Learn more about Search Results Transformer - Page 6

- You may be interested
- 統計分析入門ガイド | 5つのステップと例
- CPU上でBERT推論をスケーリングアップする...
- 「機械学習分類のための適合予測—基礎から...
- 「ミリオンドルのホームサービスビジネス...
- 大規模な言語モデルは本当に行動し思考で...
- 「トリントの創設者兼CEO、ジェフ・コフマ...
- 「アニメート・ア・ストーリー:高品質で...
- 「Pandasの結合操作を実行するための長す...
- 「スタンフォードのこのAI論文では、スパ...
- 「データから次に最適な質問をどのように...
- 「NSFが1,090万ドルの資金を安全なAI技術...
- 装着可能な光学装置が、産後出血の検出に...
- 「Code Llama内部:Meta AIがCode LLMスペ...
- 「研究者がChatGPTを破った方法と、将来の...
- 「AIをウェルコネクトされたチームに統合...

Hugging Face TransformersとAWS Inferentiaを使用して、BERT推論を高速化する
ノートブック:sagemaker/18_inferentia_inference BERTとTransformersの採用はますます広がっています。Transformerベースのモデルは、自然言語処理だけでなく、コンピュータビジョン、音声、時系列でも最先端のパフォーマンスを達成しています。💬 🖼 🎤 ⏳ 企業は、大規模なワークロードのためにトランスフォーマーモデルを使用するため、実験および研究フェーズから本番フェーズにゆっくりと移行しています。ただし、デフォルトでは、BERTとその仲間は、従来の機械学習アルゴリズムと比較して、比較的遅く、大きく、複雑なモデルです。TransformersとBERTの高速化は、将来的に解決すべき興味深い課題となるでしょう。 AWSはこの課題を解決するために、最適化された推論ワークロード向けに設計されたカスタムマシンラーニングチップであるAWS Inferentiaを開発しました。AWSは、AWS Inferentiaが「現行世代のGPUベースのAmazon EC2インスタンスと比較して、推論ごとのコストを最大80%低減し、スループットを最大2.3倍高める」と述べています。 AWS Inferentiaインスタンスの真の価値は、各デバイスに搭載された複数のNeuronコアを通じて実現されます。Neuronコアは、AWS Inferentia内部のカスタムアクセラレータです。各Inferentiaチップには4つのNeuronコアが搭載されています。これにより、高スループットのために各コアに1つのモデルをロードするか、低レイテンシのためにすべてのコアに1つのモデルをロードすることができます。 チュートリアル このエンドツーエンドのチュートリアルでは、Hugging Face Transformers、Amazon SageMaker、およびAWS Inferentiaを使用して、テキスト分類のBERT推論を高速化する方法を学びます。 ノートブックはこちらでご覧いただけます:sagemaker/18_inferentia_inference 以下の内容を学びます: 1. Hugging Face TransformerをAWS Neuronに変換する 2.…

Hugging FaceでのDecision Transformersの紹介 🤗
🤗 Hugging Faceでは、ディープ強化学習の研究者や愛好家向けのエコシステムに貢献しています。最近では、Stable-Baselines3などのディープRLフレームワークを統合しました。 そして、今日は喜んでお知らせします。オフライン強化学習手法であるDecision Transformerを🤗 transformersライブラリとHugging Face Hubに統合しました。ディープRLの分野でアクセシビリティを向上させるための興味深い計画があり、これからの数週間や数ヶ月でそれを共有できることを楽しみにしています。 オフライン強化学習とは何ですか? Decision Transformerの紹介 🤗 TransformersでDecision Transformerを使用する まとめ 次は何ですか? 参考文献 オフライン強化学習とは何ですか? ディープ強化学習(RL)は、意思決定エージェントを構築するためのフレームワークです。