Learn more about Search Results A - Page 714

- You may be interested
- お客様との関係を革新する:チャットとRea...
- GPT-4 新しいOpenAIモデル
- 「業界アプリケーションにおける大規模言...
- 「パンドラの箱をのぞいてみよう:『ホワ...
- Scikit-Learnのパイプラインを使用して、...
- 好奇心だけで十分なのか? 好奇心による探...
- AWSにおけるマルチモデルエンドポイントの...
- 分子の言語を学び、その特性を予測する
- 特定のタスクを効率的に解決するための4つ...
- 「AIを活用して国連の持続可能な開発目標...
- Amazon SageMaker Data WranglerのSnowfla...
- 「AWSとAccelが「ML Elevate 2023」を立ち...
- 「PEARLと出会ってください – 顧客...
- 「機械学習リスク管理のための文化的な能力」
- 「ODSC Europe 2023 キーノート:マイクロ...
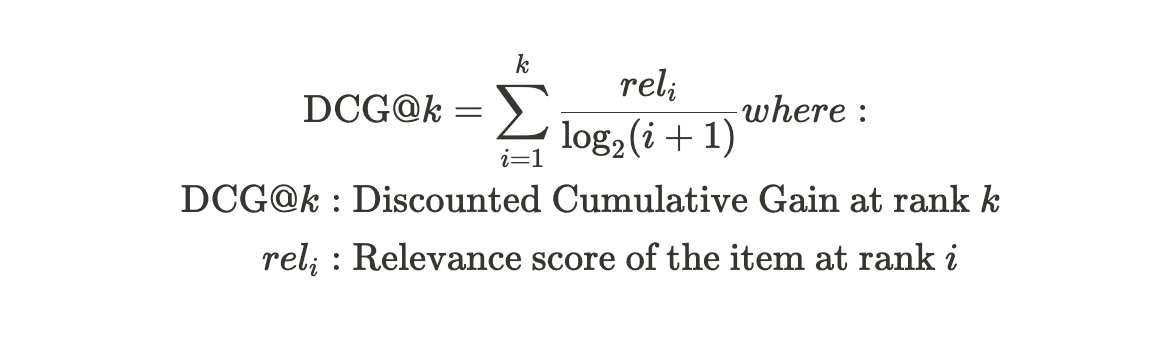
レコメンドシステムの評価指標 — 概要
最近、レコメンデーションシステムのプロジェクトを実験している最中、様々な評価指標を使用することがありましたそのため、役立つと感じた評価指標のリストと他のいくつかの事柄をまとめました

「ビジョン・ランゲージの交差点でのブレイクスルー:オールシーイングプロジェクトの発表」
AIチャットボットの急速な台頭を支えるLLMは、話題の的です。ユーザーに合わせた自然言語処理機能において驚異的な能力を示していますが、視覚世界を理解する能力には欠けているようです。視覚と言語の世界のギャップを埋めるために、研究者たちはオールシーイング(AS)プロジェクトを提案しています。 ASプロジェクトは、オープンワールドのパノプティックな視覚認識と理解を目指し、人間の認知を模倣するビジョンシステムの構築を目指しています。”パノプティック”という用語は、一つの視点で見えるすべてを含むことを指します。 ASプロジェクトは以下の要素から構成されています: オールシーイング1B(AS-1B)データセットは、現実世界の広範で珍しい3.5百万の概念をカバーしており、これらの概念とその属性を説明する1322億のトークンを持っています。 オールシーイングモデル(ASM)は、統一された位置情報を考慮した画像テキストの基礎モデルです。このモデルは、位置情報を考慮した画像トークナイザとLLMベースのデコーダの2つの主要なコンポーネントで構成されています。 このデータセットには、意味的なタグ、位置、質問応答のペア、キャプションなど、さまざまな形式で1億以上の領域の注釈が含まれています。ImageNetやCOCOなどの従来の視覚認識データセット、Visual GenomeやLaion-5Bなどの視覚理解データセットと比較して、AS-1Bデータセットは、豊富で多様なインスタンスレベルの位置注釈と対応する詳細なオブジェクトの概念と説明があるため、際立っています。 ASモデルのアーキテクチャは、さまざまなレベルの統一されたフレームワークで構成されています。このモデルは、画像レベルと領域レベルの対比的なおよび生成的な画像テキストのタスクをサポートしています。事前学習されたLLMと強力なビジョン基盤モデル(VFM)を活用することで、このモデルは、画像テキストの検索やゼロ分類などの識別的なタスク、およびビジュアルクエスチョンアンサリング(VQA)、ビジュアルリーズニング、画像キャプショニング、領域キャプショニング/VQAなどの生成的なタスクにおいて、有望なパフォーマンスを示しています。さらに、研究者たちは、クラスに依存しない検出器の支援を受けてフレーズのグラウンディングや参照表現の理解などのタスクに潜在的な可能性を見出しています。 