Learn more about Search Results DataLoader - Page 6

- You may be interested
- 「UCLAの研究者たちは、広帯域の回折光学...
- この中国のAI研究は「Consistent4D」を紹...
- デジタルアート保護の革命:不正なAIウェ...
- イーロン・マスクが「Grok」を紹介:反抗...
- 「Amazon TextractとAmazon OpenSearchを...
- 「時間の逆転:拡散モデルと確率微分方程式」
- 「学生として、私がChatGPTを使って生産性...
- KAISTの研究者らが「SyncDiffusion」を提...
- 「Jupyter AIに会おう Jupyterノートブッ...
- サリー大学の研究者が新しい人工知能(AI...
- GoogleのPaLM 2:言語モデルの革命化
- ベクトルデータベースについて知っておく...
- 「ウェアラブルデータによるコロナ感染予測」
- 中国の最新のAI研究により、「OMMO」と呼...
- Stability AIが初の日本語ビジョン言語モ...
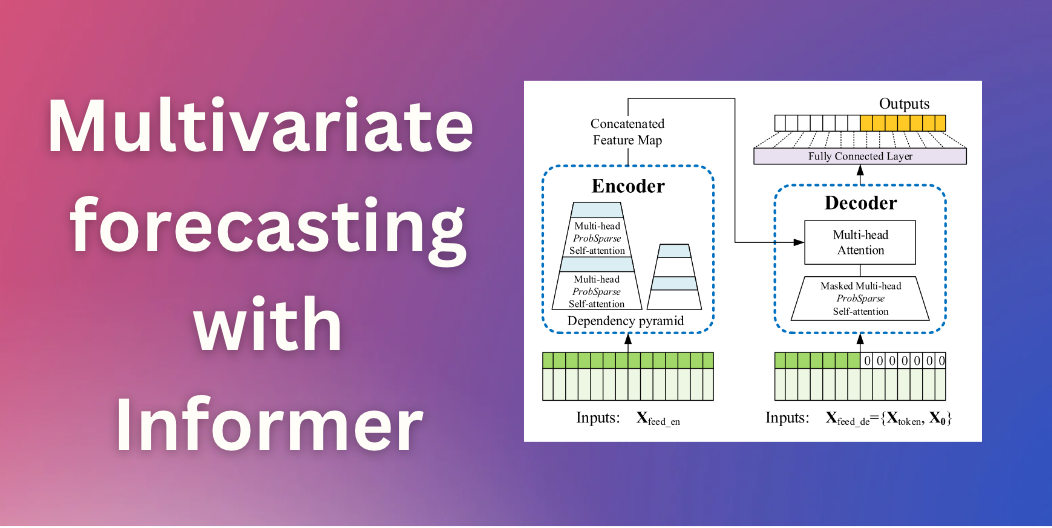
Informerを使用した多変量確率時系列予測
イントロダクション 数ヶ月前、私たちはTime Series Transformerを紹介しました。これは、予測に適用されたバニラTransformer(Vaswani et al.、2017)であり、単一変量の確率的予測課題(つまり、各時系列の1次元分布を個別に予測すること)の例を示しました。この記事では、現在🤗 Transformersで利用可能な、AAAI21のベストペーパーであるInformerモデル(Zhou, Haoyi, et al., 2021)を紹介します。これを使用して、多変量の確率的な予測課題、つまり、将来の時系列ターゲット値のベクトルの分布を予測する方法を示します。なお、バニラのTime Series Transformerモデルにも同様に適用できます。 多変量確率時系列予測 確率予測のモデリングの観点からは、Transformer/Informerは多変量時系列に対して取り扱う際に変更を必要としません。単変量と多変量の設定の両方で、モデルはベクトルのシーケンスを受け取り、唯一の変更は出力またはエミッション側にあります。 高次元データの完全な結合条件付き分布をモデリングすると、計算コストが高くなる場合があります。そのため、データを同じファミリーからの独立した分布、または完全な共分散の低ランク近似など、いくつかの近似手法に頼ることがあります。ここでは、実装した分布のファミリーに対してサポートされている独立(または対角)エミッションに頼ることにします。 Informer – 内部構造 バニラTransformer(Vaswani et al.、2017)に基づいて、Informerは2つの主要な改善を採用しています。これらの改善を理解するために、バニラTransformerの欠点を思い出してみましょう。 正準自己注意の二次計算:バニラTransformerは、計算量がO (…

