Learn more about Search Results Databricks - Page 6

- You may be interested
- 🤗 Transformersを使用して、Wav2Vec2を使...
- Twitter用の15の最高のChatGPTプロンプト...
- Amazon SageMaker 上で MPT-7B を微調整する
- OpenAIのChatGPTが音声と画像の機能を発表...
- リトリーバル・オーグメンテッド・ジェネ...
- 暗号学のゴシップ パート1と2
- 「二つの封筒の問題」
- メトリクス層:すべてのKPI定義の唯一の真...
- 「TransformersとTokenizersを使用して、...
- 「事前学習済みのテキストからイメージへ...
- 「Llama 2によるトピックモデリング」
- 「Excelにおける金融関数の包括的なガイド」
- デジタルルネッサンス:NVIDIAのNeuralang...
- 「🤗 Transformersを使用してBarkを最適化...
- 「ベストのTableauコース(2023年)」

MailchimpにおけるMLプラットフォーム構築の教訓
この記事はもともと、「MLプラットフォームポッドキャスト」という番組のエピソードでしたこの番組では、ピオトル・ニェジヴィエツとアウリマス・グリチューナスが、MLプラットフォームの専門家たちと一緒に、設計の選択肢、ベストプラクティス、サンプルのツールスタック、そして最高のMLプラットフォームの専門家たちからの実際の学びを話し合っていますこのエピソードでは、ミキコ・バゼリーがMLの構築から学んだことを共有します...

「フィーチャー/トレーニング/推論パイプラインによってバッチとMLシステムを統一する」
「データMLプロダクトチームのための新しいMLOpsの方法」

「データの成熟度ピラミッド:レポートから先進的なインテリジェントデータプラットフォームへ」
この記事では、データの成熟度ピラミッドとそのさまざまなレベルについて説明しています単純なレポートからAI対応のデータプラットフォームまでをカバーしていますビジネスにおけるデータの重要性を強調し、データプラットフォームがAIの推進力となる方法を示しています
PySparkでのランダムフォレスト回帰の実装方法
PySparkは、Apache Sparkの上に構築された強力なデータ処理エンジンであり、大規模なデータ処理に適していますスケーラビリティ、速度、多機能性、他のツールとの統合、使いやすさを提供します...

MLflowを使用した機械学習実験のトラッキング
イントロダクション 機械学習(ML)の領域は急速に拡大し、さまざまなセクターで応用されています。MLflowを使用して機械学習の実験を追跡し、それらを構築するために必要なトライアルを管理することは、それらが複雑になるにつれてますます困難になります。これにより、データサイエンティストにとって多くの問題が生じる可能性があります。例えば: 実験の損失または重複:実施された多くの実験を追跡することは困難であり、実験の損失や重複のリスクを高めます。 結果の再現性:実験の結果を再現することは困難な場合があり、モデルのトラブルシューティングや改善が困難になります。 透明性の欠如:モデルの予測を信頼するのが難しくなる場合があります。モデルの作成方法がわかりにくいためです。 写真提供:CHUTTERSNAP(Unsplash) 上記の課題を考慮すると、MLの実験を追跡し、再現性を向上させるためのメトリックをログに記録し、協力を促進するツールを持つことが重要です。このブログでは、コード例を含め、オープンソースのML実験追跡とモデル管理ツールであるMLflowについて探求し学びます。 学習目標 本記事では、MLflowを使用した機械学習の実験追跡とモデルレジストリの理解を目指します。 さらに、再利用可能で再現性のある方法でMLプロジェクトを提供する方法を学びます。 最後に、LLMとは何か、なぜアプリケーション開発のためにLLMを追跡する必要があるのかを学びます。 MLflowとは何ですか? MLflowロゴ(出典:公式サイト) MLflowは、機械学習プロジェクトを簡単に扱うための機械学習実験追跡およびモデル管理ソフトウェアです。MLワークフローを簡素化するためのさまざまなツールと機能を提供します。ユーザーは結果を比較し、複製し、パラメータやメトリックをログに記録し、MLflowの実験を追跡することができます。また、モデルのパッケージ化と展開も簡単に行えます。 MLflowを使用すると、トレーニング実行中にパラメータとメトリックをログに記録することができます。 # mlflowライブラリをインポートする import mlflow # mlflowのトラッキングを開始する mlflow.start_run() mlflow.log_param("learning_rate", 0.01)…

