Learn more about Search Results A - Page 700

- You may be interested
- 動作の良さを把握する確率的AI
- ファッションを先導する生成AI
- 「GoとMetalシェーディング言語を通じてAp...
- オムニヴォアに会ってください:産業デザ...
- 欧州とイスラエルのAIファーストスタート...
- 「データサイエンスポートフォリオの再考」
- ウェブサイトビルディングにおけるAIの台...
- 会社の文書から洞察を抽出するために、ビ...
- LLMWareは、複雑なビジネスドキュメントを...
- ハイプに乗ろう! ベイエリアでのAIイベント
- 「ChatGPTの新たなライバル:Googleのジェ...
- ODSCのAI週間まとめ:12月8日の週
- 「データガバナンスチームを改善するため...
- 「人工知能がゼロトラストを強化する方法」
- 「NASAのドラゴンフライがタイタンの大気...

「複雑性理論の50年間の知識の限界への旅」
「問題が解決が困難であることを証明するのはどれほど難しいのか」、メタ複雑性理論家は何十年もこのような質問をしてきました最近の一連の結果が、その答えを提供し始めました

「人型ロボットは人間よりも飛行機を操縦できる」
エンジニアや研究者は、コックピットの改造を必要とせずに飛行機を操縦できるヒューマノイドロボットを開発しています
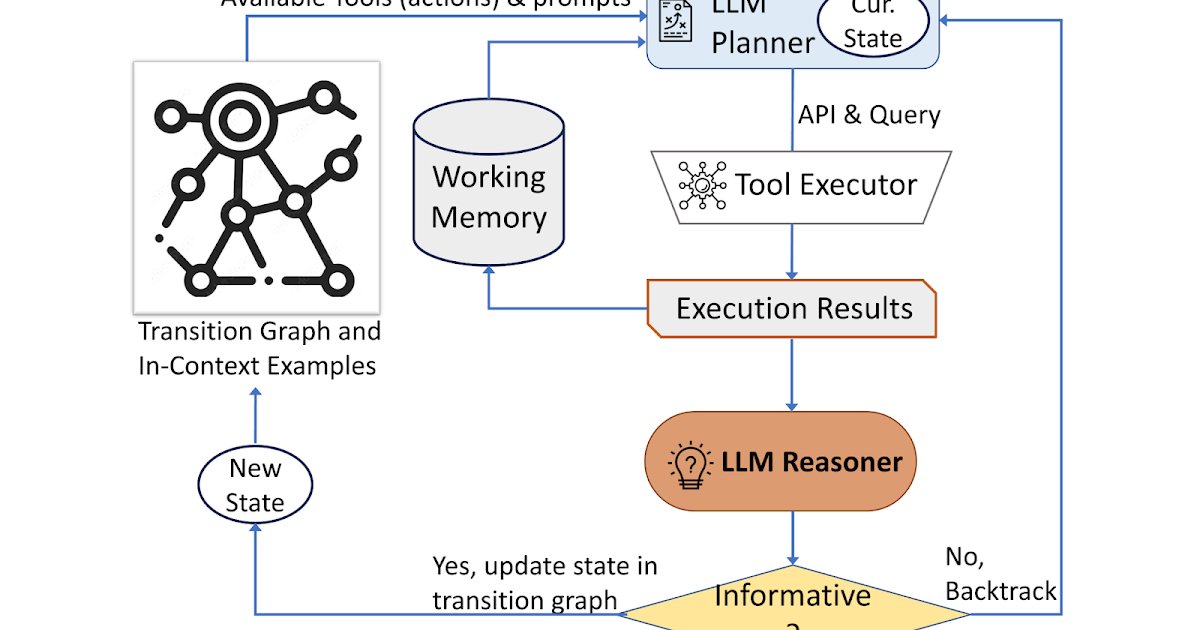
大規模な言語モデルを使用した自律型の視覚情報検索
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team 大規模言語モデル(LLM)を多様な入力に適応させるための進展があり、画像キャプショニング、ビジュアルな質問応答(VQA)、オープンボキャブラリ認識などのタスクにおいても進展が見られています。しかし、現在の最先端のビジュアル言語モデル(VLM)は、InfoseekやOK-VQAなどのビジュアル情報検索データセットにおいて、外部の知識が必要な質問に対して十分な性能を発揮できません。 外部の知識が必要なビジュアル情報検索のクエリの例。画像はOK-VQAデータセットから取得されています。 