Hugging FaceとFlowerを使用したフェデレーテッドラーニング
このチュートリアルでは、Hugging Faceを使用して、Flowerを介して複数のクライアント上で言語モデルのトレーニングをフェデレートする方法を紹介します。具体的には、IMDBの評価データセットを使用して、事前トレーニングされたTransformerモデル(distilBERT)をシーケンス分類のために微調整します。最終的な目標は、映画の評価がポジティブかネガティブかを検出することです。 ノートブックはこちらでご利用いただけますが、複数のクライアントで実行する代わりに、Google Colab内でフェデレーテッド環境をエミュレートするためにFlowerのシミュレーション機能(flwr['simulation'])を使用します(これはまた、start_serverを呼び出す代わりにstart_simulationを呼び出す必要があり、その他の変更が必要です)。 依存関係 このチュートリアルに従うためには、以下のパッケージをインストールする必要があります:datasets、evaluate、flwr、torch、およびtransformers。これはpipを使用して行うことができます: pip install datasets evaluate flwr torch transformers 標準的なHugging Faceのワークフロー データの処理 IMDBデータセットを取得するために、Hugging Faceのdatasetsライブラリを使用します。その後、データをトークン化し、PyTorchのデータローダーを作成する必要があります。これはすべてload_data関数で行われます: import random import torch from datasets…

トランスフォーマーによるグラフ分類
前回のブログでは、グラフ上での機械学習の理論的な側面について調査しました。このブログでは、Transformersライブラリを使用してグラフ分類を行う方法について調査します(デモノートブックをここからダウンロードして一緒に進めることもできます!) 現時点では、Transformersで利用できる唯一のグラフトランスフォーマーモデルはMicrosoftのGraphormerですので、こちらを使用します。他のモデルも使用して統合する人々がどのような結果を出すか楽しみにしています 🤗 必要条件 このチュートリアルに従うためには、datasetsとtransformers(バージョン>= 4.27.2)がインストールされている必要があります。これはpip install -U datasets transformersで行うことができます。 データ グラフデータを使用するためには、独自のデータセットから始めるか、Hubで利用可能なデータセットを使用することができます。既に利用可能なデータセットを使用することに焦点を当てますが、自分のデータセットを追加することも自由です! 読み込み Hubからのグラフデータセットの読み込みは非常に簡単です。まず、ogbg-mohivデータセット(StanfordのOpen Graph Benchmarkのベースライン)をロードしましょう。これはOGBリポジトリに保存されています: from datasets import load_dataset # Hubには1つのスプリットしかありません dataset =…

はい、トランスフォーマーは時系列予測に効果的です(+オートフォーマー)
イントロダクション 数ヶ月前、AAAI 2021のベストペーパーアワードを受賞したTime Series TransformerであるInformerモデル(Zhou, Haoyiら、2021)を紹介しました。また、Informerを使用した多変量確率予測の例も提供しました。この記事では、「Transformerは時系列予測に効果的か?」(AAAI 2023)という疑問について議論します。見ていくとわかりますが、それらは効果的です。 まず、Transformerは確かに時系列予測に効果的であることを経験的に証明します。私たちの比較では、線形モデルであるDLinearが主張されるほど優れていないことが示されています。線形モデルと同じ設定の同等の大きさのモデルと比較した場合、Transformerベースのモデルは私たちが考慮するテストセットのメトリックでより優れた性能を発揮します。その後、Informerモデルの後にNeurIPS 2021で発表されたAutoformerモデル(Wu, Haixuら、2021)を紹介します。Autoformerモデルは現在🤗 Transformersで利用できます。最後に、Autoformerの分解層を使用するシンプルなフィードフォワードネットワークであるDLinearモデルについて説明します。DLinearモデルは、「Transformerは時系列予測に効果的か?」という論文で初めて紹介され、Transformerベースのモデルを時系列予測で上回ると主張されています。 さあ、始めましょう! ベンチマーキング – Transformers vs. DLinear 最近AAAI 2023で発表された「Transformerは時系列予測に効果的か?」という論文では、著者らはTransformerが時系列予測に効果的ではないと主張しています。彼らは、DLinearと呼ばれるシンプルな線形モデルとTransformerベースのモデルを比較しています。DLinearモデルはAutoformerモデルの分解層を使用しており、後ほどこの記事で紹介します。著者らは、DLinearモデルがTransformerベースのモデルを時系列予測で上回ると主張しています。本当にそうなのでしょうか?さあ、確かめましょう。 上記の表は、論文で使用された3つのデータセットにおけるAutoformerモデルとDLinearモデルの比較結果を示しています。結果からわかるように、Autoformerモデルは3つのデータセットすべてでDLinearモデルを上回っています。 次に、上記の表のTrafficデータセットを使用してAutoformerモデルとDLinearモデルを比較し、得られた結果の説明を提供します。 要約: 簡単な線形モデルは一部の場合において有利ですが、ユニバリエートの設定では変数を組み込む能力がTransformerのようなより複雑なモデルに比べてありません。 Autoformer…

