Learn more about Search Results A - Page 694

- You may be interested
- Acme 分散強化学習のための新しいフレーム...
- 「10個の最高のAIヘッドショットジェネレ...
- 「MLOpsの全機械学習ライフサイクルをカバ...
- 「SafeCoder対クローズドソースのコードア...
- ランウェイの新しい「モーションブラシ」...
- Stack Overflowで最もよく尋ねられるPytho...
- 「5つのステップでPyTorchを始めましょう」
- Wandaとは:大規模言語モデルに対するシン...
- 「MITの研究者が開発した機械学習技術によ...
- AI幻覚とは何ですか?AIチャットボットで...
- 「DatabricksがMosaicMLとその他の最近のA...
- 「ナイトシェードの仕組み」
- このツールを使用することで、プロンプト...
- 「OWLv2のご紹介:ゼロショット物体検出に...
- 通貨為替レートの予測のためのSARIMAモデル
「F1スコア:視覚的ガイド – そしてなぜそれが偏ったデータから救ってくれないのか」
F1スコアは、適合率と再現率を組み合わせ、そのうちの低い値に「引っ付く」特徴がありますF1スコアはデータの不均衡からは救ってくれませんもし陽性クラスがデータの大部分を占める場合、F1スコアは良い選択肢ではありません

デシは、コード生成のためのオープンソース1Bパラメータの大規模言語モデル「DeciCoder」を紹介します
AIの速い世界では、効率的なコード生成は見過ごすことのできない課題です。ますます複雑なモデルの出現に伴い、正確なコード生成の需要は急増していますが、エネルギー消費と運用コストへの懸念も増しています。この効率のギャップに直面し、先駆的なAI企業であるDeciは、効率的かつ正確なコード生成の新たな基準を再定義することを目指す、10億パラメータのオープンソースLarge Language Model(LLM)であるDeciCoderを紹介します。 既存のコード生成モデルは、精度と効率の微妙なバランスに苦しんできました。この領域の代表的なプレーヤーであるSantaCoderは、広く使用されていますが、スループットとメモリ消費に制約があることが示されています。ここで、DeciCoderが変革的な解決策として登場します。DeciのAI効率の基盤に基づいているDeciCoderは、最先端のアーキテクチャと独自のニューラルアーキテクチャサーチ技術であるAutoNACを活用しています。しばしば不十分な手動の労力を伴うアプローチとは異なり、AutoNACは最適なアーキテクチャの生成プロセスを自動化します。その結果、NVIDIAのA10 GPUに最適化された印象的なアーキテクチャが生まれます。これにより、スループットが向上し、かつSantaCoderと同等の精度が実現されます。 DeciCoderのアーキテクチャは、革新の証です。8つのキーバリューヘッドを備えたGrouped Query Attentionを組み込むことで、計算とメモリ使用量が合理化され、精度と効率の調和が実現されます。SantaCoderとの直接対決で、DeciCoderは独自の特徴を持っています – レイヤーが少ない(20対24)、ヘッドが多い(32対16)、および並列の埋め込みサイズ。これらの特徴は、AutoNACの複雑なダンスから派生し、DeciCoderの力を支えています。 DeciCoderの道のりは、革新と効率への執念によって特徴付けられています。この開発の示す意義は深いものです。DInfery LLMと併せてDeciCoderを活用することで、ユーザーはSantaCoderの驚異的な3.5倍のスループット向上の力を発揮することができます。この革新の物語は効率の向上だけで終わるものではありません。環境に配慮したAIに関しても同様です。Deciの環境に対する強い関心は、A10G GPU上での1つのモデルインスタンスあたりの二酸化炭素排出量を324 kg削減することで表現されています。これは、環境意識の高いAIへの有望な一歩となります。 https://deci.ai/blog/decicoder-efficient-and-accurate-code-generation-llm/ DeciCoderは孤立した取り組みではありません。これはDeciのAI効率への包括的なアプローチの一環です。