Learn more about Search Results bitsandbytes - Page 6

- You may be interested
- 「A.I.が住宅法案を書いた批評家はそれが...
- xAIはPromptIDEを発表しました:Promptエ...
- AIはロボットが全身を使ってオブジェクト...
- ベイジアンネットワークの背後にあるスト...
- 現代のデータサイエンティストのための正...
- 「ジェネラティブAI:2024年の人事におけ...
- 「AWSサービスを使用して完全なウェブアプ...
- NYUとNVIDIAが協力して、患者の再入院を予...
- DEF CONでハッカーたちがいたずらをしてAI...
- 「NVIDIAのCEOがインドの首相ナレンドラ・...
- 「イーロン・マスクのxAI、10億ドルの資金...
- 迷路の作成
- 「vLLMの解読:言語モデル推論をスーパー...
- 「データエンジニアリングをマスターする...
- HuggingFaceはTextEnvironmentsを紹介しま...

フリーティアのGoogle Colabで🧨ディフューザーを使用してIFを実行中
要約:Google Colabの無料ティア上で最も強力なオープンソースのテキストから画像への変換モデルIFを実行する方法を紹介します。 また、Hugging Face Spaceでモデルの機能を直接探索することもできます。 公式のIF GitHubリポジトリから圧縮された画像。 はじめに IFは、ピクセルベースのテキストから画像への生成モデルで、DeepFloydによって2023年4月下旬にリリースされました。モデルのアーキテクチャは、GoogleのクローズドソースのImagenに強く影響を受けています。 IFは、Stable Diffusionなどの既存のテキストから画像へのモデルと比較して、次の2つの利点があります: モデルは、レイテントスペースではなく「ピクセルスペース」(つまり、非圧縮画像上で)で直接動作し、Stable Diffusionのようなノイズ除去プロセスを実行しません。 モデルは、Stable Diffusionでテキストエンコーダとして使用されるCLIPよりも強力なテキストエンコーダであるT5-XXLの出力で訓練されます。 その結果、IFは高周波の詳細(例:人の顔や手など)を持つ画像を生成する能力に優れており、信頼性のあるテキスト付き画像を生成できる最初のオープンソースの画像生成モデルです。 ピクセルスペースで動作し、より強力なテキストエンコーダを使用することのデメリットは、IFが大幅に多くのパラメータを持っていることです。T5、IFのテキストから画像へのUNet、IFのアップスケーラUNetは、それぞれ4.5B、4.3B、1.2Bのパラメータを持っています。それに対して、Stable Diffusion 2.1のテキストエンコーダとUNetは、それぞれ400Mと900Mのパラメータしか持っていません。 しかし、メモリ使用量を低減させるためにモデルを最適化すれば、一般のハードウェア上でもIFを実行することができます。このブログ記事では、🧨ディフューザを使用してその方法を紹介します。 1.)では、テキストから画像への生成にIFを使用する方法を説明し、2.)と3.)では、IFの画像バリエーションと画像インペインティングの機能について説明します。 💡 注意:メモリの利得と引き換えに速度の利得を得るために、IFを無料ティアのGoogle Colab上で実行できるようにしています。A100などの高性能なGPUにアクセスできる場合は、公式のIFデモのようにすべてのモデルコンポーネントをGPU上に残して、最大の速度で実行することをお勧めします。…

Amazon SageMakerのHugging Face LLM推論コンテナをご紹介します
これは、オープンソースのLLM(Large Language Model)であるBLOOMをAmazon SageMakerに展開し、新しいHugging Face LLM Inference Containerを使用して推論を行う方法の例です。Open Assistantデータセットで訓練されたオープンソースのチャットLLMである12B Pythia Open Assistant Modelを展開します。 この例では以下の内容をカバーしています: 開発環境のセットアップ 新しいHugging Face LLM DLCの取得 Open Assistant 12BのAmazon SageMakerへの展開 モデルを使用して推論およびチャットを行う…

