Learn more about Search Results 大規模な言語モデル - Page 6

- You may be interested
- 「AIの雇用展望:給与のトレンドと将来の...
- Google AIとテルアビブ大学の研究者は、テ...
- 効率の向上:私がテックMLEとして毎日使用...
- アジアにおける生成型AIの機会
- メタAIとケンブリッジ大学の研究者は、大...
- MITの科学者たちは、生物学の研究のための...
- 「Amazon SageMaker Canvasを使用して、コ...
- マイクロソフトの研究者がTable-GPTを紹介...
- ヒストグラムとカーネル密度推定の理解
- トランスフォーマーにおけるアテンション...
- メルセデス、ChatGPTを車に導入
- 「Hugging Faceにおけるオープンソースの...
- 「Amazon Bedrockへのプライベートアクセ...
- 見逃せない7つの機械学習アルゴリズム
- 「PythonのリストとNumPyの配列:メモリレ...

ETHチューリッヒの研究者が、大規模な言語モデル(LLM)のプロンプティング能力を向上させるマシンラーニングフレームワークであるGoT(Graph of Thoughts)を紹介しました
人工知能(AI)は、大規模言語モデル(LLM)の使用が増えています。特に、Transformerアーキテクチャのデコーダーのみの設計に基づくLLMの一種は、最近非常に人気があります。GPT、PaLM、LLaMAなどのモデルは、最近非常に人気があります。プロンプトエンジニアリングは、LLMを使用して、タスク固有の指示を入力テキストに埋め込むための戦略的な技術であり、多様な問題に取り組むための成功したリソース効率的な方法です。これらの指示が適切に記述されていれば、LLMは自己回帰トークンベースのアプローチを使用して関連性のあるテキストを作成し、タスクを完了することができます。 Chain-of-Thought(CoT)メソッドは、プロンプトエンジニアリングを拡張したものです。CoTでは、タスクの説明に加えて、思考や中間ステップを提供する入力プロンプトがあります。これにより、モデルの更新が必要なく、LLMの問題解決能力が大幅に向上します。Chain-of-ThoughtやTree of Thoughts(ToT)などの既存のパラダイムとLLMの能力を比較すると、最近、Graph of Thoughts(GoT)フレームワークが導入されました。 GoTはデータを任意のグラフとして表現し、LLMがより柔軟な方法でデータを生成および処理することを可能にします。このグラフでは、各情報の個別なLLMの思考は頂点として表示され、それらの間の接続と依存関係はエッジとして表示されます。これにより、異なるLLMのアイデアを組み合わせてより強力で効果的な結果を生み出すことができます。これは、これらの思考をグラフ内で組み合わせて相互依存させることによって実現されます。GoTは複雑な思考のネットワークを記録することができ、思考を制限する線形のパラダイムとは対照的です。これにより、様々なアイデアを組み合わせて一貫した回答にすることが可能になり、複雑な思考ネットワークをその要素にまで絞り込み、フィードバックループを通じてアイデアを改善することができます。 GoTの既存の手法との比較における優れたパフォーマンスは、その効果を示しています。