同社が高効率な基盤LLMやテキストから画像へのモデルを導入する新時代の到来を告げる中で、開発者は、ファインチューニング、最適化、展開の領域を再定義する予定の生成AI SDKを期待することができます。この包括的なスイートは、効率の利点を巨大な企業や小規模なプレーヤーにも提供し、AIの可能性を民主化します。 DeciCoderのストーリーは、そのアーキテクチャとベンチマークにとどまるものではありません。それは力を与えることについての物語です。最小の制約でDeciCoderをプロジェクトに統合することができる許可されたライセンスは、開発者やビジネスに力を与えます。商用アプリケーションでDeciCoderを展開する柔軟性は、Deciのミッションであるイノベーションと成長を促進することと一致しています。これは、単にAIについての物語ではなく、技術とその影響においてポジティブな変革を起こすことについての物語です。 https://deci.ai/blog/decicoder-efficient-and-accurate-code-generation-llm/ 全体的に、DeciCoderは単なるモデル以上であり、AIの効率の潜在能力の実現です。AutoNAC、グループ化されたクエリアテンション、専用の推論エンジンのシナジーを通じて、高性能で環境に配慮したモデルを提供します。DeciCoderの紹介によって示されるDeciの旅は、AIコミュニティのための明かりであり、私たちの惑星の資源を尊重しながら技術革新を求める呼びかけです。それは単なるコードではなく、より持続可能で効率的なAIの未来のためのコードです。
画像中のテーブルの行と列をトランスフォーマーを使用して検出する
はじめに 非構造化データを扱ったことがあり、ドキュメント内のテーブルの存在を検出する方法を考えたことはありますか?ドキュメントを迅速に処理するための方法を提供しますか?この記事では、トランスフォーマーを使用して、テーブルの存在だけでなく、テーブルの構造を画像から認識する方法を見ていきます。これは、2つの異なるモデルによって実現されます。1つはドキュメント内のテーブルの検出のためのもので、もう1つはテーブル内の個々の行と列を認識するためのものです。 学習目標 画像上のテーブルの行と列を検出する方法 Table TransformersとDetection Transformer(DETR)の概要 PubTables-1Mデータセットについて Table Transformerでの推論の実行方法 ドキュメント、記事、PDFファイルは、しばしば重要なデータを伝えるテーブルを含む貴重な情報源です。これらのテーブルから情報を効率的に抽出することは、異なるフォーマットや表現の間の課題により複雑になる場合があります。これらのテーブルを手動でコピーまたは再作成するのは時間がかかり、ストレスがかかることがあります。PubTables-1Mデータセットでトレーニングされたテーブルトランスフォーマーは、テーブルの検出、構造の認識、および機能分析の問題に対処します。 この記事はData Science Blogathonの一環として公開されました。 この方法はどのように実現されたのですか? これは、PubTables-1Mという名前の大規模な注釈付きデータセットを使用して、記事などのドキュメントや画像を検出するためのトランスフォーマーモデルであるTable Transformerによって実現されました。このデータセットには約100万のパラメータが含まれており、いくつかの手法を用いて実装されており、モデルに最先端の感触を与えています。効率性は、不完全な注釈、空間的な整列の問題、およびテーブルの構造の一貫性の課題に取り組むことで達成されました。モデルとともに公開された研究論文では、テーブルの構造認識(TSR)と機能分析(FA)のジョイントモデリングにDetection Transformer(DETR)モデルを活用しています。したがって、DETRモデルは、Microsoft Researchが開発したTable Transformerが実行されるバックボーンです。DETRについてもう少し詳しく見てみましょう。 DEtection TRansformer(DETR) 前述のように、DETRはDEtection TRansformerの略であり、エンコーダーデコーダートランスフォーマーを使用したResNetアーキテクチャなどの畳み込みバックボーンから構成されています。これにより、オブジェクト検出のタスクを実行する潜在能力を持っています。DETRは、領域提案、非最大値抑制、アンカー生成などの複雑なモデル(Faster…

