Learn more about Search Results ダウンロード - Page 69

- You may be interested
- FuncReAct OpenAIの関数呼び出しを利用し...
- ジニ係数の解説:経済学が機械学習に影響...
- 「AIを使用して気候変動と戦う」
- 勾配消失問題:原因、結果、および解決策
- 「アメリカ、軍事作戦に混乱をもたらす可...
- 「New DeepMindの研究で、言語モデルのた...
- 「APIのパワーを活用する:認証を通じて製...
- エンドツーエンドのMLパイプラインの構築方法
- CMUの研究者がMultiModal Graph Learning...
- 「オンライン大規模な推薦のためのデュア...
- 「PDFドキュメントを使用したオブジェクト...
- 「データエンジニアリングの本」
- 『アポロ8が月レースを制した方法』
- 「解釈可能性のための神経基盤モデル」
- 評価から啓示へ:クロスバリデーションに...

ロボット用の物理シミュレータを公開する
歩く時、足が地面に触れます書く時、指がペンに触れます物理的な接触が世界との相互作用を可能にしますしかし、このような普通の出来事でも、接触は驚くほど複雑な現象です2つの物体の界面で微小なスケールで起こる接触は、柔らかい場合もあれば硬い場合もあり、弾力的な場合もあればスポンジ状の場合もあり、滑りやすい場合もあれば粘り気のある場合もあります私たちの指先には4つの異なるタイプの触覚センサーがあるのも不思議ではありませんこの微妙な複雑さが、ロボット研究の重要な要素である物理的接触のシミュレーションを難しい課題にしています

Perceiver AR(パーシーバーAR):汎用、長文脈の自己回帰生成
私たちはPerceiver ARを開発していますこれは自己回帰型であり、モダリティを問わないアーキテクチャで、クロスアテンションを使用して長距離の入力を少数の潜在変数にマッピングすると同時に、エンドツーエンドの因果的マスキングを維持しますPerceiver ARは、手作りの疎なパターンやメモリメカニズムの必要なしに、10万以上のトークンに直接アテンションを注ぐことができ、実用的な長文脈の密度推定を可能にします

スケールを通じた高精度の差分プライバシー画像分類の解除
前の研究の経験的な証拠によると、DP-SGDにおける効用の低下は、より大規模なニューラルネットワークモデルでより深刻になる傾向がありますこれには、難しい画像分類のベンチマークで最高のパフォーマンスを達成するために定期的に使用されるモデルも含まれます私たちの研究では、この現象を調査し、トレーニング手順とモデルアーキテクチャの両方に一連の単純な修正を提案して、標準的な画像分類ベンチマークでのDPトレーニングの正確性を大幅に向上させることを示しています
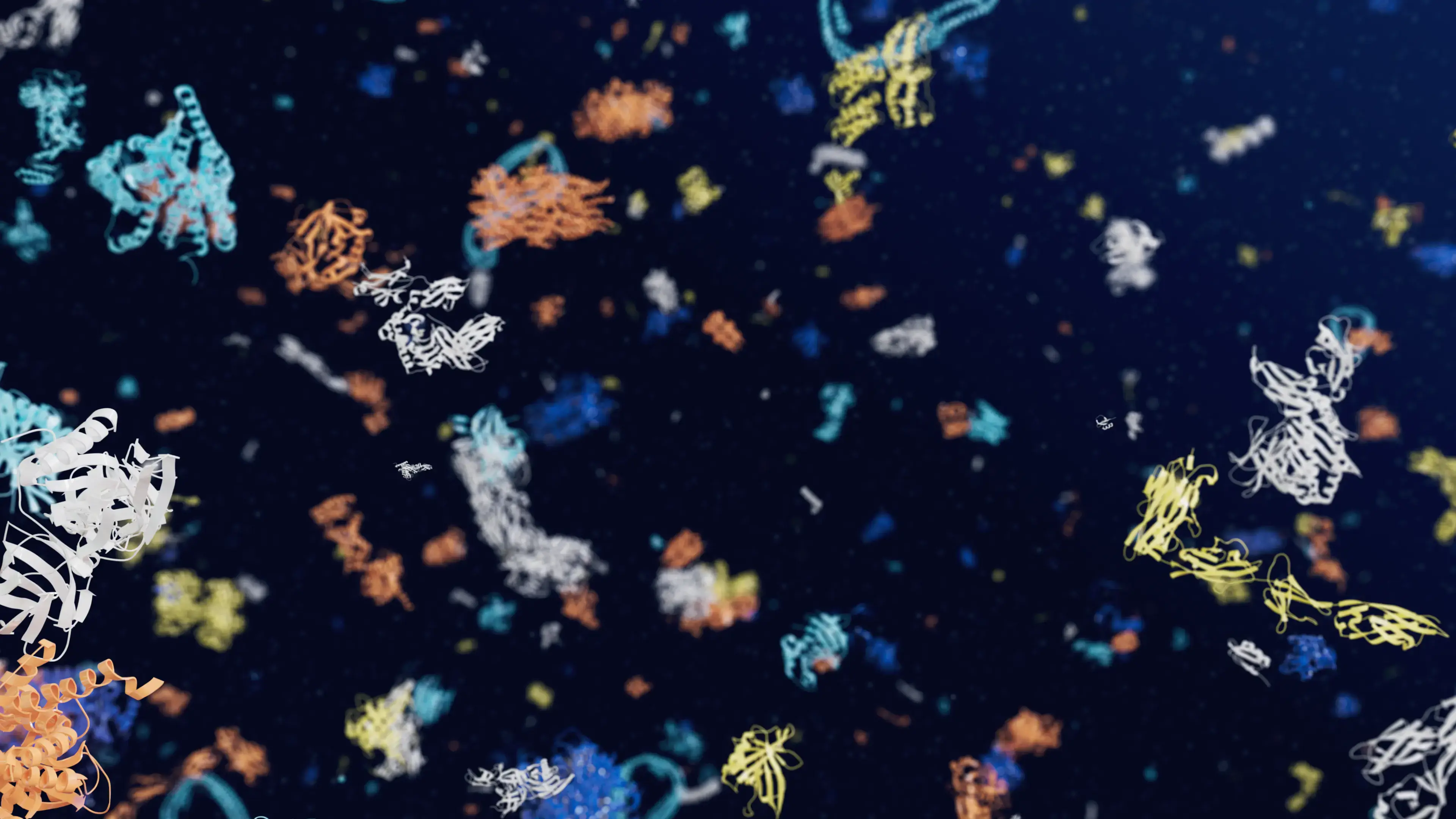
AlphaFoldは、タンパク質の宇宙の構造を明らかにする
今日、EMBLのヨーロッパバイオインフォマティクス研究所(EMBL-EBI)とのパートナーシップを結び、科学界に知られるほぼすべてのカタログ化されたタンパク質の予測構造を公開しますこれにより、AlphaFold DBの構造数は約1,000,000から約2億構造に拡大し、生物学の理解を劇的に高める可能性があります