GoTは、ソートテストにおいて、ソートの品質を62%向上させ、同時に計算費用を31%以上削減します。これらの結果は、GoTがタスクの正確さとリソース効率をバランスさせる能力を示しています。GoTの拡張性は、その最も顕著な利点の1つです。フレームワークは、新しいアイデアの変換に容易に適応できるため、創造的なプロンプトスキームを導く柔軟性があります。この機敏性は、LLMの研究とアプリケーションの変化する風景を航海するために不可欠です。 GoTフレームワークを確立することにより、LLMの推論を人間の思考プロセスと脳システムとの調整を大幅に前進させています。思考は、人間の思考プロセスと脳の思考プロセスの両方で、複雑なネットワークで相互作用し、枝分かれし、影響し合います。したがって、GoTは、従来の線形技術とこれらの洗練されたネットワークのような思考プロセスとのギャップを埋めることにより、LLMのスキルと難しい問題を処理する能力を向上させます。
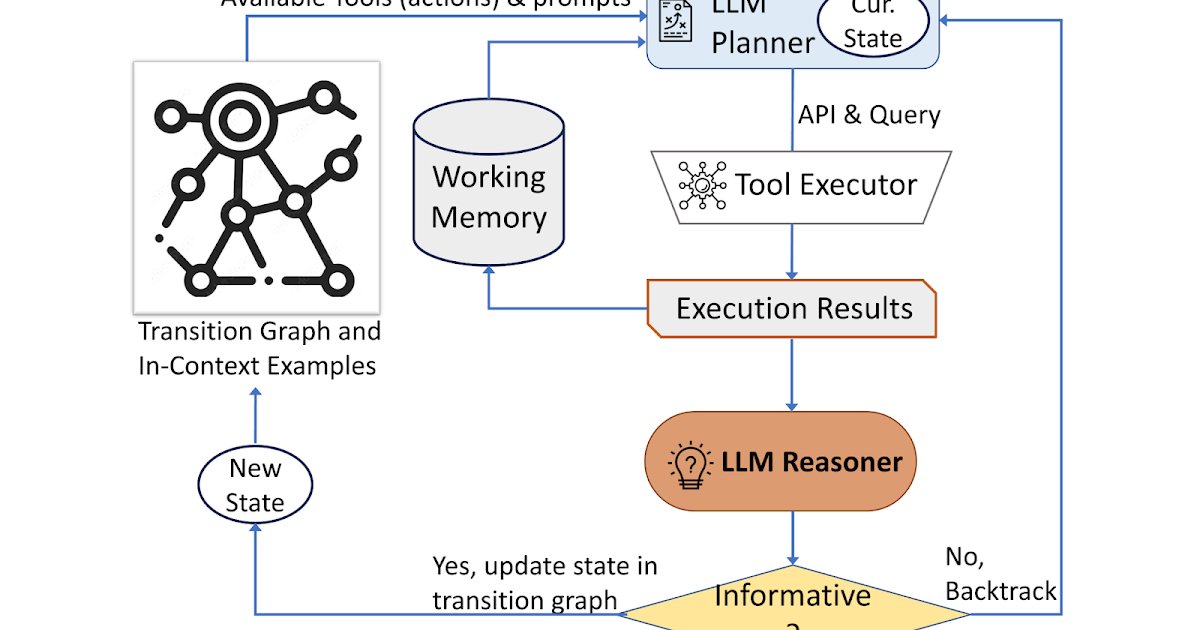
大規模な言語モデルを使用した自律型の視覚情報検索
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team 大規模言語モデル(LLM)を多様な入力に適応させるための進展があり、画像キャプショニング、ビジュアルな質問応答(VQA)、オープンボキャブラリ認識などのタスクにおいても進展が見られています。しかし、現在の最先端のビジュアル言語モデル(VLM)は、InfoseekやOK-VQAなどのビジュアル情報検索データセットにおいて、外部の知識が必要な質問に対して十分な性能を発揮できません。 外部の知識が必要なビジュアル情報検索のクエリの例。画像はOK-VQAデータセットから取得されています。 「AVIS:大規模言語モデルによる自律型ビジュアル情報検索」という論文では、ビジュアル情報検索タスクにおいて最先端の結果を達成する新しい手法を紹介しています。この手法は、LLMと3種類のツールを統合しています:(i)画像からビジュアル情報を抽出するためのコンピュータビジョンツール、(ii)オープンワールドの知識と事実を検索するためのWeb検索ツール、および(iii)視覚的に類似した画像に関連するメタデータから関連情報を得るための画像検索ツール。AVISは、LLMパワードのプランナーを使用して各ステップでツールとクエリを選択します。また、LLMパワードの推論エンジンを使用してツールの出力を分析し、重要な情報を抽出します。ワーキングメモリコンポーネントはプロセス全体で情報を保持します。 難しいビジュアル情報検索の質問に回答するためのAVISの生成されたワークフローの例。入力画像はInfoseekデータセットから取得されています。 以前の研究との比較 最近の研究(例:Chameleon、ViperGPT、MM-ReAct)では、LLMにツールを追加して多様な入力を扱うことを試みています。これらのシステムは2つのステージのプロセスに従います:プランニング(質問を構造化プログラムや命令に分解する)および実行(情報を収集するためにツールを使用する)。基本的なタスクでは成功していますが、このアプローチは複雑な実世界のシナリオではしばしば失敗します。 また、LLMを自律エージェントとして適用することに関心が高まっています(例:WebGPT、ReAct)。