ファルコンはHugging Faceのエコシステムに着陸しました
イントロダクション ファルコンは、アブダビのテクノロジーイノベーション研究所が作成し、Apache 2.0ライセンスの下で公開された最新の言語モデルの新しいファミリーです。 特筆すべきは、Falcon-40Bが多くの現在のクローズドソースモデルと同等の機能を持つ、初めての「真にオープンな」モデルであることです 。これは、開発者、愛好家、産業界にとって素晴らしいニュースであり、多くのエキサイティングなユースケースの扉を開くものです。 このブログでは、ファルコンモデルについて詳しく調査し、まずそれらがどのようにユニークであるかを説明し、その後、Hugging Faceのエコシステムのツールを使ってそれらの上に構築することがどれほど簡単かを紹介します。 目次 ファルコンモデル デモ 推論 評価 PEFTによるファインチューニング 結論 ファルコンモデル ファルコンファミリーは、2つのベースモデルで構成されています:Falcon-40Bとその弟であるFalcon-7Bです。 40Bパラメータモデルは現在、Open LLM Leaderboardのトップを占めており、7Bモデルはそのクラスで最高のモデルです 。 Falcon-40BはGPUメモリを約90GB必要としますが、それでもLLaMA-65Bよりは少なく、Falconはそれを上回します。一方、Falcon-7Bは約15GBしか必要とせず、推論やファインチューニングは一般的なハードウェアでも利用可能です。 (このブログの後半では、より安価なGPUでもFalcon-40Bを利用できるように、量子化を活用する方法について説明します!) TIIはまた、モデルのInstructバージョンであるFalcon-7B-InstructとFalcon-40B-Instructを提供しています。これらの実験的なバリアントは、命令と会話データに適応された調整が行われているため、人気のあるアシスタントスタイルのタスクに適しています。 モデルを素早く試してみたい場合は、これらが最適な選択肢です。…
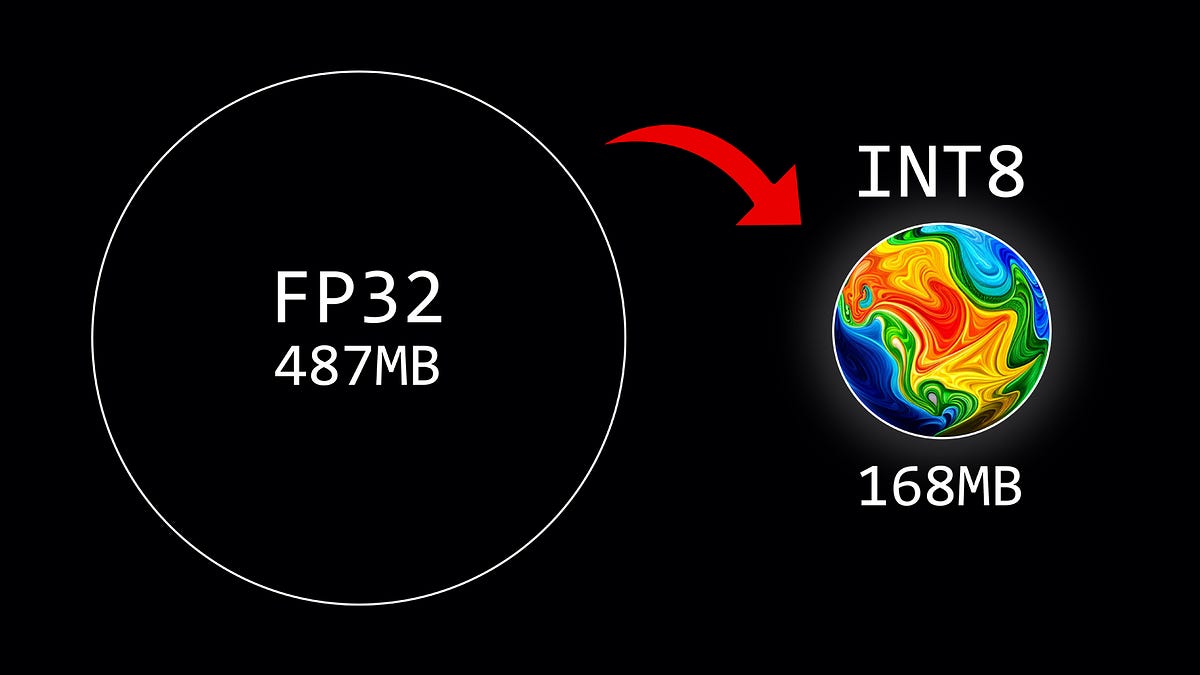
重み量子化の概要
この記事では、8ビットの量子化方式を使用して、大規模言語モデルのパラメータを量子化する方法について説明しています

Falcon-7Bの本番環境への展開
これまでに、ChatGPTの能力と提供するものを見てきましたしかし、企業利用においては、ChatGPTのようなクローズドソースモデルは、企業がデータを制御できないというリスクがあるかもしれません...

QLoRAを使用して、Amazon SageMaker StudioノートブックでFalcon-40Bと他のLLMsをインタラクティブにチューニングしてください
大規模な言語モデル(LLM)の微調整により、オープンソースの基礎モデルを調整して、特定のドメインタスクでのパフォーマンスを向上させることができますこの記事では、Amazon SageMakerノートブックを使用して、最新のオープンソースモデルを微調整する利点について説明します私たちは、Hugging Faceのパラメータ効率の良い微調整(PEFT)ライブラリと、bitsandbytesを介した量子化技術を利用して、インタラクティブな微調整をサポートしています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.