Learn more about Search Results A - Page 709

- You may be interested
- テクノロジーを通じたアクセシビリティと...
- 「ChatGPTを利用する5人のミリオネア」
- 「ODSC West 2023 予備スケジュールを発表...
- 「Quivrに会ってください:第2の脳のよう...
- 「Muybridge Derby AIによる動物の運動写...
- ヴェクタラは、AI言語モデルの「幻覚」を...
- 「Amazon Textractの新しいレイアウト機能...
- 「DiffPoseTalk(デフポーズトーク)をご...
- 「機械学習の解明:人気のあるMLライブラ...
- 「LangChainとOpenAI APIを使用した生成型...
- チャットボットの台頭
- インディアナ大学の研究者たちは、「Brain...
- 世界に向けて:非営利団体がGPUパワードの...
- 「新しいAmazon Kendra Alfrescoコネクタ...
- 「あなたに適した量子化メソッドはどれで...

「ユートピアの再創造:デジタル時代の自己創造コミュニティ」
ジョン・ヒリスは、デジタル技術を使用して、テキサス州オースティンの外にあるネイバーフッド・ゼロのような自己生成型の共同生活コミュニティのネットワークを作成し、政府の分散化を支援しています

なぜ特徴スケーリングは機械学習において重要なのか?6つの特徴スケーリング技術についての議論
さまざまなシナリオで選択できるさまざまな種類の特徴スケーリング方法がありますそれらは異なる(技術的な)名前を持っています用語の「特徴スケーリング」は、単にそれらの方法のいずれかを指します
効率的にオープンソースのLLMを提供する
この記事では、オープンソースのLLMsを提供するための6つの一般的な方法、AWS Sage Maker、Hugging Face、Together.AI、VLLM、およびPetals.mlを使用した個人的な経験について説明していますあなたは痛み、苦労、...を感じてきたでしょう
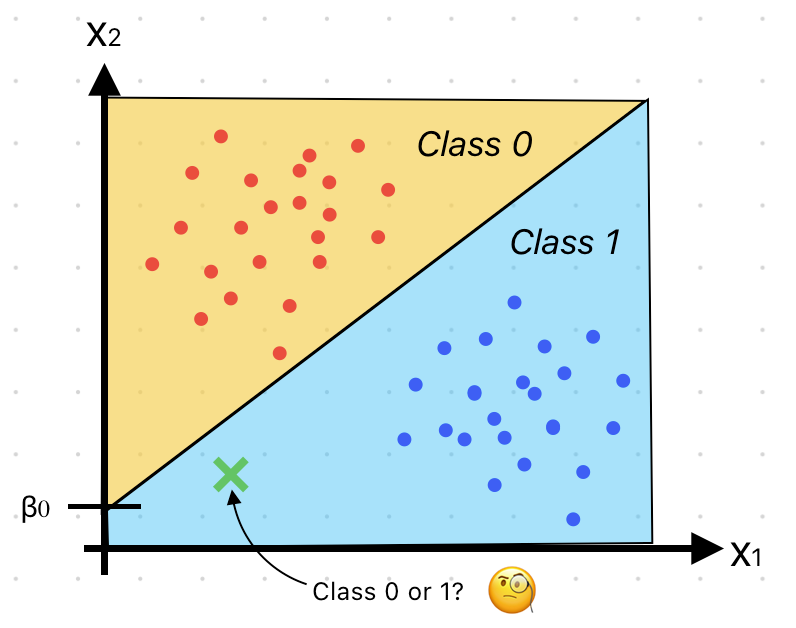
「ロジスティック回帰の謎解き:簡単なガイド」
データサイエンスと機械学習の世界において、ロジスティック回帰は強力で広く使われているアルゴリズムですその名前にもかかわらず、物流や商品の移動とは何の関係もありません...

「データ品質とは何ですか?」
データ品質は、データセットが信頼性があり、理解され、意図された目的に効果的に利用される方法を定義しますサプライチェーン管理では、データは問題を検出し、意思決定をする上で重要な役割を果たします
「なぜより多くがより良いのか(人工知能において)」
「ディープニューラルネットワーク(DNN)は、機械学習の風景を根本的に変え、しばしば人工知能や機械学習の広い範囲と同義になりましたしかし...」
ビジュアルトランスフォーマー(ViT)モデルのコードに深く潜る
ビジョン・トランスフォーマー(ViT)は、コンピュータビジョンの進化における重要な節目として位置づけられていますViTは、画像を最も適切に処理する手法として一般的に認識されていた畳み込み層を否定します...
「スロットを使用すべきですか?スロットがクラスに与える影響、それらを使用するタイミングと方法」
スロットは、クラス属性を宣言し、他の属性の作成を制限するメカニズムですクラスが持つ属性を確立し、開発者が新しい属性を追加することを防ぎます

「無料のeBookでデータサイエンスのためのデータクリーニングと前処理を学びましょう」
この無料の電子書籍では、読者はPythonエコシステムを使用してデータサイエンスのためのデータのクリーニングと前処理をどのように行うかを学びます

「分析ストリーム処理への控えめな紹介」
「基礎は揺るぎない、壊れることのない構造物の土台です成功したデータアーキテクチャを構築する際には、データがシステム全体の中心的な要素です...」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.