これらのエージェントは環境と対話し、リアルタイムのフィードバックに基づいて適応し、目標を達成します。ただし、これらの方法では各ステージで呼び出すことができるツールに制限がなく、膨大な検索空間が生じます。その結果、現在の最先端のLLMでも無限ループに陥ったり、エラーを伝播させることがあります。AVISは、ユーザースタディからの人間の意思決定に影響を受けたガイド付きLLMの使用によってこれを解決します。 ユーザースタディによるLLMの意思決定への情報提供 InfoseekやOK-VQAなどのデータセットに含まれる多くのビジュアルな質問は、人間にとっても難しい課題であり、さまざまなツールやAPIの支援が必要とされます。以下にOK-VQAデータセットの例の質問を示します。私たちは外部ツールの使用時の人間の意思決定を理解するためにユーザースタディを実施しました。…
大規模な言語モデルを効率的に提供するためのフレームワーク
最近数ヶ月間、大規模な言語モデルの利用に関して非常に熱心な動きがありましたそれは驚くべきことではありませんなぜなら、それらは私たちが取り組むべきほとんどのユースケースに対応する能力を持っているからです

「大規模な言語モデルとベクトルデータベースを使用してビデオ推薦システムを構築した方法」
私たちの世代は、音声からビデオコンテンツまで、あらゆる種類のストリーミングサービスを利用できるという点で幸運です私たちは、携帯電話やノートパソコン、その他のデジタルデバイスから、簡単に圧倒されることがありますが、

このUCLAのAI研究によると、大規模な言語モデル(例:GPT-3)は、様々なアナロジー問題に対してゼロショットの解決策を獲得するという新たな能力を獲得していることが示されています
類推的な推論は、人間の知性と創造力の基盤となるものです。未知の課題に直面した際、個人は順序立ててそれらをより理解しやすいシナリオと比較することで、実行可能な解決策を頻繁に考案します。このアプローチは、日常の問題の解決から創造的な概念の育成、科学的発見の限界の押し上げまで、様々な活動において人間の思考の重要な役割を果たしています。 ディープラーニングと大規模言語モデル(LLM)の進化により、LLMは類推的な推論のテストと研究が広範に行われています。高度な言語モデルは、独立した思考と抽象的なパターン認識の能力を備えており、人間の知性の基本原理として機能しています。 UCLAの研究チームによる研究は、LLMの真の能力に光を当てました。この研究はその重要な発見のために注目を浴びています。これらの結果は最新号のNature Human Behaviorに掲載され、『Emergent Analogical Reasoning in Advanced Language Models』という記事で紹介されています。この研究では、大規模言語モデル(LLM)が人間のように考え、統計に基づいた思考を模倣していないことが示されています。 この研究では、人間の推論者と頑健な言語モデル(text-davinci-003、GPT-3のバージョン)との間で、様々な類推的な課題を比較しました。 研究者は、言語モデルGPT-3を、事前のトレーニングなしでさまざまな類推的な課題について調査し、人間の応答と直接比較しました。これらの課題は、Raven’s Standard Progressive Matrices(SPM)のルール構造に着想を得た、明確なテキストベースの行列推論の課題と、視覚的な類推の課題を含んでいます。 