処するために、データの取り込みと秘密のコードを使用してログを毎日監視することができます。 言語モデルのデバッグとチューニング 言語モデルのデバッグとチューニングのプロセスでは、モデルの入力と応答を理解することが重要です。デバッグには、生のプロンプトを特定のチャンクや参照に絞り込むためにログが必要です。ログは、誰にでも理解しやすく、実行可能なものでなければなりません。チューニングでは、モデルにどれだけのドキュメントを与えるべきかを決定します。デフォルトの数値は常に正確ではなく、類似検索では正しい答えが得られないことがあります。目標は、何がうまくいかなかったのか、それを修正する方法を見つけることです。 OpenAI埋め込みの最適化 アプリケーションで使用されるOpenAI埋め込みのパフォーマンスを最適化することに直面したベクトルデータベースクエリアプリケーションの開発者は、いくつかの課題に直面しました。最初の課題は、モデルに渡す最適なドキュメント数を決定することであり、これはチャンキング戦略の制御とドキュメント数のための制御可能なハイパーパラメータの導入によって解決されました。 2番目の課題は、プロンプトのバリエーションであり、Better Promptというオープンソースライブラリを使用して、パープレキシティに基づいて異なるプロンプトバージョンのパフォーマンスを評価しました。3番目の課題は、マルチリンガルシナリオでの文の変換子よりもOpenAI埋め込みの結果の改善が見つかったことです。 AI開発の技術 この記事では、AI開発で使用される3つの異なる技術について説明しています。最初の技術はパープレキシティであり、与えられたタスクにおけるプロンプトのパフォーマンスを評価するために使用されます。2番目の技術は、ユーザーが異なるプロンプト戦略を簡単にテストできるパッケージの構築です。3番目の技術は、インデックスの実行であり、何かが欠けているか理想的でない場合に追加のデータを使用してインデックスを更新することが含まれます。これにより、質問のよりダイナミックな処理が可能になります。 GPT-3 APIを使用してパープレキシティを計算する スピーカーは、クエリに基づいてパープレキシティを計算するためにGPT-3 APIを使用した経験について説明しています。彼らはAPIを介してプロンプトを実行し、最適な次のトークンのログ確率を返すプロセスについて説明しています。また、新しい情報を埋め込むのではなく、特定の書き方を模倣するために大規模な言語モデルを微調整する可能性についても言及しています。 複数の質問に対する応答の評価 テキストでは、50以上の質問に対する応答の評価の課題について説明しています。すべての応答を手動で採点するのは時間がかかるため、会社は自動評価ツールの使用を検討しました。しかし、単純なはい/いいえの判断枠組みでは不十分であり、回答が正しくない理由は複数あります。会社は評価をさまざまなコンポーネントに分割しましたが、自動評価ツールの単一の実行は不安定で一貫性がありませんでした。これを解決するために、質問ごとに複数のテストを実行し、応答を完璧、ほぼ完璧、一部正しい情報を含む不正確、完全に不正確なものに分類しました。 NLPモデルでの幻覚の削減 スピーカーは、自然言語処理モデルでの幻覚を削減するためのプロセスについて説明しています。彼らは意思決定プロセスを4つのカテゴリに分け、50以上のカテゴリに対して自動機能を使用しました。また、評価プロセスをコア製品に展開し、評価を実行してCSBにエクスポートすることも可能にしました。スピーカーはプロジェクトに関する詳細情報のためのGitHubリポジトリに言及しています。そして、観測性、調整、テストなどの手順を取り上げ、幻覚率を40%から5%未満に削減することができました。 結論 NLPモデルにおけるChatGPTの幻想を減らすことは、可観測性、調整、テストといった複雑なプロセスを必要とします。開発者はプロンプトのバリエーション、埋め込みの最適化、複数の質問に対する応答の評価も考慮する必要があります。また、困惑度、プロンプト戦略のテスト用パッケージの作成、インデックスの実行といったテクニックもAI開発に役立つことがあります。AI開発の未来は、小規模でプライベート、またはタスク固有の要素にあります。 要点 NLPモデルにおけるChatGPTの幻想を減らすには、可観測性、調整、テストが必要です。…
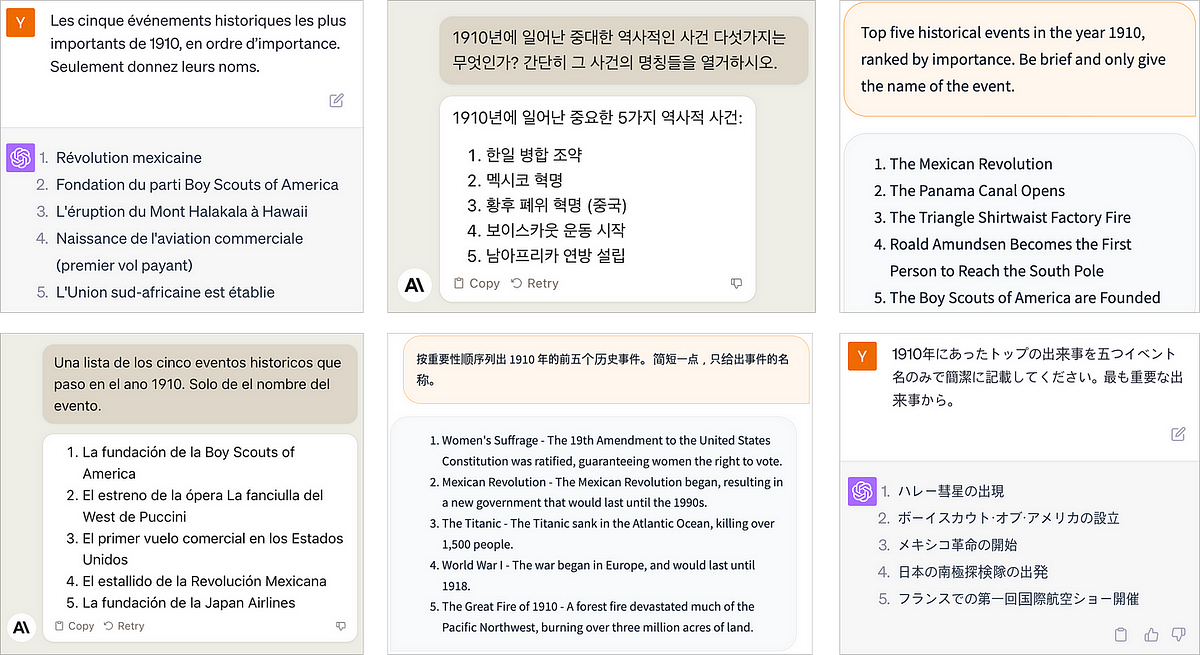