ビジョン言語モデルの高速化:Habana Gaudi2上のBridgeTower
Optimum Habana v1.6 on Habana Gaudi2 では、最新のビジョン言語モデルである BridgeTower のファインチューニングにおいて、A100 と比較してほぼ3倍の高速化を実現しています。ハードウェアアクセラレーションによるデータの読み込みと高速な DDP 実装の2つの新機能がパフォーマンス向上に寄与しています。 これらの技術は、データの読み込みに制約がある他のワークロードにも適用できます。これは、さまざまなタイプのビジョンモデルに頻繁に起こるケースです。この投稿では、BridgeTower のファインチューニングを Habana Gaudi2 と Nvidia A100 80GB で比較するために使用したプロセスとベンチマークを紹介します。また、トランスフォーマーベースのモデルでこれらの機能を簡単に活用する方法も示します。 BridgeTower 最近のビジョン言語(VL)モデルは、さまざまなVLタスクで非常に重要であり、優位性を示しています。最も一般的なアプローチは、それぞれのモダリティから表現を抽出するためにユニモーダルエンコーダを利用することです。その後、これらの表現は融合されるか、クロスモーダルエンコーダに供給されます。VL表現学習のパフォーマンス制約と制限を効果的に扱うために、BridgeTower は複数のブリッジ層を導入し、ユニモーダルエンコーダのトップ層とクロスモーダルエンコーダの各層との間に接続を構築します。これにより、クロスモーダルエンコーダ内の異なる意味レベルで視覚とテキストの表現の効果的なボトムアップのクロスモーダルの整合性と融合が可能になります。…

ドレスコードの解読👗 自動ファッションアイテム検出のためのディープラーニング
電子商取引の活気ある世界では、ファッション業界は独自のランウェイですしかし、もし我々がこのランウェイのドレスコードを、デザイナーの目ではなく、ディープラーニングの精度で解読できるとしたら...

言語モデルの構築:ステップバイステップのBERTの実装ガイド
イントロダクション 言語処理を行う機械学習モデルの進歩は、ここ数年で急速に進んでいます。この進歩は、研究室を出て、いくつかの主要なデジタル製品の動力となり始めています。良い例として、BERTモデルがGoogle検索の重要な要素となったことが発表されたことがあります。Googleは、この進化(自然言語理解の進歩が検索に応用されること)は、「過去5年間で最大の進歩であり、検索の歴史上でも最大の進歩の1つ」と考えています。では、BERTとは何かについて理解しましょう。 BERTは、Bidirectional Encoder Representations from Transformersの略です。その設計では、未ラベルのテキストから左右の文脈の両方に依存して事前学習された深層双方向表現を作成します。我々は、追加の出力層を追加するだけで、事前学習されたBERTモデルを異なるNLPタスクに適用することができます。 学習目標 BERTのアーキテクチャとコンポーネントを理解する。 BERTの入力に必要な前処理ステップと、異なる入力シーケンスの長さを扱う方法を学ぶ。 TensorFlowやPyTorchなどの人気のある機械学習フレームワークを使用してBERTを実装するための実践的な知識を得る。 テキスト分類や固有表現認識などの特定の下流タスクにBERTを微調整する方法を学ぶ。 次に、「なぜそれが必要なのか?」という別の質問が出てきます。それを説明しましょう。 この記事は、データサイエンスブログマラソンの一環として公開されました。 なぜBERTが必要なのか? 適切な言語表現とは、機械が一般的な言語を理解する能力です。word2VecやGloveのような文脈非依存モデルは、語彙中の各単語に対して単一の単語埋め込み表現を生成します。例えば、”crane”という用語は、”crane in the sky”や”crane to lift heavy objects”といった文脈で厳密に同じ表現を持ちます。文脈モデルは、文内の他の単語に基づいて各単語を表現します。つまり、BERTはこれらの関係を双方向に捉える文脈モデルです。 BERTは、Semi-supervised…

ビッグデータアプリケーションのクラウドストレージコストの管理
増加し続けるデータ量への依存度の高まりにより、現代の企業は高容量かつ高スケーラビリティのあるデータストレージソリューションにより、これまで以上に依存しています多くの企業にとって、これは...

メタAIのもう一つの革命的な大規模モデル — 画像特徴抽出のためのDINOv2
Mete AIは、画像から自動的に視覚的な特徴を抽出する新しい画像特徴抽出モデルDINOv2の新バージョンを紹介しましたこれはAIの分野でのもう一つの革命的な進歩です...
PyTorchモデルのパフォーマンス分析と最適化—Part2
これは、GPU上で実行されるPyTorchモデルの分析と最適化に関する一連の投稿の第二部です最初の投稿では、プロセスとその重要な可能性を示しました...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.