Learn more about Search Results A - Page 698

- You may be interested
- データオブザーバビリティの先駆け:デー...
- 「UnbodyとAppsmithを使って、10分でGoogl...
- リアルタイムで命を救うビッグデータ:IoV...
- 分析から実際の応用へ:顧客生涯価値の事例
- AIによって発見された初めての超新星
- 「AI Time Journalは、AI Frontier Networ...
- 「隠れマルコフモデルの力を解読する」
- 「🤗 Transformersを使用してBarkを最適化...
- 「ポッドキャスティングのためのトップAI...
- テキストから画像への革命:SegmindのSD-1...
- ビジョン-言語モデルへのダイブ
- 「ペンタゴンによって設立された生成AIの...
- Office 365の移行と管理を外部委託する主...
- ディープフェイクビデオを出し抜く
- Google Researchにおける責任あるAI:パー...
この無料のeBookでMLOpsの基礎を学びましょう
この無料のebookを今すぐダウンロードして、MLOpsの基礎を学びましょう
スタートアップに参加する前に、データエンジニアが尋ねるべきトップ5の質問
「スタートアップに参加したいのか? a16zによってIPOを控えた素敵なEシリーズのスタートアップのことは言っていない私が言っているのは、シードからシリーズBまでの本物のスタートアップだ毎日が…」

「IDEFICSをご紹介します:最新の視覚言語モデルのオープンな再現」
私たちは、IDEFICS(Image-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS)をリリースすることを喜んでいます。IDEFICSは、Flamingoに基づいたオープンアクセスのビジュアル言語モデルです。FlamingoはDeepMindによって開発された最先端のビジュアル言語モデルであり、公開されていません。GPT-4と同様に、このモデルは画像とテキストの任意のシーケンスを受け入れ、テキストの出力を生成します。IDEFICSは、公開されているデータとモデル(LLaMA v1およびOpenCLIP)のみを使用して構築されており、ベースバージョンと指示付きバージョンの2つのバリアントが9,000,000,000および80,000,000,000のパラメーターサイズで利用可能です。 最先端のAIモデルの開発はより透明性を持つべきです。IDEFICSの目標は、Flamingoのような大規模な専有モデルの能力に匹敵するシステムを再現し、AIコミュニティに提供することです。そのために、これらのAIシステムに透明性をもたらすために重要なステップを踏みました。公開されているデータのみを使用し、トレーニングデータセットを探索するためのツールを提供し、このようなアーティファクトの構築における技術的な教訓とミスを共有し、リリース前に敵対的なプロンプトを使用してモデルの有害性を評価しました。IDEFICSは、マルチモーダルAIシステムのよりオープンな研究のための堅固な基盤として機能することを期待しています。また、9,000,000,000のパラメータースケールでのFlamingoの別のオープン再現であるOpenFlamingoなどのモデルと並んでいます。 デモとモデルをハブで試してみてください! IDEFICSとは何ですか? IDEFICSは、80,000,000,000のパラメーターを持つマルチモーダルモデルであり、画像とテキストのシーケンスを入力とし、一貫したテキストを出力します。画像に関する質問に答えることができ、視覚的なコンテンツを説明し、複数の画像に基づいて物語を作成することができます。 IDEFICSは、Flamingoのオープンアクセス再現であり、さまざまな画像テキスト理解ベンチマークで元のクローズドソースモデルと同等のパフォーマンスを発揮します。80,000,000,000および9,000,000,000のパラメーターの2つのバリアントがあります。 会話型の使用事例に適した、idefics-80B-instructとidefics-9B-instructのファインチューニングバージョンも提供しています。 トレーニングデータ IDEFICSは、Wikipedia、Public Multimodal Dataset、LAION、および新しい115BトークンのデータセットであるOBELICSのオープンデータセットの混合物でトレーニングされました。OBELICSは、ウェブからスクレイプされた141,000,000の交互に配置された画像テキストドキュメントで構成され、353,000,000の画像を含んでいます。 OBELICSの内容をNomic AIで探索できるインタラクティブな可視化も提供しています。 IDEFICSのアーキテクチャ、トレーニング方法論、評価、およびデータセットに関する詳細は、モデルカードと研究論文で入手できます。さらに、モデルのトレーニングから得られた技術的な洞察と学びを文書化しており、IDEFICSの開発に関する貴重な見解を提供しています。 倫理的評価…

