Learn more about Search Results BART - Page 6

- You may be interested
- ベクトルデータベース:初心者向けガイド!
- Amazon SageMakerの自動モデルチューニン...
- 3日間でAIアプリを作成しました
- 現代の自然言語処理(NLP):詳細な概要パ...
- 研究:AIモデルはルール違反に関する人間...
- 私たちがChatGPTチャットボットを10倍速く...
- LayoutLMv3を使用してビジネス文書から主...
- 『AWS SageMaker Data Wranglerの新機能で...
- 「初心者のためのイメージ分類」
- 「AIはどこで起こるのか?」
- マーケティング予算の最適化方法
- 「AIが生成したドレイクの曲がグラミー賞...
- 「Copy AI レビュー:最高のAIライティン...
- IntelとHugging Faceがパートナーシップを...
- (いぜん より も しょうさいな じょうほう...

実際のデータなしで効率的なテーブルの事前学習:TAPEXへの導入
近年、大規模なテキストデータを活用することで、言語モデルの事前学習が大きな成功を収めています。マスクされた言語モデリングなどの事前学習タスクを使用することで、これらのモデルはいくつかの下流タスクで驚くほどのパフォーマンスを示しています。しかし、事前学習タスク(例:言語モデリング)と下流タスク(例:テーブルの質問応答)の間には大きなギャップがあり、既存の事前学習は十分に効率的ではありません。実践では、有望な改善を得るために非常に大量の事前学習データが必要なことがよくあります。ドメイン適応の事前学習でも同様です。どのようにすればギャップを埋めるための事前学習タスクを設計し、事前学習を加速させることができるでしょうか? 概要 「TAPEX: ニューラルSQL実行エグゼキュータの学習を通じたテーブルの事前学習」という論文では、事前学習中に実データの代わりに合成データを使用するアプローチを探求し、TAPEX(エグゼキューションを通じたテーブルの事前学習)を例としてその有用性を示しています。TAPEXでは、合成コーパス上にニューラルSQLエグゼキュータを学習することで、テーブルの事前学習を実現しています。 注意: [Table]は入力されたユーザー提供のテーブルのプレースホルダーです。 上記の図に示すように、TAPEXはテーブル上で実行可能なSQLクエリとその実行結果をシステム的にサンプリングし、合成された非自然な事前学習コーパスを作成します。その後、言語モデル(例:BART)を事前学習し、SQLクエリの実行結果を出力するように学習させることで、ニューラルSQLエグゼキュータのプロセスを模倣します。 事前学習 以下の図は、事前学習プロセスを示しています。各ステップでは、まずウェブからテーブルを取得します。例えば、オリンピックのテーブルがあります。次に、実行可能なSQLクエリ SELECT City WHERE Country = France ORDER BY Year ASC LIMIT 1 をサンプリングします。オフシェルフのSQLエグゼキュータ(例:MySQL)を使用して、クエリの実行結果 Paris を取得できます。同様に、SQLクエリとフラット化されたテーブルの連結をモデル(例:BARTエンコーダー)の入力として与えることで、実行結果がモデル(例:BARTデコーダー)の出力の教師として機能します。…

GraphcoreとHugging Faceが、IPU対応の新しいトランスフォーマーのラインアップを発表