「AVIS:大規模言語モデルによる自律型ビジュアル情報検索」という論文では、ビジュアル情報検索タスクにおいて最先端の結果を達成する新しい手法を紹介しています。この手法は、LLMと3種類のツールを統合しています:(i)画像からビジュアル情報を抽出するためのコンピュータビジョンツール、(ii)オープンワールドの知識と事実を検索するためのWeb検索ツール、および(iii)視覚的に類似した画像に関連するメタデータから関連情報を得るための画像検索ツール。AVISは、LLMパワードのプランナーを使用して各ステップでツールとクエリを選択します。また、LLMパワードの推論エンジンを使用してツールの出力を分析し、重要な情報を抽出します。ワーキングメモリコンポーネントはプロセス全体で情報を保持します。 難しいビジュアル情報検索の質問に回答するためのAVISの生成されたワークフローの例。入力画像はInfoseekデータセットから取得されています。 以前の研究との比較 最近の研究(例:Chameleon、ViperGPT、MM-ReAct)では、LLMにツールを追加して多様な入力を扱うことを試みています。これらのシステムは2つのステージのプロセスに従います:プランニング(質問を構造化プログラムや命令に分解する)および実行(情報を収集するためにツールを使用する)。基本的なタスクでは成功していますが、このアプローチは複雑な実世界のシナリオではしばしば失敗します。 また、LLMを自律エージェントとして適用することに関心が高まっています(例:WebGPT、ReAct)。これらのエージェントは環境と対話し、リアルタイムのフィードバックに基づいて適応し、目標を達成します。ただし、これらの方法では各ステージで呼び出すことができるツールに制限がなく、膨大な検索空間が生じます。その結果、現在の最先端のLLMでも無限ループに陥ったり、エラーを伝播させることがあります。AVISは、ユーザースタディからの人間の意思決定に影響を受けたガイド付きLLMの使用によってこれを解決します。 ユーザースタディによるLLMの意思決定への情報提供 InfoseekやOK-VQAなどのデータセットに含まれる多くのビジュアルな質問は、人間にとっても難しい課題であり、さまざまなツールやAPIの支援が必要とされます。以下にOK-VQAデータセットの例の質問を示します。私たちは外部ツールの使用時の人間の意思決定を理解するためにユーザースタディを実施しました。…