「ドメイン固有のLLMポーションの調合」
あなたのLLMをあなたの専門分野のエキスパートにしましょう

「リアルタイム1080pの新しい視点合成の革命:3Dガウスと可視性認識レンダリングによる突破」
メッシュとポイントは、明示的であり、高速なGPU/CUDAベースのラスタリゼーションに適しているため、最も一般的な3Dシーン表現です。一方、最近のニューラル輝度場(NeRF)の手法は、連続的なシーン表現をベースにしており、通常はキャプチャされたシーンの新たな視点合成のためにボリューメトリックなレイマーチングを使用してマルチレイヤパーセプトロン(MLP)を最適化します。同様に、最も効率的な輝度場の解決策も、ボクセル、ハッシュグリッド、またはポイントに格納された値を補完することで、連続的な表現を基に構築されます。これらの手法の定数的な性質は最適化を支援しますが、レンダリングに必要な確率的なサンプリングはコストがかかり、ノイズを引き起こす可能性があります。 Université Côte d’AzurとMax-Planck-Institut für Informatikの研究者は、両方の利点を組み合わせた新しいアプローチを紹介しています。彼らの3Dガウス表現は、最新の視覚品質と競争力のあるトレーニング時間で最適化を可能にします。同時に、彼らのタイルベースのスプラッティングソリューションは、以前に公開された複数のデータセットに対して1080p解像度でSOTA品質のリアルタイムレンダリングを実現します(図1を参照)。彼らの目標は、複数の写真でキャプチャされたシーンのためにリアルタイムレンダリングを可能にし、従来の実際のシーンの最も効率的な以前の手法と同様に最速の最適化時間で表現を作成することです。最近の手法では、高速なトレーニングを達成できますが、現在のSOTA NeRF手法で得られる視覚品質を達成するのは難しいです。つまり、Mip-NeRF360では最大48時間のトレーニングが必要です。 図1: このアプローチは、従来の方法と比較して最速の最適化時間と同等の品質で輝度場をリアルタイムにレンダリングします。ユニークな3Dガウスシーン表現とリアルタイム微分可能なレンダラーは、この性能を実現するために不可欠です。InstantNGPが同等のトレーニング時間で生成できる最高品質ですが、彼らは51分以内で最新のSOTA品質を得ることができます。これは、Mip-NeRF360よりもわずかに優れています。 高速であるが品質の低い輝度場の手法は、シーンによってはインタラクティブなレンダリング時間を達成できます(1秒あたり10〜15フレーム)。しかし、高解像度のリアルタイムレンダリングには達していません。彼らの解決策は、3つの主要な要素に基づいて構築されています。まず、柔軟で表現力豊かな3Dガウスをシーン表現として導入します。彼らは、以前のNeRFのような手法と同じ入力(Structure-from-Motion(SfM)でキャリブレーションされたカメラ)から始め、SfMプロセスの一部として無料で生成されるスパースなポイントクラウドで3Dガウスのセットを初期化します。MVS(Multi-View Stereo)データが必要なほとんどのポイントベースの解決策とは異なり、彼らはSfMポイントのみで高品質の結果を得ることができます。NeRFシンセティックデータセットの場合、彼らの手法はランダムな初期化でも高品質を実現します。 彼らは、3Dガウスが微分可能なボリューメトリック表現として優れた選択肢であることを示しています。それにもかかわらず、2Dに投影して標準的な𝛼ブレンディングを適用することで非常に効率的にラスタライズすることができます。これは、NeRFと同等の画像形成モデルを使用します。彼らの手法の2番目の要素は、3Dガウスのプロパティ(3D位置、不透明度𝛼、異方性共分散、球面調和(SH)係数)の最適化です。最適化手順では、適応的な密度制御ステップとともに、最適化中に3Dガウスを追加および削除します。最適化手順により、シーンの比較的コンパクトで非構造化で正確な表現(テストされたすべてのシーンについて1〜5百万のガウス)が生成されます。彼らの手法の第三および最後の要素は、最近の研究に基づいた高速なGPUソーティングアルゴリズムを使用したリアルタイムレンダリングソリューションです。 しかし、3Dガウス表現のおかげで、彼らは可視性の順序を尊重した異方性スプラッティングを行うことができます – ソートと𝛼-ブレンディングによるもの – そして必要なだけ多くのソートされたスプラットのトラバーサルを追跡することで、高速かつ正確な逆伝播を実現します。要約すると、彼らの貢献は以下のとおりです: • ラジアンスフィールドの高品質な非構造化表現としての異方性3Dガウスの導入。 • 適応的密度制御と交互に行われる3Dガウスのプロパティの最適化手法により、キャプチャされたシーンの高品質な表現を作成します。 • GPUに対して可視性を考慮した高速な微分可能なレンダリング手法により、異方性スプラッティングと高品質な新しい視点合成を実現します。 彼らが以前に公開されたデータセットでの結果は、彼らが多視点キャプチャから3Dガウスを最適化し、以前の暗黙のラジアンスフィールド手法の中で最良の品質と同等またはそれ以上の品質を実現できることを示しています。また、彼らは最速の方法と同様のトレーニング速度と品質を実現し、重要なことに、高品質の新しい視点合成のためのリアルタイムレンダリングを提供します。