GraphcoreとHugging Faceは、Hugging Face Optimumにおいて利用可能な機械学習のモダリティとタスクの範囲を大幅に拡張しました。Hugging Face Optimumは、Transformersのパフォーマンス最適化のためのオープンソースライブラリです。開発者は、GraphcoreのIPUで最高のパフォーマンスを提供するように最適化された幅広いHugging Face Transformerモデルに簡単にアクセスできるようになりました。 Optimum Graphcoreの発売後間もなく提供されたBERT Transformerモデルを含む、開発者は現在、自然言語処理(NLP)、音声、コンピュータビジョンをカバーする10のモデルにアクセスできます。これらのモデルには、IPUの設定ファイルと、事前学習および微調整済みのモデルの重みを使用するための準備が整っています。 新しいOptimumモデル コンピュータビジョン ViT(Vision Transformer)は、主要なコンポーネントとしてTransformerメカニズムを使用した画像認識の画期的な手法です。画像がViTに入力されると、言語システムで単語が処理されるのと同様に、画像は小さなパッチに分割されます。各パッチはTransformer(埋め込み)によってエンコードされ、個別に処理することができます。 NLP GPT-2(Generative Pre-trained Transformer 2)は、非常に大規模な英語のコーパスで自己教師付きの形式で事前学習されたテキスト生成Transformerモデルです。これは、テキストのラベリングを行わずに、公開されているデータを多く使用することができるため、自動的なプロセスでテキストから入力とラベルを生成することによって事前学習されました。より具体的には、文の次の単語を推測して文を生成するようにトレーニングされています。 RoBERTa(Robustly optimized BERT approach)は、自己教師付きの形式で大規模な英語のコーパスで事前学習されたTransformerモデルです(GPT-2と同様)。より具体的には、RoBERTaはマスクされた言語モデリング(MLM)の目的で事前学習されています。文を取り、モデルは入力の15%の単語をランダムにマスクし、全体のマスクされた文をモデルを通して実行し、マスクされた単語を予測する必要があります。RoBERTaはマスクされた言語モデリングに使用することができますが、主に下流タスクで微調整することを意図しています。…
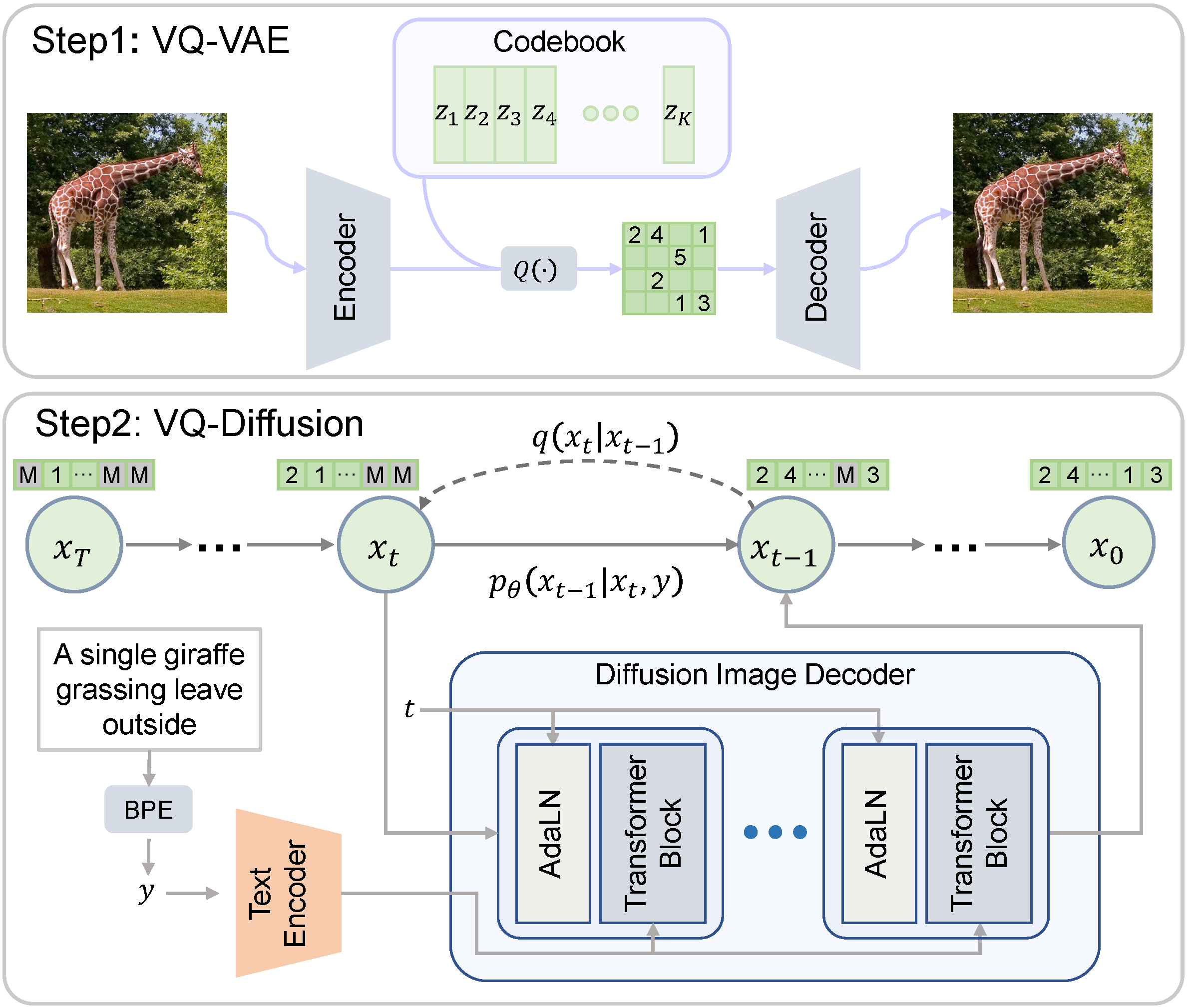
VQ-Diffusion
ベクトル量子化拡散(VQ-Diffusion)は、中国科学技術大学とMicrosoftによって開発された条件付き潜在拡散モデルです。一般的に研究されている拡散モデルとは異なり、VQ-Diffusionのノイジングとデノイジングのプロセスは量子化された潜在空間で動作します。つまり、潜在空間は離散的なベクトルの集合で構成されています。離散的な拡散モデルは、連続的な対応物と比較する興味深い比較対象を提供します。 Hugging Faceモデルカード Hugging Face Spaces オリジナルの実装 論文 デモ 🧨 Diffusersを使用すると、わずか数行のコードでVQ-Diffusionを実行できます。 依存関係をインストールする pip install 'diffusers[torch]' transformers ftfy パイプラインをロードする from diffusers import VQDiffusionPipeline pipe =…

bitsandbytes、4ビットの量子化、そしてQLoRAを使用して、LLMをさらに利用しやすくする
