Learn more about Search Results LSTM - Page 6

- You may be interested
- 大規模なネアデデュープリケーション:Big...
- なぜ私たちはHugging Face Inference Endp...
- サステイナブルな銀行業務のための生成AI ...
- ファイル管理の効率化:サーバーまたはサ...
- ゼロから学ぶアテンションモデル
- 「初心者のためのイメージ分類」
- Q-学習入門 第1部への紹介
- 業界の内部人がビッグテックのA.I.に対す...
- 「アメリカではデータサイエンティストの...
- 「WavJourneyをご紹介します:大規模な言...
- 「脳のように機能するコンピュータビジョ...
- Hugging Face TransformersとAWS Inferent...
- 10倍の生産性を向上させるためのTop 10 VS...
- 「データサイエンスにおけるデータベース...
- 2023年に就職するために持っているべきト...

TinyML アプリケーション、制限、およびIoT&エッジデバイスでの使用
過去数年間、人工知能(AI)と機械学習(ML)は、産業だけでなく学界でも人気と応用が急速に広まってきましたしかし、現在のMLとAIモデルには1つの大きな制限がありますそれは、望ましい結果を得るために膨大な計算と処理能力を必要とすることです[…]

「AIの問題を定義する方法」
「25年以上のソフトウェアエンジニアリングの経験を持っていますので、人工知能(AI)と機械学習を始めるソフトウェア開発者からの質問に多く答えてきました…」

「NLP入門コースでNLPを始めましょう」
新しいスキルを学ぶには、どんなに詳細なものであっても多くのことが必要です自然言語処理(NLP)を始める場合も例外ではありません機械学習、ディープラーニング、言語などに精通している必要があります特に、生成AIやプロンプトエンジニアリングの発展と共に...

「ディープラーニングの解説:ニューラルネットワークへの学生の入門」
ディープラーニングは、現代の時代において最も影響力のある技術の一つとして急速に進化しています音声認識アシスタントから医療画像解析まで、その応用はさまざまな産業において持つ広範な能力と潜在力を示していますこの記事の本質は、ディープラーニングの複雑に見える世界を分かりやすい部分に分解することです... ディープラーニングの謎を解く:ニューラルネットワークへの学生の入門 詳細を読む »
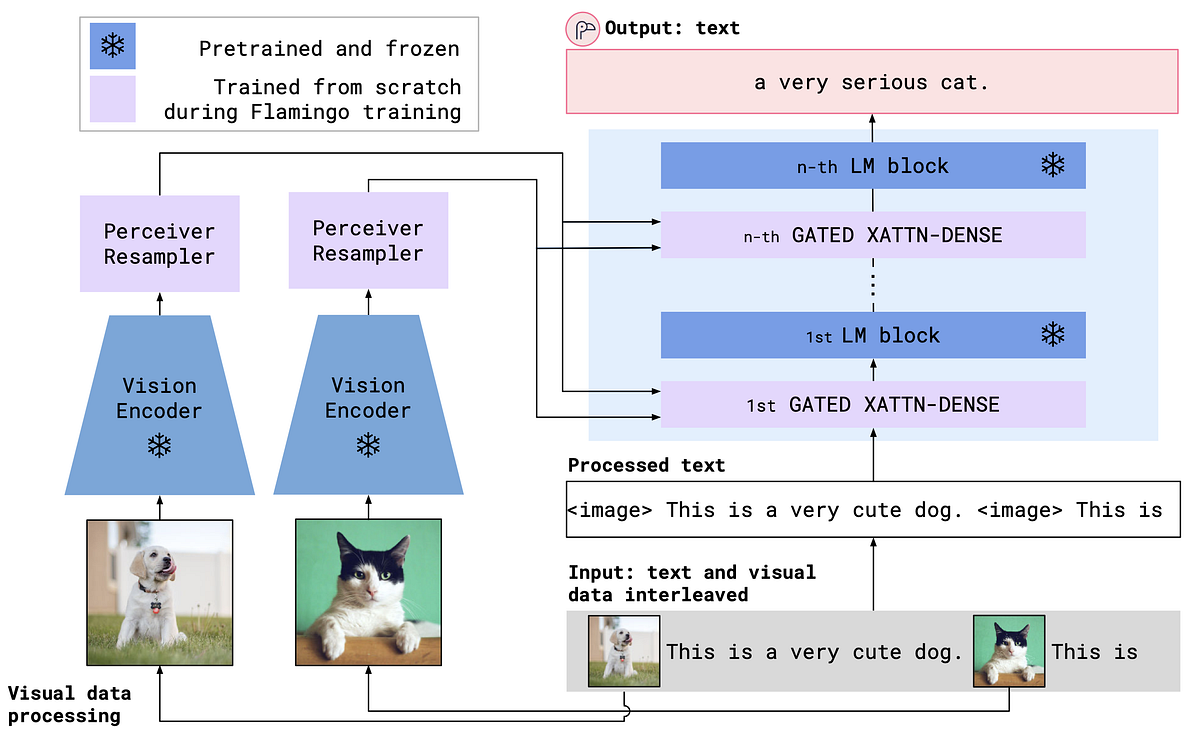
マルチモーダル言語モデルの解説:ビジュアル指示の調整
「LLMは、多くの自然言語タスクでゼロショット学習とフューショット学習の両方で有望な結果を示していますしかし、LLMは視覚的な推論を必要とするタスクにおいては不利です...」

