Learn more about Search Results 勾配降下法 - Page 6

- You may be interested
- このAIニュースレターはあなたが必要なす...
- A. Michael West 医療現場における人間と...
- 「Googleは、ヘルスケアとライフサイエン...
- NVIDIAリサーチがCVPRで自律走行チャレン...
- AI導入の迷宮を進む
- 「研究者がWindows Helloの実装に脆弱性を...
- 「コンテキストに基づくドキュメント検索...
- Nvidiaは、エンジニア向けに生成AIを試験...
- 本番環境向けのベクトル検索の構築
- Megatron-LMを使用して言語モデルをトレー...
- 「AIを活用したポッドキャストの始め方と...
- 「AIの利用者と小規模事業者を保護するた...
- 「品質と信頼性のためのPythonコードのユ...
- 商品化されたサービス101:フリーランサー...
- 学校でのAI教育の台頭:現実と未来の可能...

「ゼロからヒーローへ:PyTorchで最初のMLモデルを作ろう」
PyTorchの基礎を学びながら、ゼロから分類モデルを構築してください
Fast.AIディープラーニングコースからの7つの教訓
「最近、Fast.AIのPractical Deep Learning Courseを修了しましたこれまでに多くの機械学習コースを受講してきましたので、比較することができますこのコースは間違いなく最も実践的でインスピレーションを受けるものの一つですですので…」

