Learn more about Search Results Yi - Page 68

- You may be interested
- 「ODSC West Data PrimerシリーズでAIの学...
- 人間とAIの協力
- 「Apache SeaTunnel、Milvus、およびOpenA...
- H1Bビザはデータ分析の洞察に基づいて承認...
- 「生成AIは世界を変える可能性があるが、...
- 「文書理解の進展」
- 「ビーチでの読書:事前学習モデルの短い...
- 「UBCカナダの研究者が、都市ドライバーに...
- 「Llama 2によるトピックモデリング」
- 「マーケティングにおける人工知能の短い...
- 「2023年の市場で利用可能な15の最高のETL...
- ‘LinkedInの仕事検索機能を支える埋め込み...
- Llemmaに会ってください:現行基準を超え...
- データサイエンスの成功への道は、学習能...
- 「変革を受け入れる:AWSとNVIDIAが創発的...

「アリババが新しいAIツールを導入し、テキスト入力から画像を生成しました」
今日、テクノロジージャイアントのアリババは、期待されていたAIツール、同義ワンシャンを正式に発表しました報道によると、これはテキスト入力によって画像を生成することができます興味深いことに、このAIは、ユーザーが中国語と英語のプロンプトを入力して画像を生成することを可能にしますスタイルには、スケッチスタイルから3Dまで、さまざまなものが含まれています...

「責任あるAIダッシュボードでオブジェクト検出モデルをデバッグする」
「Microsoft Build 2023 において、Azure Machine Learning の責任ある AI ダッシュボードでテキストと画像データのサポートをプレビューで発表しましたこのブログでは、ダッシュボードの新しいビジョンインサイト機能に焦点を当て、オブジェクト検出モデルのデバッグ機能をサポートしますまた、今後の投稿ではテキストベースのシナリオにも取り組みます...」

「The Reformer – 言語モデリングの限界を押し上げる」
Reformerが半ミリオントークンのシーケンスを訓練するために8GB未満のRAMを使用する方法 Reformerモデルは、Kitaev、Kaiserらによって2020年に紹介されたもので、現在のところ最もメモリ効率の良いトランスフォーマーモデルの1つです。 最近、長いシーケンスモデリングは大きな関心を集めており、今年だけでも多くの論文が提出されています(Beltagyら(2020年)、Royら(2020年)、Tayら、Wangらなど)。長いシーケンスモデリングの背後にある動機は、要約、質問応答などの多くのNLPタスクが、BERTなどのモデルよりも長い入力シーケンスを処理する必要があるということです。大きな入力シーケンスを処理する必要があるタスクでは、長いシーケンスモデルはメモリオーバーフローを避けるために入力シーケンスを切り詰める必要がなく、従って標準の「BERT」のようなモデルを上回る性能を示すことが示されています(Beltagyら(2020年)による)。 Reformerは、このデモに示されているように、一度に最大で半ミリオンのトークンを処理する能力により、長いシーケンスモデリングの限界を em em ます。比較のために、従来の bert-base-uncased モデルでは、入力の長さを512トークンに制限しています。Reformerでは、標準のトランスフォーマーアーキテクチャの各部分が最小限のメモリ要件を最適化するために再設計されており、性能の大幅な低下を伴わずにメモリの改善がなされています。 メモリの改善は、Reformerの作者がトランスフォーマーワールドに導入した4つの特徴に帰属できます: Reformer Self-Attention Layer – ローカルコンテキストに制限されることなく自己注意を効率的に実装する方法は? Chunked Feed Forward Layers – 大規模なフォワードレイヤーの時間とメモリのトレードオフを改善する方法は? Reversible Residual Layers…