「あらゆるプロジェクトに適した機械学習ライブラリ」
「機械学習プロジェクトで使用できる多くのライブラリが存在しますプロジェクトで使用するライブラリについての包括的なガイドを探索してください」
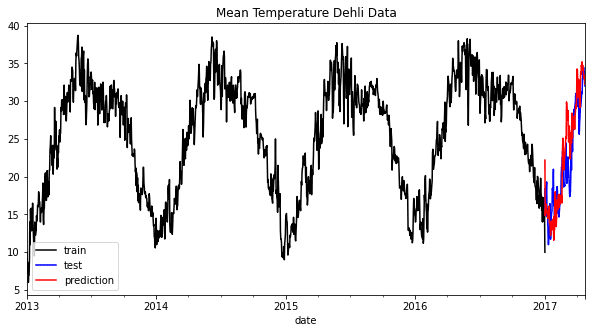
時系列予測のためのXGBoostの活用
「あなたのデータから予測するための強力なアルゴリズムを有効にする」

「MITの研究者が深層学習と物理学を使用して、動きによって損傷を受けたMRIスキャンを修正する」
MRI(磁気共鳴画像)スキャンは、大型磁石、電波、およびコンピュータを使用して体内の構造を明確に映し出すテストです。医療提供者は、MRIを使用して、いくつかの医療状態を評価、診断、およびモニタリングします。 X線とCTスキャンにはそれぞれ優れた点がありますが、MRIスキャンは優れたソフト組織の対比度と高品質の画像を提供します。ソフト組織の対比度と高品質の画像を提供しながらも、MRIは動きの干渉を受けやすく、わずかな動きでも画像の乱れを引き起こすことがあります。これらのアーティファクトは、医療画像の正確さを台無しにし、医師が患者の問題を特定する方法を乱す可能性があります。医師が重要な詳細を見落とすことがあるため、処置が十分にならない可能性もあります。 たとえ短時間のスキャンでも、わずかな動きによってMRI画像が妨害される可能性があります。カメラのブレとは異なり、MRIのモーションアーティファクトは画像全体を歪めることがあります。 ワシントン大学の放射線学の研究によれば、約15%の脳MRIスキャンにはモーションの影響があり、追加のスキャンが必要です。この追加スキャンの必要性は、さまざまなMRIモダリティで診断的に信頼性のある画像を得るために、病院内の1台のスキャナあたり年間約115,000ドルの費用をもたらしています。 この問題を解決するため、MITの研究者は、ディープラーニング技術の力を活用して大きな進歩を遂げました。彼らはディープラーニングを使用して解決策を見つけました。彼らはディープラーニングと物理学を組み合わせて、驚くべき結果を発見しました。 彼らの方法は、スキャン手順を変更せずに、モーションによって破損したデータから運動フリーの画像を計算的に構築することです。この統合アプローチを採用することの重要性は、結果の画像と対象物の実際の測定との間の一貫性を保つ能力に根ざしています。 この整合性を達成できないと、モデルが「幻覚」と呼ばれるものを生成する可能性があります。つまり、実際の物理的および空間的属性から逸脱するように見えるが、実際にはガラスのような画像です。このような相違は診断結果を変える可能性があり、医療画像の正確な表現の重要性を強調しています。 今後は、さらに複雑な頭部運動やさまざまな体の領域に影響を与える動きについての研究の可能性を示しました。例えば、胎児のMRIでは、基本的な変換と回転モデルの能力を超える急速で予測不可能なアクションに対処することが課題です。これは、複雑な運動パターンを考慮に入れるより洗練された戦略を開発する必要性を強調しており、様々な解剖学的シナリオでのMRIアプリケーションの向上に有望な道を提供しています。

音楽の探索の未来:検索対生成
約10年前、音楽ストリーミングサービスは、最高の音楽推薦システムを競っていました明らかに、完璧な推薦システムはユーザーに正確な曲を提供するでしょう...

「10 最高のワークフロー自動化ツール」
現代の速いデジタルの世界では、効率は単なる流行語以上のものです - 必要不可欠なものですビジネスが拡大し、プロセスが複雑化するにつれて、手作業の操作はしばしば煩雑で時間のかかるものになります解決策は何でしょうか?ワークフロー自動化ツールですこれらのツールによって繰り返しのタスクを効率化することで、時間を節約するだけでなく、人為的なエラーのリスクも減らすことができます[…]
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.