AIを活用した亀の顔認識による保全の推進
私たちは、Zindiと出会いましたZindiは、補完的な目標を持つ専門のパートナーであり、アフリカのデータサイエンティストの最大のコミュニティであり、アフリカの最も切迫した問題を解決するために焦点を当てた競技会を開催しています私たちの科学チームの多様性、公正性、包括性(DE&I)チームは、Zindiと協力して、保全活動を進め、AIへの参加を促進することができる科学的な課題を特定しましたZindiのバウンディングボックスカメの課題に触発され、私たちは実際の影響を持つ可能性のあるプロジェクトに着地しました:カメの顔認識です

Google Cloudによるデジタルトランスフォーメーション
ここ数年、私たちはGoogle Cloudと提携し、彼らのお客様が利用するコアソリューションに私たちのAI研究を応用して、積極的な影響を与えることに取り組んできました以下では、ドキュメントの理解の最適化、風力エネルギーの価値向上、AlphaFoldのより簡単な利用など、いくつかのプロジェクトを紹介します

次世代の終わりのない学習者のベンチマーク化
私たちの新しい論文、NEVIS’22:コンピュータビジョン研究の30年間からサンプリングされた100のタスクのストリームを提案し、効率的な知識転送の問題を制御可能で再現可能な環境で研究するためのプレイグラウンドを提供しますNever-Ending Visual classification Stream(NEVIS’22)は、評価プロトコル、初期ベースラインのセット、オープンソースのコードベースに加えたベンチマークストリームですこのパッケージは、モデルが将来のタスクをより効率的に学習するために、どのように知識を継続的に積み上げることができるかを研究者に提供します
学習トランスフォーマーコード入門:パート1 – セットアップ
あなたについてはわかりませんが、コードを見ることの方が論文を読むよりも簡単なことがありますAdventureGPTに取り組んでいた時、まずはReActの実装であるBabyAGIのソースコードを読むことから始めました

Falcon-7Bの本番環境への展開
これまでに、ChatGPTの能力と提供するものを見てきましたしかし、企業利用においては、ChatGPTのようなクローズドソースモデルは、企業がデータを制御できないというリスクがあるかもしれません...

RAPIDS:簡単にMLモデルを加速するためにGPUを使用する
はじめに 人工知能(AI)がますます成長するにつれて、より高速かつ効率的な計算能力の需要が高まっています。機械学習(ML)モデルは計算量が多く、モデルのトレーニングには時間がかかることがあります。しかし、GPUの並列処理能力を使用することで、トレーニングプロセスを大幅に加速することができます。データサイエンティストはより速く反復し、より多くのモデルで実験し、より短い時間でより良い性能のモデルを構築することができます。 使用できるライブラリはいくつかあります。今日は、GPUの知識がなくてもMLモデルの加速化にGPUを使用する簡単な解決策であるRAPIDSについて学びます。 学習目標 この記事では、以下のことについて学びます: RAPIDS.aiの概要 RAPIDS.aiに含まれるライブラリ これらのライブラリの使用方法 インストールとシステム要件 この記事は、Data Science Blogathonの一部として公開されました。 RAPIDS.AI RAPIDSは、GPU上で完全にデータサイエンスパイプラインを実行するためのオープンソースのソフトウェアライブラリとAPIのスイートです。RAPIDSは、最も人気のあるPyDataライブラリと一致する使い慣れたAPIを持ちながら、優れたパフォーマンスと速度を提供します。これは、NVIDIA CUDAとApache Arrowで開発されており、その非凡なパフォーマンスの理由です。 RAPIDS.AIはどのように動作するのですか? RAPIDSは、GPUを使用した機械学習を利用してデータサイエンスおよび分析ワークフローのスピードを向上させます。GPU最適化されたコアデータフレームを持っており、データベースと機械学習アプリケーションの構築を支援し、Pythonに似た設計となっています。RAPIDSは、データサイエンスパイプラインを完全にGPU上で実行するためのライブラリのコレクションを提供します。これは、2017年にGPU Open Analytics Initiative(GoAI)と機械学習コミュニティのパートナーによって作成され、Apache Arrowのカラムメモリプラットフォームに基づいたGPUデータフレームを使用して、エンドツーエンドのデータサイエンスおよび分析ワークフローをGPU上で加速するためのものです。RAPIDSには、機械学習アルゴリズムと統合されるDataframe APIも含まれています。 データの移動量を減らした高速データアクセス…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.