「Appleの研究者たちは、暗黙的なフィードバックを持つ協調フィルタリングのための新しいテンソル分解モデルを提案する」
過去の行動からユーザーの好みを推測する能力は、効果的な個別の提案にとって重要です。多くの製品には星の評価がないため、このタスクは指数関数的に困難になります。過去の行動は一般的にバイナリ形式で解釈され、ユーザーが過去に特定のオブジェクトと対話したかどうかを示します。このバイナリデータに基づいて、そのような秘匿的な入力からユーザーの好みを推測するために、追加の仮定をする必要があります。 視聴者は、関与したコンテンツを楽しんでおり、注意を引かなかったコンテンツは無視しているという仮定は、実際の使用ではめったに正確ではありません。消費者が製品と関わっていないのは、それが存在すら知らないためかもしれません。したがって、ユーザーが単に対話できない要素については無視または関心を持っていないと仮定するのがより妥当です。 研究では、既に馴染みのある製品を未知の製品よりも好む傾向があると仮定しました。この考えは、個別の推奨を行うための技術であるベイジアン個別ランキング(BPR)の基礎となりました。BPRでは、データはユーザーを表す最初の次元を持つ3次元のバイナリテンソルDに変換されます。 新しいAppleの研究では、推移性に依存しない人気のある基本的な製品の評価(BPR)モデルの変種を作成しました。一般化のために、彼らは代替テンソル分解を提案しています。彼らはスライス反対称分解(SAD)という新しい暗黙のフィードバックベースの協調フィルタリングモデルを導入します。ユーザーとアイテムの相互作用の新しい三次元テンソルの視点を使用して、SADは通常の方法とは異なり、各アイテムに1つの潜在ベクトルを追加します(アイテムベクトルとしての潜在表現を推定する従来の方法とは異なります)。相対的な優先順位を評価する際にアイテム間の相互作用を生成するため、この新しいベクトルは通常の内積によって導かれる好みを一般化します。ベクトルが1に収束すると、SADは最新の協調フィルタリングモデル(SOTA)となります。この研究では、その値をデータから決定することを許可しています。新しいアイテムベクトルの値が1を超えることを許可すると、非常に重要な結果が生じます。対比の中にサイクルが存在することは、ユーザーのメンタルモデルが線形ではないことを示す証拠と解釈されます。 チームはSADパラメータ推定のためのクイックなグループ座標降下法を提案しています。シンプルな確率的勾配降下法(SGD)を使用して、正確なパラメータ推定を迅速に行います。シミュレーション研究を使用して、まずSGDの効果とSADの表現力を実証します。そして、利用可能なリソースのトリオを使用して、SADを他の7つの代替の最新の推奨モデルと比較します。この研究では、以前無視されていたデータとエンティティ間の関係を組み込むことで、更新されたモデルがより信頼性の高い正確な結果を提供することも示しています。 この研究では、研究者は協調フィルタリングを暗黙のフィードバックとして参照しています。ただし、SADの応用範囲は前述のデータタイプに限定されません。たとえば、明示的な評価が含まれるデータセットは、現在のモデルの一貫性を事後評価するのではなく、モデルの適合中に直ちに使用できる部分順序を含んでいます。
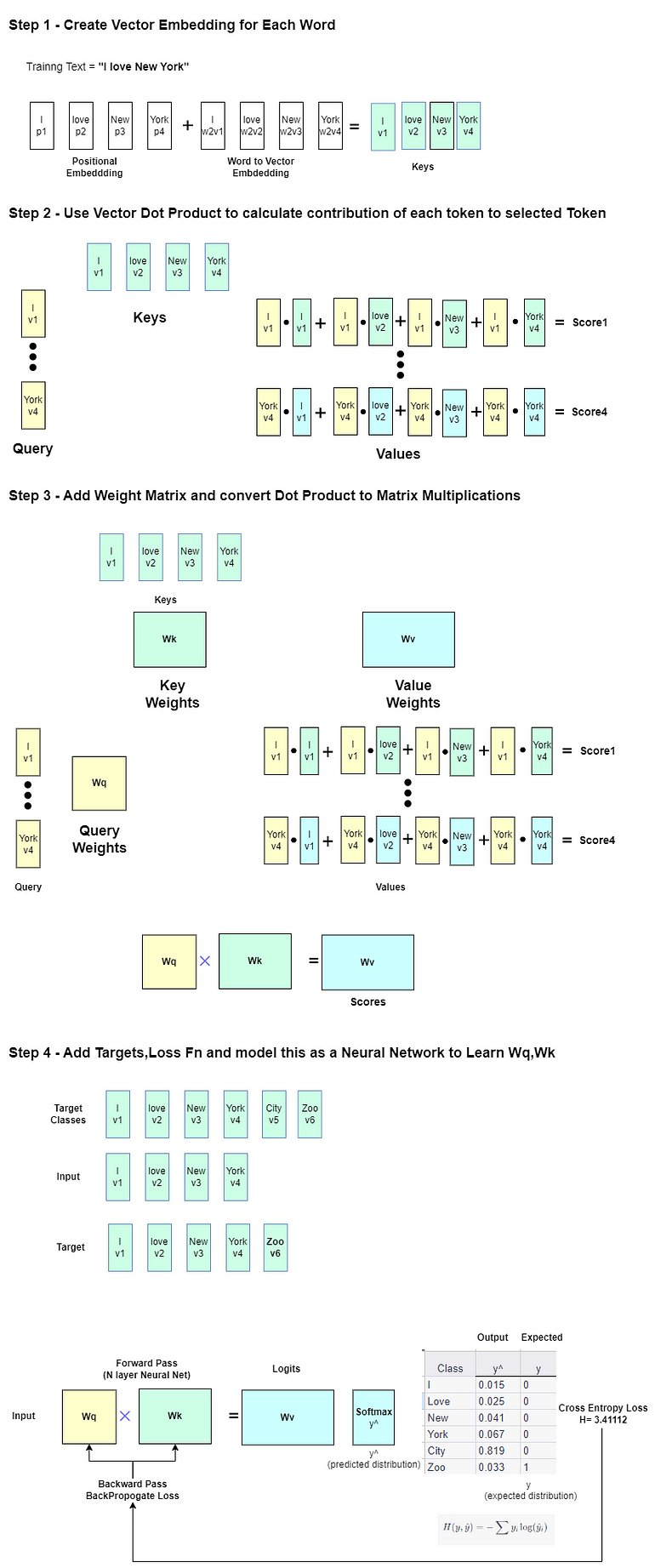
大規模言語モデルの探索 -Part 1
この記事は主に自己学習のために書かれていますそのため、広範囲かつ深い内容です興味のあるセクションをスキップしたり、自分が興味を持っている分野を探求するために、自由に特定のセクションをスキップしてください以下にいくつかの…

