Learn more about Search Results Gin - Page 6

- You may be interested
- Pythonコードの行数を100行未満で使用した...
- 3Dインスタンスセグメンテーションにおけ...
- 「プロジェクトRumiにご参加ください:大...
- 「MicrosoftがExcelにPythonを導入:分析...
- JavaScriptを使用してOracleデータベース...
- Amazon SageMaker 上で MPT-7B を微調整する
- アイドルアプリの自動シャットダウンを使...
- リシ・スナック、新しいグローバルAI安全...
- Pythonでトレーニング済みモデルを保存す...
- Android 14:より多様なカスタマイズ、制...
- 「2024年に成功したデータサイエンティス...
- FastAPIとDockerを使用してPyTorchモデル...
- 「Adversarial Autoencoders オートエンコ...
- 合成データとは何ですか?
- KAISTのAI研究者が、「KTRL+F」という技術...

「Hugging Faceを使用してLLMsを使ったテキスト要約機を構築する」
はじめに 最近、LLMs(Large Language Models)を使用したテキスト要約は多くの関心を集めています。これらのモデルは、GPT-3やT5などの事前訓練モデルであり、人間のようなテキストやテキスト分類、要約、翻訳などのタスクを生成することができます。Hugging Faceは、LLMsを使用するための人気のあるライブラリの一つです。 この記事では、特にHugging Faceに焦点を当てて、LLMの能力について検討し、難解なNLPの問題を解決するための適用方法について説明します。また、Hugging FaceとLLMsを使用して、Streamlit用のテキスト要約アプリケーションを構築する方法についても説明します。まずは、この記事の学習目標について見てみましょう。 学習目標 Hugging Faceをプラットフォームとして使用したLLMsとTransformersの機能と機能を探索する。 Hugging Faceが提供する事前訓練モデルとパイプラインを活用して、チャットボットなどのさまざまなNLPタスクを実行する方法を学ぶ。 Hugging FaceとLLMsを使用したテキスト要約の実践的な理解を開発する。 テキスト要約のための対話型Streamlitアプリケーションを作成する。 この記事は、データサイエンスのブログマラソンの一環として公開されました。 大規模言語モデル(LLMs)の理解 LLMモデルは大量のテキストデータで訓練されます。これらのモデルは、前の文脈に基づいて次の単語を予測することにより、複雑な言語パターンを捉え、一貫したテキストを生成することができます。 LLMsは大量のパラメータを含むデータセットで訓練されます。訓練データの膨大な量により、LLMsは言語の微妙なニュアンスを学び、印象的な言語生成能力を提供することができます。 LLMsは機械翻訳、テキスト生成、質問応答、感情分析などのさまざまなタスクでの突破口を可能にし、NLPの分野に大きな影響を与えました。 これらのモデルはベンチマークで優れたパフォーマンスを発揮し、多くのNLPタスクにおいて頼りになるツールとなっています。 Hugging Face…

「Llama 2が登場しました – Hugging Faceで手に入れましょう」
はじめに Llama 2は、Metaが本日リリースした最新のオープンアクセスの大規模言語モデルのファミリーです。私たちはHugging Faceとの包括的な統合を完全にサポートすることで、このリリースを支援しています。Llama 2は非常に寛容なコミュニティライセンスでリリースされ、商業利用も可能です。コード、事前学習モデル、ファインチューニングモデルはすべて本日リリースされます🔥 私たちはMetaとの協力により、Hugging Faceエコシステムへのスムーズな統合を実現しています。Hubで12のオープンアクセスモデル(3つのベースモデルと3つのファインチューニングモデル、オリジナルのMetaチェックポイントを含む)を見つけることができます。