Learn more about Search Results subplots - Page 6

- You may be interested
- スターバックスのコーヒー代で、自分自身...
- 最適なテクノロジー/ベンダーを選ぶための...
- 「UVeyeの共同設立者兼CEO、アミール・ヘ...
- Covid-19への闘いを加速する:研究者がAI...
- ロボキャット:自己改善型ロボティックエ...
- 最近の人類学的研究によれば、クロード2.1...
- データ品質のレイヤー
- Azure Machine Learningにおける生成AI:A...
- AudioSep 記述するすべてを分離する
- 「2023年のトップAIポッドキャスト」
- Power BI vs Tableau:類似点と相違点
- 「SuperDuperDBを活用して簡単にシンプル...
- 「最も価値のあるコードは、書くべきでな...
- MITの研究者が新しいAIツール「PhotoGuard...
- 革新的な製造プロセスへの3Dインサイト

ロッテン・トマト映画の評価予測のデータサイエンスプロジェクト:2つ目のアプローチ
レビューの感情に基づいて映画の状態を予測する
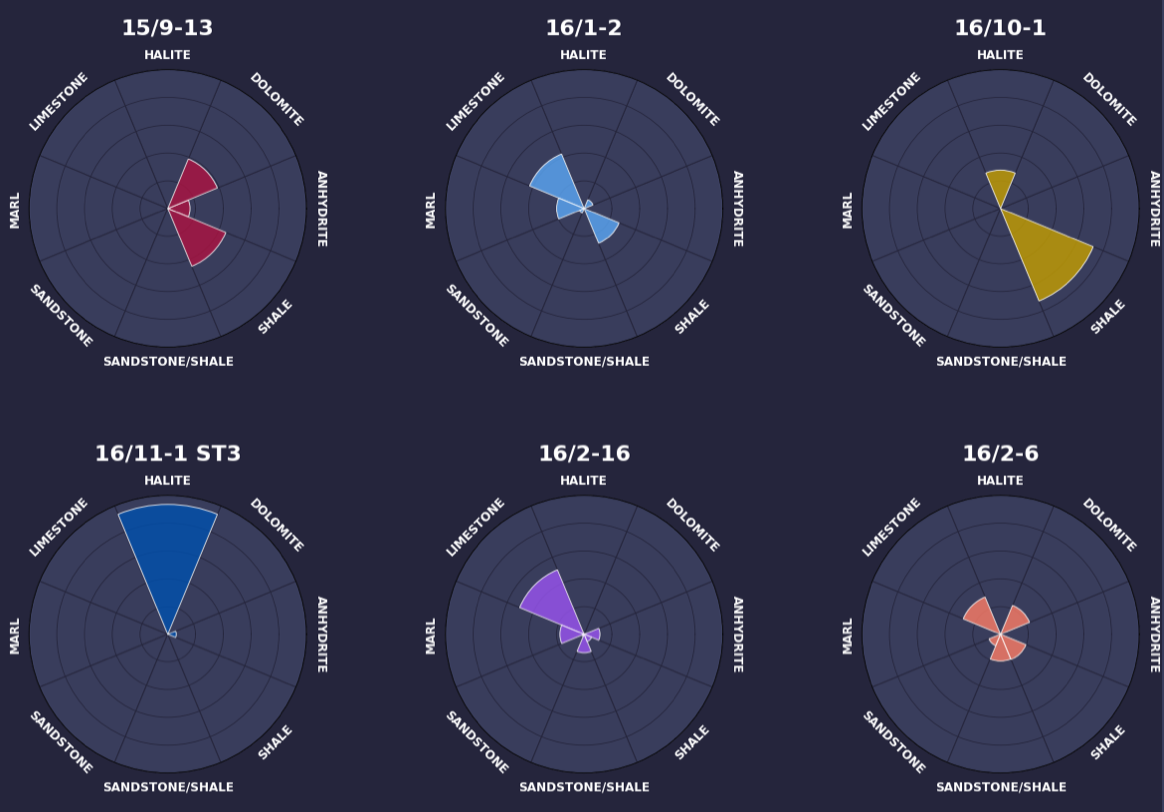
Matplotlibを使用してインフォグラフィックを作成する
データを扱い、データサイエンティストとして仕事をするためには、魅力的で興味深いデータの可視化を作成することが重要ですこれにより、読者に情報を簡潔な形式で提供することができ、理解を助けることができます