「生成AIがデータプラクティスを破壊する方法」
昨年11月にOpenAIによってリリースされたLanguage Learning Model(LLM)ChatGPTの登場は、Google BardやMicrosoft Bingなどの代替案を含む波及をもたらし、Gen AIは大規模な変革をもたらしました企業はこの技術をどのように活用できるかを探求しています

「Feature Store Summit 2023 プロダクション環境でのMLモデルの展開の実践的な戦略」
2023年10月11日、Feature Store Summitでは、UberやWeChatなどの主要な機械学習企業が集まり、データとAIについての詳細な議論が行われます

「アメリカのトップ10のデータサイエンススタートアップ企業」
データサイエンスは有望な分野として浮上しています。人間社会を革新する能力の理論的な予測を超えて、数多くのスタートアップがその莫大な潜在能力を示すために進出してきました。この記事では、アメリカのトップデータサイエンスのスタートアップを紹介しています。 アメリカのトップデータサイエンスのスタートアップ スタートアップ名 資金調達額 年数 検索の成長 Logz.Io $121.9M (シリーズE) 9 ピーク Featurespace $107.9M (助成金) 15 ピーク Zencity $51.2M (シリーズ未定) 8 急増 ComplyAdvantage $108.2M (シリーズC)…
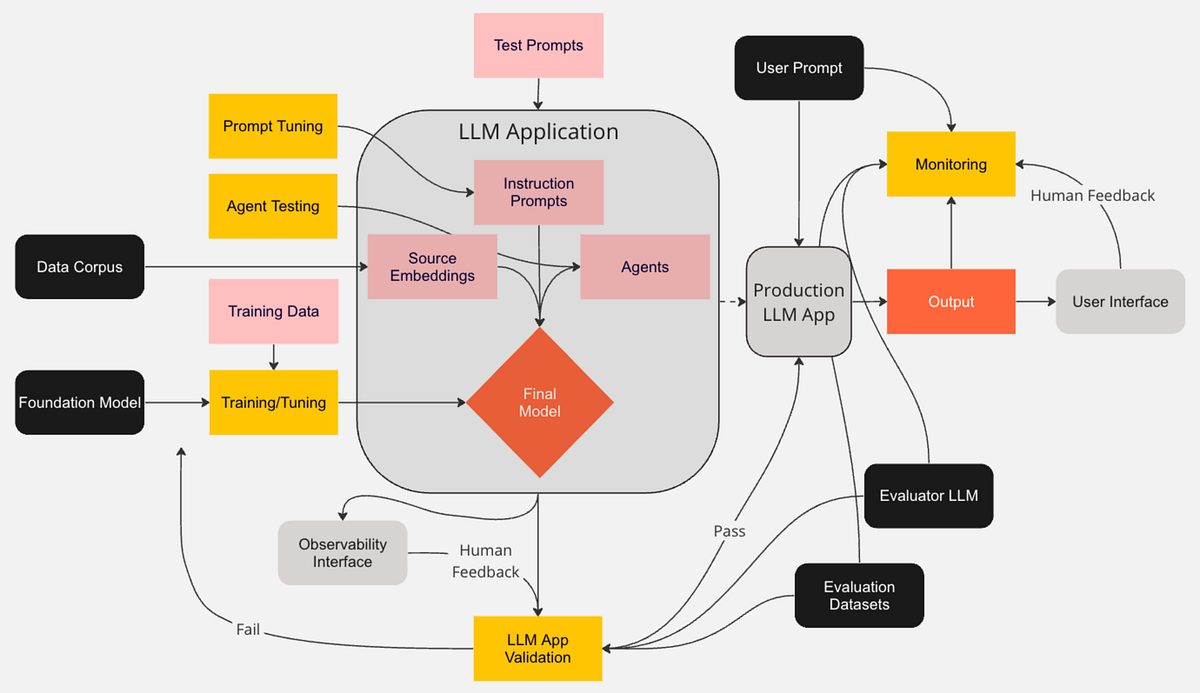
「LLMモニタリングと観測性 – 責任あるAIのための手法とアプローチの概要」
対象読者:実践者が利用可能なアプローチと実装の始め方を学びたい方、そして構築する際に可能性を理解したいリーダーたち…