‘Perceiver IO どんなモダリティにも対応するスケーラブルな完全注意モデル’
TLDR 私たちはPerceiver IOをTransformersに追加しました。これは、テキスト、画像、音声、ビデオ、ポイントクラウドなど、あらゆる種類のモダリティ(それらの組み合わせも含む)に対応した最初のTransformerベースのニューラルネットワークです。以下のスペースをご覧いただくと、いくつかの例をご覧いただけます。 画像間のオプティカルフローの予測 画像の分類。 また、いくつかのノートブックも提供しています。 以下に、モデルの技術的な説明をご覧いただけます。 はじめに Transformerは、元々Vaswaniらによって2017年に紹介され、機械翻訳の最先端(SOTA)の結果を改善するというAIコミュニティでの革命を引き起こしました。2018年には、BERTがリリースされ、トランスフォーマーエンコーダ専用のモデルで、自然言語処理(NLP)のベンチマーク(特にGLUEベンチマーク)を圧倒的に上回りました。 その後まもなくして、AI研究者たちはBERTのアイデアを他の領域にも適用し始めました。以下にいくつかの例を挙げます。 Facebook AIのWav2Vec2は、このアーキテクチャをオーディオに拡張できることを示しました。 Google AIのVision Transformer(ViT)は、このアーキテクチャがビジョンに非常に適していることを示しました。 最近では、Google AIのVideo Vision Transformer(ViViT)もこのアーキテクチャをビデオに適用しました。 これらのすべての領域で、大規模な事前トレーニングとこの強力なアーキテクチャの組み合わせにより、最先端の結果が劇的に改善されました。 ただし、Transformerのアーキテクチャには重要な制約があります。自己注意機構により、計算およびメモリの両方でスケーリングが非常に悪くなります。各レイヤーでは、すべての入力をクエリとキーの生成に使用し、ペアごとのドット積を計算します。したがって、高次元データに自己注意を適用するには、ある形式の前処理が必要です。たとえば、Wav2Vec2では、生の波形を時間ベースの特徴のシーケンスに変換するために、特徴エンコーダを使用してこの問題を解決しています。Vision Transformer(ViT)は、画像を重ならないパッチのシーケンスに分割し、「トークン」として使用します。Video Vision Transformer(ViViT)は、ビデオから重ならない時空間の「チューブ」を抽出し、「トークン」として使用します。Transformerを特定のモダリティで動作させるためには、通常はトークンのシーケンスに離散化する必要があります。…

スクラッチからCodeParrot 🦜をトレーニングする
このブログポストでは、GitHub CoPilotの背後にある技術を構築するために必要なものについて説明します。GitHub CoPilotは、プログラマがコードを書く際に提案を行うアプリケーションです。このステップバイステップガイドでは、ゼロから完全にトレーニングされた大規模なGPT-2モデルであるCodeParrot 🦜を訓練する方法を学びます。CodeParrotはPythonのコードを自動補完することができます – こちらで試してみてください。さあ、ゼロから構築してみましょう! ソースコードの大規模なデータセットの作成 まず必要なものは、大規模なトレーニングデータセットです。Pythonのコード生成モデルを訓練することを目指して、GoogleのBigQueryで利用可能なGitHubのダンプにアクセスし、すべてのPythonファイルに絞り込みました。