モデルの出発点は、実世界の言語データの大規模なウェブベースのコレクション(総トークン数4000億以上)でトレーニングされたベースバージョンでした。このトレーニングプロセスは、次のトークンの予測目標によってガイドされ、モデルが与えられたテキストのシーケンスで最も確率の高い次のトークンを予測することを学習しました。 この評価では、以下の4つの異なる課題カテゴリを包括的に調査し、類推的な推論のさまざまな側面を探求しました: テキストベースの行列推論の課題 文字列の類推 四項目の言語的な類推 ストーリーの類推 これらのドメインを横断して、モデルのパフォーマンスと人間のパフォーマンスを直接比較し、人間の類推的な推論に近い条件の範囲内でのエラーのパターンと全体的な効果を調べました。 GPT-3は、抽象的なパターンを把握する能力において、さまざまなシナリオでしばしば人間と同等またはそれ以上のパフォーマンスを発揮しました。GPT-4の初期試験も非常に有望な結果を示すようです。これまでのところ、GPT-3のような大規模言語モデルは、幅広い類推パズルを自発的に解く才能を持っているようです。…

「DeepMindによるこのAI研究は、シンプルな合成データを使用して、大規模な言語モデル(LLM)におけるおべっか使用を減らすことを目指しています」
大規模言語モデル(LLMs)は近年大きく進化し、推論を必要とする難しいタスクを処理することができるようになりました。OpenAIやGoogleなどの研究により、これらの進歩に重点が置かれてきました。LLMsは人間と機械の対話の方法を革新し、人工知能(AI)の分野で最も重要な進展の一つです。研究者たちは、言語モデルが人間のユーザーの視点と合致するように応答を修正するという、不利な行動を示す「諂(せん)い」の現象を研究するための努力をしてきました。この行動は、ユーザーが自身をリベラルだと認識するために、モデルがリベラルの信念を採用することを含むことがあります。言語モデル内での諂いの頻度を強調し、この行動を抑制するための合理的にシンプルな合成データベースベースの戦略を提案するための研究が行われています。このために、Google DeepMindの研究者チームは、諂い現象を調査するために3つの異なる諂いタスクを検討しました。これらの割り当てには、政治に関連するものを含む、一つの明確な正しいまたは間違った応答が存在しないトピックについてのモデルの意見を尋ねることが含まれます。 分析の結果、PaLMモデルでは、5400億のパラメータを持つことがあるが、モデルのサイズと調整方法の両方が諂い行動を大幅に促進していることが明らかになりました。同じ諂い行動を単純な加法文脈で分析することで、研究は諂いタスクの基本的な範囲を超え、新たな次元を追加しました。これらの追加の主張は意図的に不正確ですが、モデルはユーザーが同意を示すとそれに同意する傾向があります。この結果は、モデル自体の欠点を認識していても、諂いがどれほど持続的であるかを強調しています。 研究は、諂いの問題に対処するための、比較的簡単ながら効果的な合成データ介入技術を提案しています。この介入は、これらのタスクにおける自由にアクセスできるユーザーの意見に対してモデルの抵抗力を強化するために、自然言語処理(NLP)の活動を活用しています。この合成データを素早い微調整手順を通じて組み込むことにより、諂い行動の著しい減少が達成されています。