Learn more about Search Results ResNet - Page 6

- You may be interested
- データサイエンティストとしてJavaScript...
- 「人類を800年進化させるAI、GNoMe」
- このAI論文は、イメージとテキストのアラ...
- 「大学は、量子の未来のためにエンジニア...
- カスタムGPTの構築:教訓とヒント
- FermiNet(フェルミネット):第一原理に...
- マイクロソフトは、エンタープライズ向け...
- SalesForceはEinstein StudioとBring Your...
- 「Kubernetesに対応した無限スケーラブル...
- 「VSCodeをDatabricksと統合して、データ...
- 「6週間でCassandraにベクトル検索を追加...
- 研究者たちは、画像内の似たような材料を...
- 「アプリストア–車向け–そう...
- 新しいAI研究がGPT4RoIを紹介します:地域...
- 「OpenAIのGPT Builderが壊れたのは誰のお...
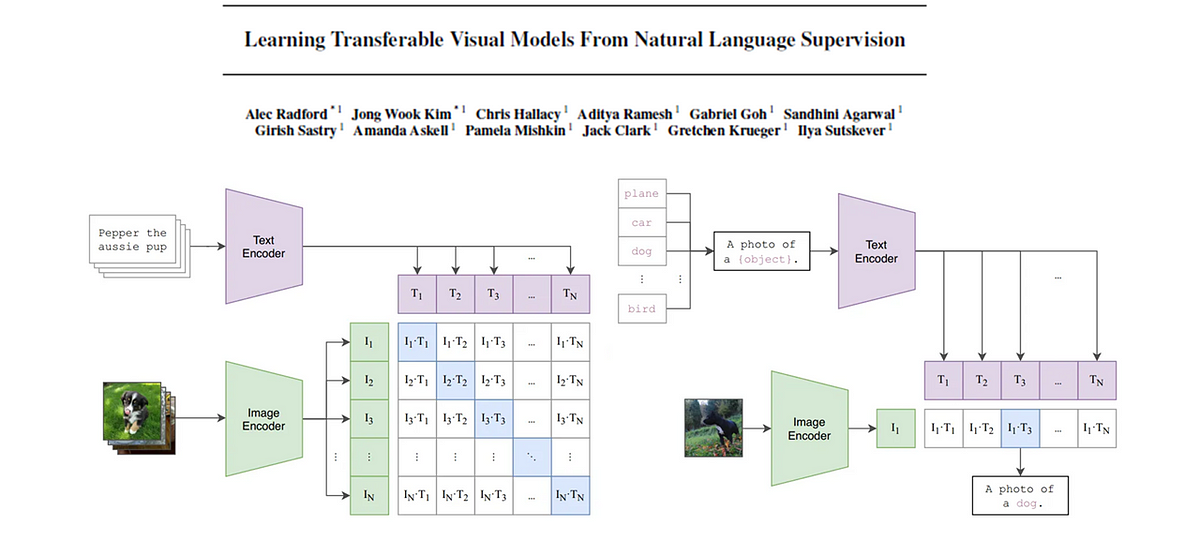
CLIP基礎モデル
この記事では、CLIP(対照的な言語画像事前学習)の背後にある論文を詳しく解説しますキーコンセプトを抽出し、わかりやすく解説しますさらに、画像...
「より良い機械学習システムの構築 – 第3章:モデリング楽しみが始まります」
こんにちは、お帰りなさいまたここでお会いできてうれしいですあなたがもっと良いプロフェッショナルになりたいという意欲、より良い仕事をしたいという願望、そしてより良いMLシステムを構築したいということを本当に感謝していますあなたは素晴らしいです、これからも頑張ってください!このシリーズでは、私は...