Pythonを使用したMann-Kendall傾向検定
はじめに マン・ケンドール傾向検定は、H.A.マンとD.R.ケンドールにちなんで名付けられた非パラメトリック検定であり、時間の経過に伴う傾向が有意であるかを判断するために使用されます。傾向は、時間の経過とともに単調に増加または減少することができます。パラメトリック検定ではデータの分布について心配する必要がないため、非パラメトリック検定です。ただし、データには直列相関/自己相関(時系列の誤差項が1期から別の期に移動すること)がない必要があります。 マン・ケンドール検定は、特定のデータの分布を仮定せずに、一貫して増加または減少する傾向を検出するために設計されています。これは、正規性などのパラメトリック検定の仮定を満たさない可能性のあるデータを扱う際に特に有用です。 この記事は、データサイエンスブログマラソンの一環として公開されました。 サンプルサイズの要件 サンプルが3または4のように非常に小さい場合、トレンドを見つける可能性が非常に低いです。時間の経過とともにサンプル数が増えるほど、テスト統計量は信頼性が高くなります。ただし、非常に少ないサンプルでもテストを実施することができます。したがって、推奨されるデータは少なくとも10です。 テストの目的 この記事では、列車の脱線に関連する事故について、時間の経過とともに研究します。オリッサ州で最近の列車脱線事故は、再び鉄道の安全性について問題を提起しました。鉄道事故は、事故の種類(例:正面衝突、後方衝突、爆発、側面衝突、脱線、火災など)で分類される場合があります。時間の経過とともに、技術的およびインフラ面で鉄道には多くの改善がありました。しかし、世界中で列車事故は頻繁に発生しています。列車事故は、世界中の鉄道システムで発生する不幸な出来事です。これらの事故は、生命の喪失、負傷、財産の損害につながる可能性があります。 この研究では、年月をかけて、インドの鉄道事故(ここでは脱線事故のカテゴリを研究します)を、過去の改善策を考慮に入れながら、減少させることができたかどうかを判断します。インドの脱線事故に関するデータは、時系列の性質を持っています。2001年から2016年までの脱線事故のデータが整理されています。 私たちのデータ 上記の表から、データの減少傾向が明らかにわかります。2001年から、脱線事故の数は非常に大幅に減少しました。2001年には350件の脱線事故があり、2016年には65件に減少しました。データが順番に整理されているため、Python環境に直接入力して作業することができます。Pythonでデータを適切に視覚化するためにプロットを作成しましょう。 !pip install seaborn import seaborn as sns import matplotlib.pyplot as plt fig =…
科学ソフトウェアの開発
この記事では、このシリーズの最初の記事で示されたように、科学ソフトウェアの開発においてTDDの原則に従って、Sobelフィルタとして知られるエッジ検出フィルタを開発します
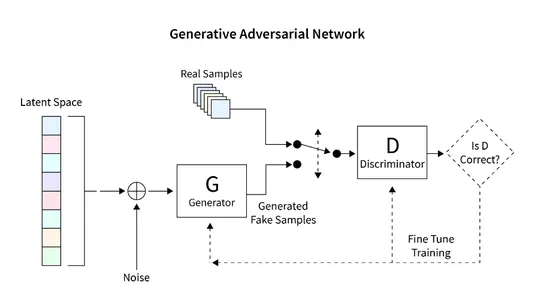
TensorFlowを使用したGANの利用による画像生成
イントロダクション この記事では、GAN(Generative Adversarial Networks)を使用して手書き数字のユニークなレンダリングを生成するためのTensorFlowの応用について探求します。GANフレームワークには、ジェネレータとディスクリミネータという2つの主要なコンポーネントがあります。ジェネレータはランダムな方法で新しい画像を生成し、ディスクリミネータは本物と偽物の画像を区別するために設計されています。GANのトレーニングを通じて、手書き数字に似たコレクションの画像を得ることができます。この記事の主な目的は、MNISTデータセットを使用してGANを構築し評価する手順を概説することです。 