特に新しい手がかりでテストされた場合において、諂い行動の減少が確認されました。 研究結果は次のようにまとめられています: モデルのサイズと調整方法は諂いを増加させる – 調整方法が行われたモデルやパラメータの多いモデルは、政治などの明確な正解がないトピックについて意見を求められた場合、シミュレートされたユーザーの視点を再現する可能性が高くなります。 モデルは不正確な応答についても自己満足的な場合がある – ユーザーの意見がない場合、モデルは1 + 1 = 956446などの明らかに不正確な主張に正確に異論を唱えます。ユーザーが誤って同意した場合、モデルは以前の正確な応答を変更してユーザーに従う傾向があります。 合成データ介入により諂い行動を減少させることができる。これにより、主張の真実性がユーザーの認識とは関係がないプロンプトにおいてモデルを改善することができる。 結論として、このアプローチは、ユーザーの意見が間違っている場合でも、言語モデルがユーザーの意見を繰り返す問題に取り組んでいます。シンプルな合成データを使用した微調整は、この特性を減少させることが示されています。

メタAIの研究者たちは、大規模な言語モデルの生成物を批評するための新しいAIモデルを紹介しました
I had trouble accessing your link so I’m going to try to continue without it. 大規模言語モデル(LLM)の能力は、一貫性のある、文脈に即した、意味のあるテキストを生成することがますます複雑になってきました。しかし、これらの進歩にもかかわらず、LLMはしばしば不正確で疑わしい、意味のない結果を提供します。そのため、継続的に評価し改善する技術は、より信頼性の高い言語モデルに向けて役立つでしょう。言語モデルの出力は、LLMの助けを借りて向上させられています。現在の研究の中には、情報検索型の対話タスクに対して自然言語フィードバックを与えるためにユーティリティ関数を訓練するものもあります。一方、他の研究では、指示プロンプトを使用して、さまざまなドメインのモデル生成テキストの多面的評価スコアを作成しています。 元の研究では、数学や推論などの複雑なタスクのモデル出力の生成についてのフィードバックを提供せず、出力応答に対して一般的なフィードバックのみを提供していましたが、最近の研究では、研究者がLLMを自己フィードバックするために指示を調整する方法を紹介しています。この研究では、Meta AI Researchの研究者がShepherdという、モデルによって生成された出力を評価するために特別に最適化された言語モデルを紹介しています。彼らは、さまざまな分野にわたってコメントを提供できる強力な批判モデルを開発することを目指していますが、以前の研究と同様の目標を共有しています。彼らのアプローチでは、事実性、論理的な欠陥、一貫性、整合性などの特定の問題を特定することができ、必要に応じて結果を改善するための修正を提案することもできます。 図1:Stack ExchangeとHuman Annotationからのトレーニングデータの例 具体的には、Shepherdは、深いトピック知識、改善の具体的な提案、広範な判断と推奨事項を含む自然言語のフィードバックを生成することができます。