その結果、180GBのデータセットがあり、2000万のファイルが含まれています(こちらで入手可能)。初期のトレーニング実験の結果、データセットの重複はモデルの性能に深刻な影響を与えることがわかりました。データセットを調査すると、次のことがわかりました: ユニークなファイルの0.1%が全ファイルの15%を占めています ユニークなファイルの1%が全ファイルの35%を占めています ユニークなファイルの10%が全ファイルの66%を占めています 詳細は、このTwitterスレッドで調査結果について詳しくご覧いただけます。重複を削除し、CoPilotの背後にあるモデルであるCodexの論文で見つかった同じクリーニングヒューリスティックを適用しました。CodexはGitHubのコードでファインチューニングされたGPT-3モデルです。 クリーニングされたデータセットはまだ50GBの大きさであり、Hugging Face Hubで利用可能です:codeparrot-clean。これで新しいトークナイザーを設定し、モデルを訓練することができます。 トークナイザーとモデルの初期化 まず、トークナイザーが必要です。コードを適切にトークンに分割するために、コード専用のトークナイザーをトレーニングしましょう。既存のトークナイザー(例えばGPT-2)を取り、train_new_from_iterator()メソッドで独自のデータセットでトレーニングします。それから、Hubにプッシュします。コードの例からインポートや引数のパース、ログ出力は省略していますが、前処理やダウンストリームタスクの評価を含めた完全なコードはこちらで見つけることができます。 # トレーニング用のイテレーター def batch_iterator(batch_size=10): for _ in…

🤗 Transformersでn-gramを使ってWav2Vec2を強化する
Wav2Vec2は音声認識のための人気のある事前学習モデルです。2020年9月にMeta AI Researchによってリリースされたこの新しいアーキテクチャは、音声認識のための自己教師あり事前学習の進歩を促進しました。例えば、G. Ng et al.、2021年、Chen et al、2021年、Hsu et al.、2021年、Babu et al.、2021年などが挙げられます。Hugging Face Hubでは、Wav2Vec2の最も人気のある事前学習チェックポイントは現在、月間ダウンロード数25万以上です。 コネクショニスト時系列分類(CTC)を使用して、事前学習済みのWav2Vec2のようなチェックポイントは、ダウンストリームの音声認識タスクで非常に簡単にファインチューニングできます。要するに、事前学習済みのWav2Vec2のチェックポイントをファインチューニングする方法は次のとおりです。 事前学習チェックポイントの上にはじめに単一のランダムに初期化された線形層が積み重ねられ、生のオーディオ入力を文字のシーケンスに分類するために訓練されます。これは以下のように行います。 生のオーディオからオーディオ表現を抽出する(CNN層を使用する) オーディオ表現のシーケンスをトランスフォーマーレイヤーのスタックで処理する 処理されたオーディオ表現を出力文字のシーケンスに分類する 以前のオーディオ分類モデルでは、分類されたオーディオフレームのシーケンスを一貫した転写に変換するために、追加の言語モデル(LM)と辞書が必要でした。Wav2Vec2のアーキテクチャはトランスフォーマーレイヤーに基づいているため、各処理されたオーディオ表現は他のすべてのオーディオ表現から文脈を得ることができます。さらに、Wav2Vec2はファインチューニングにCTCアルゴリズムを利用しており、変動する「入力オーディオの長さ」と「出力テキストの長さ」の比率の整列の問題を解決しています。 文脈化されたオーディオ分類と整列の問題がないため、Wav2Vec2には受け入れ可能なオーディオ転写を得るために外部の言語モデルや辞書は必要ありません。 