Pythonによる地理空間データの分析
地理空間データサイエンスは私の興味の一つですデータを地図上で可視化し、そしてどれだけ多くの場合にデータポイント間の関係が素晴らしいものであるかについて、私は魅了されています…

「マイクロソフトの研究者がSpeechXを紹介:ゼロショットのTTSと様々な音声変換タスクに対応する多目的音声生成モデル」
テキスト、ビジョン、音声など、複数の機械学習アプリケーションは、生成モデルの技術において急速かつ重要な進展を遂げてきました。これらの進展により、産業や社会は大きな影響を受けています。特に、マルチモーダルな入力を持つ生成モデルは、真に革新的な発展を遂げています。ゼロショットテキストto音声(TTS)は、音声ドメインにおけるよく知られた音声生成の問題であり、音声テキスト入力を使用します。意図した話者の小さな音声クリップだけを使用して、ゼロショットTTSはその話者の声の特徴や話し方を持ったテキストソースを音声に変換することを含みます。初期のゼロショットTTSの研究では、固定次元の話者埋め込みが使用されました。この方法は話者クローニングの機能を効果的にサポートせず、TTSに限定した使用に制限がありました。 しかしながら、最近の戦略では、マスクされた音声の予測やニューラルコーデックの言語モデリングなど、より広範な概念が含まれています。これらの先端的な手法では、一次元の表現に圧縮せずにターゲットスピーカーのオーディオを使用します。その結果、これらのモデルは、優れたゼロショットTTSの性能に加えて、音声変換や音声編集などの新機能を表示しています。この増加した適応性は、音声生成モデルの可能性を大きく拡大することができます。ただし、これらの現在の生成モデルには、特に入力音声の変換を含むさまざまな音声テキストベースの音声生成タスクを処理する際に、いくつかの制限があります。 例えば、現在の音声編集アルゴリズムは、クリーンな信号のみを処理することができず、バックグラウンドノイズを維持しながら話された内容を変更することはできません。さらに、議論されたアプローチは、ノイズのある信号をクリーニングするためにクリーンな音声セグメントで囲まれる必要があるため、その実用的な適用性に重大な制限を課しています。ターゲットスピーカーの抽出は、汚れた音声を変更する文脈で特に役立つ仕事です。ターゲットスピーカーの抽出は、複数の話者を含む音声混合物から目標の話者の声を取り除くプロセスです。少しの話し声クリップを再生することで、希望の話者を指定することができます。前述のように、現在の生成音声モデルは、その潜在的な重要性にもかかわらず、この仕事を処理することができません。 回帰モデルは、過去の手法におけるノイズ除去やターゲットスピーカーの抽出などの信頼性のある信号回復に使用されてきました。しかし、これらの以前の手法では、発生しうるさまざまな音響的な混乱に対して異なる専門モデルが必要な場合があり、最適ではありません。特定の音声改善タスクに主に焦点を当てた小規模な研究以外にも、参照転写を使用して理解可能な音声を生成するための完全な音声テキストベースの音声改善モデルに関する研究はまだ行われていません。音声と変換能力を統合した音声テキストベースの生成音声モデルの開発は、上記の要素および他の学問分野での成功した前例に鑑みて、重要な研究の関心を持ちます。 図1: SpeechXの一般的なレイアウト。SpeechXは、テキストと音響トークンストリームでトレーニングされたニューラルコーデック言語モデルを使用して、ノイズ抑制、音声削除、ターゲットスピーカーの抽出、ゼロショットTTS、クリーン音声編集、ノイズ音声編集など、さまざまな音声テキストベースの音声生成タスクを実行します。一部のジョブでは、テキスト入力は必要ありません。 これらのモデルは、さまざまな音声生成ジョブを処理する幅広い能力を持っています。これらのモデルは、他の機械学習の領域で作成された統一または基礎となるモデルと同様に、オーディオとテキストの入力から音声を生成するさまざまなタスクを実行できる必要があります。ゼロショットTTSだけでなく、音声拡張や音声編集など、さまざまな種類の音声変更もこれらの活動に含まれるべきです。 統一モデルは音響的に困難な状況で使用される可能性があるため、さまざまな音響的な歪みに対して耐性を示さなければなりません。これらのモデルは、背景ノイズが一般的な実世界の状況で役立つことができます。 • 拡張性: 統一モデルでは、柔軟なアーキテクチャを使用して、スムーズなタスクサポートの拡張を可能にする必要があります。これを実現する方法の一つは、追加のモジュールや入力トークンなどの新しいコンポーネントのためのスペースを提供することです。この柔軟性により、モデルは新しい音声生成のタスクに効率的に適応することができます。Microsoft Corporationの研究者は、この論文でこの目標を達成するために、柔軟な音声生成モデルを紹介しています。このモデルは、ゼロショットTTS、オプションのトランスクリプト入力を使用したノイズ抑制、音声除去、オプションのトランスクリプト入力を使用したターゲットスピーカー抽出、および静かな環境と騒々しい環境の両方に対する音声編集など、複数のタスクを実行することができます(図1)。彼らはSpeechX1を推奨モデルとして指定しています。 VALL-Eと同様に、SpeechXは、テキストと音声の入力に基づいてニューラルコーデックモデルのコードまたは音響トークンを生成する言語モデリングアプローチを採用しています。さまざまなタスクの処理を可能にするために、彼らはマルチタスク学習の設定で追加のトークンを組み込んでおり、トークンは共同して実行されるタスクを指定します。トレーニングセットとしてLibriLightから60K時間の音声データを使用した実験結果は、SpeechXの効果を示しており、上記のすべてのタスクで専門モデルと比較して同等または優れた性能を発揮しています。特に、SpeechXは、音声編集中に背景音を保持する能力や、ノイズ抑制やターゲットスピーカー抽出のための参照トランスクリプトを活用するなど、新しいまたは拡張された機能を備えています。彼らが提案するSpeechXモデルの能力を示すオーディオサンプルは、https://aka.ms/speechx でご覧いただけます。
MEMSセンサーデータの探索的分析
MEMS(マイクロ電子機械システム)センサーは、ゲームコントローラーやスマートフォンから無人航空機まで、さまざまなアプリケーションで広く使用されています本記事では、どのように... を紹介します