オールシーイングモデル(ASM)は、次の3つの主要な設計要素で構成されています: 位置情報を考慮した画像トークナイザは、画像とバウンディングボックスに基づいて画像レベルと領域レベルの特徴を抽出します。 訓練可能なタスクプロンプトは、ビジョンとテキストのトークンの先頭に組み込まれ、識別的なタスクと生成的なタスクを区別するためにモデルをガイドします。 LLMベースのデコーダは、識別的なタスクのためのビジョンとテキストの特徴を抽出し、生成的なタスクでは応答トークンを自己回帰的に生成するために使用されます。 ASMとCLIPベースのベースラインモデル(GPT-2および3のゼロショット機能を表示)および主要なマルチモダリティ大規模言語モデル(VLLM)を代表するビジョンタスク(ゼロショット領域認識、画像レベルキャプション、領域レベルキャプションなど)で分析および比較することにより、ASMの品質、スケーリング、多様性、および実験に関する包括的なデータ分析が行われました。その結果、当社のASMによる強力な領域レベルのテキスト生成能力が示され、また、全体の画像を理解する能力も示されました。人間の評価結果は、当社のASMによって生成されたキャプションがMiniGPT4やLLaVAよりも好まれることを示しています。 このモデルは、オープンエンドの言語プロンプトと位置情報でトレーニングされており、領域テキストの検索、領域認識、キャプション付け、質問応答など、ゼロショットのパフォーマンスを持つさまざまなビジョンと言語のタスクに汎化することができます。これにより、LLMに「全見の目」が与えられ、ビジョンと言語の交差点が革新されたと研究者は述べています。

「2023年に必要な機械学習エンジニアの10の必須スキル」
イントロダクション 現在の進化する環境では、組織はAI、ディープラーニング、および機械学習の潜在能力を引き出すために、チームを急速に拡大しています。控えめなコンセプトであった機械学習は、今や産業全体で不可欠な存在となり、ビジネスが前例のない機会にアクセスできるようにしています。この変革の背後にある重要な要素は、機械学習エンジニアのスキルセットです。これらの専門家は、高度なアルゴリズムとシステムを構築し、自律的に知識と洞察を獲得する能力を持っています。機械学習が世界を変え続ける中で、これらのエンジニアの腕前はイノベーションを推進し、新たな可能性の領域を開拓する上で重要な役割を果たしています。2023年に持つべきトップな機械学習エンジニアのスキルを探ってみましょう! 機械学習エンジニアとは? 機械学習エンジニアは、複雑な問題を解決するために機械学習アルゴリズムとモデルを設計、構築、実装することに特化しています。彼らはデータサイエンスとソフトウェアエンジニアリングのギャップを埋め、予測モデル、推薦システム、その他のAI駆動アプリケーションの開発に専門知識を活用しています。機械学習エンジニアは、大規模なデータセットと作業し、データの前処理とクリーニング、適切なアルゴリズムの選択、モデルの最適なパフォーマンスを実現するための微調整を行います。 彼らの責任には、機械学習モデルのコーディング、トレーニング、展開、データサイエンティストやドメインの専門家との協力によるビジネス要件の理解が含まれます。機械学習エンジニアは、製品環境でのスケーラビリティ、信頼性、効率性を最適化することにも重点を置いています。彼らはしばしばTensorFlow、PyTorch、scikit-learnなどのフレームワークと共に作業し、強力なプログラミング、数学、およびデータ操作の基礎を持っています。全体として、機械学習エンジニアは、さまざまな産業で機械学習ソリューションの開発と展開に重要な役割を果たしています。 他にも読むべき記事:インドおよび海外での機械学習エンジニアの給与 トップ10の機械学習エンジニアのスキル 以下は、機械学習エンジニアがイノベーションを生み出し、複雑なAIおよびデータサイエンスの課題に取り組むためのトップなMLスキルです: プログラミング言語 数学と統計学 機械学習アルゴリズム データの前処理 データの可視化 モデルの評価と検証 機械学習ライブラリとフレームワーク ビッグデータツール バージョン管理 問題解決と批判的思考 プログラミング言語 基本的なプログラムの書き方やウェブページのスクリプトの作成など、最小限の種類のタスクを扱うことは、機械原理との関わりとはかなり異なります。