Learn more about Search Results A - Page 728

- You may be interested
- ChatGPTはナップサック問題を解決できます...
- 「LLMsにおけるエンタープライズ知識グラ...
- 「OpenAIと共にAI製品を開発する CoRiseか...
- 「ロボット支援TMSによるうつ病治療の可能...
- 「シェアレンティングの危険性:オンライ...
- オーディオSRにお会いください:信じられ...
- 「Amazon SageMakerを使用して、ファルコ...
- 「生成型AIが必須のスキルとなった理由」
- 安定した拡散:生成AIの基本的な直感
- 抽象生成(特定語)- 直感的で徹底的に説...
- 「エヴァ・マリー・ミュラー=シュトゥー...
- 「スタンフォード大学の新しいAI研究は、...
- 冷静でクールで創造的:MUEスタジオが3Dシ...
- AWS上で請求書処理を自動化するためのサー...
- スタートアップ企業向けの20の最高のChatG...
「あなたのLLMアプリを守る必読です!」
「大規模言語モデルアプリケーションのOWASPトップ10プロジェクトは、開発者、デザイナー、アーキテクト、マネージャー、そして組織に、展開および...」
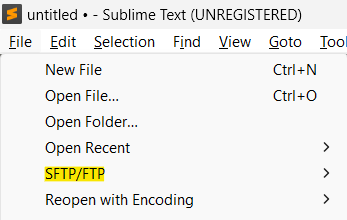
ファイル管理の効率化:サーバーまたはサーバー上で実行されているDockerコンテナーにおけるファイルの接続と変更をSFTPを使用してSublime Textで行うためのガイド
現在、多くの学術機関、研究所、およびクラウドサービスプロバイダーは、人々が実験を実行するためにアクセスできるGPU搭載サーバーを提供していますたとえば、私の大学は...
「コードを使用して、大規模な言語モデルを使って、どんなPDFや画像ファイルでもチャットする方法」
「PDFや画像ファイルには非常に価値のある情報が閉じ込められています幸いにも、私たちにはこれらのファイルを処理して特定の情報を見つけることができる強力な脳があります実際、それは素晴らしいことですそれが…」

「マイクロソフト、『極めて無責任』なセキュリティ対策で厳しい批判を受ける」
エクスプロイトと脆弱性の重みに押し潰されるカードのように、Azureは崩壊しているように見えます
『過学習から卓越へ:正則化の力を活用する』
機械学習に関して言えば、私たちの目的は、訓練されていないデータに対して最も正確な予測を行うMLモデルを見つけることですそのために、訓練データでMLモデルを訓練し、どのように機能するかを確認します

「5分でPythonとTkinterを使用してシンプルなユーザーフォームを作成する-初心者ガイド」
「今日、全てのビジネスが『デジタル化』することがトレンドになってきましたそれが小さなビジネスであっても大きなビジネスであっても、情報を手動で収集するよりもアプリケーションを利用する方が便利ですそれは…」

「15Rockの共同創業者兼CEO、ガウタム・バクシ氏によるインタビューシリーズ」
「ガウタム・バクシは、気候リスク管理とアドバイザリーサービスのグローバルリーダーである15Rockの共同創設者兼CEOですガウタムは、テクノロジー、リサーチ、製品、オペレーションを含むすべての15Rockの主要な運営部門の日々の監督を担当しています気候変動への関心が生まれた経緯と、気づいた時期について、お話しいただけますか?」