これらのエージェントは、試行錯誤を通じて環境との相互作用を通じて最適な行動(ポリシー)を学び、報酬を受け取ることでユニークなフィードバックを得ることを目指します。 エージェントの目標は、累積報酬であるリターンを最大化することです。なぜなら、RLは報酬の仮説に基づいているからです:すべての目標は、期待累積報酬を最大化することとして記述できるからです。 ディープ強化学習エージェントは、バッチの経験を使用して学習します。問題は、どのようにしてそれを収集するかです: オンラインとオフラインの設定での強化学習の比較、この投稿からの図 オンライン強化学習では、エージェントは直接データを収集します:環境との相互作用によってバッチの経験を収集します。その後、この経験を即座に(または一部のリプレイバッファを介して)使用して学習します(ポリシーを更新します)。 しかし、これはエージェントを実際の世界で直接トレーニングするか、シミュレータを持っている必要があることを意味します。もしそれがなければ、環境の複雑な現実をどのように反映させるか(環境での複雑な現実を反映させる方法は?)という非常に複雑な問題、高価な問題、そして安全性の問題があります。なぜなら、シミュレータに欠陥があれば、競争上の優位性を提供する場合はエージェントがそれを悪用する可能性があるからです。…

Habana LabsとHugging Faceが提携し、Transformerモデルのトレーニングを加速化する
2022年4月12日、カリフォルニア州サンタクララとサンフランシスコ 深層学習によって駆動されるトランスフォーマーモデルは、自然言語処理、コンピュータビジョン、音声など、さまざまな機械学習タスクで最先端のパフォーマンスを発揮します。しかし、大規模なトレーニングは多くの計算能力を必要とするため、全体のプロセスが不必要に長く、複雑で、高コストになることがあります。 今日、高効率な専用のディープラーニングプロセッサを提供するパイオニアであるHabana® Labsと、トランスフォーマーモデルの開発元であるHugging Faceは、優れた品質のトランスフォーマーモデルのトレーニングをより簡単かつ迅速にするために協力しています。HabanaのSynapseAIソフトウェアスイートとHugging Face Optimumオープンソースライブラリの統合により、データサイエンティストや機械学習エンジニアはわずか数行のコードでHabanaプロセッサ上でトランスフォーマーモデルのトレーニングジョブを加速し、生産性を向上させながらトレーニングコストを削減することができます。 AmazonのEC2 DL1インスタンスとSupermicroのX12 Gaudi AI Training Serverを駆動するHabana Gaudiトレーニングソリューションは、同等のトレーニングソリューションに比べて最大40%低い価格/パフォーマンスを提供し、より少ない費用でより多くのトレーニングを実現します。Gaudiプロセッサごとに10の100ギガビットイーサネットポートを統合することにより、システムのスケーリングを容易かつ費用効果的に1から数千のGaudiに拡張することができます。HabanaのSynapseAI®は、Gaudiのパフォーマンスと使いやすさに最適化され、TensorFlowとPyTorchのフレームワークをサポートし、コンピュータビジョンと自然言語処理のアプリケーションに特化しています。 GitHubで60,000以上のスター、30,000以上のモデル、毎月数百万の訪問数を誇るHugging Faceは、オープンソースソフトウェアの歴史で最も急成長しているプロジェクトの一つであり、機械学習コミュニティの頼れる場所です。 Hugging Faceのハードウェアパートナープログラムにより、Gaudiの高度なディープラーニングハードウェアと究極のトランスフォーマーツールセットが提供されます。このパートナーシップにより、Habana Gaudiトレーニングトランスフォーマーモデルライブラリの急速な拡大が可能となり、自然言語処理、コンピュータビジョン、音声など、さまざまな顧客のユースケースにGaudiの効率性と使いやすさをもたらします。 「Gaudiトレーニングプラットフォームの効率性、使いやすさ、スケーラビリティの恩恵を受けるトランスフォーマーモデルの需要の増大に対応するために、Hugging Faceとその多くのオープンソース開発者とパートナーシップを結ぶことを楽しみにしています」とHabana Labsのソフトウェア製品マネージメント責任者であるSree Ganesanは述べています。 「Habana…
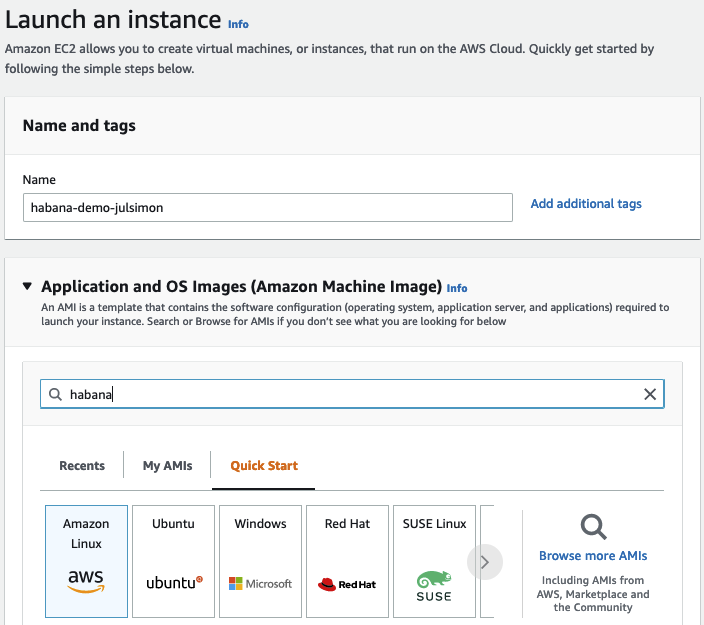