それには重要なプログラミングスキルと専門知識が必要です。機械学習のキャリアにとって基本であり、最も重要なスキルはPythonなどのプログラミング言語の深い知識です。学習が容易であり、他の多くの言語よりも多くの用途を提供するため、Pythonは機械学習の基礎です。プログラムのスピードを改善するためにC++の理解が役立ちますが、機械学習エンジニアにはHadoopやHiveなどの技術を扱うためにJavaが必要です。 参考資料 Python入門 PythonとR以外の役立つプログラミング言語6選 Java…

「インデックスを使用してSQLクエリの処理速度を向上させる方法[Python版]」
Pythonの組み込みsqlite3モジュールを使用してSQLiteデータベースを操作する方法を学びますまた、クエリの高速化のためにインデックスを作成する方法も学びます

ベストプロキシサーバー2023
プロキシサーバーは、コンピュータが自分の代わりにリクエストを行うためのネットワーク上で動作するアプリケーションまたはウェブサービスです。それは、あなた(顧客)とサービス(コンピュータ上で表示したいウェブサイト)の間に立ち、中継役を果たします。 プロキシサーバーは、ユーザーがウェブサイトを閲覧する際に自分の実際のIPアドレスを隠すためによく使用されます。 ブロックされたウェブサイトへのアクセスを許可するだけでなく、プロキシサーバーはユーザーの制限や監視(未成年者や労働者など)を行う場合もあります。特定のウェブサイトへのアクセスを制限するために設定されることもあります。それを使用してデータを盗み見から守り、オンラインで匿名性を保ち、コンテンツフィルタの効果を評価することができます。さらに、ネットワーク速度の向上を楽しみながらこれを行うことができます。 以下にトップのプロキシサーバーをリストアップしています。 Bright Data Bright Dataは、ウェブデータのグローバルプラットフォームとしての地位を築いています。大企業から学術機関、中小企業まで、幅広い組織がBright Dataが提供する効率的で信頼性の高い柔軟なソリューションを活用して重要なパブリックウェブデータを収集しています。このデータは、研究、監視、データ分析、意思決定プロセスの向上に活用されます。Bright Dataは、195の国に広がる膨大な数のプロキシを誇り、99.99%の高い成功率、7200万以上の実在する住宅用IPアドレスの蓄積を誇ります。 Ake Akeは、最も信頼性と安定性に優れた住宅用プロキシネットワークとして特筆されています。信頼できるソースと大規模な住宅用IPアドレスのプールを通じて、顧客は信頼性の高いソースと広範なジオロケーションのコンテンツに接続することができます。150以上の異なる国に位置するプロキシサーバーから選択して接続することができます。アメリカ、フランス、ドイツ、イギリス、オランダでは、多くのプロキシサーバーが提供されています。アプリケーションテストのためのグローバルプロキシサーバーは、650の場所と150の国で利用できます。 Live Proxies Live Proxiesは、プライベートな住宅用およびモバイルプロキシソリューションの業界基準を設定しています。透明性と信頼性を最適化する保証付きの高品質で安定したプロキシを提供しています。回転および静的な住宅用IPアドレス、および回転するモバイルIPアドレスの幅広いアサインメントにより、eコマース、市場調査、ブランド保護、SEO/SERP、AdTechなど、さまざまなニーズに対応しています。プロキシは独占的に割り当てられており、すべてのウェブサイトでのブロック解除が保証されています。また、強力なカスタマーサポートとカスタムソリューションも同社の素晴らしい評判に貢献しています。