データサイエンティストになりたいですか?パート1:必要な10つのハードスキル
「データサイエンティストになるために必要なハードスキルを10ステップで解説します」

「ハイパーパラメータのチューニングに関する包括的なガイド:高度な手法の探索」
機械学習において、ハイパーパラメータの調整はモデルの性能を向上させるために不可欠ですさまざまな高度な調整手法について探求しましょう

「価格最適化の技術を習得する — データサイエンスのソリューション」
価格設定はビジネスの世界で非常に重要な役割を果たします売上とマージンのバランスをとることは、どんなビジネスにおいても成功するために非常に重要ですデータサイエンスの方法でどのようにそれを行うことができるのでしょうか?
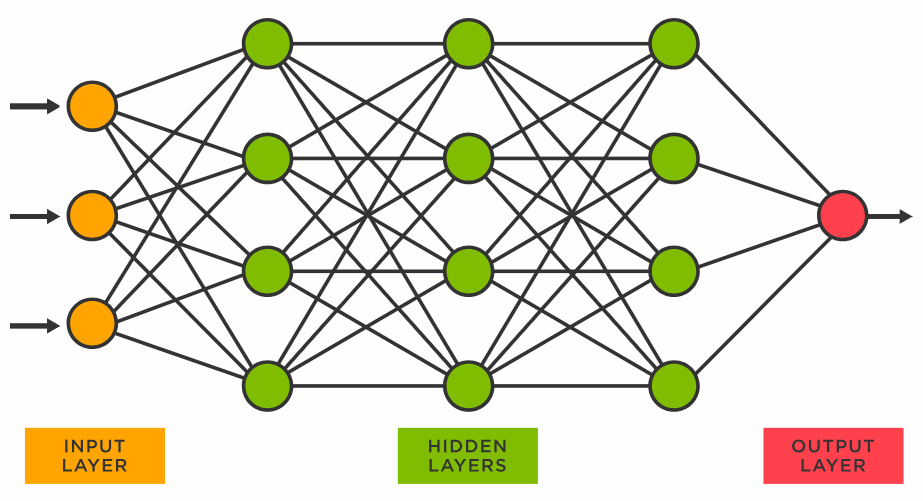
「ChatGPTのようなLLMの背後にある概念についての直感を構築する-パート1-ニューラルネットワーク、トランスフォーマ、事前学習、およびファインチューニング」
「たぶん私だけじゃないと思いますが、1月のツイートで明らかになっていなかったとしても、私は最初にChatGPTに出会ったときに完全に驚きましたその体験は他のどんなものとも違いました…」