AIのレンズを通じた世界の歴史
人工知能の進歩、特に大規模な言語モデルにより、歴史研究や教育においては興奮すべき可能性が広がっていますしかし、その方法については慎重に検証することが重要です...

PandasAIの紹介:GenAIを搭載したデータ分析ライブラリ
イントロダクション 最近、ジェネレーティブ人工知能の分野で急速な発展とブレークスルーがあり、データ分野においても大きな変革が起きています。企業は、ChatGPTなどのイノベーションを最大限に活用する方法を模索しています。これにより、どんなビジネスでも競争上の優位性を得ることができます。新しい最先端のイノベーションとして、通常のPandasライブラリに「PandasAI」という名前のGenAIパワードのデータ分析ライブラリを導入しています。これはOpenAIが行っています。ジェネレーティブAIの他の領域とは異なり、PandasAIはGenAIの技術を分析ツールPandasに適用しています。 名前の通り、これは従来のPandasライブラリに人工知能を直接適用しています。Pandasライブラリは、Pythonを使用した前処理やデータの可視化などのタスクにおいて、データ分野で非常に人気があり、このイノベーションによってさらに良くなりました。 学習目標 新しいPandasAIの理解 会話型クエリを使用したPandasAIの使用 PandasAIを使用したグラフのプロット PandasAIおよびそのバックエンド(GenAI)の概要 この記事は、Data Science Blogathonの一環として公開されました。 PandasAIとは何ですか? PandasAIは、Generative AIモデルを使用してpandasでタスクを実行するPythonライブラリです。これは、Prompt Engineeringを使用してPandasデータフレームを会話形式にするために、Generative AIの機能を統合したライブラリです。Pandasを思い出すと、データの分析と操作が思い浮かびます。PandasAIでは、GenAIの恩恵を受けながら、Pandasの生産性を向上させようとしています。 なぜPandasAIを使用するのですか? Generative AIの助けを借りて、データセットに対して会話的なプロンプトを与える必要があります。これにより、学習や理解に複雑なコードを必要としなくなります。データサイエンティストは、自然な人間の言語を使ってデータセットにクエリを投げることができ、結果を得ることができます。これにより、前処理と分析にかかる時間が節約されます。これは、プログラマがコードを書く必要がない新しい革命です。彼らはただ思っていることを言い、その指示が実行されるのを見るだけです。非技術者でも複雑なコードを書かずにシステムを構築することができるようになりました! PandasAIはどのように動作しますか? PandasAIの使用方法を見る前に、PandasAIがどのように動作するかを見てみましょう。ここで「ジェネレーティブ人工知能」という用語を何度も使用しています。これは、PandasAIの実装の背後にある技術として機能しています。ジェネレーティブAI(GenAI)は、テキスト、オーディオ、ビデオ、画像、3Dモデルなど、さまざまなデータタイプを生成できる人工知能のサブセットです。これは、既に収集されたデータのパターンを特定し、それらを利用して新しい独自の出力を作成することで実現されます。 もう一つ注意すべきことは、大規模な言語モデル(LLM)の使用です。PandasAIは、数千万から数十億のパラメータを持つ人工ニューラルネットワーク(ANN)からなるモデルであるLLMに基づいてトレーニングされています。これにより、PandasAIの背後にあるモデルは、人間の指示を受け取り、解釈する前にトークン化することができます。PandasAIはまた、LangChainモデルを扱うように設計されており、LLMアプリケーションの構築を容易にします。 Pandas AIの始め方…
OpenAIのモデレーションAPIを使用してコンテンツのモデレーションを強化する
プロンプトエンジニアリングの台頭や、言語モデルの大規模な成果により、私たちの問いに対する応答を生成する際の大変な成果を上げたLarge Language Modelsの注目すべき成果により、ChatGPTのようなチャットボットは私たちの日常生活の重要な一部となりつつあります...

