Learn more about Search Results 限定的 - Page 6

- You may be interested
- ミシガン州立大学の研究者たちは、規模の...
- このAIニュースレターは、あなたが必要な...
- 「ODSC West Bootcampプログラムから期待...
- ジョージア工科大学の論文は、より速く潜...
- コールセンターにおけるAIソフトウェアが...
- サークルブームのレビュー:最高のAIパワ...
- 「テスラ、『不十分な』自動運転安全制御...
- インフレクション-2はGoogleのPaLM-2を超...
- 「AlphaFold 2の2億モデルによって明らか...
- 「教科書で学ぶ教師なし学習:K-Meansクラ...
- ETHチューリッヒの研究者が、大規模な言語...
- Rows AI:エクセルスプレッドシートの終焉...
- timeitとcProfileを使用してPythonコード...
- 「トランスフォーマーを使用した音声から...
- ファイル共有を簡単にする

「ODSC West 2023で機械学習をより良くする11の方法」
多くの企業が現在データサイエンスと機械学習を活用していますが、ROIの面ではまだ改善の余地がたくさんあります2021年のVentureBeatの分析によれば、AIモデルの87%が実稼働環境には到達しておらず、MIT Sloan Management Reviewの記事では70%という結果が示されています...

大規模言語モデル(LLM)の調査
イントロダクション 大規模言語モデル(LLM)の登場により、技術の進歩の風景は劇的に変容しました。これらのモデルは、洗練された機械学習アルゴリズムと膨大な計算能力によって駆動され、人間の言語を理解し、生成し、操作する能力を大幅に向上させるものです。LLMは微妙なニュアンスを解釈し、一貫した物語性を創造し、人間のコミュニケーションを模倣する会話を行う驚異的な能力を示しています。LLMの深い探求に乗り出すにつれて、さまざまな産業、コミュニケーションパラダイム、そして人間とコンピュータの相互作用の未来に対するその深遠な影響に直面することになります。 しかし、驚異的な可能性の中には複雑な課題の蜘蛛の巣が広がっています。LLMはその能力にもかかわらず、バイアス、倫理的な懸念、および潜在的な誤用に免疫を持ちません。これらのモデルが広範なデータセットから学習する能力は、データの出所と可能な隠れたバイアスについての疑問を呼び起こします。さらに、LLMが私たちの日常生活にますます統合されるにつれて、プライバシー、セキュリティ、透明性への懸念が極めて重要になります。さらに、LLMのコンテンツ生成と意思決定プロセスへの関与に伴う倫理的な考慮事項が注意深く検討されるべきです。 LLMの領域を探求するこの旅では、彼らの機能の複雑さ、革新の可能性、提起する課題、および責任ある開発を指針とする倫理的なフレームワークについて深く掘り下げます。このような状況を思慮深いアプローチでナビゲートすることにより、LLMの潜在能力を活用しつつ、その限界に対処することができ、最終的には言語理解と生成において人間と機械が調和して協力する未来を形作ることができます。 学習目標 LLMの基礎理解: LLMのアーキテクチャ、コンポーネント、および基礎技術を含む、LLMの基礎的な理解を得る。LLMが人間の言語を処理し生成する方法について探求する。 