Habana GaudiでのTransformersの始め方
数週間前に、Habana LabsとHugging Faceが協力してTransformerモデルのトレーニングを加速することを発表できたことを喜んでお知らせいたします。 Habana Gaudiアクセラレータは、最新のGPUベースのAmazon EC2インスタンスと比較して、機械学習モデルのトレーニングにおいて最大40%の価格パフォーマンス向上を提供します。私たちはこの価格パフォーマンスの利点をTransformersにもたらすことに非常に興奮しています🚀 この実践的な投稿では、Amazon Web ServicesでHabana Gaudiインスタンスを素早くセットアップし、テキスト分類用にBERTモデルを微調整する方法を紹介します。通常どおり、コードはすべて提供されているため、プロジェクトで再利用できます。 さあ、始めましょう! AWSでHabana Gaudiインスタンスをセットアップする Habana Gaudiアクセラレータを使用する最も簡単な方法は、Amazon EC2 DL1インスタンスを起動することです。これらのインスタンスには、Habana SynapseAI® SDKがプリインストールされたHabana Deep Learning Amazon Machine Image(AMI)が搭載されています。また、GaudiアクセラレーションされたDockerコンテナを実行するために必要なツールも含まれています。他のAMIやコンテナを使用したい場合は、Habanaのドキュメントに手順が記載されています。…

Hugging Face Optimumを使用して、TransformersをONNXに変換する
ハグフェース・ハブには、毎日何百ものトランスフォーマーの実験とモデルがアップロードされています。これらの実験を行う機械学習エンジニアや学生は、PyTorch、TensorFlow/Keras、その他のさまざまなフレームワークを使用しています。これらのモデルはすでに数千の企業によって使用され、AIを搭載した製品の基盤となっています。 トランスフォーマーのモデルを本番環境で展開する場合、まずは特殊なランタイムとハードウェア上で読み込み、最適化、実行できるシリアライズされた形式にエクスポートすることをお勧めします。 このガイドでは、以下のことについて学びます: ONNXとは何か Hugging Face Optimumとは何か どのトランスフォーマーアーキテクチャがサポートされているか トランスフォーマーモデル(BERT)をONNXに変換する方法 次は何か さあ、始めましょう! 🚀 モデルを最大限の効率で実行するために最適化することに興味がある場合は、🤗 Optimumライブラリをチェックしてください。 5. 次は何か トランスフォーマーモデルをONNXに正常に変換したので、最適化および量子化ツールの全セットが使用できるようになりました。次のステップとしては、以下のことが考えられます: Optimumとトランスフォーマーパイプラインを使用した高速推論にONNXモデルを使用する モデルに静的量子化を適用して、レイテンシを約3倍改善する トレーニングにONNXランタイムを使用する ONNXモデルをTensorRTに変換してGPUパフォーマンスを向上させる … モデルを最大限の効率で実行するために最適化することに興味がある場合は、🤗 Optimumライブラリをチェックしてください。…

Sentence Transformersモデルのトレーニングと微調整
このNotebook Companion付きのチュートリアルをご覧ください: センテンス変換モデルのトレーニングまたはファインチューニングは、利用可能なデータと目標のタスクに大きく依存します。キーは2つあります: モデルにデータを入力し、データセットを適切に準備する方法を理解する。 データセットと関連する異なる損失関数を理解する。 このチュートリアルでは、以下の内容を学びます: “スクラッチ”から作成するか、Hugging Face Hubからファインチューニングすることにより、センテンス変換モデルの動作原理を理解する。 データセットの異なる形式について学ぶ。 データセットの形式に基づいて選択できる異なる損失関数について確認する。 モデルのトレーニングまたはファインチューニング。 Hugging Face Hubにモデルを共有する。 センテンス変換モデルが最適な選択肢でない場合について学ぶ。 センテンス変換モデルの動作原理 センテンス変換モデルでは、可変長のテキスト(または画像ピクセル)を、その入力の意味を表す固定サイズの埋め込みにマップします。埋め込みの取得方法については、前回のチュートリアルをご覧ください。この投稿では、テキストに焦点を当てています。 センテンス変換モデルの動作原理は次の通りです: レイヤー1 – 入力テキストは、Hugging Face Hubから直接取得できる事前学習済みTransformerモデルを通過します。このチュートリアルでは、「distilroberta-base」モデルを使用します。Transformerの出力は、すべての入力トークンに対する文脈化された単語の埋め込みです。テキストの各トークンに対する埋め込みを想像してください。…