公式論文の付録Cに示されているように、Wav2Vec2は言語モデルを使用せずにLibriSpeechで印象的なダウンストリームのパフォーマンスを発揮しています。ただし、付録からも明らかなように、Wav2Vec2を10分間の転写済みオーディオのみで訓練した場合、言語モデルと組み合わせると特に改善が見られます。 最近まで、🤗 TransformersライブラリにはファインチューニングされたWav2Vec2と言語モデルを使用してオーディオファイルをデコードするための簡単なユーザーインターフェースがありませんでした。幸いにも、これは変わりました。🤗…

Pythonを使用した感情分析の始め方
感情分析は、データを感情に基づいてタグ付けする自動化されたプロセスです。感情分析により、企業はデータをスケールで分析し、洞察を検出し、プロセスを自動化することができます。 過去には、感情分析は研究者、機械学習エンジニア、または自然言語処理の経験を持つデータサイエンティストに限定されていました。しかし、AIコミュニティは最近、機械学習へのアクセスを民主化するための素晴らしいツールを開発しました。今では、わずか数行のコードを使って感情分析を行い、機械学習の経験が全くなくても利用することができます!🤯 このガイドでは、Pythonを使用した感情分析の始め方についてすべてを学びます。具体的には以下の内容です: 感情分析とは何か? Pythonで事前学習済みの感情分析モデルを使用する方法 独自の感情分析モデルを構築する方法 感情分析でツイートを分析する方法 さあ、始めましょう!🚀 1. 感情分析とは何ですか? 感情分析は、与えられたテキストの極性を特定する自然言語処理の技術です。感情分析にはさまざまなバリエーションがありますが、最も広く使用されている技術の1つは、データを「ポジティブ」、「ネガティブ」、または「ニュートラル」のいずれかにラベル付けするものです。たとえば、次のようなツイートを見てみましょう。@VerizonSupportをメンションしているものです: “dear @verizonsupport your service is straight 💩 in dallas.. been with y’all over…
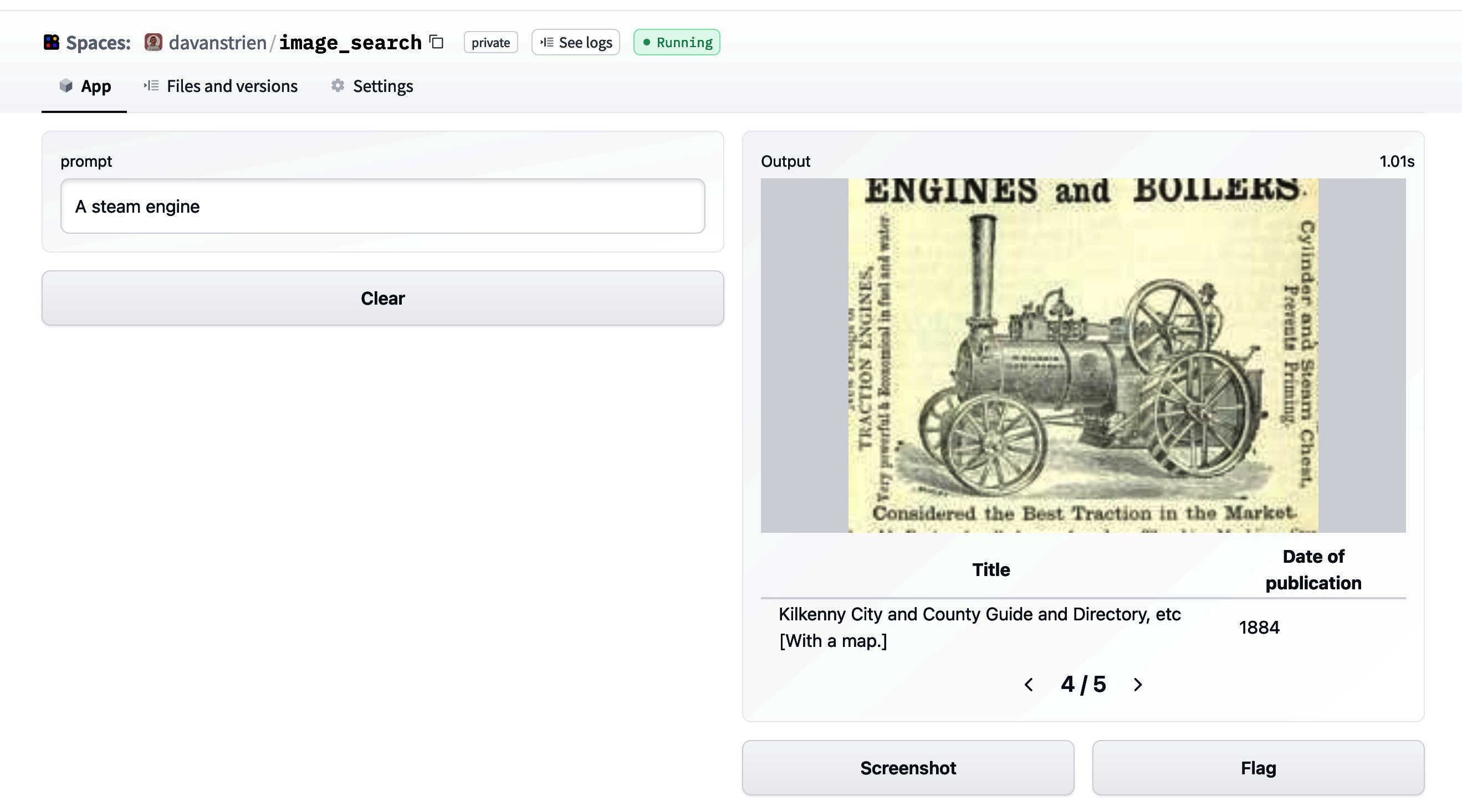
🤗データセットを使った画像検索
🤗 datasetsは、データセットに簡単にアクセスして共有することができるライブラリです。また、メモリに収まらないデータを効率的に処理することも容易にします。 datasetsが最初にリリースされた当初は、主にテキストデータと関連していました。しかし、最近では、datasetsは音声や画像に対するサポートを増やしています。特に、画像のためのdatasetsの機能タイプが追加されました。以前のブログ投稿では、datasetsと🤗 transformersを組み合わせて画像分類モデルのトレーニング方法を紹介しました。このブログ投稿では、datasetsと他のいくつかのライブラリを組み合わせて画像検索アプリケーションを作成する方法を見ていきます。 まず、datasetsをインストールします。画像を扱うために、pillowもインストールします。さらに、sentence_transformersとfaissも必要です。これらについては後ほど詳しく説明します。また、richもインストールします。ここでは簡単に使用するだけですが、非常に便利なパッケージなので、ぜひ詳しく探索してみてください! !pip install datasets pillow rich faiss-gpu sentence_transformers まずは、画像の特徴を見てみましょう。素晴らしいライブラリであるrichを使用して、Pythonオブジェクト(関数、クラスなど)を調べることができます。 from rich import inspect import datasets inspect(datasets.Image, help=True) ╭───────────────────────── <class 'datasets.features.image.Image'>…