LLMの応用の探求: 言語理解やコンテンツ生成から言語翻訳や専門家支援まで、さまざまな産業でのLLMの応用を探求する。LLMがさまざまなセクターを変革している方法を理解する。 倫理的な考慮事項の認識: バイアス、誤情報、プライバシーの懸念を含む、LLMに関連する倫理的な考慮事項に深く入り込む。LLMの責任ある倫理的な使用を確保するためにこれらの課題にどのように対処するかを学ぶ。 LLMの影響の分析: コミュニケーション、教育、産業の風景におけるLLMの社会的および経済的な影響を検証する。LLMを生活のさまざまな側面に統合することによってもたらされる潜在的な利益と課題を評価する。 将来のトレンドとイノベーション: 対話能力、個別化体験、学際的な応用におけるLLMの進化する風景を探求する。これらの展開が技術と社会にもたらす意味を考える。 実践的な応用: コンテンツ作成、言語翻訳、データ分析などのLLMの実践的なユースケースを探求することによって、自身の知識を応用する。さまざまなタスクにおいてLLMを活用することで、実践的な経験を積む。 この記事はData Science Blogathonの一環として公開されました。 言語モデルの進化 言語モデルの軌跡は、近年の驚異的な進歩を特徴とするダイナミックな進化を経験してきました。言語処理の領域におけるこの進化の旅は、大規模言語モデル(LLM)の登場により、自然言語処理(NLP)の能力におけるパラダイムシフトを示しています。 旅は、後続のイノベーションの道を開いた初期の基本的な言語モデルから始まります。最初の段階では、言語モデルは範囲が限られており、人間の言語の複雑さを捉えるのに苦労しました。技術的な力が進化するにつれて、これらのモデルの洗練度も向上しました。初期のバージョンでは、基本的な言語ルールと統計的な手法を組み合わせてテキストを生成しましたが、文脈と一貫性に制限がありました。 しかし、ニューラルネットワークの一種であるトランスフォーマーの登場は、画期的な飛躍をもたらしました。トランスフォーマーは、文全体や段落全体の文脈的な関係を理解することを可能にします。このブレークスルーが大規模言語モデルの基盤となりました。GPT-3などのこれらのモデルは、膨大な数のパラメータを持ち、前例のない品質のテキストを処理および生成する能力を持っています。…
「データ資産のポートフォリオを構築および管理する方法」
「データ資産(または製品)−特定のユースケースのために簡単に利用できる準備済みのデータまたは情報のセット−は、データ管理の世界で話題です特定のユースケースを特定し、構築し、...」
「機械学習が間違いを comitte たとき、それはどういう意味ですか?」
「ML/AIに関する議論で、私たちの通常の「ミステイク(間違い)」の定義は意味をなすでしょうか?もしそうでない場合、なぜでしょうか?」
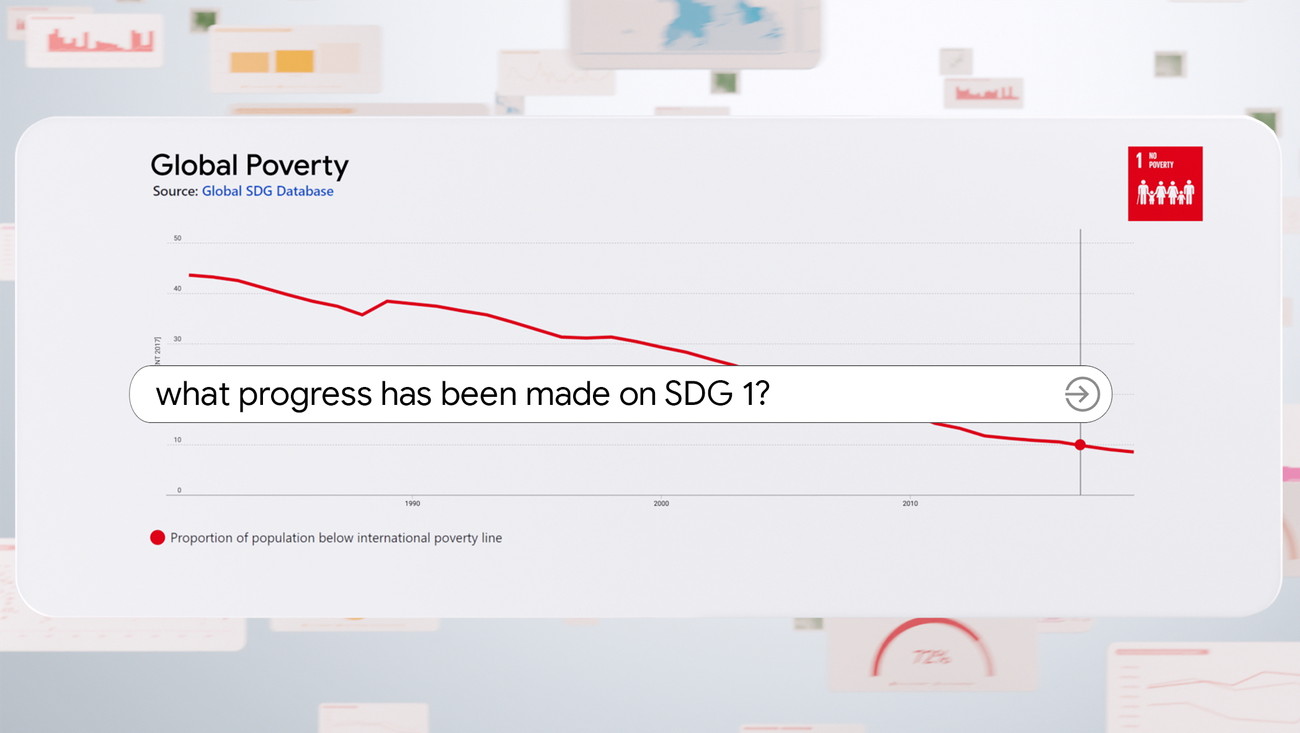
「データと人工知能を利用して、国連の持続可能な開発目標への進捗を追跡する」
「データコモンズは、SDGsへの進捗状況を追跡するために、国連とONEと協力しています」
AutoMLのジレンマ
「AutoMLは過去数年間、注目の的となってきましたそのハイプは非常に高まり、人間の機械学習の専門家を置き換えるという野心さえも持っていますしかし、長期間にわたってほとんど採用されていないという現実があります…」