リリースされる機能と統合の中には、以下のものがあります: モデルカードとライセンスを備えたHub上のモデル。 Transformersの統合 単一のGPUを使用してモデルの小さなバリアントをファインチューニングするための例 高速かつ効率的なプロダクションレディの推論のためのテキスト生成インファレンスとの統合 インファレンスエンドポイントとの統合 目次 Llama 2を選ぶ理由 デモ インファレンス Transformersを使用する場合 インファレンスエンドポイントを使用する場合 PEFTによるファインチューニング 追加リソース 結論 Llama 2を選ぶ理由…

「Hugging Faceにおけるオープンソースのテキスト生成とLLMエコシステム」
テキスト生成と対話技術は古くから存在しています。これらの技術に取り組む上での以前の課題は、推論パラメータと識別的なバイアスを通じてテキストの一貫性と多様性を制御することでした。より一貫性のある出力は創造性が低く、元のトレーニングデータに近く、人間らしさに欠けるものでした。最近の開発により、これらの課題が克服され、使いやすいUIにより、誰もがこれらのモデルを試すことができるようになりました。ChatGPTのようなサービスは、最近GPT-4のような強力なモデルや、LLaMAのようなオープンソースの代替品が一般化するきっかけとなりました。私たちはこれらの技術が長い間存在し、ますます日常の製品に統合されていくと考えています。 この投稿は以下のセクションに分かれています: テキスト生成の概要 ライセンス Hugging FaceエコシステムのLLMサービス用ツール パラメータ効率の良いファインチューニング(PEFT) テキスト生成の概要 テキスト生成モデルは、不完全なテキストを完成させるための目的で訓練されるか、与えられた指示や質問に応じてテキストを生成するために訓練されます。不完全なテキストを完成させるモデルは因果関係言語モデルと呼ばれ、有名な例としてOpenAIのGPT-3やMeta AIのLLaMAがあります。 次に進む前に知っておく必要がある概念はファインチューニングです。これは非常に大きなモデルを取り、このベースモデルに含まれる知識を別のユースケース(下流タスクと呼ばれます)に転送するプロセスです。これらのタスクは指示の形で提供されることがあります。モデルのサイズが大きくなると、事前トレーニングデータに存在しない指示にも一般化できるようになりますが、ファインチューニング中に学習されたものです。 因果関係言語モデルは、人間のフィードバックに基づいた強化学習(RLHF)と呼ばれるプロセスを使って適応されます。この最適化は、テキストの自然さと一貫性に関して行われますが、回答の妥当性に関しては行われません。RLHFの仕組みの詳細については、このブログ投稿の範囲外ですが、こちらでより詳しい情報を見つけることができます。 例えば、GPT-3は因果関係言語のベースモデルですが、ChatGPTのバックエンドのモデル(GPTシリーズのモデルのUI)は、会話や指示から成るプロンプトでRLHFを用いてファインチューニングされます。これらのモデル間には重要な違いがあります。 Hugging Face Hubでは、因果関係言語モデルと指示にファインチューニングされた因果関係言語モデルの両方を見つけることができます(このブログ投稿で後でリンクを提供します)。LLaMAは最初のオープンソースLLMの1つであり、クローズドソースのモデルと同等以上の性能を発揮しました。Togetherに率いられた研究グループがLLaMAのデータセットの再現であるRed Pajamaを作成し、LLMおよび指示にファインチューニングされたモデルを訓練しました。詳細についてはこちらをご覧ください。また、Hugging Face Hubでモデルのチェックポイントを見つけることができます。このブログ投稿が書かれた時点では、オープンソースのライセンスを持つ最大の因果関係言語モデルは、MosaicMLのMPT-30B、SalesforceのXGen、TII UAEのFalconの3つです。 テキスト生成モデルの2番目のタイプは、一般的にテキスト対テキスト生成モデルと呼ばれます。これらのモデルは、質問と回答または指示と応答などのテキストのペアで訓練されます。