transformers、accelerate、bitsandbytesを使用した大規模トランスフォーマーの8ビット行列乗算へのやさしい入門
導入 言語モデルはますます大きくなっています。この執筆時点では、PaLMは540Bのパラメータを持ち、OPT、GPT-3、およびBLOOMは約176Bのパラメータを持ち、さらに大きなモデルに向かっています。以下は、いくつかの最近の言語モデルのサイズを示した図です。 したがって、これらのモデルは簡単にアクセス可能なデバイス上で実行するのが難しいです。例えば、BLOOM-176Bで推論を行うためには、8つの80GBのA100 GPU(各約15,000ドル)が必要です。BLOOM-176Bを微調整するには、これらのGPUが72台必要です!PaLMのようなさらに大きなモデルでは、さらに多くのリソースが必要です。 これらの巨大なモデルは多くのGPUで実行する必要があるため、モデルの性能を維持しながらこれらの要件を削減する方法を見つける必要があります。モデルサイズを縮小するためのさまざまな技術が開発されており、量子化や蒸留などの技術があります。 BLOOM-176Bのトレーニングを完了した後、HuggingFaceとBigScienceでは、この大きなモデルをより少ないGPUで簡単に実行できるようにする方法を探していました。BigScienceコミュニティを通じて、大規模モデルの予測パフォーマンスを低下させずに大規模モデルのメモリフットプリントを2倍に減らすInt8推論の研究について知らされました。すぐにこの研究に協力し始め、Hugging Faceのtransformersに完全に統合することで終了しました。このブログ記事では、Hugging FaceモデルのLLM.int8()統合を提供し、詳細を以下で説明します。研究についてもっと読みたい場合は、論文「LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale」を読んでください。 この記事では、この量子化技術の高レベルの概要を提供し、transformersライブラリへの統合の難しさを概説し、このパートナーシップの長期的な目標を立てます。 ここでは、なぜ大きなモデルが多くのメモリを使用するのか、BLOOMが350GBになる理由について、少しずつ基本的な前提を説明します。 機械学習で使用される一般的なデータ型 まず、機械学習の文脈では「精度」とも呼ばれる異なる浮動小数点データ型の基本的な理解から始めます。 モデルのサイズは、そのパラメータの数とその精度によって決まります。一般的には、float32、float16、またはbfloat16のいずれかのデータ型が使用されます(以下の画像は、https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/から引用されています)。 Float32(FP32)は、標準化されたIEEE 32ビット浮動小数点表現を表します。このデータ型では、幅広い浮動小数点数を表現することが可能です。FP32では、8ビットが「指数」に、23ビットが「仮数」に、1ビットが数値の符号に予約されています。さらに、ほとんどのハードウェアはFP32の操作と命令をサポートしています。 浮動小数点16ビット(FP16)のデータ型では、5ビットが指数に、10ビットが仮数に予約されています。これにより、FP16数の表現可能な範囲はFP32よりもはるかに低くなります。これにより、FP16数はオーバーフロー(非常に大きな数を表現しようとする)やアンダーフロー(非常に小さな数を表現する)のリスクにさらされます。 例えば、10k…

ディープダイブ:Hugging Face Optimum GraphcoreにおけるビジョンTransformer