学習目標 この記事は、生成的対抗ネットワーク(GAN)の包括的な紹介を提供し、画像生成におけるその応用を探求します。 このチュートリアルの主な目的は、TensorFlowライブラリを使用してGANを構築する手順をステップバイステップで読者に案内することです。MNISTデータセットでGANをトレーニングして手書き数字の新しい画像を生成する方法をカバーしています。 この記事では、ジェネレータとディスクリミネータを含むGANのアーキテクチャとコンポーネントについて説明し、基本的な動作原理を読者の理解を深めるために探求します。 学習を支援するために、記事にはMNISTデータセットの読み込みと前処理、GANアーキテクチャの構築、損失関数の計算、ネットワークのトレーニング、結果の評価などさまざまなタスクをデモンストレーションするコード例が含まれています。 さらに、この記事ではGANの予想される成果物である手書き数字に酷似した画像のコレクションを探求します。 この記事は、データサイエンスブログマラソンの一環として公開されました。 何を構築するのか? 既存の画像データベースを使用して新しい画像を生成することは、生成的対抗ネットワーク(GAN)と呼ばれる特殊なモデルの主要な特徴です。GANは多様な画像データセットを活用して教師なしまたは半教師ありの画像を生成することに優れています。 この記事では、GANの画像生成の潜在能力を活用して手書き数字を作成します。手法としては、手書き数字のデータベースでネットワークをトレーニングすることが含まれます。この教示的な記事では、Tensorflowライブラリを利用して基本的なGANを構築し、MNISTデータセットでトレーニングを行い、手書き数字の新しい画像を生成します。 どのように設定しますか? この記事の主な焦点は、GANの画像生成の潜在能力を活用することです。手順は、画像データベースの読み込みと前処理から始まり、GANのトレーニングプロセスを容易にするためです。データが正常に読み込まれたら、GANモデルを構築し、トレーニングとテストのための必要なコードを開発します。次のセクションでは、この機能を実装し、MNISTデータベースを使用して新しい画像を生成するための詳細な手順が提供されます。 モデルの構築 構築するGANモデルは、2つの重要なコンポーネントで構成されています: ジェネレータ:このコンポーネントは新しい画像を生成する責任があります。 ディスクリミネータ:このコンポーネントは生成された画像の品質を評価します。 GANを使用して画像を生成するために開発する一般的なアーキテクチャは、以下の図に示されています。次のセクションでは、データベースの読み取り、必要なアーキテクチャの作成、損失関数の計算、ネットワークのトレーニングなどの詳細な手順について簡単に説明します。また、ネットワークの検査と新しい画像の生成に使用するコードも提供されます。 データセットの読み込み MNISTデータセットは、コンピュータビジョンの分野で非常に重要で、28×28ピクセルの大きさの手書き数字の広範なコレクションで構成されています。このデータセットは、グレースケールの単一チャンネルの画像形式であるため、GANの実装に理想的です。 次のコードスニペットは、Tensorflowの組み込み関数を使用してMNISTデータセットを読み込む例を示しています。読み込みが成功したら、画像を正規化し、3次元形式に変形します。この変換により、GANアーキテクチャ内で2D画像データを効率的に処理することができます。また、トレーニングデータと検証データの両方にメモリが割り当てられます。…
南アメリカにおける降水量と気候学的なラスターデータの活用
2023年にエルニーニョ現象が激化するにつれて、気候学的および降水データは、その気象パターンと地球全体または地域の気候ダイナミクスへの影響を解読するために基本的な要素となっています...

