Learn more about Search Results 24 - Page 6

- You may be interested
- 「Amazon Bedrockを使用した生成型AIアプ...
- 「ジェネラティブAIサミットのオンデマン...
- (Shōrai no toppu 10 de-ta saiensu no ky...
- 最適なテクノロジー/ベンダーを選ぶための...
- 「初心者のためのPandasを使ったデータフ...
- 「AmazonショッピングがAmazon Rekognitio...
- 「ベルカーブの向こう側:t-分布の紹介」
- このAI論文は、デュアル1-Dヒートマップを...
- 2023年のトップジェネレーティブAI企業
- 声サンプルデータ分析を使用したパーキン...
- AIが統合セールスチームにより高速かつ高...
- 特定のドメインに特化した物体検出モデル...
- AI教育の追求 – 過去、現在、そして...
- In Japanese, the translation of Time Se...
- 「2023年の最高の人工知能AIベースのアー...

「2024年のトップ5大学の証明書」
「大学の証明書が技術セクターに特化した知識と専門知識の扉を開く方法を探索してください」

「2023-24年のアクセンチュアフェローにお会いください」
「MITとAccentureの産業と技術の融合イニシアチブは、2023-24年度の大学院フェローシップを発表します」

「ジェネレーティブAI(2024)の10の重要ポイント」
「2023年、生成AIの世界に飛び込み、その応用、影響、そして将来の課題についての洞察を得ましょう」

「GeForce NOWが大いに盛り上がり、9月には24本の新作ゲームが登場しますその中でも『Party Animals』が一番注目されています」
そうして、夏は9月になり、今年最も期待されているゲームのいくつか、Cyberpunk 2077:Phantom Libertyの拡張版、PAYDAY 3、そしてParty Animalsが、今月のローンチと共にGeForce NOWライブラリに追加されます。 これらは9月にクラウドゲーミングサービスに追加される24の新しいゲームの一部です。そして、次のGame PassタイトルであるSea of Starsが、今週の13の新しいゲームの一部としてローンチ時にクラウドに参加します。 GFN Thursdayでは、今月クラウドに参加する次のMicrosoftタイトル(Quake II、Gears Tactics、Halo Infiniteなど)を見るために目を光らせてください。 さらに、NVIDIAはGoogleと連携して、Chromebookの所有者にGeForce NOW Priorityメンバーシップの3か月無料オファーを提供します。GeForce NOWクラウドゲーミングは、最大1,600pの解像度と120Hz以上のディスプレイを提供するChromebookと完全に組み合わせることができます。 クラウドでパーティーハード クラウドが大騒ぎになります。 Recreate GamesとSource Technologyによる、笑えるほどおかしい物理ベースのパーティーバトラー、Party…

「2024年のデータ管理の未来予想:トップ4の新興トレンド」
「これらは、私の個人的な経験、最近の研究、および主要なプラットフォームからのレポートに基づいた予測です」

ビジュアルエフェクトマルチプライヤー:ワイリー社、24倍のリターンを得るためにGPUレンダリングに全力投球
ビジュアルエフェクトスタジオは長い間、計算負荷の高い複雑な特殊効果のために、レンダーファーム(膨大な数のサーバー)に頼ってきましたが、その風景は急速に変わりつつあります。 これらのサーバー施設では、高いシリコンとエネルギーコストがかかり、Mooreの法則によるパフォーマンスの向上が制約されることで、スタジオの利益を減少させ、制作時間を増加させています。 それらの課題を回避するために、Oscar受賞作品『デューン』、マーベルのタイトル、HBO、Netflixの作品を手掛けるビジュアルエフェクトスタジオであるWylie Co.は、GPUレンダリングに全力を注いでいます。 写実的なビジュアルエフェクトやスタイライズされたアニメーションのレンダリングには、年間約100億CPUコア時間が必要とされます。単一のアニメーション映画をレンダリングするためには、レンダーファームには5万以上のCPUコアが300億以上のCPUコア時間を稼働することが必要です。これらのリソースは、著しい炭素効果と物理的な足跡を作り出すことができます。 多くのスタジオが既にレンダリングプロセスの一部にGPUを使用していますが、Wylie Co.は最終的なレンダリングやワイヤリムーバーなどのAI、コンポジットやビジュアルエフェクトワークフローの多くの側面において、すべての作業にGPUを使用しています。 GPUへの移行によるパフォーマンスの向上 24倍 レンダーファームによって、ビジュアルエフェクトスタジオは大量の画像、シーン、または映画全体のファイルをオフロードし、これらの作業には数時間または数週間かかるため、スタジオのリソースを開放することができます。 多くのスタジオは、以前にレンダーファームに送信されていた一部のタスクを処理できるマルチGPUワークステーションに移行しています。これにより、スタジオはより迅速に反復することができ、制作時間とコストを圧縮することができます。 Wylie Co.は、さまざまな領域でGPUに移行し、CPUと比較して総合的に24倍のパフォーマンス向上を実現しました1。 GPUはエネルギー使用量を10倍低減 スタジオは、このような計算負荷の高いレンダリングタスクのコストを削減したいと考えていますが、現実的には、エネルギーとスペースのコストの低下も低い炭素足跡の利益をもたらします。 ビジュアルエフェクトレンダリングパイプラインで使用されるGPUは、パフォーマンスを最大46倍に向上させる一方、エネルギー消費を5倍、資本費を6倍低減します。 GPUへの切り替えにより、業界全体での調達コストを9億ドル、CPUベースのレンダーファームを使用した場合に比べて消費されるエネルギー量を215ギガワット時間削減できる見込みです。 NVIDIAのデジタルレンダリングの省エネソリューションについて学ぶ 1 NVIDIA Quadro…
「7月24日から7月31日までの週間でのトップのコンピュータビジョン論文」
コンピュータビジョンは、視覚世界を解釈し理解するための機械の能力を高めることに重点を置いた人工知能の分野であり、画期的な研究と技術の進展により急速に進化しています