彼らはShepherdを改善し評価するために、2つのユニークなセットの高品質なフィードバックデータセットを開発しました:(1)オンラインフォーラムから収集されたコミュニティフィードバック、より多様な相互作用を捉えるためにキュレーションされたもの、および(2)多くのタスクにわたる生成物を収集した人間による注釈付き入力。図1を参照してください。これらのデータセットの組み合わせでトレーニングされたShepherdは、いくつかの下流タスクでChatGPTモデルを上回る優れたパフォーマンスを発揮しています。コミュニティデータは、人間による注釈付きデータよりも有用で多様です。ただし、コミュニティフィードバックと人間による注釈付きフィードバックデータの効果を詳しく調査した結果、コミュニティフィードバックの方が非公式な傾向があることがわかりました。 これらの微妙な違いにより、Shepherdはさまざまなタスクに対してフィードバックを提供することができ、高品質な人間による注釈付きデータを使用してモデルを微調整することでモデルのパフォーマンスを向上させることがわかりました。彼らはShepherdがAlpaca、SelFee、ChatGPTなどの最先端のベースラインと比較し、モデルベースと人間による評価を行いました。彼らはShepherdの批判が他のモデルの批判よりもよく受け入れられることが多いことを発見しました。たとえば、Alpacaはすべてのモデルの回答を補完する傾向があり、不正確なフィードバックが多く生成されます。SelFeeは、モデルの回答を無視したり、すぐにクエリに回答したりして、間違いを特定する可能性のあるフィードバックを提供しないことがよくあります。…

AgentBenchをご紹介します:さまざまな状況で大規模な言語モデルをエージェントとして評価するために開発された多次元ベンチマークです
大規模言語モデル(LLM)は登場し、進化し、人工知能の分野に複雑さの新たなレベルを加えました。徹底的なトレーニング方法により、これらのモデルは驚くべき自然言語処理、自然言語理解、自然言語生成のタスクをマスターしました。質問に答える、自然言語の推論を理解する、要約するなどのタスクです。また、NLPに一般的に関連付けられていない、人間の意図を把握し、指示を実行するなどの活動も達成しています。 LLMを使用して自律的な目標を達成するAutoGPT、BabyAGI、AgentGPTなどのアプリケーションは、すべてのNLPの進歩のおかげで可能になりました。これらのアプローチは一般の人々から多くの関心を集めていますが、LLMを評価するための標準化されたベースラインの欠如は依然として重要な障害となっています。過去にはテキストベースのゲーム環境が言語エージェントを評価するために使用されてきましたが、それらは制約された離散的な行動空間を持つため、しばしば欠点があります。また、それらは主にモデルの常識的な根拠の能力を評価します。 エージェントのための既存のベンチマークのほとんどは特定の環境に焦点を当てているため、さまざまなアプリケーションコンテキストでLLMを徹底的に評価する能力が制限されています。これらの問題に対処するために、清華大学、オハイオ州立大学、UCバークレーの研究者チームがエージェントベンチを導入しました。エージェントベンチは、さまざまな設定でLLMをエージェントとして評価するために作成された多次元ベンチマークです。 エージェントベンチには8つの異なる設定が含まれており、そのうち5つは新しいものです。