LLMは大きいことで知られており、一般のハードウェア上で実行またはトレーニングすることは、ユーザーにとって大きな課題であり、アクセシビリティも困難です。私たちのLLM.int8ブログポストでは、LLM.int8論文の技術がtransformersでどのように統合され、bitsandbytesライブラリを使用しているかを示しています。私たちは、モデルをより多くの人々にアクセス可能にするために、再びbitsandbytesと協力することを決定し、ユーザーが4ビット精度でモデルを実行できるようにしました。これには、テキスト、ビジョン、マルチモーダルなどの異なるモダリティの多くのHFモデルが含まれます。ユーザーはまた、Hugging Faceのエコシステムからのツールを活用して4ビットモデルの上にアダプタをトレーニングすることもできます。これは、DettmersらによるQLoRA論文で今日紹介された新しい手法です。論文の概要は以下の通りです: QLoRAは、1つの48GBのGPUで65Bパラメータモデルをフィントゥーニングするためのメモリ使用量を十分に削減しながら、完全な16ビットのフィントゥーニングタスクのパフォーマンスを維持する効率的なフィントゥーニングアプローチです。QLoRAは、凍結された4ビット量子化された事前学習言語モデルをLow Rank Adapters(LoRA)に逆伝搬させます。私たちの最高のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達しますが、1つのGPUでのフィントゥーニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています:(a)通常分布された重みに対して情報理論的に最適な新しいデータ型である4ビットNormalFloat(NF4)(b)量子化定数を量子化して平均メモリフットプリントを減らすためのダブル量子化、および(c)メモリスパイクを管理するためのページドオプティマイザ。私たちはQLoRAを使用して1,000以上のモデルをフィントゥーニングし、高品質のデータセットを使用した指示の追跡とチャットボットのパフォーマンスの詳細な分析を提供しています。これは通常のフィントゥーニングでは実行不可能である(例えば33Bおよび65Bパラメータモデル)モデルタイプ(LLaMA、T5)とモデルスケールを横断したものです。私たちの結果は、QLoRAによる小規模な高品質データセットでのフィントゥーニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。さらに、ヒューマンとGPT-4の評価に基づいてチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価がヒューマンの評価に対して安価で合理的な代替手段であることを示しています。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するための信頼性がないことがわかります。レモンピックされた分析では、GuanacoがChatGPTに比べてどこで失敗するかを示しています。私たちは4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 リソース このブログポストとリリースには、4ビットモデルとQLoRAを始めるためのいくつかのリソースがあります: 元の論文 基本的な使用法Google Colabノートブック-このノートブックでは、4ビットモデルとその変種を使用した推論の方法、およびGoogle ColabインスタンスでGPT-neo-X(20Bパラメータモデル)を実行する方法を示しています。 フィントゥーニングGoogle Colabノートブック-このノートブックでは、Hugging Faceエコシステムを使用してダウンストリームタスクで4ビットモデルをフィントゥーニングする方法を示しています。