最も人気のあるものはT5とBARTです(ただし、現時点では最先端ではありません)。Googleは最近、FLAN-T5シリーズのモデルをリリースしました。FLANは指示にファインチューニングするために開発された最新の技術であり、FLAN-T5はFLANを使用してファインチューニングされたT5です。現時点では、FLAN-T5シリーズのモデルが最先端であり、オープンソースでHugging Face Hubで利用可能です。入力と出力の形式は似ているかもしれませんが、これらは指示にファインチューニングされた因果関係言語モデルとは異なります。以下は、これらのモデルがどのように機能するかのイラストです。 より多様なオープンソースのテキスト生成モデルを持つことで、企業はデータをプライベートに保ち、ドメインに応じてモデルを適応させ、有料のクローズドAPIに頼る代わりに推論のコストを削減することができます。Hugging…

「HuggingFace Transformers ツールとエージェント:ハンズオン」
Transformersバージョンv4.29.0は、ツールとエージェントのコンセプトを基に構築され、transformersの上に自然言語APIを提供しますそれらの使い方は?言語学習を目的として詳しく調べてみましょう…

Hugging Face Transformersでより高速なTensorFlowモデル
ここ数か月、Hugging FaceチームはTransformersのTensorFlowモデルの改良に取り組んできました。目標はより堅牢で高速なモデルを実現することです。最近の改良は主に次の2つの側面に焦点を当てています: 計算パフォーマンス:BERT、RoBERTa、ELECTRA、MPNetの計算時間を大幅に短縮するための改良が行われました。この計算パフォーマンスの向上は、グラフ/イージャーモード、TF Serving、CPU/GPU/TPUデバイスのすべての計算アスペクトで顕著に見られます。 TensorFlow Serving:これらのTensorFlowモデルは、TensorFlow Servingを使用して展開することができ、推論においてこの計算パフォーマンスの向上を享受することができます。 計算パフォーマンス 計算パフォーマンスの向上を実証するために、v4.2.0のTensorFlow ServingとGoogleの公式実装との間でBERTのパフォーマンスを比較するベンチマークを実施しました。このベンチマークは、GPU V100上でシーケンス長128を使用して実行されました(時間はミリ秒単位で表示されます): v4.2.0の現行のBertの実装は、Googleの実装よりも最大で約10%高速です。また、4.1.1リリースの実装よりも2倍高速です。 TensorFlow Serving 前のセクションでは、Transformersの最新バージョンでブランドニューのBertモデルが計算パフォーマンスが劇的に向上したことを示しました。このセクションでは、製品環境で計算パフォーマンスの向上を活用するために、TensorFlow Servingを使用してBertモデルを展開する手順をステップバイステップで説明します。 TensorFlow Servingとは何ですか? TensorFlow Servingは、モデルをサーバーに展開するタスクをこれまで以上に簡単にするTensorFlow Extended(TFX)が提供するツールの一部です。TensorFlow Servingには、HTTPリクエストを使用して呼び出すことができるAPIと、サーバー上で推論を実行するためにgRPCを使用するAPIの2つがあります。 SavedModelとは何ですか? SavedModelには、ウェイトとアーキテクチャを含むスタンドアロンのTensorFlowモデルが含まれています。SavedModelは、モデルの元のソースを実行する必要がないため、Java、Go、C++、JavaScriptなどのSavedModelを読み込むバックエンドをサポートするすべてのバックエンドと共有または展開するために役立ちます。SavedModelの内部構造は次のように表されます:…

PyTorch / XLA TPUsでのHugging Face