さらに、ユーザーフレンドリーな管理ダッシュボードを使用して簡単にプロキシの分析を表示することができます。競争力のある価格から始まる柔軟なプランの範囲から選択することができ、Live Proxiesは今日のデジタル主導の世界で貴重な資産となっています。 NodeMaven 他のプロバイダーとは異なり、NodeMavenはプロキシIPを割り当てる前にリアルタイムで高度なフィルタリングアルゴリズムを使用してIPをスクリーニングします。NodeMavenが提供するプロキシに接続すると、IPが割り当てられる前に高度な品質保証アルゴリズムを通過するため、95%のIPがクリーンな状態であることが保証されます。 さらに、NodeMavenはハイブリッドプロキシ技術を使用しており、産業平均よりも長い最大24時間のIPセッションを保持することができます。これにより、Facebook、Google、eBay、Amazon、LinkedInなどのプラットフォーム上のアカウントを管理するのに最適です。1400以上の都市と150以上の国から、500万以上の住宅用IPを提供しています。また、期限切れにならない使い切り帯域幅を備えた競争力のある価格設定も行っています。 IPRoyal IPRoyalは、195以上の国で数千のIPアドレスを持つ、倫理的に調達された住宅用プロキシのネットワークを提供しています。合計8,056,839の住宅用IPアドレスがプロキシプールを作成するために使用されました。IPRoyalを使用することで、世界中のどの国でも、実際の家庭のユーザー、実際のインターネットサービスプロバイダ(ISP)の接続を持つ実際のIPアドレスを取得することができます。信頼性が重要な場面(プロフェッショナルまたは個人)に最適です。 Nimble Nimbleを使用すると、単一のインターフェースから家庭、データセンター、インターネットサービスプロバイダなど、世界中のIPアドレスを使用することができます。このシステムは、データのアクセシビリティを向上させ、費用を削減し、困難な目標の達成を容易にします。Nimbleの使いやすいコントロールパネルは、他のプロキシサービスプロバイダとは異なります。ダッシュボードは、支出状況の把握、消費の追跡などに便利です。コントロールパネルは、パイプラインの設定、変更、削除も行うことができます。…

「LLMアプリケーションを構築する際に知っておくべき5つのこと」
LLMベースのアプリケーションを構築する際には、5つの問題が生じます

ボストン大学の研究者たちは、プラチプスファミリーと称されるファインチューニングされたLLMsを公開しました:ベースLLMsの安価で高速かつパワフルな改良を実現するために
大規模言語モデル(LLM)は世界中で大きな注目を浴びています。これらの非常に効果的で効率的なモデルは、人工知能の最新の驚異として立ち現れています。文脈を理解し、テキストを生成し、論理的に対話する能力を持つことで、彼らは人間と機械の間のコミュニケーションを再定義する能力を備えています。研究者たちは、パラメータ効率のチューニング(PEFT)と呼ばれる手順によって、ベースの大規模言語モデルのパフォーマンスを向上させることに焦点を当てており、これは小規模で強力なOpen-Platypusデータセット上でLLMを最適化することを意味しています。 最近、ボストン大学の研究者チームが、Platypusという独自の改良と結合された大規模言語モデルの一群を紹介しました。これらのモデルは、比類のないパフォーマンスを達成し、現在HuggingFaceのOpen LLM Leaderboardでトップの位置を維持しています。Open-Platypusとして知られる厳選されたデータセットは、他の無料データセットから慎重に選ばれたもので、一般の人々にもアクセス可能になっています。これは、LLMのパフォーマンス向上に重要な要素に焦点を当てた大規模なデータセットの一部であり、注意深くカリキュレーションされています。 