「NExT-GPTを紹介します:エンドツーエンドの汎用的な任意対任意のマルチモーダル大規模言語モデル(MM-LLM)」
マルチモーダルLLMは、音声、テキスト、および視覚入力を介したより自然で直感的なユーザーとAIシステムのコミュニケーションを可能にすることで、人間とコンピュータのインタラクションを向上させることができます。これにより、チャットボット、仮想アシスタント、コンテンツ推薦システムなどのアプリケーションにおいて、より文脈に即した総合的な応答が可能となります。これらは、GPT-3などの従来の単一モーダル言語モデルの基礎を築きながら、異なるデータタイプを処理するための追加の機能を組み込んでいます。 ただし、マルチモーダルLLMは、優れたパフォーマンスを発揮するためには大量のデータが必要となり、他のAIモデルよりもサンプル効率が低くなる可能性があります。トレーニング中に異なるモダリティのデータを整合させることは困難な場合があります。エラー伝搬におけるエンドツーエンドのトレーニングが全体的に欠けているため、コンテンツの理解やマルチモーダルな生成能力は非常に限定的となることがあります。異なるモジュール間の情報伝達は、LLMによって生成される離散的なテキストに基づいて完全に行われるため、ノイズやエラーが避けられません。各モダリティからの情報が適切に同期されることは、実用的なトレーニングには不可欠です。 これらの問題に対処するために、NeXT++の研究者、School of Computing(NUS)は、NexT-GPTを構築しました。これは、テキスト、画像、動画、音声のモダリティの任意の組み合わせでの入力と出力を処理するために設計されたマルチモーダルLLMです。エンコーダは、さまざまなモダリティの入力をエンコードし、それらをLLMの表現に投影することができます。 彼らの手法は、既存のオープンソースのLLMを修正して、入力情報を処理するコアとして使用します。投影後、特定の指示を持つ生成されたマルチモーダル信号は、異なるエンコーダに送られ、最終的に対応するモダリティでコンテンツが生成されます。モデルをゼロからトレーニングするのは費用効果が低いため、既存の高性能なエンコーダとデコーダ(Q-Former、ImageBind、最先端の潜在的な拡散モデルなど)を使用します。 彼らは、LLM中心のエンコーディング側とデコーディング側の指示に従ったアライメントを効率的に実現するための軽量なアライメント学習技術を導入しました。さらに、人間レベルの機能を持つ任意のMM-LLMを実現するためのモダリティ切り替え指示チューニングも導入しています。これにより、異なるモダリティの特徴空間のギャップを埋め、他の入力の流暢な文脈理解を確保し、NExT-GPTのためのアライメント学習を行うことができます。 モダリティ切り替え指示チューニング(MosIT)は、複雑なクロスモーダルな理解と推論をサポートし、洗練されたマルチモーダルなコンテンツ生成を可能にします。彼らはさらに、多様なユーザーのインタラクションを扱い、必要な応答を正確に提供するために必要な複雑さと変動性を持つ高品質なデータセットを構築しました。 最後に、彼らの研究は、任意のMMLLMがさまざまなモダリティ間のギャップを埋め、将来的により人間らしいAIシステムの可能性を示しています。

AnomalyGPT:LVLMを使用して産業の異常を検出する
最近、LLavaやMiniGPT-4などの大規模な自然言語処理モデル(LVLMs)は、画像を理解し、いくつかの視覚的な課題で高い精度と効率を達成する能力を示していますLVLMsは、広範なトレーニングデータセットによる一般的なオブジェクトの認識に優れていますが、特定のドメイン知識を欠き、局所的な詳細に対する理解が限定されています