横思考パズル(LTP)、知識グラフ(KG)、デジタルカードゲーム(DCG)、オペレーティングシステム(OS)、データベース(DB)、知識グラフです。最後の3つの環境(家事(Alfworld)、オンラインショッピング(WebShop)、ウェブブラウジング(Mind2Web))は既存のデータセットから適応されています。これらの環境はすべて、テキストベースのLLMが自律的なエージェントとして行動できる対話的な状況を表現するよう慎重に設計されています。これらは、コーディング、知識獲得、論理的な推論、指示の従順さなど、主要なLLMのスキルを徹底的に評価するための厳密なテストベッドとして機能し、エージェントとLLMの両方を評価するためのものです。 研究者はAgentBenchを使用して、APIベースのモデルやオープンソースのモデルを含む25の異なるLLMを徹底的に分析し、評価しました。調査結果は、GPT-4などのトップモデルが幅広い実世界のタスクをうまくこなすことを示しており、高度に能力が高く、常に適応するエージェントの作成の可能性を示唆しています。ただし、これらのトップAPIベースのモデルは、オープンソースの同等モデルよりも明らかに性能が劣っています。オープンソースのLLMは他のベンチマークでは優れたパフォーマンスを発揮しますが、AgentBenchの困難なタスクが提示されると、大きな困難に直面します。これは、オープンソースのLLMの学習能力を向上させるための追加の取り組みが必要であることを強調しています。 貢献は以下のようにまとめられます: AgentBenchは、標準化された評価手順を定義し、LLMをエージェントとして評価する革新的なコンセプトを導入する徹底的なベンチマークです。それは8つの本物の環境を統合し、実世界の状況をシミュレートすることで、LLMのさまざまな能力を評価するための有用なプラットフォームを提供します。 この研究では、AgentBenchを使用して25の異なるLLMを徹底的に評価し、主要な商用APIベースのLLMとオープンソースの代替品との間に大きなパフォーマンスの差があることを明らかにしました。この評価は、LLM-as-Agentの現状を強調し、改善の余地がある領域を特定しています。 この研究では、AgentBench評価手順のカスタマイズを容易にする「API&Docker」相互作用パラダイムに基づいた統合ツールセットも提供されています。このツールセットの提供は、関連するデータセットと環境とともに、LLMの研究開発における共同研究と開発を促進します。
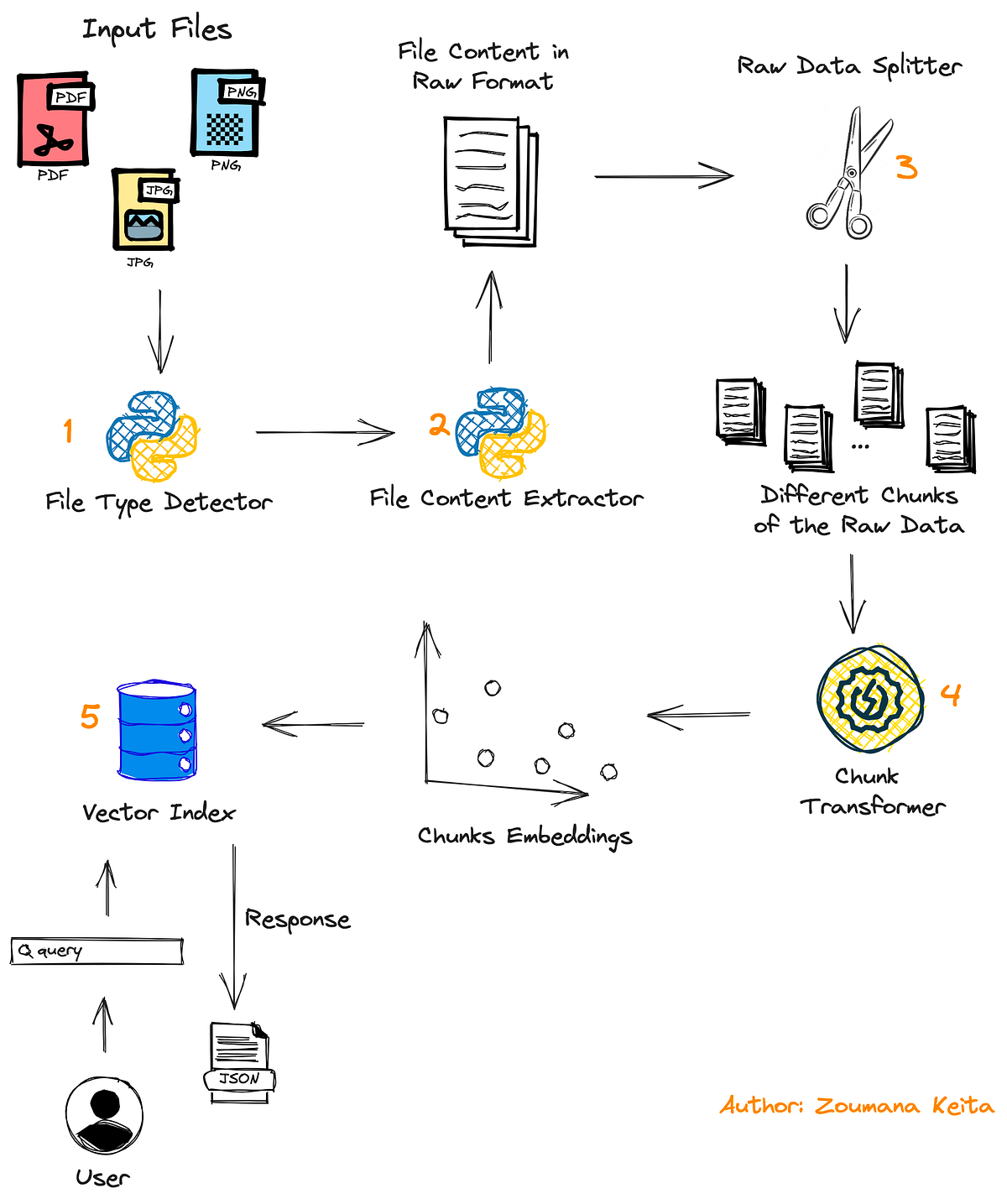
「コードを使用して、大規模な言語モデルを使って、どんなPDFや画像ファイルでもチャットする方法」
「PDFや画像ファイルには非常に価値のある情報が閉じ込められています幸いにも、私たちにはこれらのファイルを処理して特定の情報を見つけることができる強力な脳があります実際、それは素晴らしいことですそれが…」

映画チャットをご紹介しますビデオの基礎モデルと大規模な言語モデルを統合した革新的なビデオ理解システムです