画像中のテーブルの行と列をトランスフォーマーを使用して検出する
はじめに 非構造化データを扱ったことがあり、ドキュメント内のテーブルの存在を検出する方法を考えたことはありますか?ドキュメントを迅速に処理するための方法を提供しますか?この記事では、トランスフォーマーを使用して、テーブルの存在だけでなく、テーブルの構造を画像から認識する方法を見ていきます。これは、2つの異なるモデルによって実現されます。1つはドキュメント内のテーブルの検出のためのもので、もう1つはテーブル内の個々の行と列を認識するためのものです。 学習目標 画像上のテーブルの行と列を検出する方法 Table TransformersとDetection Transformer(DETR)の概要 PubTables-1Mデータセットについて Table Transformerでの推論の実行方法 ドキュメント、記事、PDFファイルは、しばしば重要なデータを伝えるテーブルを含む貴重な情報源です。これらのテーブルから情報を効率的に抽出することは、異なるフォーマットや表現の間の課題により複雑になる場合があります。これらのテーブルを手動でコピーまたは再作成するのは時間がかかり、ストレスがかかることがあります。PubTables-1Mデータセットでトレーニングされたテーブルトランスフォーマーは、テーブルの検出、構造の認識、および機能分析の問題に対処します。 この記事はData Science Blogathonの一環として公開されました。 この方法はどのように実現されたのですか? これは、PubTables-1Mという名前の大規模な注釈付きデータセットを使用して、記事などのドキュメントや画像を検出するためのトランスフォーマーモデルであるTable Transformerによって実現されました。このデータセットには約100万のパラメータが含まれており、いくつかの手法を用いて実装されており、モデルに最先端の感触を与えています。効率性は、不完全な注釈、空間的な整列の問題、およびテーブルの構造の一貫性の課題に取り組むことで達成されました。モデルとともに公開された研究論文では、テーブルの構造認識(TSR)と機能分析(FA)のジョイントモデリングにDetection Transformer(DETR)モデルを活用しています。したがって、DETRモデルは、Microsoft Researchが開発したTable Transformerが実行されるバックボーンです。DETRについてもう少し詳しく見てみましょう。 DEtection TRansformer(DETR) 前述のように、DETRはDEtection TRansformerの略であり、エンコーダーデコーダートランスフォーマーを使用したResNetアーキテクチャなどの畳み込みバックボーンから構成されています。これにより、オブジェクト検出のタスクを実行する潜在能力を持っています。DETRは、領域提案、非最大値抑制、アンカー生成などの複雑なモデル(Faster…

組合せ最適化によるニューラルネットワークの剪定
Posted by Hussein Hazimeh、Athenaチームの研究科学者、およびMITの大学院生であるRiade Benbakiによる投稿 近代的なニューラルネットワークは、言語、数学的推論、ビジョンなど、さまざまなアプリケーションで印象的なパフォーマンスを達成しています。しかし、これらのネットワークはしばしば大規模なアーキテクチャを使用し、多くの計算リソースを必要とします。これにより、特にウェアラブルやスマートフォンなどのリソース制約のある環境では、このようなモデルをユーザーに提供することが実用的ではありません。事前学習済みネットワークの推論コストを軽減するための広く使用されている手法は、いくつかの重みを削除することによる枝刈りですが、これはネットワークの有用性にほとんど影響を与えない方法で行われます。標準的なニューラルネットワークでは、各重みは2つのニューロン間の接続を定義します。したがって、重みが剪定された後、入力はより小さな一連の接続を介して伝播し、より少ない計算リソースを必要とします。 元のネットワークと剪定されたネットワークの比較。 枝刈り手法は、ネットワークのトレーニングプロセスのさまざまな段階で適用できます。トレーニング後、トレーニング中、またはトレーニング前(つまり、重みの初期化直後)に適用できます。この投稿では、トレーニング後の設定に焦点を当てています。つまり、事前学習済みネットワークが与えられた場合、どの重みを剪定すべきかをどのように決定できるかという問題です。最も一般的な手法の1つは、マグニチュード剪定です。この手法では、最も小さい絶対値を持つ重みを削除します。