Learn more about Search Results ダウンロード - Page 71

- You may be interested
- 「UBCカナダの研究者が、都市ドライバーに...
- 『基礎に戻る週間2 データベース、SQL、デ...
- AWSの知的ドキュメント処理を生成AIで強化...
- 「AIに友達になる」
- イネイテンスとは何か?人工知能にとって...
- 「23andMeにおける複数の個人情報漏洩」
- 「チップの戦いに勝ちたいですか?たくさ...
- 現代の生成的AIアプリケーションにおける...
- 光ニューラルネットワークとトランスフォ...
- 「データパイプラインについての考え方が...
- AI/MLを活用してインテリジェントなサプラ...
- 高度な顔認識のためのDeepFace
- 「機械学習のための現実世界のデータ収集...
- なぜデータは「新しい石油」ではなく、デ...
- 「2023年に機械学習とコンピュータビジョ...

AWS上で動作する深層学習ベースの先進運転支援システムのための自動ラベリングモジュール
コンピュータビジョン(CV)では、興味のあるオブジェクトを識別するためのタグを追加したり、オブジェクトの位置を特定するためのバウンディングボックスを追加したりすることをラベリングと呼びますこれは、深層学習モデルを訓練するためのトレーニングデータを準備するための事前のタスクの1つです数十万時間以上の作業時間が、様々なCVのために画像やビデオから高品質なラベルを生成するために費やされています

2023年の最高のサイバーセキュリティニュースレター
サイバーセキュリティのニュースレターは、幅広いトピックをカバーし、さまざまな読者のニーズに対応していますこの分野で先を見越したいと思っている人にとって、非常に役立ちます

新しい言語モデルを評価するための3つの重要な方法
毎週新しいLLMがリリースされますが、私のように考えると、これはついに私がLLMを利用したいすべてのユースケースに適合するのでしょうか?このチュートリアルでは、私は...を共有します

CMUの研究者がFROMAGeを紹介:凍結された大規模言語モデル(LLM)を効率的に起動し、画像と交錯した自由形式のテキストを生成するAIモデル
巨大な言語モデル(LLM)は、大規模なテキストコーパスでスケールに基づいて訓練されているため、人間のような話し言葉を生成したり、複雑な問いに応答したりするなど魅力的なスキルを発揮することができます。これらのモデルは非常に素晴らしいものですが、ほとんどの先端的なLLMはインターネットからダウンロードしたテキストデータのみで訓練されています。そのため、豊富な視覚的手がかりに触れる必要があるため、実世界に基づく概念を吸収することができません。その結果、現在使用されているほとんどの言語モデルは、視覚的な推論や基盤を必要とするタスクに制約があり、また視覚的な要素を生成することができません。本記事では、凍結されたLLMの能力をマルチモーダル(画像とテキスト)の入力と出力に効果的に使用する方法を示しています。 彼らは、言語モデルを訓練して、画像の代わりになる[RET]トークンを学習させ、コントラスティブラーニングを使用して[RET]の埋め込みを、それに関連する画像の視覚的な埋め込みに近づける線形マッピングも行っています。訓練中には、線形層と[RET]トークンの埋め込みの重みのみが更新され、モデルの大部分は凍結されたままです。そのため、彼らの提案手法はメモリと計算効率が非常に高いです。訓練が完了すると、モデルはいくつかのスキルを示します。元のテキストのみのLLMがテキストを生成する能力に加えて、新たなマルチモーダルの会話と推論のスキルを持っています。彼らの提案手法はモデルに依存せず、より強力なまたは大きなLLMの将来のリリースの基盤として使用することができます。 言語モデルは、画像を表す新しい[RET]トークンを学習し、コントラスティブラーニングを使用して、キャプションの[RET]の埋め込みを対応する画像の視覚的な埋め込みに近づける線形マッピングを行います。訓練中には、線形層と[RET]トークンの埋め込みの重みのみが更新され、モデルの大部分は固定されたままです。その結果、彼らの提案手法はメモリと計算効率が非常に高いです。訓練が完了すると、彼らのモデルはいくつかのスキルを示します。元のテキストのみのLLMがテキストを生成する能力に加えて、新たなマルチモーダルの会話と推論のスキルを持っています。彼らの提案手法はモデルに依存せず、より強力なまたは大きなLLMの将来のリリースの基盤として使用することができます。 オートリグレッシブLLMによるテキストから画像への検索の感度の向上を示しています。彼らの主な貢献の一つは、凍結された検索を使用したマルチモーダルデータに対するオートリグレッシブジェネレーション(FROMAGe)モデルであり、画像キャプションとコントラスティブラーニングを通じてLLMを視覚的に固定することが効果的に訓練されています。以前のアルゴリズムはウェブスケールの画像テキストデータが必要でしたが、FROMAGeは画像キャプションのペアだけから強力なフューショットのマルチモーダル能力を開発しています。彼らの手法は、以前のモデルよりも長く複雑な自由形式のテキストに対してより正確です。視覚的な入力を必要とするタスクにおいて、事前に訓練されたテキストのみのLLMの現在のスキル、コンテキストでの学習、入力の感度、会話の作成などを活用する方法を示しています。 彼らは以下を示しています:(1) 画像とテキストが交互に並ぶシーケンスからの文脈に基づいた画像の検索、(2) ビジュアルな会話におけるゼロショットの優れたパフォーマンス、および(3) 画像の検索における強化された対話文脈の感度。彼らの結果は、マルチモーダルなシーケンスの学習と生成を可能にするモデルの可能性を示しています。また、視覚に基づくタスクでの事前に訓練されたテキストのみのLLMの能力も強調しています。より多くの研究開発を促進するために、彼らのコードと事前訓練モデルは近々一般に公開される予定です。 このアプローチを使用することで、言語モデルは視覚領域に基づいて固定され、任意の画像テキスト入力を処理し、一貫した画像テキスト出力を生成することができます。緑の吹き出しはモデルによって作成され、グレーの吹き出しは入力プロンプトを表します。