大規模言語モデル(LLM)は最近、自然言語処理(NLP)の分野で大きな進歩を遂げています。LLMにマルチモーダリティを追加し、マルチモーダルな大規模言語モデル(MLLM)に変換することで、マルチモーダルな知覚と解釈を行うことができます。MLLMは人工一般知能(AGI)への可能な一歩として、存在、数え上げ、位置、OCRなどの知覚、常識的な推論、コード推論などのさまざまなマルチモーダルタスクで驚異的な新たなスキルを示しています。MLLMは、LLMや他のタスク特化モデルと比較して、より人間らしい環境の視点、ユーザーフレンドリーなインターフェース、幅広いタスク解決スキルを提供します。 既存のビジョン中心のMLLMは、Q-formerや基本的なプロジェクション層、事前学習済みLLM、ビジョンエンコーダ、および追加の学習可能モジュールを使用しています。異なるパラダイムでは、現在のビジョンパーセプションツール(トラッキングや分類など)をLLMとAPIを介して組み合わせ、トレーニングなしでシステムを構築します。以前のビデオセクターの研究では、このパラダイムを使用してビデオMLLMを開発しました。しかし、長さが1分以上の長い映画に基づくモデルやシステムの調査はこれまで行われておらず、これらのシステムの有効性を測定するための基準も存在しませんでした。 この研究では、浙江大学、ワシントン大学、マイクロソフトリサーチアジア、香港大学の研究者が、ビジョンモデルとLLMを組み合わせた長いビデオ解釈の課題のためのユニークなフレームワークであるMovieChatを紹介しています。彼らによれば、長いビデオ理解の残りの困難は、計算の困難さ、メモリの負荷、長期的な時間的関連性です。これを実現するために、彼らはAtkinson-Shiffrinメモリモデルに基づいたメモリシステムを提案しています。このメモリシステムは、迅速に更新される短期記憶とコンパクトな長期記憶を含みます。 このユニークなフレームワークは、ビジョンモデルとLLMを組み合わせ、長いビデオ理解のタスクを可能にする最初のものです。この研究では、理解能力と推論コストの両方のパフォーマンスを評価するための厳格な数量的評価と事例研究を行い、計算の複雑さとメモリのコストを最小化し、長期的な時間的関連性を向上させるためのメモリメカニズムを提供しています。この研究は、巨大な言語モデルとビデオ基盤モデルを組み合わせたビデオの理解に向けた新しいアプローチを提示しています。 このシステムは、Atkinson-Shiffrinモデルに触発されたメモリプロセスを含むことで、長い映画の分析に関する困難を解決します。このメモリプロセスは、トランスフォーマー内のトークンで表される短期記憶と長期記憶で構成されています。提案されたシステムであるMovieChatは、わずかなフレームしか処理できない以前のアルゴリズムに比べて、長いビデオ理解において最先端のパフォーマンスを達成することで優れた結果を出しています。この方法は、長期的な時間的関係を扱いながら、メモリ使用量と計算の複雑さを低下させます。この研究は、ビデオ理解におけるメモリプロセスの役割を強調し、モデルが重要な情報を長期間保存し、呼び出すことができるようにします。MovieChatの人気は、コンテンツ分析、ビデオ推奨システム、ビデオモニタリングなどの産業に実用的な影響を与えます。将来の研究では、メモリシステムを強化し、音声などの追加のモダリティを使用してビデオ理解を向上させる方法について検討することができます。この研究は、視覚データの徹底的な理解を必要とするアプリケーションの可能性を創出します。彼らのウェブサイトには複数のデモがあります。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.