効率的ではありますが、この手法は重みの削除がネットワークのパフォーマンスに与える影響を直接考慮しません。もう1つの一般的な手法は、最小化された損失関数に対する重みの影響度に基づいて重みを削除する最適化ベースの剪定です。概念的には魅力的ですが、既存の最適化ベースの手法の多くは、パフォーマンスと計算要件の間に深刻なトレードオフがあるようです。粗い近似を行う手法(例:対角ヘッシアン行列を仮定する)はスケーラブル性が高く、パフォーマンスは比較的低いです。一方、より少ない近似を行う手法はパフォーマンスが向上する傾向がありますが、スケーラブル性ははるかに低いようです。 「Fast as CHITA: Neural Network Pruning with Combinatorial Optimization」は、ICML 2023で発表された論文で、事前学習済みニューラルネットワークの剪定において、スケーラビリティとパフォーマンスのトレードオフを考慮した最適化ベースのアプローチを開発した方法について説明しています。CHITA(「Combinatorial Hessian-free Iterative Thresholding Algorithm」の略)は、高次元統計、組合せ最適化、およびニューラルネットワークの剪定など、いくつかの分野の進歩を活用しています。たとえば、CHITAはResNetの剪定において最先端の手法よりも20倍から1000倍高速であり、多くの設定で精度を10%以上向上させることができます。 貢献の概要 CHITAには、人気のある手法に比べて2つの注目すべき技術的改善点があります:…

「転移学習の非合理的な効果」
「複雑なディープラーニングニューラルネットワークのトレーニングには、計算効率の高さ、大規模なデータコーパスの利用可能性、およびより優れた特徴学習アーキテクチャが必要です」

このAI研究は、パーソン再識別に適したデータ拡張手法であるStrip-Cutmixを提案しています
コンピュータビジョンでは、個人再識別は現在の相互接続された世界における重要な追求です。これは、しばしば非理想的な状況で異なるカメラビュー間で個人を識別する困難なタスクを含みます。ただし、正確な再識別モデルを実現するには、多様なラベル付きデータが必要です。ここで、データ拡張の重要性が登場します。データ拡張技術は、利用可能なデータの質と量を向上させ、モデルが堅牢な特徴を学習し、さまざまなシナリオに適応できるようにします。 文献では、個人再識別のためにさまざまなデータ拡張手法が使用されています。これには、ランダムイレーシング、ランダム水平反転、遮蔽サンプル生成、異なる照明条件で仮想画像を作成する方法、さらには生成的対抗ネットワーク(GAN)を使用したアプローチなどが含まれます。ただし、高品質の画像を生成できるCutmixやmixupなどの手法は、個人再識別のトリプレットロスフレームワークに適応する上での課題があるため、ほとんど利用されていません。 最近、中国の研究チームが、Cutmixデータ拡張手法を個人再識別に組み込むための解決策を紹介する新しい論文を発表しました。著者たちは、一般的に使用されるトリプレットロスを拡張し、小数の類似度ラベルを処理することで、画像の類似度を最適化しました。彼らはまた、個人再識別に適したAugmentation技術であるStrip-Cutmixを提案し、その効果的な適用戦略を提供しました。 具体的には、この論文では、トリプレットロスとcutmixを調整することで、この課題に対処しています。Cutmixは、1つの画像の一部を別の画像に貼り付けて新しい画像を作成する手法です。一般的に使用されますが、cutmixが生成する小数の類似度ラベルとの非互換性のため、個人再識別ではほとんど使用されません。 これを解決するために、著者たちはトリプレットロスを修正し、小数の類似度ラベルを処理できるようにし、cutmixをトリプレットロスと併用できるようにしました。修正されたトリプレットロスは、目標の類似度に基づいて最適化方向を動的に調整します。また、トリプレットロスの意思決定条件も、目標の類似度ラベルと一致するように書き直されます。 具体的には、著者たちは小数の類似度ラベルを処理できるようにトリプレットロスを拡張し、再識別コンテキストでcutmixを利用できるようにしました。Cutmixは通常、画像の一部を切り取り、別の画像に貼り付けて新しい組み合わせ画像を作成します。しかし、個人再識別のメトリック学習において重要な役割を果たす元のトリプレットロスは、cutmixによって生成される小数の類似度ラベルに苦労します。 