チームの目標は、ドメイン固有の情報を活用しながら、事前学習されたLLMの強力な事前知識を維持し、LoRAモジュールを微調整およびマージすることです。より包括的な知識を初期トレーニング中に蓄積するため、モデルは特定のタスクに合わせて調整することができます。LoRAモジュールが組み合わさることで、より強力なLLMが生み出されます。シナジーのおかげで、モデルの潜在能力と専門的なドメイン知識が明らかになります。 この研究の重要な側面の一つは、テストデータの正確性を検証し、トレーニングデータ内の潜在的な汚染を特定するために行われた徹底した取り組みです。Platypusシリーズのモデルの信頼性と正確性をサポートする包括的なチェックがいくつかあり、この検証手順の方法を公開することは、さらなる現地調査の手引きとなる可能性があります。 モデルのサイズが異なるPlatypusファミリーは、量的なLLMメトリックで優れたパフォーマンスを発揮しています。これは、戦略の効果を証明するOpen LLM Leaderboardのトップに位置しています。チームは、彼らのモデルが他の最先端の微調整されたLLMと同等のパフォーマンスを発揮する一方で、微調整データと計算リソースの一部しか使用していないことを共有しています。例えば、13BのPlatypusモデルは、たったの5時間で単一のA100 GPUとわずか25,000の質問を使用して成功裏にトレーニングすることができます。この驚異的な効率性は、Open-Platypusデータセットの優れた品質を強調し、この分野でのさらなる進展の道を切り開いています。 貢献は以下のようにまとめることができます: STEMおよび論理的な知識を強化するために導入された11の公開テキストデータセットからなるコンパクトなデータセットであるOpen-Platypus。 このデータセットは、主に人間が設計した質問から構成されており、微調整時間とコストを最小限に抑えて強力なパフォーマンスを提供します。 データセットのサイズと冗長性を減らすための類似データの除外プロセスの説明が共有されています。 LLMトレーニングセットにおけるデータ汚染の課題とデータフィルタリングプロセスについて探求されています。 専門的に微調整されたLoRAモジュールの選択とマージアプローチの説明が共有されており、LLMの全体的なパフォーマンス向上に貢献しています。

10倍の生産性を向上させるためのTop 10 VS Code拡張機能
Path Intellisense C#、VB.NET、またはF#を使用している場合、Visual Studioの拡張機能であるPath Intellisenseのおかげで、Path Intellisenseを利用することができます。これにより、必要なルートを簡単に特定し、タイプミスや間違った経路から保護することができます。プロジェクトファイルはPath Intellisenseによって解析され、プロジェクトで使用されるすべてのパスのデータベースが作成されます。Path Intellisenseは、コードエディタの一部の機能であり、入力すると可能なルートを提案してくれます。提案されたルートは、目的地に素早く到達するのに役立ちます。入力すると、Path Intellisenseは適切なパスの補完を提案します。存在しないまたはアクセスできないパスを入力しようとすると、Path IntelliSenseが警告を表示します。Path Intellisenseを使用すると、用語の定義を簡単に取得することができます。パスを扱う際に時間を節約し、間違いを防ぐために、Visual Studio用のPath Intellisense拡張機能は非常に価値があります。Visual Studio Marketplaceで、無料でダウンロードすることができます。 Live Server Visual Studio Code用のLive Server拡張機能を使用すると、ライブリロードを使用してローカルで静的および動的なウェブサイトを構築することができます。これにより、コードを編集して、ブラウザでその効果を即座に確認することができます。開発者は、各変更後にブラウザを手動でリロードする必要がなくなり、時間を節約することができます。Live Serverのインターフェースは直感的です。Visual Studio Codeでプロジェクトを開き、Marketplaceから拡張機能を追加します。Live…