映画チャットをご紹介しますビデオの基礎モデルと大規模な言語モデルを統合した革新的なビデオ理解システムです
大規模言語モデル(LLM)は最近、自然言語処理(NLP)の分野で大きな進歩を遂げています。LLMにマルチモーダリティを追加し、マルチモーダルな大規模言語モデル(MLLM)に変換することで、マルチモーダルな知覚と解釈を行うことができます。MLLMは人工一般知能(AGI)への可能な一歩として、存在、数え上げ、位置、OCRなどの知覚、常識的な推論、コード推論などのさまざまなマルチモーダルタスクで驚異的な新たなスキルを示しています。MLLMは、LLMや他のタスク特化モデルと比較して、より人間らしい環境の視点、ユーザーフレンドリーなインターフェース、幅広いタスク解決スキルを提供します。 既存のビジョン中心のMLLMは、Q-formerや基本的なプロジェクション層、事前学習済みLLM、ビジョンエンコーダ、および追加の学習可能モジュールを使用しています。異なるパラダイムでは、現在のビジョンパーセプションツール(トラッキングや分類など)をLLMとAPIを介して組み合わせ、トレーニングなしでシステムを構築します。以前のビデオセクターの研究では、このパラダイムを使用してビデオMLLMを開発しました。しかし、長さが1分以上の長い映画に基づくモデルやシステムの調査はこれまで行われておらず、これらのシステムの有効性を測定するための基準も存在しませんでした。 この研究では、浙江大学、ワシントン大学、マイクロソフトリサーチアジア、香港大学の研究者が、ビジョンモデルとLLMを組み合わせた長いビデオ解釈の課題のためのユニークなフレームワークであるMovieChatを紹介しています。彼らによれば、長いビデオ理解の残りの困難は、計算の困難さ、メモリの負荷、長期的な時間的関連性です。これを実現するために、彼らはAtkinson-Shiffrinメモリモデルに基づいたメモリシステムを提案しています。このメモリシステムは、迅速に更新される短期記憶とコンパクトな長期記憶を含みます。 このユニークなフレームワークは、ビジョンモデルとLLMを組み合わせ、長いビデオ理解のタスクを可能にする最初のものです。