この課題を克服するために、著者たちはトリプレットロスの最適化方向を動的に修正し、小数のラベルを処理できるようにし、cutmixと元のトリプレットロスの両方と互換性のあるものにしました。さらに、彼らはStrip-Cutmixを導入しました。この手法は、画像を水平方向のブロックに分割し、個人の類似した特徴が画像間で対応する場所によく見られるという事実を活用しています。このアプローチにより、生成された画像の品質が向上し、トリプレットロスの境界条件も改善されます。Strip-Cutmixは、位置ベースのミキシングと画像ブロックを重視した標準的なcutmixとは異なり、組み合わせ画像間の類似度ラベルを取得することができます。 具体的な手法としては以下が含まれます: 小数ラベルを処理するためにトリプレットロスを修正すること。 Strip-Cutmix技術を導入すること。 トレーニング中にStrip-Cutmixを適用するための最適なスキームを決定すること。 提案手法の有効性を評価するために実験的な研究が行われました。実験はMarket-1501、DukeMTMC-ReID、MSMT17のデータセットで行われました。評価には平均平均適合率(mAP)と累積マッチング特性(CMC)が使用されました。 研究者たちはバックボーンとしてResNet-50を選択しました。結果は、提案手法が他の手法を上回り、ResNet-50およびRegNetY-1.6GFバックボーンで最高の結果を達成したことを示しています。また、この技術は過学習に対しても抵抗力を示し、最先端のパフォーマンスを達成しました。全体的に、この手法はデータセット全体で個人再識別タスクを向上させる一貫した優位性を示しました。 結論として、ここで紹介した論文は、cutmixデータ拡張技術を個人再識別に組み込むアプローチを紹介しています。個人再識別で使用される既存のトリプレットロスは、この新しい形式を処理するために拡張されました。さらに、個人再識別タスクに特化した新しい概念であるStrip-Cutmixが導入されました。Strip-Cutmixの最適な利用スキームを調査することで、著者たちは最も効果的なアプローチを特定しました。この提案手法は、純粋な畳み込みネットワークフレームワーク内で最適なパフォーマンスを提供する、他の畳み込みニューラルネットワークベースの個人再識別モデルを上回る結果をもたらします。

「医療分野における生成型AI」
はじめに 生成型人工知能は、ここ数年で急速に注目を集めています。医療と生成型人工知能の間に強い関係性が生まれていることは驚くことではありません。人工知能(AI)はさまざまな産業を急速に変革しており、医療分野も例外ではありません。AIの特定のサブセットである生成型人工知能は、医療分野において画期的な存在となっています。 生成型AIシステムは、新しいデータ、画像、さらには完全な芸術作品を生成することができます。医療分野では、この技術は診断、新薬の発見、患者ケア、医学研究の向上において非常に有望です。本記事では、医療分野における生成型人工知能の潜在的な応用と利点、実装上の課題、倫理的な考慮事項について探究します。 学習目標 GenAIとその医療分野への応用 GenAIの医療分野における潜在的な利点 医療分野における生成型AIの実装上の課題と制約 医療分野における生成型AIの将来的な展望 本記事は、Data Science Blogathonの一環として公開されました。 医療分野における生成型人工知能の潜在的な応用 医療分野において、GenAIをどのように活用できるかについて、いくつかの研究が行われています。GenAIは、新薬のための分子構造や化合物の生成に影響を与え、有望な薬剤候補の同定と発見を促進しています。これにより、先端技術を活用しながら時間とコストを節約することが可能です。以下は、これらの潜在的な応用の一部です: 医療画像および診断の向上 医療画像は、診断と治療計画において重要な役割を果たしています。生成型AIアルゴリズム(生成対抗的ネットワーク(GAN)や変分オートエンコーダー(VAE)など)は、医療画像解析を大幅に改善しています。これらのアルゴリズムは、実際の患者データに似た合成医療画像を生成することができ、機械学習モデルのトレーニングと検証に役立ちます。また、限られたデータセットを補完するために追加のサンプルを生成することで、画像に基づく診断の正確性と信頼性を向上させることもできます。 薬剤の発見と開発の促進 新薬の発見と開発は、複雑で時間がかかり、費用がかかる作業です。生成型AIは、所望の特性を持つ仮想化合物や分子を生成することで、このプロセスを大幅に加速することができます。研究者は、生成モデルを用いて広大な化学空間を探索し、新たな薬剤候補を同定することができます。