Google AIは、MediaPipe Diffusionプラグインを導入しましたこれにより、デバイス上で制御可能なテキストから画像生成が可能になります
最近、拡散モデルはテキストから画像を生成する際に非常に成功を収め、画像の品質、推論のパフォーマンス、および創造的な可能性の範囲の大幅な向上をもたらしています。しかし、効果的な生成管理は、特に言葉で定義しにくい条件下では依然として課題となっています。 Googleの研究者によって開発されたMediaPipe拡散プラグインにより、ユーザーの制御下でデバイス内でのテキストから画像の生成が可能になります。本研究では、デバイスそのもの上で大規模な生成モデルのGPU推論に関する以前の研究を拡張し、既存の拡散モデルおよびそのLow-Rank Adaptation(LoRA)のバリエーションに統合できるプログラマブルなテキストから画像の生成の低コストなソリューションを提供します。 拡散モデルでは、イテレーションごとに画像の生成が行われます。拡散モデルの各イテレーションは、ノイズが混入した画像から目標の画像までを生成することで始まります。テキストのプロンプトを通じた言語理解は、画像生成プロセスを大幅に向上させています。テキストの埋め込みは、テキストから画像の生成のためのモデルにリンクされ、クロスアテンション層を介して結びつけられます。ただし、物体の位置や姿勢などの詳細は、テキストのプロンプトを使用して伝えるのがより困難な例です。研究者は、条件画像からの制御情報を拡散に追加することで、拡散を利用して制御を導入します。 Plug-and-Play、ControlNet、およびT2Iアダプターの方法は、制御されたテキストから画像を生成するためによく使用されます。Plug-and-Playは、入力画像から状態をエンコードするために、拡散モデル(Stable Diffusion 1.5用の860Mパラメータ)のコピーと、広く使用されているノイズ除去拡散暗黙モデル(DDIM)逆推定手法を使用します。これにより、入力画像から初期ノイズ入力を導出します。コピーされた拡散からは、自己注意の空間特徴が抽出され、Plug-and-Playを使用してテキストから画像への拡散に注入されます。ControlNetは、拡散モデルのエンコーダーの訓練可能な複製を構築し、ゼロで初期化されたパラメータを持つ畳み込み層を介して接続し、条件情報をエンコードし、それをデコーダーレイヤーに渡します。残念ながら、これによりサイズが大幅に増加し、Stable Diffusion 1.5では約450Mパラメータとなり、拡散モデル自体の半分となります。T2I Adapterは、より小さなネットワーク(77Mパラメータ)であるにもかかわらず、制御された生成で同等の結果を提供します。条件画像のみがT2I Adapterに入力され、その結果がすべての後続の拡散サイクルで使用されます。ただし、このスタイルのアダプターはモバイルデバイス向けではありません。 MediaPipe拡散プラグインは、効果的かつ柔軟性があり、拡張性のある条件付き生成を実現するために開発されたスタンドアロンネットワークです。 訓練済みのベースラインモデルに簡単に接続できる、プラグインのようなものです。 オリジナルモデルからの重みを使用しないゼロベースのトレーニングです。 モバイルデバイス上でほとんど追加費用なしにベースモデルとは独立して実行可能なため、ポータブルです。 プラグインはそのネットワーク自体であり、その結果はテキストから画像への変換モデルに統合されます。拡散モデル(青)に対応するダウンサンプリング層は、プラグインから取得した特徴を受け取ります。 テキストから画像の生成のためのモバイルデバイス上でのポータブルなオンデバイスパラダイムであるMediaPipe拡散プラグインは、無料でダウンロードできます。条件付きの画像を取り込み、多スケールの特徴抽出を使用して、拡散モデルのエンコーダーに適切なスケールで特徴を追加します。テキストから画像への拡散モデルと組み合わせると、プラグインモデルは画像生成に条件信号を追加します。プラグインネットワークは、相対的にシンプルなモデルであるため、パラメータはわずか6Mとなっています。モバイルデバイスでの高速推論を実現するために、MobileNetv2は深度方向の畳み込みと逆ボトルネックを使用しています。 基本的な特徴 自己サービス機械学習のための理解しやすい抽象化。低コードAPIまたはノーコードスタジオを使用してアプリケーションを修正、テスト、プロトタイプ化、リリースするために使用します。 Googleの機械学習(ML)ノウハウを使用して開発された、一般的な問題に対する革新的なMLアプローチ。 ハードウェアアクセラレーションを含む完全な最適化でありながら、バッテリー駆動のスマートフォン上でスムーズに実行するために十分に小さく効率的です。