TensorRT-LLMとは、NVIDIA Tensor Core GPU上の最新のLLMにおいて推論パフォーマンスを高速化し最適化するためのオープンソースライブラリです
人工知能(AI)の大規模言語モデル(LLM)は、テキストを生成したり、言語を翻訳したり、さまざまな形式の創造的な素材を書いたり、質問に役立つ回答を提供したりすることができます。ただし、LLMにはいくつかの問題があります。例えば、バイアスが含まれる可能性のある大規模なテキストやコードのデータセットで訓練されていることです。LLMが生成する結果には、これらの偏見が反映され、否定的なステレオタイプを強化し、誤った情報を広める可能性があります。時には、LLMは現実に基づかない文章を生成することもあります。これらの体験を幻覚と呼びます。幻覚的なテキストを読むことで、誤解や誤った推論が生じる可能性があります。LLMの内部の動作原理を理解するには、作業が必要です。そのため、医療や金融など、オープンさと責任が重要な文脈で問題が生じる可能性があります。LLMのトレーニングと展開には、大量の計算能力が必要です。これにより、多くの中小企業や非営利団体にはアクセスできなくなる可能性があります。スパム、フィッシングメール、フェイクニュースなど、悪情報がLLMを使用して生成されることがあります。これによってユーザーや企業が危険にさらされる可能性があります。 NVIDIAの研究者は、Meta、Anyscale、Cohere、Deci、Grammarly、Mistral AI、MosaicML(現在はDatabricksの一部)、OctoML、Tabnine、Together AIなどの業界のリーダーと協力し、LLMの推論の高速化とパーフェクト化に取り組んでいます。これらの改善は、近日公開予定のオープンソースNVIDIA TensorRT-LLMソフトウェアバージョンに含まれます。TensorRT-LLMは、NVIDIAのGPUを利用して最適化されたカーネル、前処理および後処理フェーズ、およびマルチGPU/マルチノード通信プリミティブを提供するディープラーニングコンパイラです。開発者は、C++やNVIDIA CUDAの詳しい知識を必要とせずに、新しいLLMを試行することができ、優れたパフォーマンスと迅速なカスタマイズオプションを提供します。オープンソースのモジュラーなPython APIを備えたTensorRT-LLMは、LLMの開発において新しいアーキテクチャや改良を定義、最適化、実行することを容易にします。 NVIDIAの最新のデータセンターGPUを活用することで、TensorRT-LLMはLLMのスループットを大幅に向上させながら、経費を削減することを目指しています。プロダクションにおける推論のためのLLMの作成、最適化、実行には、TensorRT Deep Learning Compiler、FasterTransformerからの最適化されたカーネル、前処理および後処理、マルチGPU/マルチノード通信をカプセル化した、わかりやすいオープンソースのPython APIが提供されます。 TensorRT-LLMにより、より多様なLLMアプリケーションが可能になります。MetaのLlama 2やFalcon 180Bなどの700億パラメータのモデルが登場した現在、定型的なアプローチはもはや実用的ではありません。このようなモデルのリアルタイムパフォーマンスは、通常、マルチGPUの構成や複雑な調整に依存しています。TensorRT-LLMは、重み行列をデバイス間で分散させるテンソル並列処理を提供することで、このプロセスを効率化し、開発者が手動で断片化や再配置を行う必要をなくします。 また、LLMアプリケーションには非常に変動するワークロードが特徴であるため、フライト中のバッチ最適化は効果的に管理するための注目すべき機能です。この機能により、質問応答型チャットボットや文書要約などのタスクにおいて、動的な並列実行が可能となり、GPUの利用率を最大限に引き出すことができます。AIの実装の規模と範囲の拡大を考慮すると、企業は所有コストの削減を期待できます。 性能面でも驚異的な結果が出ています。TensorRT-LLMを使用した場合、TensorRT-LLMを使用しない場合やA100と比較した場合、NVIDIA H100を使用した場合の記事要約などのタスクで、8倍の性能向上が見られます。 図1. GPT-J-6B A100とTensorRT-LLMを使用したH100の比較 | テキスト要約、可変長の入出力、CNN /…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.