音楽作曲における創造的なジェネレーティブAIの交響曲
はじめに 生成型AIは、教科書、画像、音楽などの新しいデータを生成できる人工知能です。音楽作曲では、生成型AIは作曲家に新しい鳴き声、チャイム、小節、さらには完全な曲を生成する力を与えます。この技術は、既に一部のアーティストやミュージシャンが新しい革新的な作品を生み出すために使用しており、音楽の創造方法を革命化する可能性があります。音楽作曲における生成型AIの使用方法には、主に2つのアプローチがあります。 1つのアプローチは、大規模な音楽データセットでAIアルゴリズムをトレーニングすることです。アルゴリズムは音楽のパターンと構造を学習し、この知識を活用してトレーニングデータに似た新しい音楽を生成します。もう1つのアプローチは、音楽に基づかない新しい音楽のアイデアをAIを使って生成することです。これは、AIを使って任意の音符のシーケンスを誘導するか、AIを使って可能な音楽の組み合わせの空間を探索することによって行われます。 学習目標 生成型AIについて学び、音楽の作曲方法にどのように変革をもたらしているかを理解する。 音楽の創作における生成型AIの多くの利点について知る。これには音楽のインスピレーションからカスタマイズされた制作までが含まれる。 AIが生成した音楽を芸術の領域に取り入れる際に発生する困難や倫理的な問題について検討する。 現在の音楽制作における生成型AIの使用方法と、将来の可能性について学ぶ。 この記事はData Science Blogathonの一部として公開されました。 生成型AIの理解 人工知能は、現代の機械学習アルゴリズムを使用して独自の音楽作品を作成するため、音楽作曲を根本的に変革します。大規模なデータセットを学習し、音楽の重要な要素を文書化することによって、これらのモデルは芸術的な表現と一貫性を持つメロディ、リズム、ハーモニーを作成することができます。これにより、作曲家は新しい可能性を研究し、音楽の分野で創造力を発揮するための新しいアイデアを得ることができます。 このGenAIモデルを音楽作曲に適用するには、RNN、Variational Autoencoders(VAEs)、またはTransformersなどの高度な機械学習アルゴリズムが必要です。これらのアルゴリズムはこのモデルの基盤となります。モデルが学習したデータに基づいて音楽を認識し、作成するために、音楽作曲家や開発者はPyTorchやTensorFlowなどの機械学習のサブストラクチャを利用して構築し、教えます。さまざまなネットワークアーキテクチャ、トレーニング技術、ハイパーパラメータを試し、作成される音楽の品質と革新を最大化するためにテストします。 音楽作曲のためのAIモデルのトレーニングには、さまざまな音楽ジャンルやスタイルなど、幅広いデータの提示が含まれます。モデルは入力データから学習したパターンから必要なデータを選択して自身の作品を作成します。これにより、オリジナルでユニークな出力が得られ、観客を魅了することができます。 音楽作曲における生成型AIの利点 生成型AIモデルは、高度な機械学習アルゴリズムと豊富な音楽ノートのデータセットを使用して音楽作品の増加とモチベーションを提供します。 以下は、このモデルのいくつかの利点です: インスピレーションと革新 このAIモデルは、音楽作曲家に新しいアイデアの源を提供し、音楽の創作において広範で新しいアイデアを提供します。さまざまな音楽の種類やスタイルを理解することにより、生成型AIモデルは将来の音楽作曲家に脅威となるユニークなバリエーションや組み合わせを作成することができます。この革新とインスピレーションにより、創造プロセスが活性化され、新しいコンセプトと音楽の領域の開発が促進されます。作曲家は新しい音楽の領域を学び、以前に考えたことのない遊び心のある音楽、ハーモニー、曲の試行錯誤を行うことができます。 このモデルが新しい音楽の作成のための新しいアイデアを生み出す能力により、創造力の大きな障壁が取り除かれ、音楽作曲家が助けられます。このインスピレーションと革新は、作曲家の創造性を高めるだけでなく、作曲家が自身の創造的な限界を探求し、音楽業界や世界の向上に貢献する機会を提供します。 効率と時間の節約 このモデルの使用により、時間の節約能力によって音楽の作曲の視点が変わりました。高度な機械学習アルゴリズムと豊富な音楽データセットを使用することで、このモデルは短時間で多くの音符、曲、バリエーションを素早く生成することができます。これにより、音楽作曲家は最初から始める必要がなくなり、新しい音楽の創造を加速するのに役立ちます。…
Mozilla Common Voiceでの音声言語認識-第II部:モデル
これはMozilla Common Voiceデータセットに基づく音声認識に関する2番目の記事です最初の部分ではデータの選択と最適な埋め込みの選択について議論しましたさて、いくつかのトレーニングを行いましょう...