「インクリメンタルラーニング:メリット、実装、課題」
インクリメンタルラーニングは、学術界における動的なアプローチを表しており、徐々で一貫した知識の吸収を促しています。学習者に大量の情報を押し付ける従来の方法とは異なり、インクリメンタルラーニングは複雑な主題を管理可能な断片に分解します。機械学習においては、インクリメンタルなアプローチによりAIモデルを新しい知識を段階的に吸収するように訓練します。これにより、モデルは既存の理解を保持・強化し、持続的な進歩の基盤を形成します。 インクリメンタルラーニングとは何ですか? インクリメンタルラーニングは、新しいデータを小さな管理可能な増分で徐々に導入することによって、年々知識を蓄積していく教育的なアプローチです。すべてを即座に学ぼうとするのではなく、インクリメンタルラーニングは複雑なトピックを小さなチャンクに分割します。このアプローチは、スペースドリペティション(間隔をあけた反復)、定期的な復習、以前に学んだ概念の強化を重視し、理解力、記憶力、主題の長期的な習得を共に向上させます。 インクリメンタルラーニングでは、AIモデルは以前に獲得した情報を忘れずに知識を徐々に向上させます。したがって、これは人間の学習パターンを模倣しています。この学習は、データの入力が順序立てて行われる場合やすべてのデータの保存が実現不可能な場合に重要です。 インクリメンタルラーニングの利点 メモリの強化、リソースの効率的な利用、リアルタイムの変化への適応、または学習をより管理可能な旅にするために、インクリメンタルラーニングは幅広い魅力的な利点を提供します: 記憶力の向上:以前に学んだ素材を再訪し、積み重ねることにより、インクリメンタルラーニングは記憶力を向上させ、知識を年々確固たるものにします。 リソースの効率的な利用:インクリメンタルラーニングモデルは一度に少ないデータを保存する必要があるため、メモリの節約に役立ちます。 リアルタイムの適応:インクリメンタルラーニングモデルはリアルタイムの変化に適応する能力を持っています。たとえば、製品推薦システムはユーザーの好みを学習し、関連する興味を引く製品を推奨します。 効率的な学習:タスクを小さなパートに分割することにより、インクリメンタルラーニングはMLモデルの新しいタスクへの学習能力を迅速に向上させ、精度を向上させます。 持続可能な学習習慣:インクリメンタルラーニングはプロセスを圧倒的に減らし、管理可能にすることで、持続可能な学習習慣を促進します。 アプリケーション指向:インクリメンタルラーニングは、概念の定期的な実践と適用が内在化されており、実用的な理解とスキルを向上させます。 インクリメンタルラーニングの実世界の応用 これらの例は、インクリメンタルラーニングが言語能力からAIモデルの精度、自動運転車の安全性まで、さまざまな領域で深みと洗練を加える方法を示しています。既存の知識を基に構築することの変革的な影響を示すこの動的なアプローチにより、より知的で適応性のあるシステムが生まれます。 言語学習 インクリメンタルラーニングは、言語習得の領域でその地歩を築いており、学習者が徐々に語彙を構築し文法の複雑さを理解していく旅です。この徐々のアプローチにより、学習者は時間をかけて語学力を向上させることができます。基本的なフレーズのマスタリングから複雑な文構造の理解まで、インクリメンタルラーニングは包括的な言語力を養成する道を開きます。 AIと機械学習 AIと機械学習のダイナミックな世界では、インクリメンタルラーニングの技術が新しい情報の流入に基づいてモデルを磨き、置き換える役割を果たしています。これらの技術により、モデルは最新のデータに更新され、進化するパターンと洞察に適応します。この柔軟なアプローチは、変化が唯一の定数であるドメインで特に重要であり、AIシステムが高い精度と関連性を維持することを可能にします。 詐欺検知システム 金融セクターに進出すると、インクリメンタルラーニングのアルゴリズムは銀行システム内の不正行為に対抗するために重要です。Mastercardは、これらのアルゴリズムを使用してさまざまな変数を検討し、不正な取引の確率を評価しています。新しいデータインスタンスごとに、アルゴリズムは自身の理解を洗練し、不正行為の検出精度を高め、金融取引を保護します。 自動運転車 自動運転車の領域は、インクリメンタルラーニングが輝く別の領域です。自動運転車は蓄積された知識の力を利用し、以前の経験から学び、より効果的に周囲の環境をナビゲートします。これらの車は道路を走行する際にさまざまな状況からデータを収集し、異なるシナリオの理解を向上させます。テスラの車は、道路からデータを収集して機械学習モデルを改善し、より安全でスマートな運転体験を創造しています。 推薦システム デジタルの世界では、増分学習によって私たちが日々遭遇する個別化された推薦が形成されます。ニュース記事から映画の提案まで、推薦システムは私たちの好みを理解し、私たちの嗜好に合ったコンテンツをカリキュレートします。このアプローチは徐々に洗練され、ユーザーがカスタマイズされた魅力的な消費の旅を楽しむことができるように、推薦を微調整していきます。…

「歴史的なアルゴリズムが最短経路問題の突破口を開くのに役立つ」
コンピューティングからの主要なアルゴリズムを再考することで、チームは長年のコンピュータ科学の問題に隠された効率性を解き放ちました
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.