これらのモデルは既存のデータセット(既知の薬剤構造と関連する特性を含む)から学習し、望ましい特性を持つ新しい分子を生成します。 個別化医療と治療 生成型AIは、患者データを活用して個別化された治療計画を作成することで、個別化医療を革新する潜在能力を持っています。電子健康記録、遺伝子プロファイル、臨床結果などの大量の患者情報を分析することにより、生成型AIモデルは個別化された治療の推奨を生成することができます。これらのモデルはパターンを特定し、病気の進行を予測し、介入に対する患者の反応を推定することができるため、医療提供者は情報に基づいた意思決定を行うことができます。 医学研究と知識生成 生成型AIモデルは、特定の特性と制約を満たす合成データを生成することで、医学研究を支援することができます。合成データは、機密性の高い患者情報の共有に関連するプライバシーの問題を解決しながら、研究者が有益な洞察を抽出し、新たな仮説を開発することができます。 また、生成型AIは臨床試験のための合成患者コホートを生成することもできます。これにより、研究者はさまざまなシナリオをシミュレートし、実際の患者に対する高価で時間のかかる試験を実施する前に治療の効果を評価することができます。この技術は、医学研究を加速し、イノベーションを推進し、複雑な疾患に対する理解を広げる可能性があります。 事例研究: CPPE-5…

大規模画像モデルのための最新のCNNカーネル
「OpenAIのChatGPTの驚異的な成功が大型言語モデルのブームを引き起こしたため、多くの人々が大型画像モデルにおける次のブレークスルーを予測していますこの領域では、ビジョンモデルは...」

「自己教師あり学習とトランスフォーマー? – DINO論文の解説」
「一部の人々は、Transformerのアーキテクチャを愛し、それをコンピュータビジョンの領域に歓迎しています他の人々は、新しいプレイグラウンドに新しい子供がいることを受け入れたくありません さて、何が起こるのか見てみましょう...」

「糖尿病網膜症の段階を予測して眼の盲目を防ぐ」
はじめに 糖尿病性網膜症は、網膜の血管に変化を引き起こす眼の状態です。無治療のまま放置すると、視力の喪失につながります。そのため、糖尿病性網膜症の段階を検出することは、目の失明を防ぐために重要です。このケーススタディは、糖尿病性網膜症の症状から目の失明を検出することについてのもので、データはさまざまな撮影条件で眼底カメラ(眼の後ろを写真に撮るカメラ)を使用して、さまざまな訓練された臨床専門家によって田舎の地域から収集されました。これらの写真は、2019年にKaggleが行ったコンペティション(APTOS 2019 Blindness Detection)で糖尿病性網膜症の段階を検出するために使用され、私たちのデータは同じKaggleのコンペティションから取得されました。この糖尿病性網膜症の早期検出は、治療を迅速化し、視力の喪失のリスクを大幅に減らすのに役立ちます。 訓練された臨床専門家の手作業による介入は、特に発展途上国では時間と労力がかかります。したがって、このケーススタディの主な目的は、効率的な技術を使用して状態の重症度を検出し、失明を防止することです。私たちは、深層学習の技術を実装して、状態の分類に効果的な結果を得るために取り組んでいます。 学習目標 糖尿病性網膜症の理解:眼の状態と視力への影響について学び、早期検出の重要性を強調します。 深層学習の基礎:深層学習の基礎を探求し、糖尿病性網膜症の診断における関連性を理解します。 データの前処理と拡張:ディープラーニングモデルのトレーニングのためにデータセットを効果的に準備し、強化する方法を理解します。 モデルの選択と評価:重症度分類のためのディープラーニングモデルの選択と性能評価の方法を学びます。 実用的な展開:Flaskを使用して最適なモデルの展開と実世界での予測を実現します。 この記事はデータサイエンスブログマラソンの一環として公開されました。 ビジネスの問題 ここでは、人の状態の重症度が5つのカテゴリに分類されます。つまり、人は重症度レベルのいずれか1つで認識されます。 ビジネスの制約事項 医療分野では正確性と解釈可能性が非常に重要です。間違った予測は人々の命を奪う可能性があるため、厳格なレイテンシの心配はありませんが、結果については正確でなければなりません。 データセットの説明 データセットには、訓練された臨床専門家が各画像を糖尿病性網膜症の重症度に基づいて以下のように分類した3,662枚のラベル付き網膜画像が含まれています。 0 — 糖尿病性網膜症なし 1 —…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.