お気に入りのトランスフォーマーをPyTorch / XLAを使用してCloud TPUsでトレーニングする PyTorch-TPUプロジェクトは、Facebook PyTorchチームとGoogle TPUチームの共同作業として始まり、2019年のPyTorch Developer Conference 2019で正式に開始されました。それ以来、私たちはHugging Faceチームと協力して、PyTorch / XLAを使用してCloud TPUsでトレーニングをサポートするための一流のサポートを提供してきました。この新しい統合により、PyTorchユーザーはHugging Faceトレーナーインターフェースをそのまま維持しながら、Cloud TPUs上でモデルを実行しスケーリングすることができます。 このブログ記事では、Hugging Faceライブラリで行われた変更の概要、PyTorch / XLAライブラリの機能、Cloud TPUsでお気に入りのトランスフォーマーをトレーニングするための例、およびいくつかのパフォーマンスベンチマークについて説明します。TPUsで始めるのが待ちきれない場合は、「Cloud TPUsでトランスフォーマーをトレーニングする」セクションにスキップしてください – 私たちはTrainerモジュール内でPyTorch…
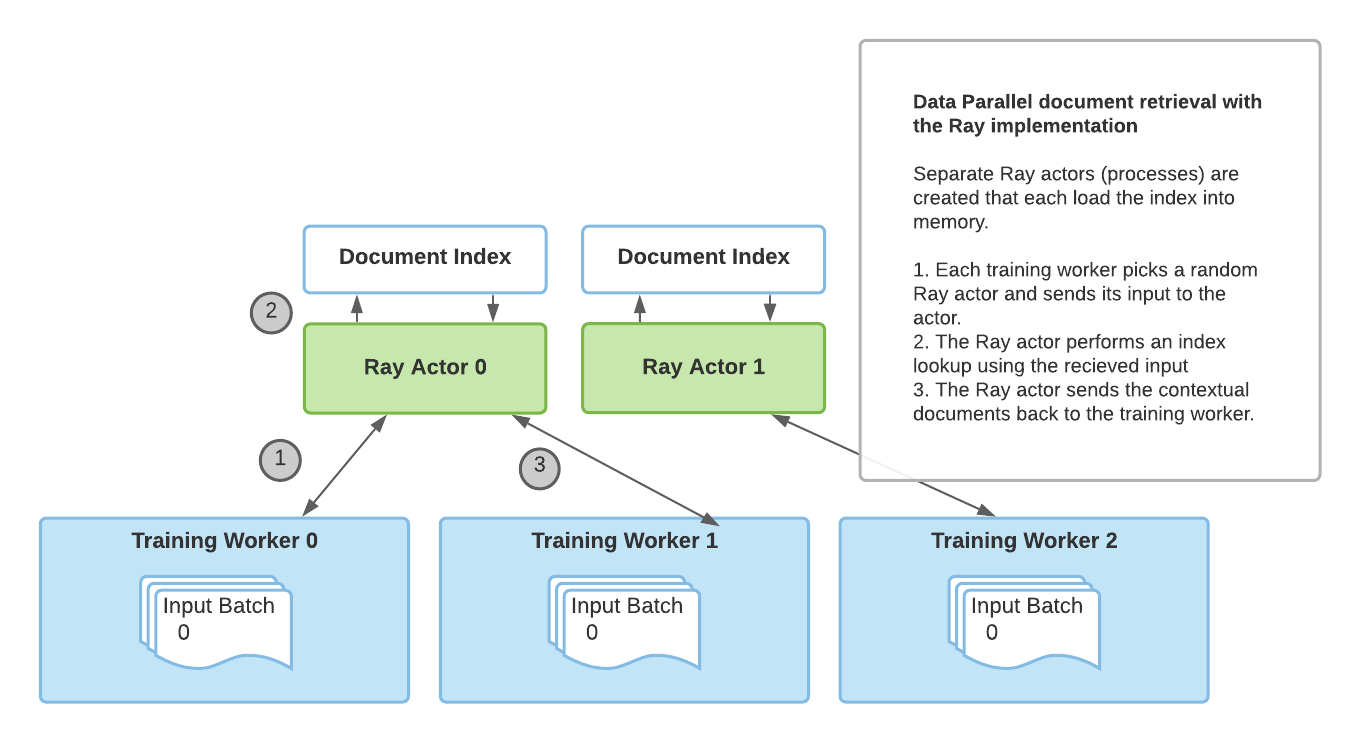
Huggingface TransformersとRayを使用した検索増強生成
アノスケールのチームからのゲストブログ投稿:Amog Kamsetty氏 Huggingface Transformersは最近、Retrieval Augmented Generation(RAG)モデルを追加しました。これは、外部のドキュメント(ウィキペディアなど)を活用して知識を拡充し、知識集約的なタスクで最先端の結果を実現する新しいNLPアーキテクチャです。このブログ投稿では、スケーラブルなアプリケーションを構築するためのライブラリであるRayをRAGの文脈におけるドキュメント検索メカニズムに統合する方法を紹介します。これにより、検索呼び出しの速度が2倍に向上し、RAGの分散ファインチューニングのスケーラビリティが向上します。 Retrieval Augmented Generation(RAG)とは何ですか? RAGの概要です。モデルは外部のデータセットから文脈ドキュメントを取得し、実行の一環として使用します。これらの文脈ドキュメントは元の入力と組み合わせて出力を生成するために使用されます。このGIFはFacebookのオリジナルのブログ投稿から取得されました。 最近、HuggingfaceはFacebook AIと提携して、RAGモデルをTransformersライブラリの一部として導入しました。 RAGは他のseq2seqモデルと同様に機能しますが、外部の知識ベース(ウィキペディアのテキストコーパスなど)から文脈ドキュメントを取得する中間コンポーネントを持っています。これらのドキュメントは入力シーケンスと組み合わせて基礎となるseq2seqジェネレータに渡されます。 この情報検索ステップにより、RAGはモデルパラメータに埋め込まれた知識と文脈のパッセージに含まれる情報という複数の知識源を活用することができます。これにより、質問応答などのタスクで他の最先端モデルを上回るパフォーマンスを発揮します。Huggingfaceが提供するデモを使用して、自分自身で試すこともできます。 ファインチューニングのスケーリング これらの文脈ドキュメントの取得は、RAGの最先端の結果にとって重要ですが、追加の複雑さをもたらします。データ並列トレーニングルーチンを介してトレーニングプロセスをスケーリングアップする際、ドキュメントの検索の単純な実装はトレーニングのボトルネックになることがあります。さらに、検索コンポーネントで使用されるドキュメントインデックスは非常に大きいため、各トレーニングワーカーが自分自身の複製されたインデックスを読み込むことは不可能です。 以前のRAGファインチューニングの実装では、torch.distributed通信パッケージを使用してドキュメント検索部分を活用していました。しかし、この実装は柔軟性に欠け、スケーラビリティに制約がありました。 