機械学習洞察のディレクター
機械学習のテーブルの席は、技術的なスキル、問題解決能力、ビジネスの洞察力など、ディレクターのような役職にしかないものです。 機械学習および/またはデータサイエンスのディレクターは、しばしばMLシステムの設計、数学の深い知識、MLフレームワークの熟知、リッチなデータアーキテクチャの理解、実世界のアプリケーションへのMLの適用経験、優れたコミュニケーションスキルを持つことが求められます。また、業界の最新動向に常に精通していることも期待されています。これは大変な注文です! これらの理由から、私たちはこのユニークなMLディレクターのグループにアクセスし、ヘルスケアからファイナンス、eコマース、SaaS、研究、メディアなど、さまざまな産業における彼らの現在のMLの洞察と業界のトレンドについての記事シリーズを作成しました。たとえば、あるディレクターは、MLを使用して空の空転トラック運転(約20%の時間が発生)をわずか19%に減らすことで、約10万人のアメリカ人の炭素排出量を削減できると指摘しています。注意:これは元ロケット科学者によって行われた即興の計算ですが、私たちはそれを受け入れます。 この最初のインストールでは、地中に埋まった地雷を検出するために地中レーダーを使用している研究者、元ロケット科学者、ツォンカ語に堪能なアマチュアゲーマー(クズ=こんにちは!)、バン生活を送っていた科学者、まだ実践的な高性能データサイエンスチームのコーチ、関係性、家族、犬、ピザを大切にするデータ実践者など、豊富なフィールドの洞察を持つ機械学習ディレクターの意見を紹介します。 🚀 さまざまな産業における機械学習ディレクターのトップと出会い、彼らの見解を聞いてみましょう: アーキ・ミトラ – Buzzfeedの機械学習ディレクター 背景:ビジネスにおけるMLの約束にバランスをもたらす。プロセスよりも人。希望よりも戦略。AIの利益よりもAIの倫理。ブラウン・ニューヨーカー。 興味深い事実:ツォンカ語を話すことができます(Googleで検索してください!)そしてYouth for Sevaを支援しています。 Buzzfeed:デジタルメディアに焦点を当てたアメリカのインターネットメディア、ニュース、エンターテイメント会社。 1. MLがメディアにポジティブな影響を与えたのはどのような点ですか? 顧客のためのプライバシー重視のパーソナライゼーション:すべてのユーザーは個別であり、長期的な関心事は安定していますが、短期的な関心事は確率的です。彼らはメディアとの関係がこれを反映することを期待しています。ハードウェアアクセラレーションの進歩と推奨のためのディープラーニングの組み合わせにより、この微妙なニュアンスを解読し、ユーザーに適切なコンテンツを適切なタイミングで適切なタッチポイントで提供する能力が解き放たれました。 メディア製作者のための支援ツール:メディアにおける制作者は限られた資産ですが、MLによる人間-ループアシストツールにより、彼らの創造的な能力を保護し、協力的なマシン-人間のフライホイールを解き放つことができました。適切なタイトル、画像、ビデオ、および/またはコンテンツに合わせて自動的に提案するだけの簡単なことでも、協力的なマシン-人間のフライホイールを解き放つことができます。 テストの締め付け:資本集約型のメディアベンチャーでは、ユーザーの共感を得る情報を収集する時間を短縮し、即座に行動する必要があります。ベイジアンテクニックのさまざまな手法と強化学習の進歩により、時間だけでなくそれに関連するコストも大幅に削減することができました。 2. メディア内の最大のMLの課題は何ですか? プライバシー、編集の声、公平な報道:メディアは今以上に民主主義の重要な柱です。MLはそれを尊重し、他のドメインや業界では明確に考慮されない制約の中で操作する必要があります。編集によるカリキュレーションされたコンテンツとプログラミングとMLによる推奨のバランスを見つけることは、依然として課題です。BuzzFeedにとってももう1つのユニークな課題は、インターネットは自由であるべきだと信じているため、他の企業とは異なり、ユーザーを追跡していないことです。 3. メディアへのMLの統合を試みる際に、よく見かける間違いは何ですか?…