このブログ投稿では、Hugging Face Optimumライブラリを使用して、事前学習済みのTransformerモデルをあなたのデータセットに簡単に微調整する方法をGraphcoreのIntelligence Processing Units(IPUs)で紹介します。例として、大規模で広く使用されている胸部X線データセットを取り上げ、ビジョンTransformer(ViT)モデルを訓練する手順とノートブックを提供します。 ビジョンTransformer(ViT)モデルの紹介 2017年、GoogleのAI研究者グループがTransformerモデルアーキテクチャを紹介する論文を発表しました。Transformerは新しいセルフアテンションメカニズムによって特徴付けられ、言語アプリケーションのための新しい効率的なモデルのグループとして提案されました。実際、過去5年間でTransformerは爆発的な人気を見ており、自然言語処理(NLP)の事実上の標準として受け入れられています。 言語のためのTransformerは、急速に進化するGPTとBERTモデルファミリーによって特に代表されています。両方とも、Hugging Face Optimum Graphcoreライブラリの一部としてGraphcore IPUs上で簡単かつ効率的に実行することができます。 Transformerモデルアーキテクチャの詳細な説明(NLPに焦点を当てたもの)は、Hugging Faceのウェブサイトで見つけることができます。 Transformerは言語で初期の成功を収めましたが、非常に多目的であり、このブログ投稿でカバーするように、コンピュータビジョン(CV)などのさまざまな目的に使用することができます。 CVは、畳み込みニューラルネットワーク(CNN)が間違いなく最も人気のあるアーキテクチャの1つです。しかし、ビジョンTransformer(ViT)アーキテクチャは、Google Researchが2021年の論文で初めて紹介された画像認識のブレークスルーであり、BERTやGPTと同じセルフアテンションメカニズムを主要なコンポーネントとして使用しています。 BERTや他のTransformerベースの言語処理モデルは、文(つまり単語のリスト)を入力として受け取りますが、ViTモデルは入力画像をいくつかの小さなパッチに分割し、言語処理における個々の単語に相当するものにします。各パッチは、Transformerモデルによって線形にエンコードされ、個別に処理できるベクトル表現に変換されます。この画像をパッチやビジュアルトークンに分割するアプローチは、CNNが使用するピクセル配列とは対照的です。 事前学習により、ViTモデルは画像の内部表現を学習し、それを下流タスクに役立つ視覚的な特徴を抽出するために使用できます。たとえば、事前学習されたビジュアルエンコーダの上に線形層を配置することで、新しいラベル付き画像データセットで分類器を訓練することができます。通常、[CLS]トークンの上に線形層を配置します。このトークンの最後の隠れ状態は、画像全体の表現と見なすことができます。 CNNと比較して、ViTモデルはより高い認識精度を持ちながら、より低い計算コストで動作し、画像分類、物体検出、セグメンテーションなどのさまざまなアプリケーションに適用されています。医療領域のユースケースには、COVID-19、大腿骨骨折、肺気腫、乳がん、アルツハイマー病などの検出と分類などが含まれます。 ViTモデル – IPUに最適なモデル GraphcoreのIPUは、データパイプライニングとモデル並列処理の組み合わせを使用して、ViTモデルに特に適しています。この大規模並列プロセスの高速化は、IPUのMIMDアーキテクチャとIPU-Fabricを中心としたスケールアウトソリューションによって可能になっています。…

Hugging Face TransformersとHabana Gaudiを使用して、BERTを事前に学習する
このチュートリアルでは、Habana GaudiベースのDL1インスタンスを使用してBERT-baseをゼロから事前トレーニングする方法を学びます。Gaudiのコストパフォーマンスの利点を活用するためにAWSで使用します。Hugging Face Transformers、Optimum Habana、およびDatasetsライブラリを使用して、マスクされた言語モデリングを使用してBERT-baseモデルを事前トレーニングします。これは、最初のBERT事前トレーニングタスクの一つです。始める前に、ディープラーニング環境をセットアップする必要があります。 コードを表示する 以下のことを学びます: データセットの準備 トークナイザのトレーニング データセットの前処理 Habana Gaudi上でBERTを事前トレーニングする 注意:ステップ1から3は、CPUを多く使用するタスクのため、異なるインスタンスサイズで実行することができます/すべきです。 要件 始める前に、以下の要件を満たしていることを確認してください DL1インスタンスタイプのクオータを持つAWSアカウント AWS CLIがインストールされていること AWS IAMユーザーがCLIで構成され、ec2インスタンスの作成と管理の権限を持っていること 役立つリソース Hugging Face TransformersとHabana…