24GBのコンシューマーGPUでRLHFを使用して20B LLMを微調整する
私たちは、trlとpeftの統合を正式にリリースし、Reinforcement Learningを用いたLarge Language Model (LLM)のファインチューニングを誰でも簡単に利用できるようにしました!この投稿では、既存のファインチューニング手法と競合する代替手法である理由を説明します。 peftは一般的なツールであり、多くのMLユースケースに適用できますが、特にメモリを多く必要とするRLHFにとって興味深いです! コードに直接深く入りたい場合は、TRLのドキュメンテーションページで直接例のスクリプトをチェックしてください。 イントロダクション LLMとRLHF 言語モデルとRLHF(Reinforcement Learning with Human Feedback)を組み合わせることは、ChatGPTなどの非常に強力なAIシステムを構築するための次の手段として注目されています。 RLHFを用いた言語モデルのトレーニングは、通常以下の3つのステップを含みます: 1- 特定のドメインまたは命令のコーパスで事前学習されたLLMをファインチューニングする 2- 人間によって注釈付けされたデータセットを収集し、報酬モデルをトレーニングする 3- ステップ1で得られたLLMを報酬モデルとデータセットを用いてRL(例:PPO)でさらにファインチューニングする ここで、ベースとなるLLMの選択は非常に重要です。現時点では、多くのタスクに直接使用できる「最も優れた」オープンソースのLLMは、命令にファインチューニングされたLLMです。有名なモデルとしては、BLOOMZ、Flan-T5、Flan-UL2、OPT-IMLなどがあります。これらのモデルの欠点は、そのサイズです。まともなモデルを得るには、少なくとも10B+スケールのモデルを使用する必要がありますが、モデルを単一のGPUデバイスに合わせるだけでも40GBのGPUメモリが必要です。 TRLとは何ですか? trlライブラリは、カスタムデータセットとトレーニングセットアップを使用して、誰でも簡単に自分のLMをRLでファインチューニングできるようにすることを目指しています。他の多くのアプリケーションの中で、このアルゴリズムを使用して、ポジティブな映画のレビューを生成するモデルをファインチューニングしたり、制御された生成を行ったり、モデルをより毒性のないものにしたりすることができます。…