機械学習インサイトのディレクター[Part 2 SaaSエディション]
もしもあなたやあなたのチームがMLソリューションの構築に興味があるなら、今すぐhf.co/supportを訪れてください! 👋 マシンラーニングインサイトの第2弾へようこそ。第1弾はこちらをご覧ください。 マシンラーニングディレクターは、さまざまな役割と責任の視点を持つAIテーブルで特別な立場にあります。彼らのMLフレームワーク、エンジニアリング、アーキテクチャ、実世界の応用および問題解決に関する豊富な知識は、MLの現状に深い洞察を提供します。例えば、あるディレクターは、新しいトランスフォーマースピーチテクノロジーの使用により、チームのエラーレートを30%減少させ、単純な思考が多くの計算能力を節約するのに役立つことに気付くでしょう。 SalesforceやZoomInfoのディレクターが現在のマシンラーニングの状況についてどう考えているのか、彼らの最大の課題は何か、そして彼らが最も興奮していることは何か、気になりませんか?それでは、すぐに知ることができます! この第2弾のSaaSに焦点を当てたインストールでは、ヘルスケアの教科書の著者であり、MLの才能を育成する非営利団体を設立した深層学習の専門家、チェス愛好家のサイバーセキュリティ専門家、リードリコール後のバービーのブランド評判の監視の必要性からビジネスを起こした起業家、そして自身の4人の子供がMLモデルと同じ間違いをするのを見るのが楽しいと感じる特許および学術論文の著者が登場します。 🚀 SaaSのトップマシンラーニングディレクターに会って、彼らがマシンラーニングについてどう考えているか聞いてみましょう: Omar Rahman – Salesforceでのマシンラーニングディレクター 経歴:オマーは、サイバーセキュリティチームの一環として、MLとデータエンジニアのチームをリードし、MLを防御的なセキュリティ目的で活用しています。以前、オマーはAdobeやSAPでデータサイエンスとMLエンジニアリングのチームをリードし、マーケティングクラウドや調達アプリケーションにインテリジェントな機能をもたらしていました。オマーはアリゾナ州立大学で電気工学の修士号を取得しています。 おもしろい事実:オマーはチェスをすることが大好きで、自由な時間にAIの卒業生を指導しています。 Salesforce:世界トップの顧客関係管理ソフトウェア。 1. MLはSaaSにどのようにポジティブな影響を与えていますか? MLはSaaSの提供に多くの利点をもたらしています。 a. アプリケーション内の自動化の改善:たとえば、サービスリクエストの文脈を理解し、組織内の適切なチームにルーティングするためにNLP(自然言語処理)を使用するサービスチケットルーター。 b. コードの複雑さの削減:ルールベースのシステムは、新しいルールが追加されると使いにくくなり、メンテナンスコストが増加します。例えば、以前のルールベースのシステムと比較して、MLベースの言語翻訳システムは、より正確で堅牢でありながら、はるかに少ない行数のコードで構築されています。 c. コスト削減につながるより良い予測結果。より正確に予測できることは、供給チェーンのバックオーダーの削減やストレージコストの削減など、コスト削減に役立ちます。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.