「MicrosoftがExcelにPythonを導入:分析能力と親しみやすさを結びつけ、データ洞察を向上させる」
データ分析の領域では、Pythonの能力(分析に広く使用される強力なプログラミング言語)とMicrosoft Excelの使い慣れたインターフェースと機能をシームレスに統合することが長らく課題となってきました。この課題は、両方のツールを業務に使用するプロフェッショナルの効率的な意思決定とデータ処理を妨げてきました。このギャップを埋める統合ソリューションの必要性は明らかです。 PythonとExcelを統合しようとする既存の試みは、しばしば手間がかかり、複雑なセットアップが必要でした。アナリストたちは、外部スクリプト、サードパーティのツール、または2つの環境間での手動データ転送を使用して対応しました。これらの方法は効率を低下させ、セキュリティ上の懸念を引き起こし、共同作業のワークフローを困難にしました。欠けていたのは、両プラットフォームの強みを組み合わせた統一されたソリューションでした。 マイクロソフトは、この長年の課題に対する回答として、ExcelにPythonを統合する形で革新的な統合を提供しています。この画期的な統合は、Excelのデータの整理、視覚化能力、および使い慣れたインターフェースとPythonの分析能力をシームレスに組み合わせる方法を提供します。これにより、プロフェッショナルがデータ分析、意思決定、および共同作業に取り組む方法が再定義されることが期待されています。 Python in Excelでは、新しいPY関数を使用して、ユーザーがPythonコードを直接Excelセルに入力できます。これにより、外部スクリプトや複雑なデータ転送の必要性がなくなります。この統合は、アナリストを念頭に設計されており、pandas、Matplotlib、scikit-learnなどのPythonの分析ライブラリを簡単に利用できるようになっています。この統合は、単なる並べ替え以上の機能を提供し、Excelの既存の機能とPythonの分析を組み合わせたエンドツーエンドのソリューションを作成できるようにします。 この統合は、PythonコードをMicrosoft Cloud上の独立したコンテナで実行することにより、セキュリティを確保しています。PythonとExcelの関数間の制御されたやり取りにより、データのプライバシーが保持されます。Microsoft TeamsやOutlookなどのツールとの互換性により、共同執筆やデータ共有が効率的に行われ、セキュリティポリシーに準拠します。 Python in Excelは、データ分析のワークフローにおけるパラダイムシフトをもたらします。アナリストは、馴染みのあるExcelインターフェースを離れることなく、Pythonの豊富な分析機能にシームレスにアクセスできるようになりました。高度な可視化、機械学習、予測分析、およびデータクリーニングは、Excelベースの分析に不可欠です。この統合の成功指標には、データ分析の効率向上、データ転送に費やされる時間の削減、共同作業の強化、およびデータセキュリティの改善が含まれるでしょう。 Python in Excelの導入は、さまざまな業界のプロフェッショナルが直面する持続的な課題に対処しています。PythonとExcelの強みを組み合わせることで、マイクロソフトは分析の可能性と共同作業の新たなレベルを開拓しました。この統合により、ワークフローが簡素化され、データの洞察力が向上し、意思決定が効率化されます。変革的なツールであるPython in Excelは、マイクロソフトのイノベーションへの取り組みを反映しており、データ分析のより効率的で強力な未来の道を切り拓いています。

クラウドコンピューティングはデータサイエンスのワークフローをどのように向上させるのか
クラウドコンピューティングは、データサイエンスのワークフローに必要な効率性、スケーラビリティ、セキュリティを提供しますこれらの利点をここでどのように提供しているかをご覧ください

モデルの精度向上:Spotifyでの機械学習論文で学んだテクニック(+コードスニペット)
この記事は、私のSpotifyでの機械学習の論文からの学びを記録した2部構成の一部ですFeature Importanceの実装方法についての第2の記事もぜひチェックしてください