このAI論文は、大規模なビジョン・ランゲージ・ナビゲーション(VLN)トレーニングのための効果的なパラダイムを提案し、パイプライン内の各コンポーネントの影響を定量的に評価しています
ビジュアルナビゲーションの学習のために、いくつかの人間のデモが収集され、最近の巨大なデータセットには数百の対話的なシナリオが含まれており、エージェントのパフォーマンスの大幅な改善につながっています。ただし、このような大規模なトレーニングを行うには、ナビゲーショングラフの構築方法、破損したレンダリングされた画像の復元方法、およびナビゲーション指示の生成方法など、いくつかの重要なサブ問題を解決する必要があります。これらすべてが収集されたデータの品質に大きな影響を与えるため、徹底的に探求されるべきです。 大規模なデータを効率的に活用し、ナビゲーションエージェントのトレーニングに適切に利益をもたらす方法を研究することが必要であり、人間の自然言語を理解し、写真のような環境でナビゲーションすることができるエージェントは、洗練されたモジュール化されたシステムです。 オーストラリア国立大学、OpenGVLab、上海AI研究所、UNCチャペルヒル、アデレード大学、Adobe Researchの研究者たちは、大規模なビジョンと言語のナビゲーションネットワーク(VLN)をトレーニングするために、パイプライン内の各コンポーネントの影響を統計的に評価する新しいパラダイムを提供しています。彼らはHabitatシミュレータを使用して、HM3DとGibsonのデータセットから環境を使用し、環境のためのナビゲーショングラフを構築します。彼らは新しい軌跡をサンプリングし、指示を作成し、エージェントをトレーニングして下流のナビゲーション問題を解決します。 AutoVLNやMARVALなどの従来の方法とは異なり、これらのナビゲーショングラフは、過剰な視点サンプリングと集約手法を使用して構築され、導入されたグラフ作成ヒューリスティックを使用しています。このアプローチにより、広範な屋外カバレッジを持つ完全に接続されたネットワークが得られます。 研究者たちはまた、HM3DとGibsonの設定から生成された破損した生成画像から、壊れた、変形した、または欠落した部分の写真のような画像を生成するために、Co-Modulated GANをトレーニングします。これにより、視覚データのノイズの影響を軽減することができます。MARVALとは異なり、この大規模なトレーニング体制は完全に再現可能で実行が容易であり、エージェントのパフォーマンスを大幅に向上させます。 包括的な実験により、エージェントがR2Rなどの特定の指示に基づいて下流のタスクでより良いパフォーマンスを発揮するためには、ナビゲーショングラフが完全にトラバーサブルである必要があります。さらに、Gibsonの環境からの低品質な3Dスキャンに対して生成された画像から写真のような画像を復元する利点も示されています。研究結果は、エージェントが一般的により多様な視覚データを使用でき、新しいシーンから学習することにより新しいコンテキストへの一般化を向上させることができることを示しています。 さらに、チームは、基本的なLSTMベースのモデルによって提供される拡張指示を使用してトレーニングされたエージェントがさまざまなナビゲーションタスクでうまく機能することを検証しました。彼らは、拡張データを元のデータと統合し、事前トレーニングと微調整中にエージェントの一般化能力を向上させることができると結論付けています。 驚くべきことに、データ拡張やエージェントのトレーニングのための上記の分析をガイドとして使用することで、提案されたVLNモデルは、先行探索、ビームサーチ、またはモデルのアンサンブルなしで単純な模倣学習によってR2Rテスト分割で80%の成功率を達成し、見たことのない環境とのナビゲーションギャップを解消します。この結果は、以前の最良の手法(73%)と比べて、パフォーマンスの差を人間のレベルに約6パーセントポイントまで縮める大幅な改善です。CVDNやREVERIEなどのいくつかの言語によるビジュアルナビゲーションの課題へのアプローチは、最先端を前進させました。強化されたデータは離散的であるにもかかわらず、連続的な環境(R2R-CE)においてVLNのパフォーマンスが5%成功率向上していることも示しています。
モジラのコモンボイスでの音声言語認識 — Part I.
「話者の言語を特定することは、後続の音声テキスト変換のために最も困難なAIのタスクの一つですこの問題は、例えば人々が住んでいる場所で発生することがあります...」
「ゲート付き再帰型ユニット(GRU)の詳細な解説:RNNの数学的背後理論の理解」
この記事では、ゲート付き再帰ユニット(GRU)の動作について説明しますGRUは、長期短期記憶(LSTM)の事前知識があれば簡単に理解できるため、強くおすすめします...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.