その代わりに、フレームワークに依存しないアドホックな並行プログラミングのためのより柔軟な実装が必要です。それには、Rayが完璧に適しています。Rayは一般的な分散および並列プログラミングのためのシンプルで強力なPythonライブラリです。Rayを使用して分散ドキュメント検索を行うことで、torch.distributedに比べて検索呼び出しごとに2倍の高速化と、ファインチューニングのスケーラビリティの向上を実現しました。 ドキュメント検索のためのRay torch.distributedの実装によるドキュメント検索 torch.distributedを使用したドキュメント検索の主な欠点は、トレーニングに使用されるプロセスグループに依存していて、ランク0のトレーニングワーカーのみがインデックスをメモリに読み込んでいたことです。 その結果、この実装にはいくつかの制限がありました: 同期のボトルネック:ランク0のワーカーはすべてのワーカーから入力を受け取り、インデックスクエリを実行し、その結果を他のワーカーに送信する必要がありました。これにより、複数のトレーニングワーカーでのパフォーマンスが制限されました。 PyTorch固有の:ドキュメント検索プロセスグループはトレーニングに使用される既存のプロセスグループに依存する必要があり、トレーニングにはPyTorchを使用する必要がありました。…
Hugging Faceを使用してWav2Vec2を英語音声認識のために微調整する
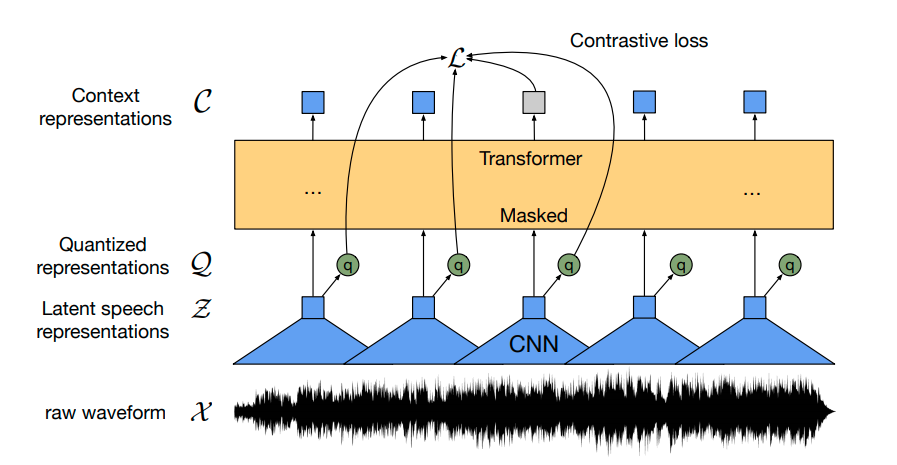
Wav2Vec2は、自動音声認識(ASR)のための事前学習済みモデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。 Wav2Vec2は、革新的な対比的事前学習目標を使用して、50,000時間以上の未ラベル音声から強力な音声表現を学習します。BERTのマスクされた言語モデリングと同様に、モデルはトランスフォーマーネットワークに渡す前に特徴ベクトルをランダムにマスクすることで、文脈化された音声表現を学習します。 初めて、事前学習に続いてわずかなラベル付き音声データで微調整することで、最先端のASRシステムと競合する結果が得られることが示されました。Wav2Vec2は、わずか10分のラベル付きデータを使用しても、LibriSpeechのクリーンテストセットで5%未満の単語エラーレート(WER)を実現します – 論文の表9を参照してください。 このノートブックでは、Wav2Vec2の事前学習チェックポイントをどの英語のASRデータセットでも微調整する方法について詳しく説明します。このノートブックでは、言語モデルを使用せずにWav2Vec2を微調整します。言語モデルを使用しないWav2Vec2は、エンドツーエンドのASRシステムとして非常にシンプルであり、スタンドアロンのWav2Vec2音響モデルでも印象的な結果が得られることが示されています。デモンストレーションの目的で、わずか5時間のトレーニングデータしか含まれていないTimitデータセットで「base」サイズの事前学習チェックポイントを微調整します。 Wav2Vec2は、コネクショニスト時系列分類(CTC)を使用して微調整されます。CTCは、シーケンス対シーケンスの問題に対してニューラルネットワークを訓練するために使用されるアルゴリズムであり、主に自動音声認識および筆記認識に使用されます。 Awni Hannunによる非常にわかりやすいブログ記事Sequence Modeling with CTC(2017)を読むことを強くお勧めします。 始める前に、datasetsとtransformersを最新バージョンからインストールすることを強くお勧めします。また、オーディオファイルを読み込むためにsoundfileパッケージと、単語エラーレート(WER)メトリックを使用して微調整モデルを評価するためにjiwerが必要です1 {}^1 1 。 !pip install datasets>=1.18.3 !pip install…

パートナーシップ:Amazon SageMakerとHugging Face