vLLMについて HuggingFace Transformersの推論とサービングを加速化するオープンソースLLM推論ライブラリで、最大24倍高速化します
大規模言語モデル、略してLLMは、人工知能(AI)の分野において画期的な進歩として登場しました。GPT-3などのこのようなモデルは、自然言語理解を完全に革新しました。これらのモデルが既存の大量のデータを解釈し、人間らしいテキストを生成できる能力を持っていることから、これらのモデルは、AIの未来を形作るために膨大な可能性を秘めており、人間と機械の相互作用とコミュニケーションに新たな可能性を開くことができます。ただし、LLMで達成された大成功にもかかわらず、このようなモデルに関連する重要な課題の1つは、計算の非効率性であり、最も強力なハードウェアでも遅いパフォーマンスにつながることがあります。これらのモデルは、数百万から数十億のパラメータで構成されているため、このようなモデルをトレーニングするには、広範囲な計算リソース、メモリ、および処理能力が必要であり、常にアクセスできるわけではありません。さらに、これらの複雑なアーキテクチャによる遅い応答時間により、LLMはリアルタイムまたはインタラクティブなアプリケーションでは実用的ではなくなることがあります。そのため、これらの課題に対処することは、LLMのフルポテンシャルを引き出し、その利点をより広く利用可能にするために不可欠なことになります。 この問題に取り組むため、カリフォルニア大学バークレー校の研究者たちは、vLLMというオープンソースライブラリを開発しました。このライブラリは、LLMの推論とサービングのためのよりシンプルで、より速く、より安価な代替方法です。Large Model Systems Organization (LMSYS)は、現在、このライブラリをVicunaとChatbot Arenaの駆動力として使用しています。初期のHuggingFace Transformersベースのバックエンドに比べて、vLLMに切り替えることで、研究機関は限られた計算リソースを使用しながらピークトラフィックを効率的に処理することができ、高い運用コストを削減することができました。現在、vLLMは、GPT-2、GPT BigCode、LLaMAなど、いくつかのHuggingFaceモデルをサポートしており、同じモデルアーキテクチャを維持しながら、HuggingFace Transformersのスループットレベルを24倍に向上させることができます。 バークレーの研究者たちは、PagedAttentionという革新的なコンセプトを導入しました。これは、オペレーティングシステムでのページングの従来のアイデアをLLMサービングに拡張した、新しいアテンションアルゴリズムです。PagedAttentionは、キーと値のテンソルをより柔軟に管理する方法を提供し、連続した長いメモリブロックが必要なくなるため、非連続のメモリスペースにそれらを格納することができます。これらのブロックは、アテンション計算中にブロックテーブルを使用して個別に取得することができ、より効率的なメモリ利用を実現します。この巧妙な技術を採用することで、メモリの無駄を4%未満に減らし、ほぼ最適なメモリ使用を実現できます。さらに、PagedAttentionは、5倍のシーケンスをまとめてバッチ処理できるため、GPUの利用率とスループットが向上します。 PagedAttentionには、効率的なメモリ共有の追加的な利点があります。複数の出力シーケンスが単一のプロンプトから同時に作成される並列サンプリング時に、PagedAttentionは、そのプロンプトに関連する計算リソースとメモリを共有することを可能にします。これは、論理ブロックを同じ物理ブロックにマッピングすることによって実現されます。このようなメモリ共有メカニズムを採用することで、PagedAttentionはメモリ使用量を最小限に抑え、安全な共有を確保します。研究者たちによる実験評価により、並列サンプリングによりメモリ使用量を55%削減し、スループットを2.2倍に向上させることができることが明らかになりました。 まとめると、vLLMは、PagedAttentionメカニズムの実装により、アテンションキーと値のメモリ管理を効果的に処理します。これにより、優れたスループット性能が実現されます。さらに、vLLMは、よく知られたHuggingFaceモデルとシームレスに統合され、並列サンプリングなどの異なるデコーディングアルゴリズムと一緒に使用することができます。ライブラリは、簡単なpipコマンドを使用してインストールでき、オフライン推論とオンラインサービングの両方に現在利用可能です。
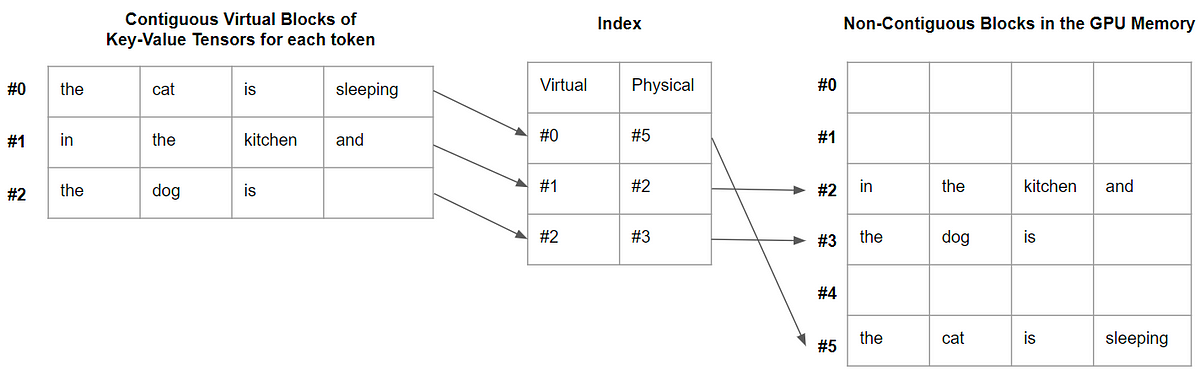
vLLM:24倍速のLLM推論のためのPagedAttention
この記事では、PagedAttentionとは何か、そしてなぜデコードを大幅に高速化するのかを説明します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.