ロッテン・トマト映画評価予測のデータサイエンスプロジェクト:最初のアプローチ
数値およびカテゴリカルな特徴に基づく映画の状態予測

Pythonを使用して北極の氷の傾向を分析する
Pythonは、データサイエンスのための卓越したプログラミング言語として、計測データを収集・クリーニング・解釈することが容易になりますPythonを使って、予測をバックテストし、モデルを検証することができますそして...

メタAIのもう一つの革命的な大規模モデル — 画像特徴抽出のためのDINOv2
Mete AIは、画像から自動的に視覚的な特徴を抽出する新しい画像特徴抽出モデルDINOv2の新バージョンを紹介しましたこれはAIの分野でのもう一つの革命的な進歩です...

紛争のトレンドとパターンの探索:マニプールのACLEDデータ分析
はじめに データ分析と可視化は、複雑なデータセットを理解し、洞察を効果的に伝えるための強力なツールです。この現実世界の紛争データを深く掘り下げる没入型探索では、紛争の厳しい現実と複雑さに深く踏み込みます。焦点は、長期にわたる暴力と不安定状態によって悲惨な状況に陥ったインド北東部のマニプール州にあります。私たちは、武装紛争ロケーション&イベントデータプロジェクト(ACLED)データセット[1]を使用し、紛争の多面的な性質を明らかにするための詳細なデータ分析の旅に出ます。 学習目標 ACLEDデータセットのデータ分析技術に熟達する。 効果的なデータ可視化のスキルを開発する。 脆弱な人口に対する暴力の影響を理解する。 紛争の時間的および空間的な側面に関する洞察を得る。 人道的ニーズに対処するための根拠に基づくアプローチを支援する。 この記事は、データサイエンスブログマラソンの一環として公開されました。 利害の衝突 このブログで提示された分析と解釈に責任を持つ特定の組織や団体はありません。目的は、紛争分析におけるデータサイエンスの潜在力を紹介することです。さらに、これらの調査結果には個人的な利益や偏見が含まれておらず、紛争のダイナミクスを客観的に理解するアプローチが確保されています。データ駆動型の方法を促進し、紛争分析に関する広範な議論に情報を提供するために、積極的に利用することを推奨します。 実装 なぜACLEDデータセットを使用するのか? ACLEDデータセットを活用することで、データサイエンス技術の力を活用することができます。これにより、マニプール州の状況を理解するだけでなく、暴力に関連する人道的側面にも光を当てることができます。ACLEDコードブックは、このデータセット[2]で使用されるコーディングスキームと変数に関する詳細な情報を提供する包括的な参考資料です。 ACLEDの重要性は、共感的なデータ分析にあります。これにより、マニプール州の暴力に関する理解が深まり、人道的ニーズが明らかにされ、暴力の解決と軽減に貢献します。これにより、影響を受けるコミュニティに平和で包摂的な未来が促進されます。 このデータ駆動型の分析により、貴重な洞察力を得るだけでなく、マニプール州の暴力の人的コストにも光が当てられます。ACLEDデータを精査することで、市民人口、強制的移動、必要なサービスへのアクセスなど、地域で直面する人道的現実の包括的な描写が可能になります。 紛争のイベント まず、ACLEDデータセットを使用して、マニプール州の紛争のイベントを調査します。以下のコードスニペットは、インドのACLEDデータセットを読み込み、マニプール州のデータをフィルタリングして、形状が(行数、列数)のフィルタリングされたデータセットを生成します。フィルタリングされたデータの形状を出力します。 import pandas as pd # ACLEDデータをダウンロードして国別のcsvをインポートする…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.