JourneyDBとは:多様かつ高品質な生成画像が400万枚収録された大規模データセットであり、マルチモーダルな視覚理解のためにキュレーションされています
ChatGPTやDALL-Eなどの大規模な言語モデルの進化と、生成型人工知能の人気の上昇により、人間のようにコンテンツを生成することはもはや夢ではありません。質問応答、コードの補完、テキストの説明からのコンテンツの生成、テキストと画像の両方からの画像の作成など、すべてが実現可能になりました。最近、AIは人間の創造力に匹敵するまでになりました。OpenAIが開発した有名なチャットボットであるChatGPTは、GPT 3.5のトランスフォーマーアーキテクチャを基にしており、ほとんどの人に使用されています。最新バージョンのGPT、つまりGPT 4は、以前のバージョンであるGPT 3.5とは異なり、マルチモーダルな性質を持っています。ChatGPTは、テキストの入力のみを受け付けることができます。 拡散モデルの開発により、生成コンテンツの品質は大幅に向上しました。これらの進歩により、DALLE、Stability AI、Runway、MidjourneyなどのAI生成コンテンツ(AIGC)プラットフォームがますます人気を集めています。これらのシステムは、自然言語で提供されるテキストプロンプトに基づいて高品質の画像を作成することができます。マルチモーダルな理解の進歩にもかかわらず、ビジョン言語モデルはまだ生成された視覚的なものを理解するのに苦労しています。実際のデータに比べて、合成画像はより大きな内容とスタイルの変動性を示し、モデルが適切にそれらを理解することははるかに困難です。 これらの問題に対処するため、研究者のチームはジャーニーDBという大規模なデータセットを導入しました。このデータセットは、生成画像のマルチモーダルな視覚理解のために特別に作成された400万以上のユニークな高品質な生成写真を含んでいます。このデータセットは、コンテンツとスタイルの解釈の両方に焦点を当て、生成された画像の理解能力を訓練および評価するための完全なリソースを提供することを目指しています。 提案されたベンチマークに含まれる4つのタスクは以下の通りです。 プロンプトの反転 – プロンプトの反転は、ユーザーが画像を生成するために使用したテキストプロンプトを見つけるために使用されます。これにより、モデルの生成画像の内容とスタイルの理解がテストされます。 スタイルの検索 – チームはスタイルの検索に焦点を当て、モデルがスタイル属性に基づいて似たような生成画像を識別して取得することを目指しています。これにより、モデルが生成画像内のスタイルの微妙なニュアンスを識別する能力が評価されます。 画像キャプション – 画像キャプションでは、モデルに対して生成画像の内容を正確に表現する記述的なキャプションを生成するように指示されます。これにより、モデルのビジュアルコンテンツを効果的に自然言語で理解および表現する能力が評価されます。 ビジュアル質問応答 – ビジュアル質問応答(VQA)を通じて、モデルは生成画像に関連する質問に正確に答えることができます。モデルはビジュアルおよびスタイルのコンテンツを理解し、与えられた質問に基づいて関連する回答を提供することができます。 チームは4,692,751の画像とテキストのプロンプトのペアを収集し、トレーニングセット、バリデーションセット、テストセットに分割しました。チームはベンチマークデータセットを使用して、幅広い実験を行いました。その結果、現在の最先端のマルチモーダルモデルは、実際のデータセットと同じくらいうまく機能しないことがわかりましたが、提案されたデータセットに対するいくつかの調整により、性能が大幅に向上しました。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.