東京大学の研究者たちは、静的バンディット問題からより困難な動的環境に向けた拡張フォトニック強化学習手法を開発しました
機械学習の世界では、強化学習の概念が中心になっており、特定の環境内で反復的な試行と誤りを通じてエージェントがタスクを達成することが可能になっています。この分野の成果は、計算コストを外部にアウトソーシングするための光子アプローチの使用や、光の物理的特性を活用することなどを示しています。また、これらの手法を複数エージェントや動的な環境を含むより複雑な問題に拡張する必要性も強調されています。東京大学の研究では、バンディットアルゴリズムとQ学習を組み合わせて、学習を加速し、マルチエージェントの協力に関する洞察を提供する改良版バンディットQ学習(BQL)を作成することを目指しています。これにより、光子強化学習技術の進歩に貢献することを最終目標としています。 研究者は、グリッドワールドの問題の概念を使用しています。これは、エージェントが5×5のグリッド内を移動し、各セルが状態を表すものです。各ステップで、エージェントは上下左右の行動を取り、報酬と次の状態を受け取ります。特定のセルAとBは高い報酬を提供し、エージェントに異なるセルに移動するよう促します。この問題は、エージェントの行動が移動を決定する確定的な方針に依存しています。 行動価値関数Q(s, a)は、方策πに基づいた状態-行動のペアに対する将来の報酬を定量化します。この関数は、エージェントが行動を通じて累積報酬を予測するものです。この研究の主な目的は、エージェントがすべての状態-行動のペアに対する最適なQ値を学習できるようにすることです。改良版のQ学習は、バンディットアルゴリズムを統合し、動的な状態-行動のペア選択を通じて学習プロセスを強化します。 この改良版のQ学習スキームでは、複数のエージェントが共有のQテーブルを更新する並列学習が可能です。並列化により、Qテーブルの更新の精度と効率が向上し、学習プロセスが促進されます。エージェントの同時行動が直接的な通信なしでも明確になるように、光子の量子干渉の原理を利用した意思決定システムが構想されています。 研究者は、エージェントが連続的に行動し、より複雑な学習タスクに彼らの手法を適用できるアルゴリズムを開発する予定です。将来的には、少なくとも3つのエージェント間で衝突のない意思決定を可能にする光子システムを作成することを目指しています。

「勾配降下法アルゴリズムとその直感的な考え方」
最適化手法の中で、そして一次のアルゴリズムタイプにおいて、確かにGradient Descentとして知られるものを聞いたことがあるでしょうこれは一次の最適化タイプであり、…を必要とします
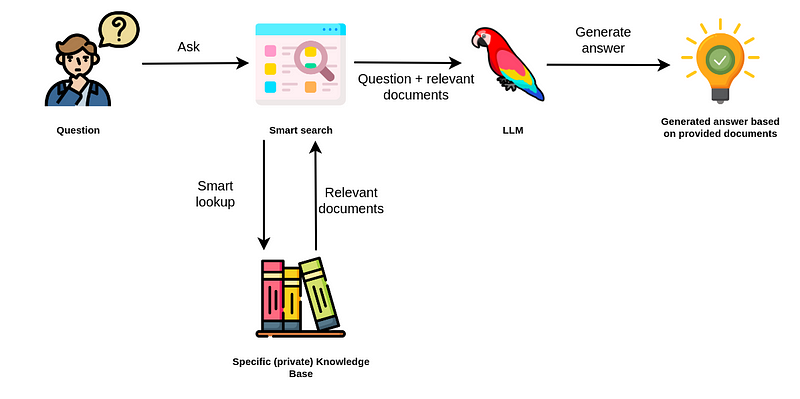
「Neo4jにおける非構造化テキストに対する効率的な意味検索」
ChatGPTが6か月前に登場して以来、技術の風景は変革的な転換を遂げましたChatGPTの優れた一般化能力により、...

画像認識におけるディープラーニング:技術と課題
「人工知能の広大な領域において、特に画像認識の分野において、ディープラーニングはゲームチェンジャーとして登場しました」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.