この研究では、理解能力と推論コストの両方のパフォーマンスを評価するための厳格な数量的評価と事例研究を行い、計算の複雑さとメモリのコストを最小化し、長期的な時間的関連性を向上させるためのメモリメカニズムを提供しています。この研究は、巨大な言語モデルとビデオ基盤モデルを組み合わせたビデオの理解に向けた新しいアプローチを提示しています。 このシステムは、Atkinson-Shiffrinモデルに触発されたメモリプロセスを含むことで、長い映画の分析に関する困難を解決します。このメモリプロセスは、トランスフォーマー内のトークンで表される短期記憶と長期記憶で構成されています。提案されたシステムであるMovieChatは、わずかなフレームしか処理できない以前のアルゴリズムに比べて、長いビデオ理解において最先端のパフォーマンスを達成することで優れた結果を出しています。この方法は、長期的な時間的関係を扱いながら、メモリ使用量と計算の複雑さを低下させます。この研究は、ビデオ理解におけるメモリプロセスの役割を強調し、モデルが重要な情報を長期間保存し、呼び出すことができるようにします。MovieChatの人気は、コンテンツ分析、ビデオ推奨システム、ビデオモニタリングなどの産業に実用的な影響を与えます。将来の研究では、メモリシステムを強化し、音声などの追加のモダリティを使用してビデオ理解を向上させる方法について検討することができます。この研究は、視覚データの徹底的な理解を必要とするアプリケーションの可能性を創出します。彼らのウェブサイトには複数のデモがあります。
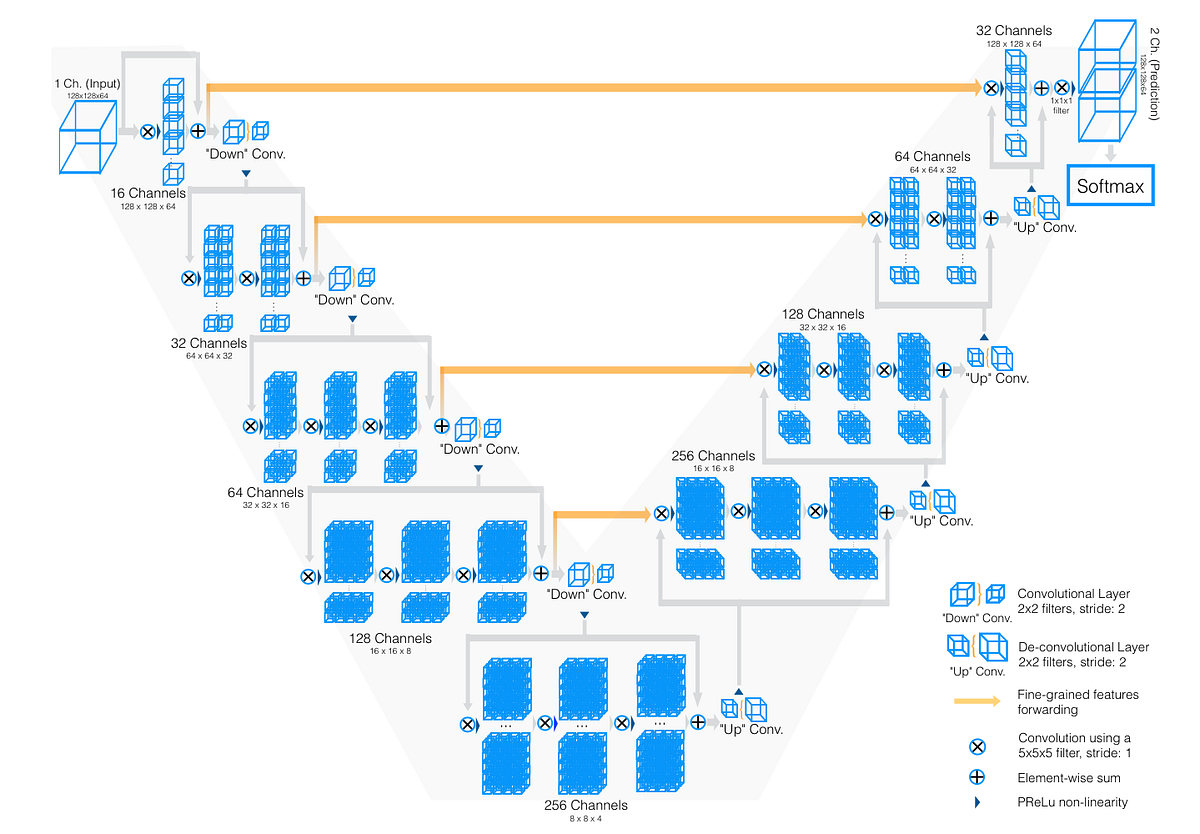
「V-Net、イメージセグメンテーションにおけるU-Netの兄貴」
イメージセグメンテーションと医療画像のためのV-Net、U-Netの兄弟分についてのレビューと紹介データサイエンティストや医療関係者に最適です
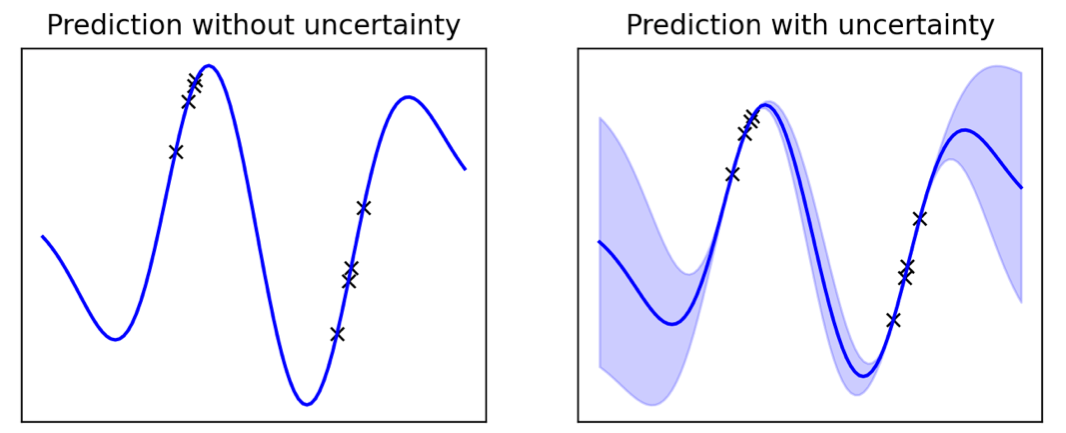
ベイズ深層学習への優しい入門
「確率的プログラミングの興奮する世界へようこそ!この記事は初心者向けのベイズ深層学習とディープニューラルネットワークの紹介です」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.