Pythonを使用したウェブサイトモニタリングによるリアルタイムインサイトの強化
イントロダクション このプロジェクトの目的は、複数のウェブサイトの変更をモニタリングし、追跡するプロセスを自動化するPythonプログラムを開発することです。Pythonを活用して、ウェブベースのコンテンツの変更を検出し、文書化する繊細な作業を効率化することを目指しています。リアルタイムのニュース追跡、即時の製品更新、競合分析を行うために、この能力は非常に貴重です。デジタルの世界が急速に変化する中で、ウェブサイトの変更を特定することは、持続的な認識と理解を保つために不可欠です。 学習目標 このプロジェクトの学習目標は、以下のコンポーネントをカバーすることです: BeautifulSoupやScrapyなどのPythonライブラリを使用したウェブスクレイピングの方法に関する知識を向上させる。効率的にウェブサイトから価値のあるデータを抽出し、HTMLの構造をナビゲートし、特定の要素を特定し、さまざまなコンテンツタイプを処理することを目指します。 ウェブサイトのコンテンツの微妙な変化を特定するスキルを向上させる。新しくスクレイピングされたデータを既存の参照と比較して、挿入、削除、または変更を検出するための技術を学ぶことを目指します。また、これらの比較中に遭遇するさまざまなデータ形式と構造を処理することも目指します。 ウェブサイトの更新を追跡するためにPythonの自動化機能を活用する。cronジョブやPythonのスケジューリングライブラリなどのスケジューリングメカニズムを使用して、データ収集を強化し、繰り返しのタスクを排除する予定です。 HTMLのアーキテクチャについて包括的な理解を開発する。HTMLドキュメントを効率的にナビゲートし、データ抽出中に重要な要素を特定し、ウェブサイトのレイアウトと構造の変更を効果的に管理することを目指します。 データ操作技術を探索することにより、テキスト処理のスキルを向上させる。抽出したデータをクリーンアップし、洗練させ、データエンコーディングの複雑さに対処し、洞察に基づいた分析と多目的なレポートのためにデータを操作する方法を学びます。 この記事は、データサイエンスのブログマラソンの一環として公開されました。 プロジェクトの説明 このプロジェクトでは、特定のウェブサイトの変更を監視し、カタログ化するためのPythonアプリケーションを作成することを目指しています。このアプリケーションには、以下の機能が組み込まれます: ウェブサイトのチェック:特定のコンテンツやセクションの更新を検出するために、割り当てられたウェブサイトを一貫して評価します。 データの取得:ウェブスクレイピングの方法を使用して、テキスト、グラフィック、または関連データなど、必要な詳細をウェブサイトから抽出します。 変更の特定:新しくスクレイピングされたデータを以前に保存されたデータと比較し、違いや変更箇所を特定します。 通知メカニズム:変更が検出された場合にユーザーをリアルタイムに通知するアラートメカニズムを実装します。 ログ記録:変更の詳細な記録を時間スタンプや変更の情報とともに保持します。このアプリケーションは、ユーザーの設定に基づいて、任意のウェブサイトと特定のコンテンツを監視するようにカスタマイズできます。期待される結果には、ウェブサイトの変更に関する直ちにアラートが含まれ、変更の性質とタイミングを理解するための包括的な変更記録が含まれます。 問題の定義 このプロジェクトの主な目的は、特定のウェブサイトの監視プロセスを効率化することです。Pythonアプリケーションを作成することで、興味のあるウェブサイトの変更を追跡し、カタログ化します。このツールは、ニュース記事、製品リスト、その他のウェブベースのコンテンツの最新の変更について、タイムリーな更新情報を提供します。この追跡プロセスを自動化することで、時間の節約とウェブサイトへの変更や追加に対する即時の認識が確保されます。 アプローチ このプロジェクトを成功裏に実装するために、以下の手順に従う高レベルのアプローチを取ります: プロジェクトでは、BeautifulSoupやScrapyなどの強力なPythonライブラリを使用します。これらのライブラリを使用すると、ウェブサイトから情報を収集し、HTMLコンテンツを取捨選択することが容易になります。 始めに、ウェブサイトから情報を取得してベースラインを作成します。このベンチマークデータは、後で変更を特定するのに役立ちます。 入力データを設定されたベンチマークと照合して、新しい追加や変更を追跡することができます。テキストの比較やHTML構造の違いの分析など、さまざまな技術を使用する場合があります。…