「BERT vs GPT:NLPの巨人たちの比較」
「2018年、NLPの研究者たちは皆、BERTの論文[1]に驚かされましたその手法はシンプルでありながら、その結果は印象的でした11つのNLPタスクにおいて新たなベンチマークを確立しましたそして2022年、ChatGPT [3]は一気に…」

「スタンフォード大学の研究者が自然な視覚の解読を解明し、新しいモデルが目が視覚シーンを解読する方法を明らかにする」
感覚神経科学の分野における基本的な目標は、自然な視覚シーンを処理するのに責任のある神経コードの複雑なメカニズムを理解することです。神経科学において、未解決の基本的な問いの一つは、複数の細胞タイプの相互作用によって自然な環境で神経回路がどのように発達するのかということです。目は、様々な内在ニューロンを使って自然な視覚シーンに関する情報を伝えるために進化しており、これは視覚情報を脳に伝達するために重要です。 網膜の機能は、点滅する光やノイズなどの人工的な刺激に対してどのように反応するかという研究に基づいています。これらは実際の視覚データを網膜がどのように解釈するかを正確に表しているわけではありません。これら50種類以上の異なるタイプの内在ニューロンが網膜の処理にどのように寄与しているかの複雑さは、こうした方法を使用しても完全に理解されていません。最近の研究論文では、研究者のグループが3層のネットワークモデルが自然な風景への網膜の応答を驚異的な精度で予測する能力を持っていることを示すことで、重要な進展を遂げました。研究者たちは脳が自然な視覚シーンをどのように処理するのかを理解したかったため、脳への信号を送る目の一部である網膜に焦点を当てました。 このモデルの解釈可能性、つまり内部の組織を理解し、調査する能力は、その特徴の一つです。モデルに直接含まれている内在ニューロンの応答と、別に記録された応答との間には強い相関があります。これは、モデルが網膜の内在ニューロン活動の重要な側面を捉えていることを示しています。自然なシーンで訓練された場合、広範な動作解析、適応性、予測コーディング現象を再現することに成功します。一方、白いノイズで訓練されたモデルでは同じセットのイベントを再現することができず、自然な視覚処理を理解するためには自然な風景を調査することが必要であるという考えを支持しています。 モデルの範疇細胞が行う計算は、チームによって提示された手法を用いてモデルの内在ニューロンの個々の貢献に分解されています。このアプローチにより、網膜の計算を生成するために内在ニューロンがさまざまな空間的および時間的な応答パターンと相互作用するという新しい理論が自動的に生成され、予測発生が明らかにされます。 自然な画像のシーケンスに対しては、画像は秒間30フレームの揺れを受け、1秒ごとに変更され、視網膜運動データを模倣したランダムウォークパターンが生成されました。この方法により、網膜の機能が行われる環境により似た空間時間的な刺激が生成されました。 結論として、研究チームは、正確な応答を再現するために、網膜の構造に似た3層の神経処理が重要であることを発見しました。このモデルは、実際の網膜範疇細胞が自然な画像とランダムノイズにどのように反応するかを正確に予測することに成功しました。特定の層を持つ注意深く設計されたモデルは、これらの細胞の振る舞いを正確に模倣します。したがって、この研究は、視覚システムが世界を解釈する方法を理解することを可能にし、自然な視覚に関わる複雑なプロセスに対する洞察を提供します。
大規模な言語モデルを効率的に提供するためのフレームワーク
最近数ヶ月間、大規模な言語モデルの利用に関して非常に熱心な動きがありましたそれは驚くべきことではありませんなぜなら、それらは私たちが取り組むべきほとんどのユースケースに対応する能力を持っているからです

洞察を具体的な成果に変える
ここには、ココア、植物性脂肪、甘味料をブレンドしたコンパウンドチョコレートが表示されています高価な材料に比べて、経済的な本物のチョコレートの代替品です見つけることができます
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.