Google ColabインスタンスでGPT-neo-X 20Bをフィントゥーニングすることが可能であることを示しています。 論文の結果を再現するための元のリポジトリ Guanaco 33b playground-または以下のプレイグラウンドセクションをチェック はじめに モデルの精度と最も一般的なデータ型(float16、float32、bfloat16、int8)について詳しく知りたくない場合は、これらの概念の詳細について視覚化を含めた簡単な言葉で説明している私たちの最初のブログポストの紹介を注意深くお読みいただくことをお勧めします。 詳細については、このwikibookドキュメントを通じて浮動小数点表現の基本を読むことをお勧めします。 最近のQLoRA論文では、4ビットFloatと4ビットNormalFloatという異なるデータ型を探求しています。ここでは、理解しやすい4ビットFloatデータ型について説明します。…
データ駆動型の世界で理解すべき重要な統計的アイデア4つ
2023年にデータリテラシーを持つためには、サンプリング、不確実性、AI、機械学習、そして統計的な主張の解釈といった基本的な概念が必要です

TaatikNet(ターティクネット):ヘブライ語の翻字のためのシーケンス・トゥ・シーケンス学習
この記事では、TaatikNetとseq2seqモデルの簡単な実装方法について説明していますコードとドキュメントについては、TaatikNetのGitHubリポジトリを参照してくださいインタラクティブなデモについては、HF Spaces上のTaatikNetをご覧ください多くのタスク...

CVPR 2023におけるGoogle
Googleのプログラムマネージャー、Shaina Mehtaが投稿しました 今週は、バンクーバーで開催される最も重要なコンピュータビジョンとパターン認識の年次会議であるCVPR 2023の始まりを迎えます(追加のバーチャルコンテンツもあります)。Google Researchはコンピュータビジョンの研究のリーダーであり、プラチナスポンサーであり、メインカンファレンスで約90の論文が発表され、40以上のカンファレンスワークショップやチュートリアルに積極的に参加しています。 今年のCVPRに参加する場合は、是非、ブースに立ち寄って、最新のマシンパーセプションの様々な分野に応用するための技術を積極的に探求している研究者とお話ししてください。弊社の研究者は、MediaPipeを使用したオンデバイスのMLアプリケーション、差分プライバシーの戦略、ニューラル輝度場技術など、いくつかの最近の取り組みについても話し、デモを行います。 以下のリストでCVPR 2023で発表される弊社の研究についても詳しくご覧いただけます(Googleの所属は太字で表示されています)。 理事会と組織委員会 シニアエリアチェアには、Cordelia Schmid、Ming-Hsuan Yangが含まれます。 エリアチェアには、Andre Araujo、Anurag Arnab、Rodrigo Benenson、Ayan Chakrabarti、Huiwen Chang、Alireza Fathi、Vittorio Ferrari、Golnaz Ghiasi、Boqing Gong、Yedid Hoshen、Varun Jampani、Lu…
Rにおける二元配置分散分析
二元分散分析(Two-way ANOVA)は、二つのカテゴリカル変数が量的連続変数に与える同時効果を評価することができる統計的方法です二元分散分析は…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.