2023年の最高のAIテキスト生成ツール
ChatGPTのリリース以来、AIテキスト生成器は頻繁にニュースになっています。適切に訓練されたツールをプロンプトすると、AIテキスト生成器は作業をより良く、より速く支援することができます。現在、ChatGPTは最も有名なAIシステムかもしれませんが、その基盤となるGPT技術は注目を浴びています。最新のGPT-3とGPT-4は非常に強力であり、APIとしても利用できるため、他のプログラマーが自分のプログラムにAIテキスト生成を組み込むことができます。そのため、類似のAIテキスト生成器が数多く存在しています。 以下は現在チェックするべきいくつかのAIテキスト生成器です: Jasper AIを使用したテキスト生成に関して、Jasperは有名です。ブランドのトーンに合わせてカスタマイズ可能な長さの高品質なコンテンツを簡単に作成することができます。Jasperはこのリストで最も高価なプログラムの一つなので、コミットする前にデモを活用しましょう。ZapierはJasperとの統合をサポートしているため、AIのテキスト生成を他のすべてのワークアプリケーションにリンクして自動化することができます。 Copy.ai Copy.aiは、ビジネス向けに説得力のあるコンテンツを作成するのを支援するAI駆動のコピーライティングツールです。参加には会員費や最低購入額は必要ありません。このツールでは、よりパーソナライズされた体験と広告を提供するためにCookieが使用されます。Cookieは、このサイトでのGDPRの遵守およびボットの識別に使用されます。アプリは、ユーザーのサイト上のクリックやタップを記録し、統計情報やヒートマップを作成するために使用します。Cookieはまた、ユーザーの好みの言語とサーバークラスターを記憶します。これにより、ユーザーの体験と表示される広告にメリットがあります。 Anyword Anywordは、マーケティングで使用するための人工知能(AI)ベースのテキスト生成器およびコピーライティングツールです。AnywordはAIシステムを使用して、ユーザーの入力を分析し、再現的なテーマを認識し、ユーザーのニーズに合わせたオリジナルでカスタマイズされたコンテンツを作成します。スペルチェック、文法修正、最適な文構造などの追加機能もあります。 Sudowrite Sudowriteは、小説や映画の執筆に向けた高度なAIライティングツールで、作家やジャーナリストなどの著名人から称賛を受けており、The New Yorker、The New York Times、The Vergeなどの一流のジャーナルにも掲載されています。Sudowriteの多くの機能のうち、「Show, Not Tell」ボタンと「Brainstorming Buddy」は、ユーザーが執筆スキルを磨くのをサポートするために設計されています。人工知能ツールに関する事前の知識や経験は必要ありません。Human++株式会社がソフトウェアをサポートし、定期的なサブスクリプション料金を請求する前に無料トライアル期間を提供しています。 Rytr Rytrは、高品質なコンテンツを迅速かつ手頃な価格で作成するのを支援するAIライティングアシスタントです。このツールは、最新の言語AIを使用して、40以上のユースケースと30以上の言語で100%ユニークなコンテンツを生成することができます。Rytrの充実した機能には、リッチテキストエディタ、言い換えや短縮ツール、盗作チェック、フォーマットオプションなどがあります。さらに、Rytrにはブラウザ拡張機能もあり、メール、ドキュメント、ソーシャルメディア、請求書、プロジェクトと統合することができます。 Notion AI パワフルなAI駆動のアプリケーションNotion…
科学ソフトウェアの開発
この記事では、このシリーズの最初の記事で示されたように、科学ソフトウェアの開発においてTDDの原則に従って、Sobelフィルタとして知られるエッジ検出フィルタを開発します