「プログラマーのための10の数学の概念」
「プロのプログラマになるための秘密 - 数学とそのトップ10の概念」

このAI研究は、DISC-MedLLMという包括的な解決策を提案し、大規模言語モデル(LLM)を活用して正確な医療応答を提供します
テレメディシンの台頭により、医療の提供方法が変わり、プロフェッショナルネットワークを広げ、価格を下げ、遠隔医療相談を可能にしました。さらに、知的医療システムにより、医療情報抽出、薬物推奨、自動診断、健康問い合わせなどの機能が追加され、オンライン医療サービスが改善されました。知的医療システムの構築には進歩がありましたが、これまでの研究は特定の問題や疾患に焦点を当てたものであり、実験的な開発と実世界での使用との間にはギャップがあります。このギャップを埋めるためには、さまざまな医療シナリオに対する完全なソリューションと、消費者向けの最高水準のエンドツーエンドの会話型医療サービスが必要です。 最近の大規模言語モデルは、人間と意味のある対話を行い、指示に従う驚異的な能力を示しています。これらの進展は、医療相談のシステム開発の新たな可能性を創出しました。ただし、医療相談に関わる状況は通常複雑であり、一般領域のLLMの範囲外です。図1は実世界の医療相談のイラストです。この図は2つの特性を示しています。まず、各段階で会話を理解し、適切に応答するために、詳細で信頼性のある医学知識が必要です。一般領域のLLMは、特定のケースに関連しない出力を提供し、重大な幻想の懸念が生じます。 次に、医療相談には通常、患者の健康状態に関する詳細な知識を得るために何度かの対話が必要であり、各対話ラウンドには目標があります。しかし、広範な領域のLLMは、ユーザーの健康状態の詳細に関する限定的なマルチターンのクエリング能力を持ち、シングルターンのエージェントです。これらの2つの発見に基づいて、Fudan University、Northwestern Polytechnical University、University of Torontoの研究者らは、医療LLMが徹底的で信頼性のある医学知識をエンコードし、実世界の医療会話の分布に準拠するべきだと主張しています。彼らはInstruction Tuningの成功に触発され、医療LLMのトレーニングのための高品質な監督付きファインチューニングデータセットの作成方法を調査し、医学の知識と相談行動のパターンを含めることを検討しています。 実際の実践では、彼らは3つの異なる方法を使用してサンプルを作成します: ・医学知識グラフに基づくサンプルの開発。実世界の相談データセットから収集した患者のクエリ分布に従って、部門指向のアプローチを使用して医学知識ネットワークから知識トリプルを選択します。各トリプルに対してGPT-3.5を使用してQAのペアをfew-shot作成します。その結果、50,000のサンプルが得られます。 ・実世界の対話の再構築。LLMの改善のために、医療フォーラムから収集した相談記録は適切な情報源です。これらの文書で使用される言語はカジュアルであり、専門用語は一貫して提示されず、さまざまな医療従事者によって異なる表現スタイルが使われます。そのため、実際のケースを使用してGPT-3.5を使用してディスカッションを再作成します。その結果、420,000のサンプルが得られます。 ・サンプルの収集後、人間の嗜好。さまざまな相談セッティングを網羅する実世界の医療対話記録から、限られたエントリのグループを手動で選択し、特定の例を人間の意図に合わせて書き直します。また、人間によるガイド付き再構築後の各ディスカッションの全体的な品質を保証します。その結果、2,000のサンプルが得られます。DISC-MedLLMは、13Bのパラメータを持つ一般領域の中国語LLMの上に新たに作成されたSFTデータセットを使用して、2段階のトレーニングプロセスでトレーニングされます。モデルのパフォーマンスを2つの観点から評価し、マルチターンのディスカッションでの体系的な相談能力とシングルターンの対話での正確な応答能力を確認します。 図1: 患者と実際の医師との会話の一例。医師の応答で言及される医療エンティティは青色でハイライトされています。各ラウンドでは、医師のアクションには特定の意図が示されます:(1)ラウンド1では、潜在的なシナリオを特定するのに役立つデータを収集するためにさらなる調査が行われます。(2)ラウンド2では、予備的な診断が行われ、適切なアドバイスが提供されます。(3)ラウンド3では、医療状態に応じて特定の治療選択肢が提示されます。 彼らは、3つの公開医療データセットから収集された複数選択問題のベンチマークを作成し、このベンチマークを使用してモデルの正確性を単一ターンの評価について評価します。マルチターンのレビューのために、まずGPT-3.5を使用して優れたコンサルテーションケースの小さなコレクションを作成し、患者をシミュレートしてモデルと対話します。GPT-4を使用して、モデルの積極性、正確性、助けになる度、および言語的品質を評価します。実験結果は、DISCMedLLMがGPT-3.5に劣るものの、同じパラメータを持つ医療大規模HuatuoGPTよりも平均10%以上優れていることを示しています。 さらに、DISC-MedLLMは、GPT-3.5、HuatuoGPT、BianQueなどのベースラインモデルよりも、シミュレートされた医療相談設定全体で優れたパフォーマンスを発揮します。特に医療部門と患者の意図が関わるケースでは、DISC-MedLLMは他の中国の医療LLMに比べて優れた結果を出します。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.