マルチリンガルASRのためのWhisperの調整を行います with 🤗 Transformers
このブログでは、ハギングフェイス🤗トランスフォーマーを使用して、Whisperを任意の多言語ASRデータセットに対して細かく調整する手順を段階的に説明します。このブログでは、Whisperモデル、Common Voiceデータセット、および細かな調整の背後にある理論について詳しく説明し、データの準備と細かい調整の手順を実行するためのコードセルと共に提供しています。説明は少ないですが、すべてのコードがあるより簡略化されたバージョンのノートブックは、関連するGoogle Colabを参照してください。 目次 はじめに Google ColabでのWhisperの細かい調整 環境の準備 データセットの読み込み 特徴抽出器、トークナイザー、およびデータの準備 トレーニングと評価 デモの作成 締めくくり はじめに Whisperは、OpenAIのAlec Radfordらによって2022年9月に発表された自動音声認識(ASR)のための事前学習モデルです。Whisperは、Wav2Vec 2.0などの先行研究とは異なり、ラベル付きの音声トランスクリプションデータで事前学習されています。具体的には、680,000時間のデータが使用されています。これは、Wav2Vec 2.0の訓練に使用されるラベルなしの音声データ(60,000時間)よりも桁違いに多いデータです。さらに、この事前学習データのうち117,000時間が多言語ASRデータです。これにより、96以上の言語に適用できるチェックポイントが生成され、その多くは低リソース言語とされています。 このような大量のラベル付きデータにより、Whisperは事前学習データから音声認識の教師ありタスクを直接学習し、音声トランスクリプションデータからテキストへのマッピングを学習します。そのため、Whisperはパフォーマンスの高いASRモデルを得るためにほとんど追加の細かい調整を必要としません。これに対して、Wav2Vec 2.0は非教師付きタスクのマスク予測で事前学習されており、音声から隠れた状態への中間的なマッピングを学習します。非教師付きの事前学習は音声の高品質な表現を生み出しますが、音声からテキストへのマッピングは学習されません。このマッピングは細かい調整中にのみ学習されるため、競争力のあるパフォーマンスを得るにはより多くの細かい調整が必要です。 680,000時間のラベル付き事前学習データにスケールされると、Whisperモデルは多くのデータセットとドメインに対して高い汎化能力を示します。事前学習されたチェックポイントは、LibriSpeech ASRのtest-cleanサブセットで約3%の単語エラーレート(WER)を達成し、TED-LIUMでは4.7%のWERで新たな最先端の結果を実現します(Whisper論文の表8を参照)。Whisperが事前学習中に獲得した多言語ASRの知識は、他の低リソース言語に活用することができます。細かい調整により、事前学習済みのチェックポイントを特定のデータセットと言語に適応させることで、これらの結果をさらに改善することができます。 Whisperは、Transformerベースのエンコーダーデコーダーモデルであり、シーケンスからシーケンスへのモデルとも呼ばれています。Whisperは、オーディオのスペクトログラム特徴のシーケンスをテキストトークンのシーケンスにマッピングします。まず、生のオーディオ入力は特徴抽出器によってログメルスペクトログラムに変換されます。次に、Transformerエンコーダーはスペクトログラムをエンコードしてエンコーダーの隠れ状態のシーケンスを形成します。最後に、デコーダーはエンコーダーの隠れ状態と以前に予測されたトークンの両方に依存して、テキストトークンを自己回帰的に予測します。図1はWhisperモデルを要約しています。 <img…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.