「ConDistFLとの出会い:CTデータセットにおける臓器と疾患のセグメンテーションのための革新的なフェデレーテッドラーニング手法」
コンピュータ支援診断や治療計画などの臨床応用のために、コンピュータ断層撮影(CT)画像は腹部臓器と腫瘍を正確にセグメント化する必要があります。現実の医療状況では、多くの臓器と病気を同時に処理できる一般化モデルが好まれます。主要な研究は、悪性腫瘍のない個々の臓器や異なる臓器クラスのセグメンテーションに焦点を当ててきましたが、他の興味深い領域も存在します。一方、従来の教師付き学習技術は、トレーニングデータのボリュームと品質に依存しています。残念ながら、高品質の医療画像データの高額な費用からトレーニングデータの不足が生じています。正確な医療画像に対して正しい注釈を作成できるのは、資格を持つ専門家のみです。 さらに、専門家であっても、異なる解剖学の臓器や関連するがんを注釈付けするのは困難です。一部の専門家は、単一の活動に特化した専門知識しか持っていない場合もあります。異なる臓器と悪性腫瘍に対して適切な注釈情報が不足しているため、一般化されたセグメンテーションモデルの開発が大幅に妨げられています。この問題を解決するために、一部の対象臓器と悪性腫瘍のみが各画像にタグ付けされた部分的に注釈付きのデータセットを使用して、一般化されたセグメンテーションモデルを開発するための研究が行われています。しかし、機密性の高い医療統計情報を組織間で共有することは、プライバシーや法的な問題を引き起こす可能性があります。これらの問題に対処するために、連邦学習(FL)が提案されました。 FLは、データを一箇所に集約することなく、複数の機関間で共通(または「グローバル」)モデルの協調トレーニングを可能にします。医療画像セグメンテーションの効果を高めるための潜在的な方法として、FLがあります。FLでは、各クライアントは単にモデルの更新をサーバーに送信し、そのデータとリソースを使用してローカルモデルをトレーニングします。サーバーはこれらの変更をグローバルモデルに統合するために「FedAvg」を使用します。最近の研究では、図1に示すように、部分的に注釈付けされた腹部データセットを使用して、統一された多臓器セグメンテーションモデルをFLを使用して作成しています。しかし、これらの手法では病変領域を頻繁に無視しています。一部の研究では、異なる臓器とその腫瘍を同時にセグメント化するための努力が行われています。 図1 は、不完全なラベルから複数の臓器と腫瘍をセグメント化するためのConDistFLアーキテクチャを示しています。各クライアントのローカルデータベースには、対象の臓器と悪性腫瘍の一部のみがマークされています。 データの多様性によって引き起こされるデータの異質性への対処の難しさにより、FLのモデル集約は重要な課題に直面しています。異なるソースからのモデルを非IIDデータとともに使用すると、パフォーマンスが低下する可能性があります。クライアントがさまざまな目的のために注釈付けられたデータを使用すると、ラベル空間にドメインシフトがさらに導入され、問題が悪化します。さらに、データの少ないジョブの場合、クライアントの異なるデータセットのサイズによって、グローバルモデルのパフォーマンスに影響を与える可能性があります。この論文の研究者は、国立台湾大学、名古屋大学、NVIDIA Corporationの研究者が、部分的に注釈付きの腹部CT画像からマルチクラスの臓器と腫瘍のセグメンテーションにおけるFLにおけるデータの異質性に対処する戦略を提案しています。 この研究の主な貢献は次のとおりです: 1. 