製造品の品質におけるコンピュータビジョンの欠陥検出を、Amazon SageMaker Canvasを使用したノーコード機械学習で民主化する
品質の低下によるコストは、製造業者にとっての最重要課題です品質の欠陥は、廃棄物や再作業のコストを増加させ、スループットを減少させ、顧客と企業の評判に影響を与える可能性があります生産ラインでの品質検査は、品質基準を維持するために重要です多くの場合、品質と欠陥の検出のために人間の視覚検査が使用されますが、これは...
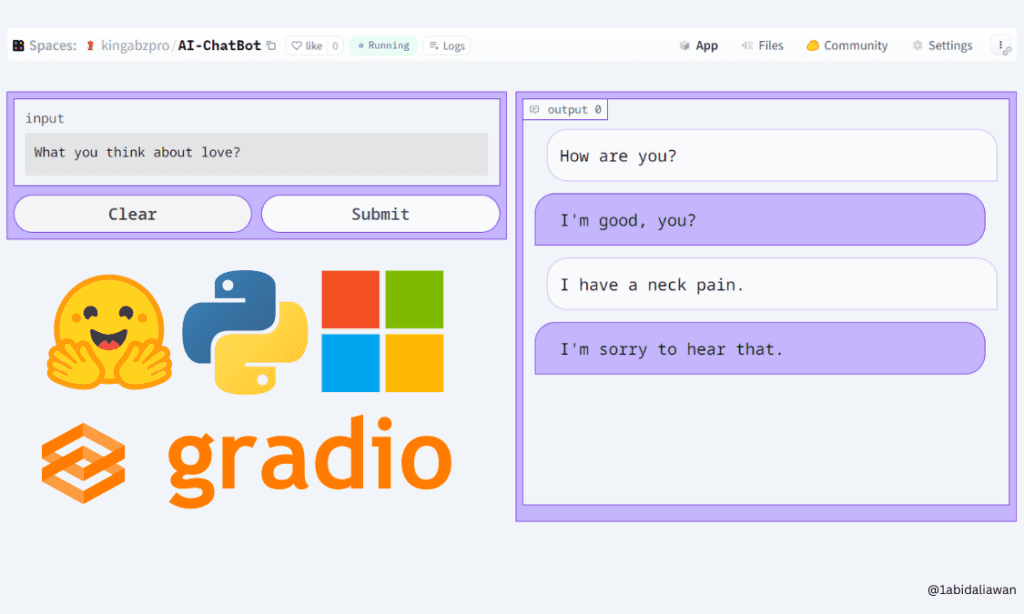
Hugging FaceとGradioを使用して、5分でAIチャットボットを構築する
この簡単なチュートリアルを使って、ブラウザ上で低コード技術を使ってGradioチャットボットを作成する方法を学びましょう
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.