この笑顔をご覧ください! 本日、私たちはHugging FaceとAmazonの戦略的パートナーシップを発表しました。これにより、企業が最先端の機械学習モデルを活用し、最新の自然言語処理(NLP)機能をより迅速に提供できるようになります。 このパートナーシップを通じて、Hugging Faceはお客様にサービスを提供するためにAmazon Web Servicesを優先的なクラウドプロバイダーとして活用しています。 共通のお客様に利用していただくための第一歩として、Hugging FaceとAmazonは新しいHugging Face Deep Learning Containers(DLC)を導入し、Amazon SageMakerでHugging Face Transformerモデルのトレーニングをさらに簡単にする予定です。 Amazon SageMaker Python SDKを使用して新しいHugging Face DLCにアクセスし、使用する方法については、以下のガイドとリソースをご覧ください。 2021年7月8日、私たちはAmazon SageMakerの統合を拡張し、Transformerモデルの簡単なデプロイと推論を追加しました。Hugging…

Hugging FaceモデルをGradio 2.0で使用して混在させる
Gradioブログからの転載。 Hugging Face Model Hubには、ユーザーによって提出された10,000以上の機械学習モデルがあります。フィンランド語と英語の翻訳や中国語の音声認識など、あらゆる種類の自然言語処理モデルが見つかります。最近では、ハブは画像分類や音声処理のためのモデルも含めるように拡大しました。 Hugging Faceは常にモデルをアクセス可能で使いやすくすることに取り組んできました。 transformersライブラリを使用すると、わずか数行のコードでモデルを読み込むことができます。モデルを読み込んだ後、新しいデータに対してプログラム上で予測を行うことができます。しかし、機械学習モデルを使用しているのはプログラマーだけではありません!機械学習におけるますます一般的なシナリオは、異分野のチームにモデルをデモすることや、非プログラマーがモデルを使用すること(バイアスや不具合箇所の発見などのため)です。 Gradioライブラリを使用すると、機械学習開発者は機械学習モデルから簡単にデモやGUIを作成し、Googleドキュメントのリンクを共有するのと同じくらい簡単に共有することができます。そして、Gradio 2.0ライブラリを使用すると、たった1行のコードでほぼどんなHugging FaceモデルでもGUIをロードして使用することができます。以下に例を示します: デフォルトでは、これはHuggingFaceのホステッド推論APIを使用します(独自のAPIキーを提供するか、APIキーなしでパブリックアクセスを使用できます)。また、pip install transformersを実行してモデルの計算をローカルで実行することもできます。 デモをカスタマイズしたいですか?Interfaceクラスのデフォルトパラメータをオーバーライドすることができます。 しかし、まだまだあります!Model Hubには既に10,000以上のモデルがありますが、それらは単体のコードとしてではなく、より洗練されたアプリケーションやデモを作成するためのレゴブロックのようなものと見なしています。 例えば、Gradioを使用すると複数のモデルを並列に読み込むことができます(Hugging Faceの4つの異なるテキスト生成モデルを比較して、使用ケースに最適なモデルを見つけたい場合などを想像してください): また、モデルを直列に配置することもできます。これにより、複数の機械学習モデルから構築された複雑なアプリケーションを簡単に構築することができます。例えば、次のようなアプリケーションを3行のコードで作成することができます:フィンランドのニュース記事を翻訳して要約するアプリケーションです。 さらに、複数のモデルを並列に比較しながらシリーズに混ぜることもできます(ぜひ試してみてください!)。これらのいずれかを試すには、Gradioをインストール(pip install gradio)し、試したいHugging Faceモデルを選択してください。GradioとHugging…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.