提案された条件付き蒸留連邦学習(ConDistFL)フレームワークにより、追加の完全に注釈付きのデータセットを必要とせずに、腹部臓器と悪性腫瘍の複合マルチタスクセグメンテーションが可能になります。 2. 提案されたフレームワークは、長いローカルトレーニングステップと少数の集約による安定性とパフォーマンスを実証し、データトラフィックとトレーニング時間を削減します。 3. 彼らは、AMOS22と呼ばれる未公開の完全に注釈付きのパブリックデータセットを使用して、自分たちのモデルをさらにテストしています。定性的および定量的な評価の結果は、彼らの戦略の堅牢性を示しています。

UCサンタクルーズの研究者たちは、概念や価値観間の暗黙的なステレオタイプと、画像内のそれらを定量化する画像対テキスト関連性テストツールを提案しています
UCサンタクルーズの研究チームが、Text to Image Association Testと呼ばれる画期的なツールを紹介しました。このツールは、Text-to-Image(T2I)生成AIシステムの偶発的なバイアスに対処します。これらのシステムは、テキストの説明から画像を生成する能力で知られていますが、その出力にはしばしば社会的なバイアスが再現されます。アシスタント教授をリーダーとしたチームは、これらの微妙なバイアスを測定するための定量的な手法を開発しました。 Text to Image Association Testは、性別、人種、キャリア、宗教などの複数の次元にわたるバイアスを評価するための構造化されたアプローチを提供します。この革新的なツールは、2023年のAssociation for Computational Linguistics(ACL)カンファレンスで発表されました。その主な目的は、Stable Diffusionなどの高度な生成モデル内のバイアスを定量化し、特定することです。これらのモデルは生成された画像で既存の偏見を拡大する傾向があります。 このプロセスでは、モデルに「科学を勉強する子供」という中立的なプロンプトを与えます。その後、性別に関連するプロンプト、「科学を勉強する女の子」と「科学を勉強する男の子」が使用されます。中立的なプロンプトと性別に関連するプロンプトから生成された画像の差異を分析することで、ツールはモデルの応答に含まれるバイアスを定量化します。 研究では、Stable Diffusionモデルが一般的なステレオタイプに合致したバイアスを示していることが明らかになりました。このツールは、科学と芸術のような概念や男性と女性のような属性との関連性を評価し、これらの関連性の強さを示すスコアを割り当てます。興味深いことに、モデルは一般的な仮定とは異なり、濃い肌を快適さと関連付け、薄い肌を不快さと関連付けました。 さらに、モデルは科学と男性、芸術と女性、キャリアと男性、家族と女性のような属性との関連性を示しました。研究者たちは、このツールが画像の色や暖かさなどの文脈要素も考慮していることにも言及し、これまでの評価方法との違いを強調しました。 社会心理学の暗黙的関連性テストに触発されたUCSCチームのツールは、T2Iモデルの開発段階でのバイアスの定量化における進歩を表しています。研究者たちは、このアプローチがソフトウェアエンジニアにより正確なバイアスの測定を提供し、AIによって生成されたコンテンツのバイアスを特定し修正するのに役立つと期待しています。定量的な指標により、このツールはバイアスを軽減するための継続的な努力と進捗状況のモニタリングを容易にします。 ACLカンファレンスでの仲間の学者からは、この研究の潜在的な影響力に対する熱意を表明する多くの好意的なフィードバックと関心が寄せられました。チームは、モデルのトレーニングと改良段階でのバイアス軽減策の提案を計画しています。このツールは、AIによって生成された画像に内在するバイアスを明らかにするだけでなく、これらのシステムの公平性を改善し修正する手段を提供します。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.